当Agent需要动手干活:Tool还是MCP?
最近在调研各类Agent,遇到了一个很有趣的现象。业界各类产品集成的Agent有两种主流做法:一是 Agent 通过调用远程 MCP 工具包来走完整个编辑流程,二是 Agent 自带一套内置 Tool,所有操作在本地闭环完成。这个选择题是所有 Agent 产品都会面临的根本问题——Agent 的工具能力,应该长在自己身上,还是接在外部协议上?
这篇文章将先讲清楚 Tool 和 MCP 分别是什么(熟悉的同学可以跳过),再讨论在不同的业务场景下,到底应该怎么选。
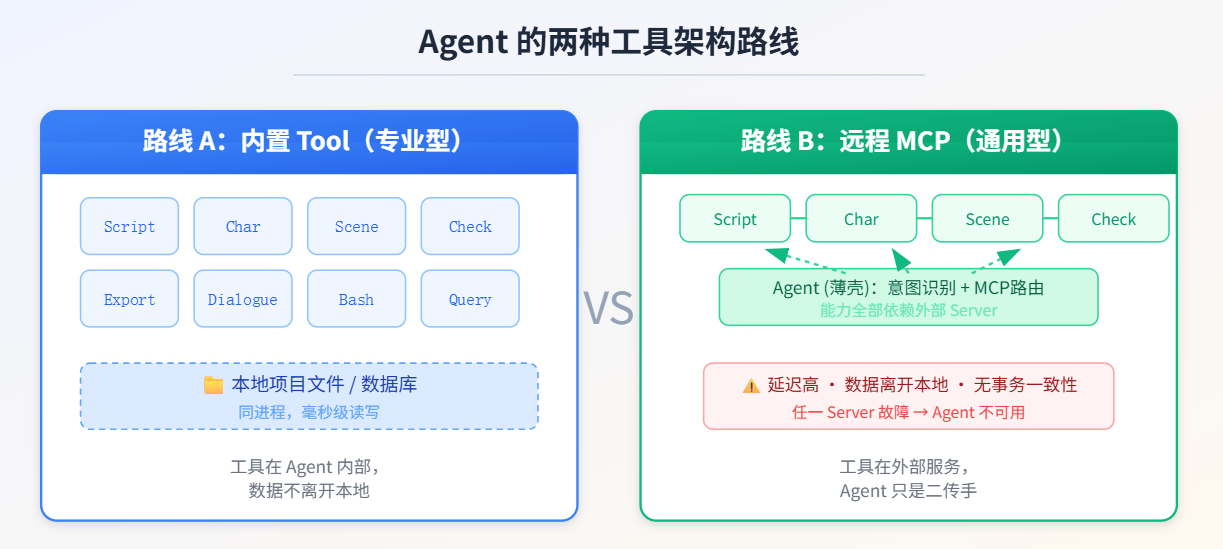
一、什么是Tool?
1.1 问题的起点:LLM 只能说话,不能动手
大语言模型(LLM)天生只会做一件事——根据输入文本生成输出文本。它没有眼睛,看不见你的文件系统;没有手,改不了你的代码;没有权限,执行不了任何命令。
如果你问一个纯 LLM:“帮我读一下项目里的 config.json,把数据库密码改成新的”,它会怎样?
它会假装帮你改了,生成一段看起来很对的文本,但你的文件纹丝不动。当你再问他,他会老实告诉你:“抱歉,我目前无法直接访问你的文件系统。你可以把文件内容粘贴到对话框中,我来帮你分析。”
这就是纯 LLM 的天花板:只能聊,不能干。
1.2 Function Calling:让 LLM说出它想用什么工具
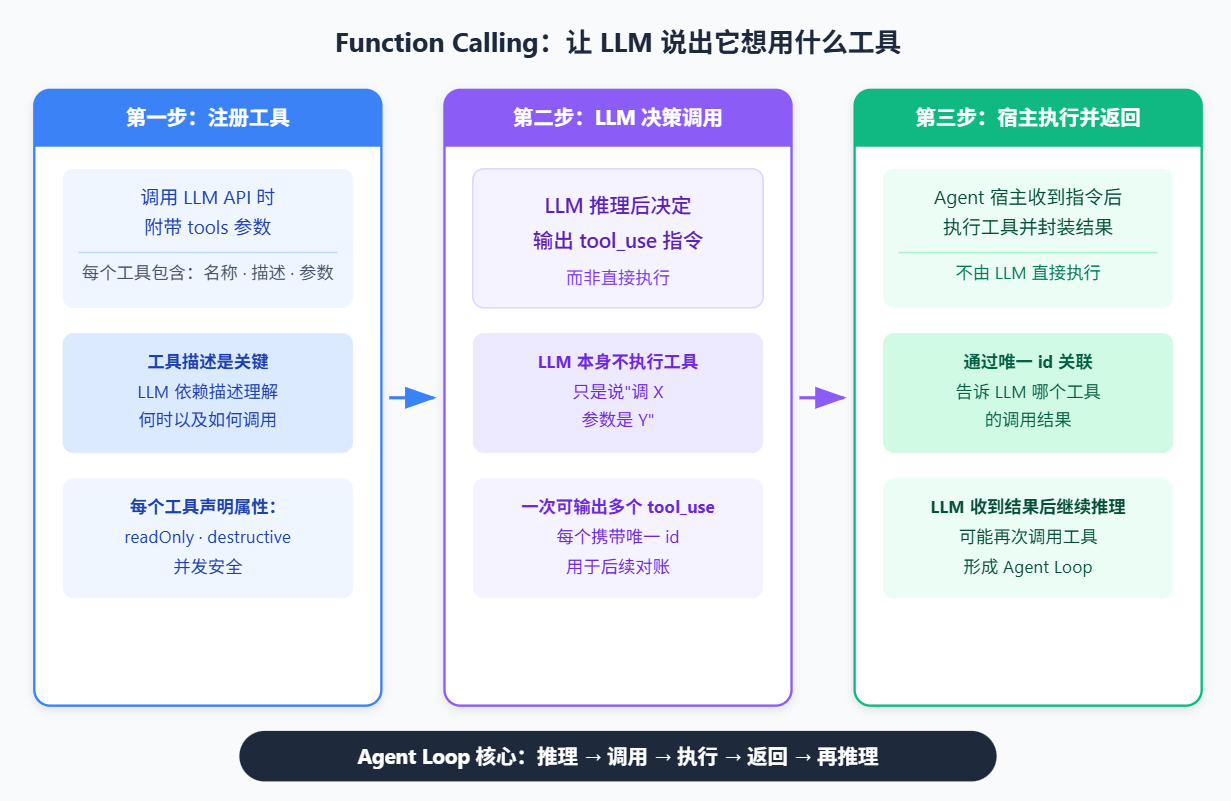
要让 LLM 能干实事,需要给它接上工具。而第一步,就是 Function Calling(也叫 Tool Use)。
Function Calling 的核心机制并不复杂,分三步走:
第一步:告诉模型有哪些工具可用。
在调用 LLM API 的时候,除了 prompt,还需要附带一个 tools 参数,能够描述提供的所有工具。每个工具包括:
name:工具名,比如ReadFiledescription:自然语言描述,告诉模型这个工具能干什么input_schema:JSON Schema,描述这个工具需要什么参数
举个例子,一个简单的文件读取工具定义:
{
"tools": [{
"name": "ReadFile",
"description": "读取指定路径的文件内容,返回带行号的文件文本",
"input_schema": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "文件的绝对路径"
}
},
"required": ["path"]
}
}]
}
第二步:模型决定使用哪个工具,返回 tool_use 指令。
当 LLM 推理后认为这个任务需要读取文件,它不会真的去读,而是输出一个结构化的 tool_use 消息。
{
"role": "assistant",
"content": [
{"type": "text", "text": "我来读取配置文件。"},
{
"type": "tool_use",
"id": "toolu_abc123",
"name": "ReadFile",
"input": {"path": "/home/user/project/main.py"}
}
]
}
第三步:宿主执行工具,把结果返回给模型。
你的代码收到 tool_use 后,不是模型在执行—,是客户端在执行,然后把结果封装为 tool_result 返回给模型:
{
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": "toolu_abc123",
"content": "1\tdef main():\n2\t print('hello')\n3\t ..."
}]
}
然后模型拿到文件内容,继续推理。可能需要第二次调用工具,也可能直接输出最终回复。
这就是 Agent Loop/ ReAct-style agent 的核心:LLM 推理 → 输出 tool_use → 宿主执行 → 返回 tool_result → LLM 再推理 → 循环,直到任务完成。
1.3 流式传输的复杂性
上面讲的是简化版。实际生产中,Function Calling 通常是流式的,模型不是一次性返回完整 JSON,而是一块一块地吐。
1.4 一个好 Tool 不止是能跑就行
Function Calling 只是通信协议。真正决定 Agent 体验的,是 Tool 的设计质量。
以本人开源项目内置的核心工具为例:
① BaseTool
所有工具继承同一个抽象基类:
interface BaseTool {
name: string // 工具名
description: string // 自然语言描述(直接影响 LLM 选择工具的准确率)
inputSchema: JSON // 参数 Schema
readOnly: boolean // 是否只读(影响权限控制)
destructive: boolean // 是否破坏性操作(影响确认流程)
concurrencySafe: boolean // 是否支持并发(影响调度策略)
category: string // 分类:file | shell | search
execute(ctx, input): ToolResult // 执行逻辑
validate(input): error | null // 参数校验
}
这个接口的精妙之处在于:元信息(readOnly、destructive、concurrencySafe)不只是注释,它们是 Agent 安全系统和调度系统的决策依据。
readOnly: true的工具(ReadFile、Glob、Grep)自动放行destructive: true的工具(WriteFile、EditFile)需要用户确认concurrencySafe: true的工具可以并行调用
② ReadFile
- 每行前面加行号前缀(
1\tcontent),让 LLM 能准确引用「第 42 行」 - 支持 offset + limit 分段读取,避免万行文件撑爆 token
- 检测二进制文件(前 512 字节有
\x00就拒绝),防止 LLM 读到乱码后瞎编 - 文件不存在、权限不足等异常返回明确的结构化错误
③ EditFile
EditFile 的逻辑是:LLM 提供 old_string 和 new_string,程序在文件中找到 old_string 的唯一匹配然后替换。
关键约束:old_string 必须在文件中恰好出现一次。为什么?
- 匹配到 0 次 → 说明 LLM 记错了文件内容,报错让它重新读取
- 匹配到 N 次 → 说明 old_string 太短不够唯一,报错让它加更多上下文
- 匹配到恰好 1 次 → 执行替换,并把修改后的行号返回给 LLM 确认
恰好一次的约束是大量踩坑后沉淀的设计——它专治 LLM 的记忆模糊和指令不精确两大顽疾。
④ Bash
让 LLM 执行 shell 命令。默认超时 120 秒,截断过长输出,合并 stdout/stderr,返回 exit code。
⑤⑥ Glob + Grep
Glob 按通配模式找文件,Grep 按正则搜文件内容。二者合力让 Agent 能快速理解项目结构——先 Glob 定位范围,再 Grep 精确定位,最后 ReadFile 读取详情。而且都是 readOnly,不计入安全确认的干扰项。
二、什么是MCP?
2.1 MCP 想解决什么问题
Function Calling 解决的是「模型怎么调用工具」的问题。但它没解决另一个问题:工具谁来做?
如果你的 Agent 需要集成 GitHub、Jira、Slack、Postgres、Docker……你不可能每一个都自己实现一遍。即使实现了,隔壁团队的 Agent 也想用 GitHub 集成,又得重新写一遍。
MCP(Model Context Protocol)就是来解决这个问题的。 它是 Anthropic 在 2024 年底发布的开源协议,核心思路是:
定义一套标准协议,让工具提供方(Server)和工具消费方(Agent/Client)解耦。一个 MCP Server 写好之后,任何实现了 MCP Client 的 Agent 都能直接用。
这个思路被比喻为「AI 时代的 USB」——以前每个设备都有自己的充电口,现在统一了标准。
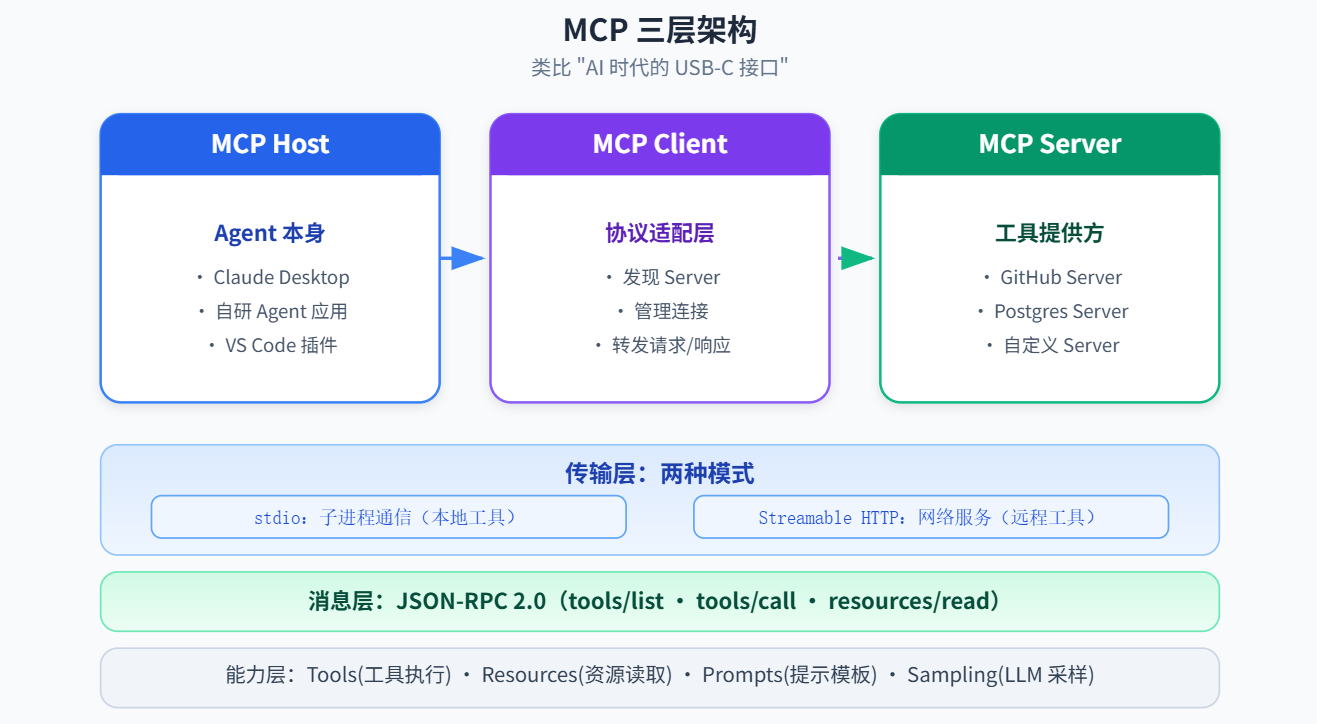
2.2 MCP 的架构
MCP 有三个角色:
- MCP Host:Agent 本身,比如 Claude Desktop、你的自研 Agent 应用
- MCP Client:协议适配层,负责发现 Server、管理连接、转发请求
- MCP Server:工具的实际提供方,暴露 Tools、Resources、Prompts 等能力
传输层有两种模式:
- stdio:Server 作为子进程启动,通过标准输入/输出通信。适合本地工具。
- Streamable HTTP:Server 作为网络服务运行,通过 HTTP 通信。适合远程工具。
消息层采用 JSON-RPC 2.0,定义了 tools/list、tools/call、resources/read 等标准方法。
能力层目前定义了四种 Server 能力:
| 能力 | 说明 | 例子 |
|---|---|---|
| Tools | 可执行的工具函数 | git commit、query database |
| Resources | 可读取的数据资源 | 文件内容、数据库记录 |
| Prompts | 预定义的提示模板 | 帮我写 Release Notes |
| Sampling | Server 反向请求 LLM 生成 | Server 内部需要 AI 辅助时 |
2.3 MCP 的工作流程
一个典型的使用流程:
1. 用户启动 Agent
2. Agent 根据配置,初始化所有已连接的 MCP Client
3. 每个 Client 向对应的 Server 发送 tools/list 请求
4. Server 返回自己能提供的工具列表(含 name、description、inputSchema)
5. Agent 将所有 Server 的工具合并,注册到自己的工具清单
6. 用户发出指令 → LLM 决定调用某个工具
7. Agent 通过 MCP Client 向对应 Server 发送 tools/call 请求
8. Server 执行并返回结果
9. Agent 将结果喂给 LLM,继续循环
和内置 Tool 的关键区别在于第 7-8 步:工具执行不在 Agent 进程内,而是通过网络或子进程通信交给外部服务完成。
2.4 MCP 的生态效应
MCP 最大的价值不是技术上的,而是生态上的。
官方和社区已经贡献了大量 MCP Server,而且这些 Server 的实现语言不受限——Python、TypeScript、Go、Rust 都可以,只要能实现 JSON-RPC 通信就行。
对于 Agent 开发者来说,MCP 意味着不用再造轮子。 你的 Agent 只需要接上 MCP Server。
2.5 MCP 的局限
但在实际使用中,MCP 有几个绕不开的问题:
延迟不可控。 每次工具调用都要经过:Agent → MCP Client → 序列化 → 传输 → Server 反序列化 → 执行 → 序列化 → 传输 → 反序列化 → Agent。即使在内网,这个链路也比同进程调用慢一个数量级。
体验不由你控制。 你接入了 10 个 MCP Server。其中 9 个质量很好,1 个返回格式混乱、错误信息含糊、动不动超时。用户不会骂那个 Server 的开发者——他们骂的是你的 Agent。
安全模型分散。 内置 Tool 下,Agent 统一管理权限和安全策略(readOnly 自动放行、destructive 需确认)。MCP 下,每个 Server 自行负责安全,Agent 只能做粗粒度的连/不连控制。
调试困难。 问题可能在 Agent、Client、传输层、Server 四个环节中的任何一个,排查链路长。
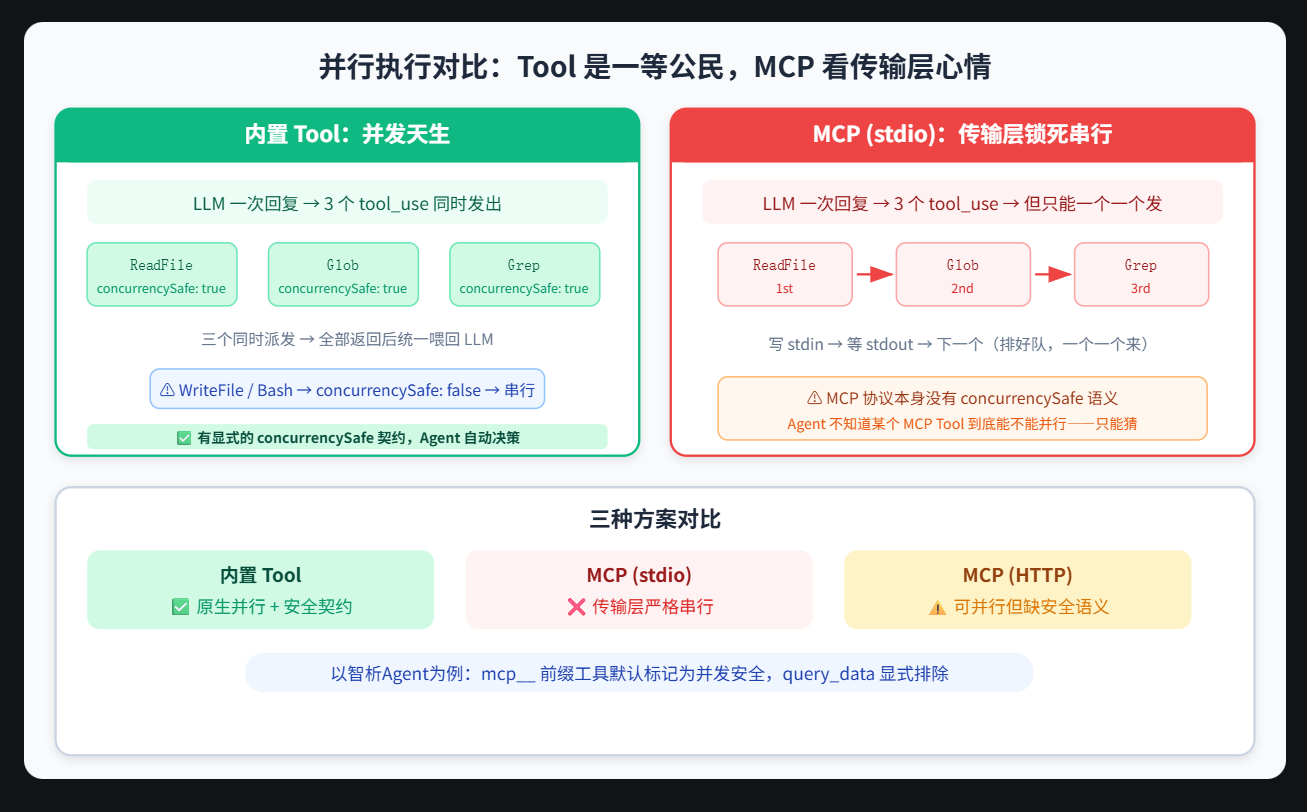
2.6 并行执行:Tool 和 MCP 的差距有多大?
这是一个容易被忽略但实际影响巨大的差异。
Tool 的并行:一等公民
Tool 路线下,并行是设计在基因里的。LLM 一次回复可以输出多个 tool_use,Agent 根据每个工具的 concurrencySafe 元信息来决定能否并发派发:
LLM 一次回复:
├── tool_use: ReadFile("main.py") ← concurrencySafe: true
├── tool_use: ReadFile("config.json") ← concurrencySafe: true
└── tool_use: Glob("**/*.py") ← concurrencySafe: true
Agent : 三个同时派发 → 全部返回后统一喂回 LLM
在 Data-Analysis-Agent 里,ReadFile、Glob、Grep 都是 concurrencySafe: true——纯读取操作,放心并行。而 WriteFile、EditFile 是 false——你不可能两个线程同时写同一个文件。Bash 也是 false——shell 环境共享,并行不可控。
MCP 的并行:协议行,传输层拉胯
MCP 底层用的是 JSON-RPC 2.0,协议本身支持并发——你可以对同一个 Server 同时发多个 tools/call,各带不同的 id,Server 返回时靠 id 对应。
但问题不在协议层,在传输层:
| 传输方式 | 并行能力 | 原因 |
|---|---|---|
| stdio | 不支持 | 标准输入输出是单管道。上一请求的响应没回来之前,不能发下一个。写 stdin → 等 stdout → 下一个。 |
| Streamable HTTP | 支持 | HTTP 天然多连接,可以同时发多个请求。 |
而现实中,大量 MCP Server 默认用的是 stdio 模式(通过 uvx run 或 npx 启动子进程,走标准输入输出)。这意味着:即使你的 Agent 想并行调一个 MCP Server 的 3 个工具,如果它走的是 stdio 只能排好队,一个一个来。
更致命的问题:MCP 缺少「并发安全」语义
内置 Tool 有 concurrencySafe 这个元信息——它是显式的、可编程的契约,Agent 知道哪些工具能并行、哪些不能。
MCP 协议规范里没有等价概念。Agent 不知道一个 MCP Server 的某个工具到底支不支持并发。你只能猜。
跨 Server 并行理论上可以,但实践中少见
如果你连了 3 个 MCP Server(都走 HTTP),Agent 可以同时给它们发请求:
Agent 同时派发:
├── → GitHub Server: "list PRs" ← HTTP,可以
├── → Jira Server: "query bugs" ← HTTP,可以
└── → Slack Server: "post message" ← HTTP,可以
但这个场景的实际触发率很低——LLM 一次推理通常产出的是同领域的工具调用(比如同时查 3 张表的 schema),而同一领域的工具大概率挂在同一个 MCP Server 上。同一个 Server + stdio = 退化成串行。
对比总结:
| 维度 | 内置 Tool | MCP (stdio) | MCP (HTTP) |
|---|---|---|---|
| 并行派发 | 支持 | 传输层串行 | 可以,但缺少并发安全语义 |
| 并行安全保证 | 声明式契约,Agent 自动决策 | 无 | 无 |
| 实际工程表现 | 3-5 个读操作同时进行是常态 | 一个接一个排队 | 取决于是否有人专门写了 HTTP Server |
三、到底什么时候用 Tool,什么时候用 MCP?
3.1 决策框架:两个维度四个象限
回到最开始的问题。我们把决策简化成两个维度:
- X 轴:操作频率(这个工具被调用的频次有多高?)
- Y 轴:领域耦合度(这个工具和你的核心业务逻辑绑得有多紧?)
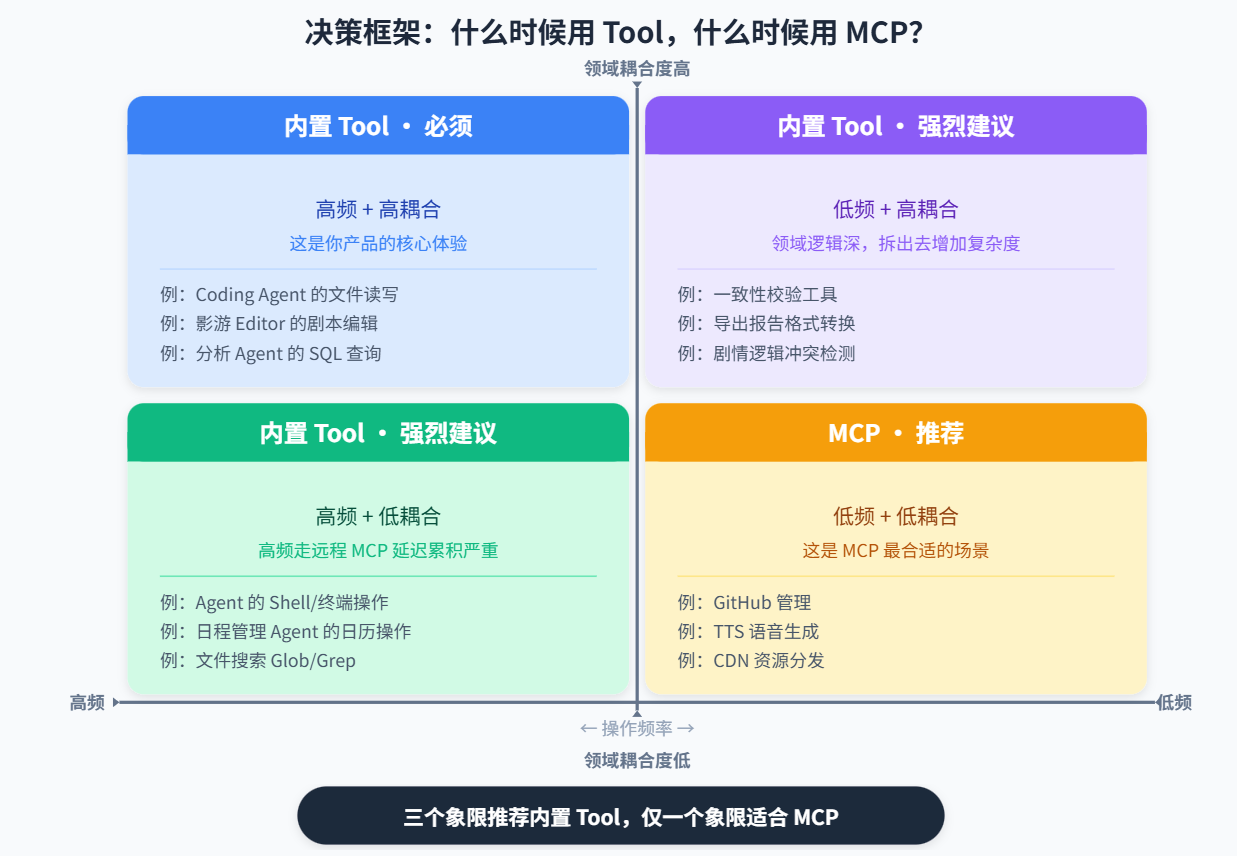
结论很直接:只有低频 + 低耦合这一种情况适合 MCP,其余三种都应该用内置 Tool。
3.2 MCP 的舒适区
总结一下,MCP 真正发光发热的场景有三个共同特征:
- 低频使用:一天用不了几次,延迟不敏感
- 独立性强:和核心业务逻辑没有紧密耦合,拆出去不影响整体
- 计算或数据在外部:本地做不了(GPU 渲染)、数据在别处(第三方 API)、或社区已有现成的 Server
除此之外的场景,本人认为内置 Tool 都是更好的选择。
四、智析Agent(Data-Analysis-Agent)的混合架构
智析Agent 是一个面向商业分析的 AI Agent——用户上传 Excel/CSV 或连接数据库后,用自然语言提问,Agent 自动完成数据识别、SQL 生成、图表推荐和业务洞察。
4.1 架构总览
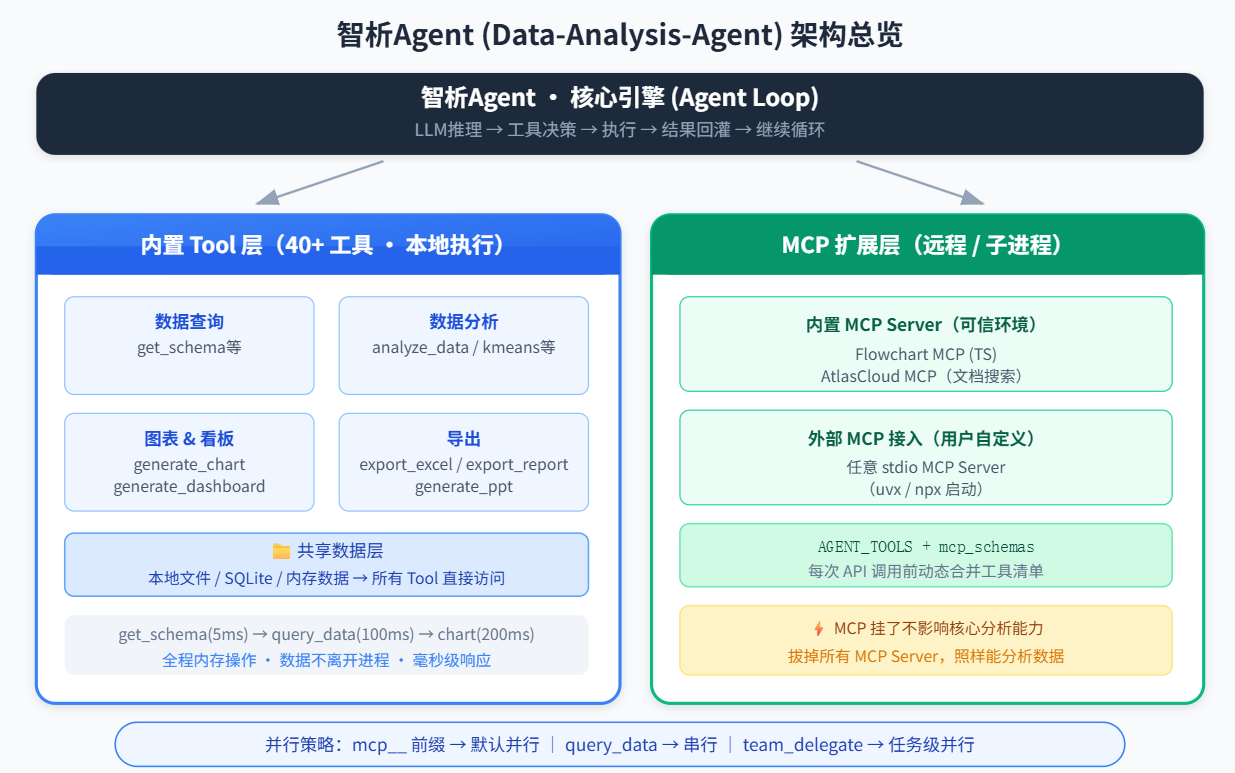
4.2 为什么核心分析流水线用内置 Tool?
智析Agent 把 get_schema → query_knowledge → query_data → analyze_data → generate_chart 这条链路全部做成了内置 Tool。原因很直接:
这是一个深度耦合的闭环。 每一步的输出是下一步的输入——表结构决定了 SQL 怎么写,SQL 的结果决定了该画什么图。如果把这些拆成独立的 MCP Server,每步都跨进程传数据,延迟累积会非常可观。
而且分析场景对数据安全极度敏感。用户上传的 Excel/CSV 可能包含商业机密。如果 query_data 走远程 MCP,意味着原始数据要离开 Agent 进程。
4.3 MCP 用来做什么?——能力扩展,而非核心流程
智析Agent 的 MCP 层只承担两个角色:
1. 内置 MCP Server(可信环境):
流程图 MCP 是一个 TypeScript 编写的独立服务,负责生成流程图。为什么不用内置 Tool?因为流程图渲染需要独立的布局引擎和导出模块,做成 MCP Server 可以独立开发、独立测试、独立部署,而且 TypeScript 生态在前端图表方面更成熟。
2. 外部 MCP 接入(用户自定义):
通过 MCPManager,用户可以自行连接任意 MCP Server。系统会动态获取这些 Server 暴露的工具列表,合并到 LLM 可用的工具清单中。
关键在于:外部 MCP 挂了,不影响 Agent 的核心分析能力。 断开所有 MCP Server,照样能上传 Excel、问问题、生成图表——因为那些能力是内置 Tool 提供的。
五、为什么说「MCP 调用壳」不是护城河
回到一个更商业的视角。
我见过一些 Agent 产品的架构:核心逻辑只有一层薄薄的「意图识别 + MCP 路由」,所有实际能力由第三方 MCP Server 提供。这种架构看起来很美——开发快、生态广、维护成本低。
但它有一个致命缺陷:没有护城河。
如果两个竞争对手接入的 MCP Server 集合完全相同,它们的「能力」就完全相同。唯一的差异化只剩下 Prompt 写得怎么样——而这几乎构不成壁垒。
真正的护城河是那些你不得不自己做的 Tool。 以 Coding Agent 为例:
- EditFile 的「唯一匹配约束」——这是对 LLM 行为模式的深刻理解
- Bash 的输出截断和后台运行策略——这是踩了一百个坑之后才定下来的
- Glob 的默认排除目录——这是对开发者工作流的洞察
这些东西 MCP Server 也可以实现,但第一,现成的 MCP Server 大概率没做到这个深度;第二,这些设计需要和你的 Agent Loop 协同优化,不是一个独立服务能搞定的。
所以结论是:MCP 解决的是能力有无的问题,内置 Tool 解决的是能力好不好的问题。前者决定你能做什么,后者决定你的产品值不值得用。
本文部分技术细节参考了业界公开的 Tool 系统设计实践、Anthropic MCP 协议规范、智析Agent(Data-Analysis-Agent)项目架构,以及笔者近期的实际调研。欢迎讨论。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)