跟吴恩达学 Prompt Engineering:用清晰指令驯服 AI 的随机性
前言
很多人抱怨大模型"时灵时不灵"——同样的需求,有时候回答惊艳,有时候胡说八道。其实问题往往不在模型能力,而在我们给的指令不够清晰。
 吴恩达(Andrew Ng)的 Prompt Engineering 课程系统地讲了这件事:大模型很聪明,但它的"聪明"自带随机性。Prompt Engineering 的本质,就是用一系列规则来减少这种随机性,让模型稳定地输出我们想要的结果。
吴恩达(Andrew Ng)的 Prompt Engineering 课程系统地讲了这件事:大模型很聪明,但它的"聪明"自带随机性。Prompt Engineering 的本质,就是用一系列规则来减少这种随机性,让模型稳定地输出我们想要的结果。
本文结合课程核心原理和可直接运行的代码,帮你从"随便问问"进阶到"精确控制"。
一、两条核心原则
吴恩达提出了两条关键原则:
- 清晰且具体地表达(Be Clear and Specific):让模型准确理解你的目的,避免偏离主题或犯错。
- 给模型"思考"的时间(Give the Model Time to Think):不要期望一步到位,拆解任务步骤能让模型更可靠。
注意——清晰不等于简短。很多人习惯给模型一句话指令,但实际经验表明,篇幅更长的 Prompt 能提供更完整的上下文和约束,输出质量反而更高。
二、开胃菜:封装一个通用的 LLM 调用函数
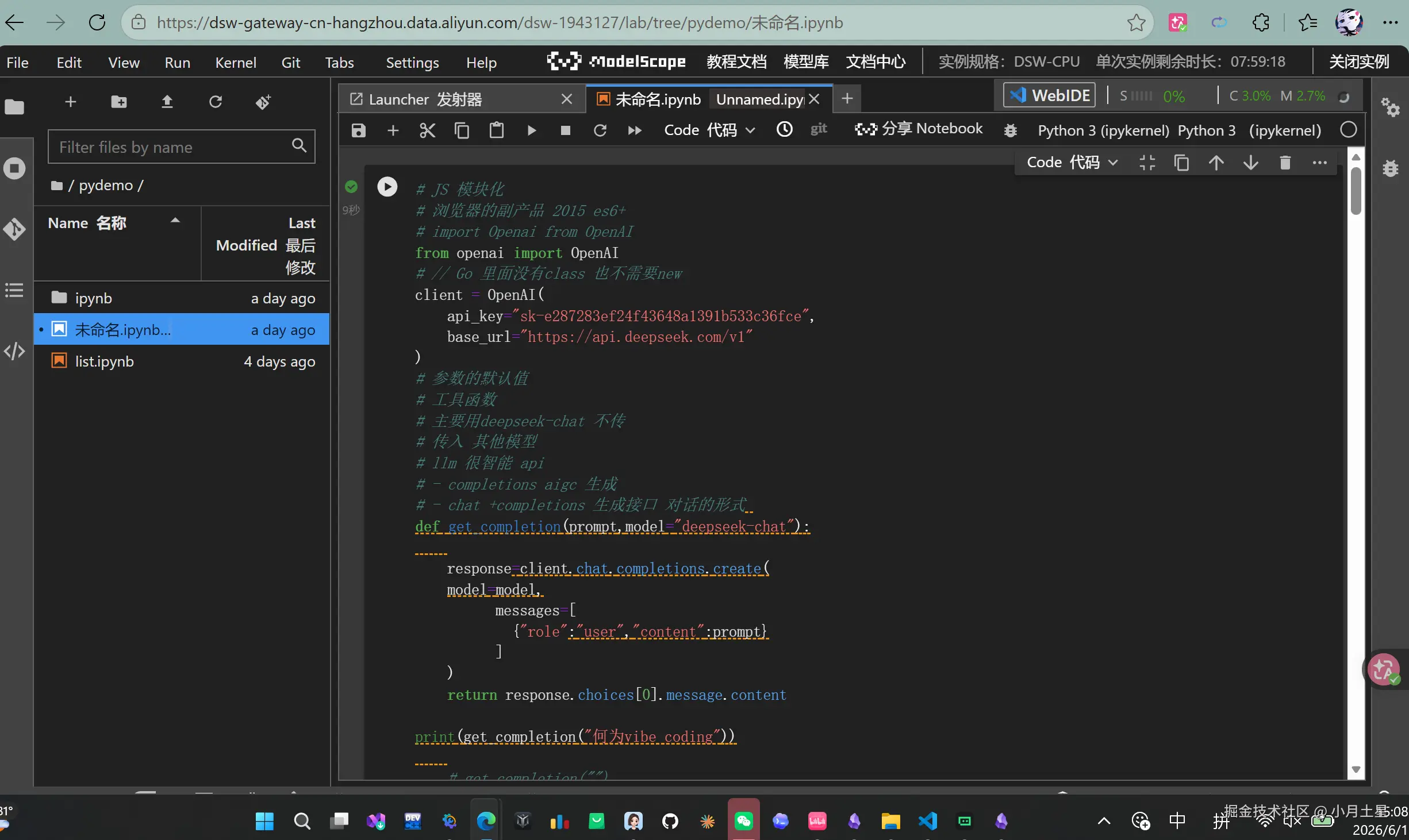 在开始之前,先封装一个工具函数。参数默认值是一个很实用的语法特性——默认用 deepseek-chat,也可以随时切换到其他模型:
在开始之前,先封装一个工具函数。参数默认值是一个很实用的语法特性——默认用 deepseek-chat,也可以随时切换到其他模型:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com/v1"
)
def get_completion(prompt, model="deepseek-chat"):
"""通用 LLM 调用函数,默认使用 deepseek-chat"""
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
函数虽短,但好处明显:复用、灵活、简洁。后文所有例子都通过它来调用。
三、技巧一:用分隔符清晰标记待处理文本
这是最简单也最实用的技巧。无论做摘要、翻译还是分析,先用符号(如 ```)把"待处理的内容"和"你的指令"清晰隔开。
text = f"""
你应当通过尽可能清晰、具体的指令,来明确你希望模型完成的任务。
这能引导模型产出符合预期的结果,同时降低回复内容偏离主题或出现错误的概率。
不要把编写清晰的提示词和精简提示词混为一谈。
很多时候,篇幅更长的提示词能为模型提供更完整的说明与背景信息,
进而让输出内容更加详实、贴合需求。
"""
prompt = f"""
将三个反引号之间的文本总结为一句话。
```{text}```
"""
print(get_completion(prompt))
输出:
通过提供清晰、具体且有时更长、更完整的指令和背景信息,可以引导模型产出更符合预期、更详实且减少错误的回复。
这里 {text} 是 Python f-string 的占位符。核心思路:让模型明确知道"哪部分是你要处理的原料"。 分隔符不限于反引号,尖括号 < >、XML 标签 <tag></tag> 等都行,关键是让你的指令边界清晰。
四、技巧二:约束输出格式(结构化输出)
让模型返回自然语言没问题,但在工程应用中,我们通常需要结构化数据——JSON 是最常见的选择。你可以在 Prompt 中明确要求字段名和含义。
prompt = f"""
请列出四大名著,并标注对应的作者与书籍类型。
使用 JSON 格式呈现,需包含以下字段:
book_id(书籍编号)、title(书名)、author(作者)、genres(书籍类型)、desc(概述)。
"""
print(get_completion(prompt))
输出(节选):
[
{
"book_id": 1,
"title": "水浒传",
"author": "施耐庵",
"genres": ["古典小说", "英雄传奇", "章回体"],
"desc": "以北宋末年宋江起义为背景,描写了一百零八位好汉被逼上梁山..."
},
...
]
这样做的好处很明显:后续代码可以直接 json.loads() 解析,无需额外处理。当你想让 AI 的输出接入自己的 pipeline 时,这一步是关键。
五、技巧三:引导模型分步执行
对于复杂任务,直接要最终结果容易出错。更好的做法是在 Prompt 里指定步骤顺序,让模型每一步只关注一件事。
先看一个包含操作指令的例子:
text = f"""
泡一杯茶其实很简单!
首先把水烧开。烧水的同时,拿出茶杯,放入茶包。
水烧开后,将热水冲入杯中浸泡茶包。静置片刻让茶香析出。
几分钟后取出茶包。
根据个人口味,还可以加入糖或牛奶。
这样一杯美味的茶饮就泡好了。
"""
prompt = f"""
你将收到三个引号包裹的文本。
若文本中包含一系列操作指令,
请按照以下格式重新整理这些指令。
步骤一 ...
步骤二 ...
...
步骤 N ...
如果文本中没有一系列操作指引,
直接输出**没有必要的步骤**
\"\"\"{text}\"\"\"
"""
print(get_completion(prompt))
输出:
步骤一:把水烧开。
步骤二:烧水的同时,拿出茶杯,放入茶包。
步骤三:水烧开后,将热水冲入杯中浸泡茶包。
步骤四:静置片刻让茶香析出。
步骤五:几分钟后取出茶包。
步骤六:根据个人口味,加入糖或牛奶。
同样一段 Prompt,如果输入的是一段写景文字(“今日阳光明媚,鸟儿欢唱…”),模型会正确判断并输出 “没有必要的步骤”。
这个技巧的价值在于:让模型具备条件判断能力——有指令就提取,没有就拒绝,而不是强行编造。
六、技巧四:Few-Shot 少样本提示
有时候你要的不是"规则",而是"风格"。Few-Shot 就是在 Prompt 里附带 1-2 个示例,让模型参照格式、逻辑和风格来作答,无需冗长的文字描述。
prompt = f"""
你的任务是保持统一的行文风格作答。
提问: 请讲讲何为耐心。
回答: 能凿出幽深峡谷的江河,源自涓涓细流;
恢弘壮阔的交响乐,起于单个音符;
精美繁复的织锦,始于一缕丝线。
提问: 请讲讲何为韧性。
"""
print(get_completion(prompt))
输出:
能磨圆砾石的潮水,源自千万次退却与重来;破土而出的翠竹,在暗处扎根数年而不语;锻打千次的刀锋,终成削铁如泥的寒光——所谓韧性,是温柔的固执,把每一道裂痕都编成向上的阶梯。
只给了一个"耐心"的示例,模型就学会了用类比排比 + 哲理总结的风格来写"韧性"。Few-Shot 的应用场景很广:客服话术统一、文案风格对齐、代码规范约束等。
七、进阶:多任务组合
真实业务场景往往不是一个任务走到底,而是多个子任务串联。你可以在一个 Prompt 里描述完整链路:
text = f"""
在一座风光宜人的小村庄里,姐弟俩杰克和吉尔动身前往山顶的水井取水。
两人一路欢歌向上攀登,不料意外突生
——杰克被石头绊倒,滚下山坡,吉尔也跟着摔了下去。
二人虽受了些轻伤,还是回到了家中,得到家人温柔的安抚。
这场小意外并未磨灭他们冒险的兴致,此后他们依旧满心欢喜地四处游玩。
"""
prompt = f"""
执行以下操作:
1. 将三个反引号的文本概括为一句话。
2. 把这一句话摘要翻译成法语。
3. 列出法语摘要中出现的所有人名。
4. 使用 JSON 格式呈现,包含字段: french_summary(法语摘要)、
num_names(人物数量)、name(名字,用 & 连接)。
```{text}```
"""
print(get_completion(prompt))
输出:
{
"french_summary": "Jack et Jill, un frère et une sœur, tombent d'une colline en allant chercher de l'eau, mais rentrent chez eux légèrement blessés et continuent à jouer joyeusement.",
"num_names": 2,
"name": "Jack&Jill"
}
模型在一个 Prompt 内完成了摘要 → 翻译 → 实体提取 → 结构化输出四个步骤。这种"任务链"模式在实际开发中非常实用,可以大大减少 API 调用次数。
八、避坑指南:LLM 幻觉问题
必须正视一个问题:大模型会产生幻觉(Hallucination)——即有模有样地编造看似合理但实际不存在的信息。 比如当你问一个不存在的"蜜雪冰城滑雪装备品牌"时,模型可能不会直接说"不存在",而是自行拼凑出一堆看似靠谱的答案。
应对策略:
- 要求模型先确认信息是否存在,再作答
- 让模型引用来源或标明不确定的部分
- 关键业务场景,在 Prompt 中提供事实依据,限制模型的"发挥空间"
总结
把这套方法论提炼成一张速查表:
| 技巧 | 核心思路 | 适用场景 |
|---|---|---|
| 清晰分隔 | 用 ` ````等分隔符标明待处理文本 | 摘要、翻译、分析 |
| 结构化约束 | 要求 JSON 输出并指定字段 | 工程接入、数据抽取 |
| 分步执行 | 在 Prompt 中指定步骤 N | 复杂推理、条件判断 |
| Few-Shot | 附带 1-2 个示例对齐风格 | 文案生成、格式对齐 |
| 多任务链 | 一个 Prompt 串联多个子任务 | 减少 API 调用、提升效率 |
最后用吴恩达课程中的一句话总结:不要把清晰的 Prompt 和简短的 Prompt 混为一谈。很多时候,篇幅更长的 Prompt 能提供更完整的背景和约束,让输出更可靠。 与其在对话中来回纠偏,不如在第一次就把话说清楚。
*本文基于吴恩达《ChatGPT Prompt Engineering for Developers》课程笔记与实战代码整理,所有代码均可直接运行呦。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)