一文带你入门LangChain
LangChain
1 了解 LangChain
1.1 LangChain 所包含的包
| 包 | 描述 |
|---|---|
| langchain | 包含构建使用LLM的应用所需的所有实现的主入口点 |
| langchain-core | LangChain生态系统中的核心接口和抽象 |
| langchain-openai/deepseek | Langchain和OpanAI(Deepseek)继承包,langchain还包含还包含了一系列集成包,包括文本生成模型, 工具,文档加载, 向量存储等多个方面,共同构成了LangChain生态系统 |
| langchain-mcp-adapters | 在LangChain和LangGraph应用中提供MCP工具 |
| langchain-text-splitters | 用于文档处理的文本分割工具 |
| langchain-tests | 用于验证Langchain集成包实现的标准化测试套件 |
| langchain- classic | 遗留的langchain实现和组件,主要为1.0.0版本和以前相关的内容 |
1.2 LangChain 核心模块划分
langchain的核心组件, 从逻辑上可以分为Model I/O, Chain, RAG,Agents
-
Model I/O
标准化大模型的输入和输出, 包括提示词模版, 模型调用和格式化输出
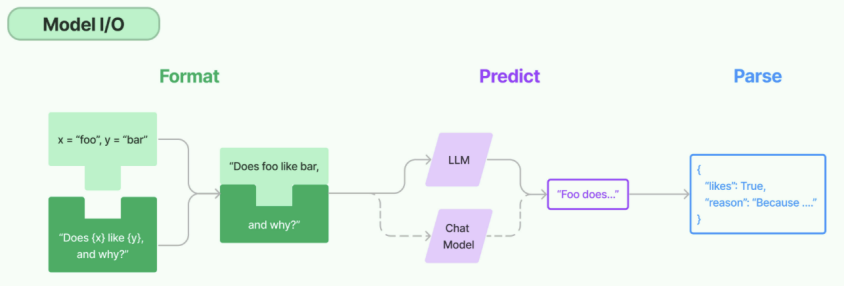
1. Format(格式化):通过模版管理大模型的输入,将原始数据格式化成模型可以处理的形式, 插入到一个模版中, 然后送入大模型进行处理
2. Predict(预测): 调用LLM接收收入, 进行预测/生成答案
3. Prase(解析):规范化模型输出,例如将模型输出格式化为JSON
-
Chain: 用于将多个组件组合成一个完整的流程, 方便链式调用
-
Retrieval: 对应RAG,检索外部数据,作为参考信息输入LLM辅助生成答案
-
Agents: Agent自主规划步骤并且使用工具来完成任务
2 Model I/O 与 Chain
2.1 在线调用大模型
对于不同LLM厂商的模型, 需要不同的SDK来调用, 但是如果使用LangChain,就可以通过统一的方式来进行模型调用和解析
在使用LangChain来进行模型调用之前,需要先安装对应的包, 如对于OpenAI,需要安装langchain-openai。https://docs.langchain.com/oss/python/integrations/providers/overview
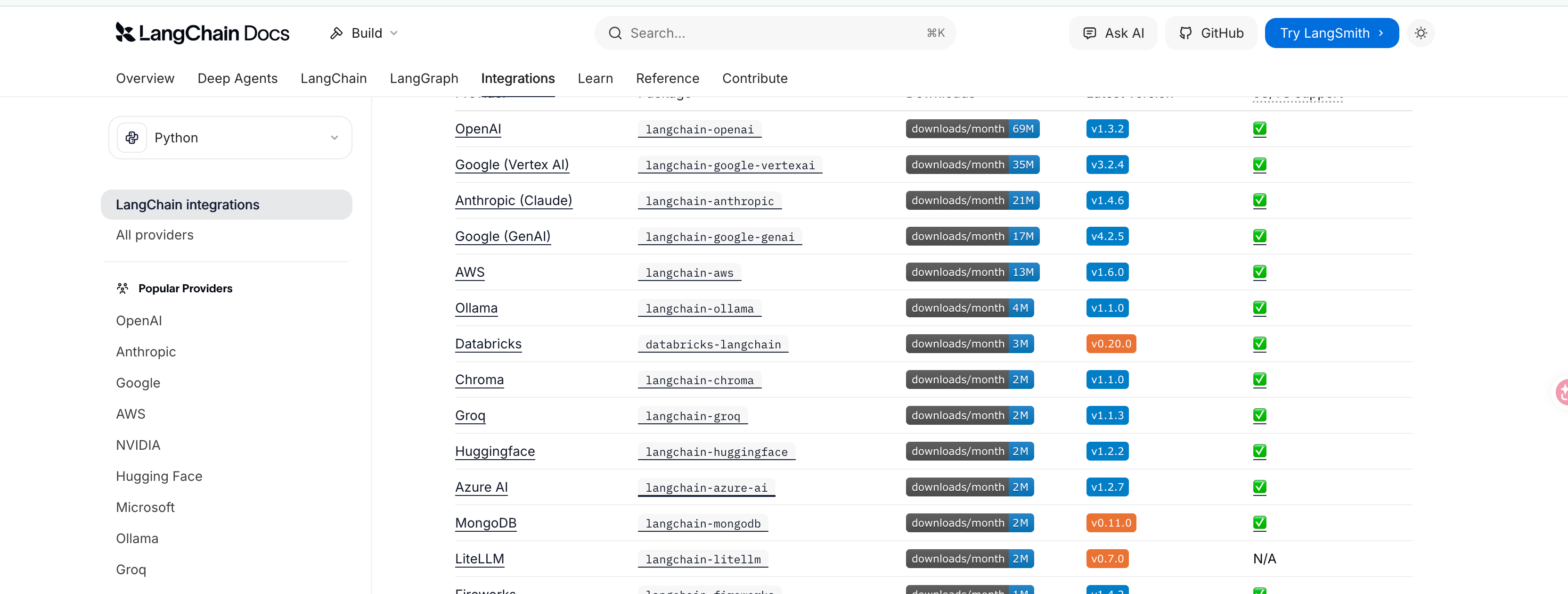
使用langchainApi调用大模型的步骤如下
-
构造LLM ChatModel实例
-
传递Message 对象列表或普通字符串,调用LLM实例
-
解析调用结果
2.1.1 构造 LLM 实例
方式1:
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="gpt-4.1-free",
model_provider='openai',
base_url='https://aihubmix.com/v1',
api_key=os.getenv('AIHUBMIX_API_KEY')
)
resp = llm.invoke('你是哪个模型?')
print(f"type of resp: {type(resp)}, resp -> {resp}")
执行结果:

方式2:(使用特定包下的LLM Model实例化,但是本质上还是调用的上面的init_chat_model
llm = ChatOpenAI(
model='gpt-4.1-free',
temperature=0.0,
base_url='https://aihubmix.com/v1',
api_key=os.getenv('AIHUBMIX_API_KEY')
)
resp = llm.invoke('你是哪个模型?')
2.1.2 调用 LLM 实例
2.1.2.1 调用传入对象类型
在上面我们直接传入的是一个字符串对象, 但是更好的方式是传入一个消息列表
from typing import Any
from uuid import UUID
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.messages import BaseMessage
class PrintPromptCallback(BaseCallbackHandler):
def on_chat_model_start(
self,
serialized: dict[str, Any],
messages: list[list[BaseMessage]],
*,
run_id: UUID,
parent_run_id: UUID | None = None,
tags: list[str] | None = None,
metadata: dict[str, Any] | None = None,
**kwargs: Any,
) -> Any:
print("\n========= Langchain 调用llm前完整的messages =========")
for batch_index, message_list in enumerate(messages):
print(f'\n --- batch {batch_index} --- ')
for msg in message_list:
print(f'message -> {msg.type} : {msg.content}')
print("\n========= 输出完毕 =========")
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from model_io.invoke_config import PrintPromptCallback
llm = ChatOpenAI(
model='gpt-4.1-free',
api_key=os.getenv('AIHUBMIX_API_KEY'),
base_url='https://aihubmix.com/v1'
)
resp = llm.invoke(
[
SystemMessage(content='你是一个专业的法律知识问答助手'),
HumanMessage(content='你是谁?')
],
config={
"callbacks":[PrintPromptCallback()]
}
)
print(f"resp: {resp.content}")

消息列表表示了一段“聊天记录历史”,不同的消息类型, 代表了不同的角色
| 类型 | 描述 |
|---|---|
| SystemMessage | 代表一段初始指令,用于引导模型的行为, 可以使用系统消息设定语气,定义模型的角色,并建立响应的指导方针 |
| HumanMessage | 表示用户的输入,可以在message当中传递其他元数据信息 |
| AIMessage | 模型生成的响应,包括文本内容,工具调用和token使用量等元数据信息 |
| ToolMessage | 表示工具调用的输出 |
除了使用上面的方式,还可以使用元组对象来表示, 元组对象第一个元素表示角色, 第二个就是具体的消息内容,也可以通过OpenAI官方使用的dict来表示,dict当中有两个类, 一个为role,一个是content
message_list = [
{
"role":"system",
"content": '你是一个专业的法律知识问答助手'
},
{
"role":"user",
"content":'你是谁?'
}
]
resp = llm.invoke(
message_list
)
print(f"resp: {resp.content}")
2.1.2.2 调用方式
LangChain的LLM对象还支持异步调用,流式调用,批调用等多种方式
异步:
async def main():
print("执行开始")
task = asyncio.create_task(
llm.ainvoke([
("user", "什么是 LangChain")
])
)
print("LLM 请求已经提交了,但我现在不等它")
print("我可以先做别的事情")
await asyncio.sleep(2)
print("别的事情做完了,现在再等 LLM 结果")
resp = await task
print(f"resp: {resp.content}")
print("执行结束")
asyncio.run(main())

流式:
def stream_call():
resp = llm.stream(
input=[
("user","什么是LangChain")
]
)
for chunk in resp:
print(chunk.content,end="")
if __name__ == '__main__':
stream_call()
批次调用
def batch_call():
resps = llm.batch(
inputs=
[
[
('user','什么是LangChain'),
('user','LangChain的核心价值是什么?')
]
]
)
for question_chunk in resps:
print(question_chunk.content)
if __name__ == '__main__':
batch_call()
2.1.3 模型调用结果解析
LLM产出的时候,我们希望模型以更加结构化的形式进行输出,如JSON,LangChain设计了一系列包(如langchain_core.output_parsers)和方法专门用来解决此类问题
2.1.3.1 获取 JSON 结果
要想大模型输出json字符串, 有两种方式
2.1.3.1.1 通过 Prompt 约束
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import JsonOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from model_io.invoke_config import PrintPromptCallback
llm = ChatOpenAI(
model='glm-4.7',
api_key=os.getenv('GLM_API_KEY'),
base_url='https://open.bigmodel.cn/api/paas/v4'
)
class Prime(BaseModel):
prime: list[int] = Field(description='素数')
count: list[int] = Field(description='小于该素数的素数个数')
json_parser = JsonOutputParser(pydantic_object=Prime)
res = llm.invoke(
[
SystemMessage(json_parser.get_format_instructions()),
HumanMessage("任意生成5个1000-10000000之间的素数,并且标出小于该素数的素数个数")
],
config={
"callbacks": [PrintPromptCallback()]
}
)
print(res.content)
parsed_res = json_parser.invoke(res)
print(type(parsed_res))
执行结果:
========= Langchain 调用llm前完整的messages =========
--- batch 0 ---
message -> system : STRICT OUTPUT FORMAT:
- Return only the JSON value that conforms to the schema. Do not include any additional text, explanations, headings, or separators.
- Do not wrap the JSON in Markdown or code fences (no ```or ```json).
- Do not prepend or append any text (e.g., do not write "Here is the JSON:").
- The response must be a single top-level JSON value exactly as required by the schema (object/array/etc.), with no trailing commas or comments.
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]} the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema (shown in a code block for readability only — do not include any backticks or Markdown in your output):
{“properties”: {“prime”: {“description”: “素数”, “items”: {“type”: “integer”}, “title”: “Prime”, “type”: “array”}, “count”: {“description”: “小于该素数的素数个数”, “items”: {“type”: “integer”}, “title”: “Count”, “type”: “array”}}, “required”: [“prime”, “count”]}
message -> human : 任意生成5个1000-10000000之间的素数,并且标出小于该素数的素数个数
========= 输出完毕 =========
{
"prime": [1009, 3571, 48611, 611953, 999983],
"count": [168, 499, 4999, 49999, 78497]
}
<class 'dict'>
Process finished with exit code 0
Prompt约束,对模型能力有一定的依赖,如果模型参数不够强,就容易出现幻觉,从而导致输出的json语法有问题,或者是不符合我们定义的json格式
2.1.3.1.2 通过厂商能力
对于主流大模型厂商, 其api已经提供了专门的参数,用以限制模型输出内容符合我们所定义的schema结构
import os
import json
import httpx
from openai import OpenAI
from pydantic import BaseModel
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
def print_request(request: httpx.Request):
print("\n========== 最终 HTTP 请求 ==========")
print("URL:", request.url)
print("Method:", request.method)
safe_headers = {
k: v
for k, v in request.headers.items()
if k.lower() != "authorization"
}
print("Headers:", dict(safe_headers))
try:
body = json.loads(request.content.decode("utf-8"))
print("Body:")
print(json.dumps(body, ensure_ascii=False, indent=2))
except Exception:
print("Raw Body:", request.content)
print("===================================\n")
http_client = httpx.Client(
event_hooks={
"request": [print_request]
}
)
client = OpenAI(
base_url="https://aihubmix.com/v1",
api_key=os.getenv("AIHUBMIX_API_KEY"),
http_client=http_client
)
response = client.chat.completions.parse(
model="gpt-4.1-free",
messages=[
{
"role": "user",
"content": "Alice and Bob are going to a science fair on Friday."
}
],
response_format=CalendarEvent
)
print(response.choices[0].message.parsed)
========== 最终 HTTP 请求 ==========
URL: https://aihubmix.com/v1/chat/completions
Method: POST
Headers: {'host': 'aihubmix.com', 'accept-encoding': 'gzip, deflate, zstd', 'connection': 'keep-alive', 'accept': 'application/json', 'content-type': 'application/json', 'user-agent': 'OpenAI/Python 2.43.0', 'x-stainless-lang': 'python', 'x-stainless-package-version': '2.43.0', 'x-stainless-os': 'MacOS', 'x-stainless-arch': 'arm64', 'x-stainless-runtime': 'CPython', 'x-stainless-runtime-version': '3.14.4', 'x-stainless-async': 'false', 'x-stainless-helper-method': 'chat.completions.parse', 'x-stainless-retry-count': '0', 'x-stainless-read-timeout': '600', 'content-length': '525'}
Body:
{
"messages": [
{
"role": "user",
"content": "Alice and Bob are going to a science fair on Friday."
}
],
"model": "gpt-4.1-free",
"response_format": {
"type": "json_schema",
"json_schema": {
"schema": {
"properties": {
"name": {
"title": "Name",
"type": "string"
},
"date": {
"title": "Date",
"type": "string"
},
"participants": {
"items": {
"type": "string"
},
"title": "Participants",
"type": "array"
}
},
"required": [
"name",
"date",
"participants"
],
"title": "CalendarEvent",
"type": "object",
"additionalProperties": false
},
"name": "CalendarEvent",
"strict": true
}
},
"stream": false
}
===================================
name='Science Fair' date='2024-06-14' participants=['Alice', 'Bob']
Process finished with exit code 0
Langchain也对这种能力进行了封装, 不同厂商的模型都是继承了ChatModel类,而ChatModel提供了with_structured_output方法,传入pydantic base model类作为schema对象,得到一个新的llm对象,调用新的llm对象即可。
llm = ChatOpenAI(
model='gpt-4.1-free',
base_url="https://aihubmix.com/v1",
http_client=http_client,
api_key=os.getenv("AIHUBMIX_API_KEY")
)
newllm = llm.with_structured_output(schema=CalendarEvent)
res = newllm.invoke('Alice and Bob are going to a science fair on Friday.')
print(res)
========== 最终 HTTP 请求 ==========
URL: https://aihubmix.com/v1/chat/completions
Method: POST
Headers: {'host': 'aihubmix.com', 'accept-encoding': 'gzip, deflate, zstd', 'connection': 'keep-alive', 'accept': 'application/json', 'content-type': 'application/json', 'user-agent': 'OpenAI/Python 2.43.0', 'x-stainless-lang': 'python', 'x-stainless-package-version': '2.43.0', 'x-stainless-os': 'MacOS', 'x-stainless-arch': 'arm64', 'x-stainless-runtime': 'CPython', 'x-stainless-runtime-version': '3.14.4', 'x-stainless-async': 'false', 'x-stainless-helper-method': 'chat.completions.parse', 'x-stainless-raw-response': 'true', 'x-stainless-retry-count': '0', 'content-length': '525'}
Body:
{
"messages": [
{
"content": "Alice and Bob are going to a science fair on Friday.",
"role": "user"
}
],
"model": "gpt-4.1-free",
"response_format": {
"type": "json_schema",
"json_schema": {
"schema": {
"properties": {
"name": {
"title": "Name",
"type": "string"
},
"date": {
"title": "Date",
"type": "string"
},
"participants": {
"items": {
"type": "string"
},
"title": "Participants",
"type": "array"
}
},
"required": [
"name",
"date",
"participants"
],
"title": "CalendarEvent",
"type": "object",
"additionalProperties": false
},
"name": "CalendarEvent",
"strict": true
}
},
"stream": false
}
===================================
name='Science Fair' date='2024-06-14' participants=['Alice', 'Bob']
Process finished with exit code 0
不管使用什么模型,都是调用统一的方法,就能够实现相关的需求,如果需要换模型,只需要调整llm实例化代码即可,其余代码无需改动,这正是LangChain框架的强大之处。
2.1.3.2 获取其他类型的解析结果
想要获取其他类型(如XML)等的结果, 也可以通过output_parser当中的其他类来实现
__all__ = [
"BaseCumulativeTransformOutputParser",
"BaseGenerationOutputParser",
"BaseLLMOutputParser",
"BaseOutputParser",
"BaseTransformOutputParser",
"CommaSeparatedListOutputParser",
"JsonOutputKeyToolsParser",
"JsonOutputParser",
"JsonOutputToolsParser",
"ListOutputParser",
"MarkdownListOutputParser",
"NumberedListOutputParser",
"PydanticOutputParser",
"PydanticToolsParser",
"SimpleJsonOutputParser",
"StrOutputParser",
"XMLOutputParser",
]
2.1.4 提示词模版
固定的提示词限制了模型的灵活性和适用范围,通过提示词模版,可以将变量插入到模版中,从而创建出不同的Prompt
LangChain中有很多类型的提示模版, 常用的有PromptTemplate(字符串提示词模版)和ChatPromptTemplate(聊天提示词模版)
提示词模版以字典作为输入,其中每一个键代表要填充在提示词模版中的变量,并输出一个PromptValue,这个PromptValue可以传递给聊天模型,也可以转化为字符串或消息列表,PromptValue存在的目的就是方便在字符串和消息之间进行切换
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
chat_prompt_template = ChatPromptTemplate.from_messages(
messages=[
("system","你是一个专门的评论员"),
("human",'请你评价{product}的优缺点,包括{aspect1}和{aspect2}')
]
)
chat_prompt_value = chat_prompt_template.invoke(
{
"product":"IPhone 15",
"aspect1":'性能',
"aspect2":'外观'
}
)
llm = init_chat_model(
model='gpt-4.1-free',
base_url='https://aihubmix.com/v1',
api_key=os.getenv('AIHUBMIX_API_KEY')
)
resp = llm.invoke(chat_prompt_value)
print(resp)
content='当然,以下是对iPhone 15的详细优缺点评价(基于2024年的资料):\n\n一、性能方面\n\n优点:\n\n1. A16仿生芯片\n - iPhone 15采用与iPhone 14 Pro相同的A16仿生芯片,性能提升明显。无论是日常操作、游戏还是多任务处理,都非常流畅。\n2. 能效优化\n - 芯片在性能强大的同时能耗控制做得很好,续航时间相比前代有所提升。\n3. USB-C接口\n - 首次加入USB-C接口,传输速度和兼容性大幅提升,方便与其他电子设备连接。\n4. 摄像头升级\n - 主摄提升到4800万像素,照片细节更丰富,夜景和人像拍摄效果显著增强。\n5. 动态岛(Dynamic Island)\n - 几乎成为标准配置,加强了交互体验,通知、音乐、来电更直观。\n\n缺点:\n\n1. 与Pro型号差距明显\n - 虽然处理器性能强,但在屏幕刷新率(依然是60Hz而非120Hz ProMotion)、材质(铝合金边框而非不锈钢)方面与Pro差距较大。\n2. 存储扩展仍然无解\n - 不支持存储卡扩展,256GB及以上版本价格较高。\n3. USB-C数据传输速率\n - 虽然接口升级,但数据传输速率依然为USB 2.0,远低于Pro机型(USB 3)。\n\n二、外观方面\n\n优点:\n\n1. 流线型设计\n - 机身更加圆润,边框做了微妙弧度处理,握持手感舒适。\n2. 轻薄\n - 重量控制得当,没有Pro型号那么厚重,日常携带更轻便。\n3. 颜色选择多样\n - 提供多种淡雅配色,适合不同用户风格。\n4. 前后玻璃工艺\n - 采用高强度彩色玻璃,外观质感更出色。\n\n缺点:\n\n1. 材质不及Pro\n - 边框依然是铝合金,不如Pro的钛合金或者不锈钢,高级感稍逊。\n2. 屏幕变化并不大\n - 屏幕依然没有高刷新率,观感提升有限;边框宽度也没有明显进步。\n3. 可辨识度降低\n - 由于外观变化不大,和iPhone 14差异较小,不易一眼识别新机。\n\n三、综合评价\n\niPhone 15是一次稳健升级,性能、拍照、充电、交互体验都有进步。对于普通用户来说,A16芯片和USB-C已经足够满足需求。外观虽有小幅调整,但整体辨识度和高级质感略逊于Pro系列。如你追求极致性能和更高端质感,建议考虑Pro型号;如需要轻薄、高性价比的新机,iPhone 15依然是不错选择。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 713, 'prompt_tokens': 35, 'total_tokens': 748, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-2025-04-14', 'system_fingerprint': 'fp_d9270d932a', 'id': 'chatcmpl-DsgiRrrj9C4odiFXkca1t9nor5Zr6', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019ee315-4417-7d62-91f7-79f76fedb3c8-0' tool_calls=[] invalid_tool_calls=[] usage_metadata={'input_tokens': 35, 'output_tokens': 713, 'total_tokens': 748, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}
2.2 Chains
之前涉及到的模型调用,解析器调用,最终都使用到了invoke方法,这是因为这些类都实现了 langchain最底层定义的Runnable接口,其代表了langchain中可以调用,批处理,流式传输,转换和组合的工作单元,是使用langchain组件的基础。
Runnable接口定义了一系列标准的方法
| invoke/ainvoke | 将单个输入转为输出 |
|---|---|
| batch/abatch | 批量将多个输入转为输出 |
| stream/astream | 从单个输入生成流式输出 |
统一的调用方式有什么好处?
如果没有统一的调用方式,每个组件的调用方式不同,组合的时候就需要手动适配:
prompt_text = prompt.format(topic='cat')
model_out = model.generate(prompt_text)
result = parser.parse(model_out)
如果使用了统一的调用方式
prompt_text`` = prompt``.invoke``({``"topic"``: ``"cat"``})
model_out`` = model``.invoke``(``prompt_text``)
result`` = parser``.invoke``(``model_out``)
所有实现了Runnable接口的组件,都可以通过一种特定的方法,将其连接起来,打包成一个可调用对象,这也就是Chain的由来,这种方式就成为LCEL
LECL(LangChain Expression Language),是一种从现有的Runnable构建新的Runnable的声明式方法, 用于声明,组合和执行各种组件(模型,提示,工具,函数等)
chain = prompt | model | paeser
result = chain.invoke({"topic": "cat"})
无论功能多么复杂,调用方式完全相同,并且可以通过管道符 | 组合, 自动处理类型匹配和中间结果传递
我们称使用LCEL创建的Runnable为“链”, “链”本身就是Runnable
LCEL两个主要的组合原语是 Runnable Sequence 和 RunnableParallel,许多其他的组合原语言可以当作是这两个原语的 变体
2.2.1 RunnableSequence 可运行序列
RunnableSequence 按顺序“链接”多个可运行对象,其中一个对象的输出作为下一个对象的输入
LCEL重载了 | 运算符,以便从两个 Runnables 创建 RunnableSequence
也就是说 chain = runnable1 | runnable2 等价于 chain = RunnableSequence([runnable1,runnable2])
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from model_io.llm_create import llm
prompt_template = PromptTemplate(
template="tell a story about {topic}",
input_variables=["topic"]
)
parser = StrOutputParser()
chain = prompt_template | llm | parser
resp = chain.invoke({"topic": "Little Red Riding Hood"})
print(resp)
2.2.2 RunnableParallel 可运行并行
RunnableParallel 同时运行多个可运行对象,并为每个对象提供相同的输入
对于同步执行,RunnableParaller 使用 ThreadPoolExecutor 来同时运行可运行对象,对于异步执行, RunnableParaller使用 asyncio.gather来同时运行可运行对象
构造 RunnableRarallar实例的时候, 参数列表是可变数量关键字参数,一个参数名对应着一个可运行组件,每个可运组件输出结果将作为参数名key所对应的值,封装到整个运行实例的结果中
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableParallel
from model_io.llm_create import llm_glm
english_chain = (
PromptTemplate.from_template('把这个句子{topic}翻译成英文') | llm_glm | StrOutputParser()
)
korean_chain = (
PromptTemplate.from_template('把这个句子{topic}翻译成韩文') | llm_glm | StrOutputParser()
)
map_chain = RunnableParallel(english=english_chain, korean=korean_chain)
resp = map_chain.invoke({"topic": "人工智能是一种智能技术"})
print(resp)
在LCEL当中,要想定义并行运行结构,只需通过字典的方式定义即可
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableParallel, RunnableLambda
from model_io.llm_create import llm_glm, llm_xiaomi_aihubmix, llm_qwen, llm_deepseek, llm_glm_4_5, llm_glm_4_6
# english_chain = (
# PromptTemplate.from_template('把这个句子{topic}翻译成英文') | llm_glm | StrOutputParser()
# )
#
#
# korean_chain = (
# PromptTemplate.from_template('把这个句子{topic}翻译成韩文') | llm_glm | StrOutputParser()
# )
#
# map_chain = RunnableParallel(english=english_chain, korean=korean_chain)
#
# resp = map_chain.invoke({"topic": "人工智能是一种智能技术"})
#
# print(resp)
paragraph_1_chain = (
PromptTemplate.from_template("对这首诗{poem}做一下赏析,分析它蕴含的含义") | llm_glm_4_5 | StrOutputParser()
)
paragraph_2_chain = (
PromptTemplate.from_template("对这首诗{poem}做一下赏析,分析它蕴含的含义") | llm_glm_4_6 | StrOutputParser()
)
summary_chain = (
PromptTemplate.from_template("对于诗句{poem}, 这两种赏析,第一种: {paragraph_1}, 第二种 : {paragraph_2}, 哪个比较好? 为什么?") | llm_deepseek | StrOutputParser()
)
poem= """
菩提本无树,
明镜亦非台,
本来无一物,
何处惹尘埃。
"""
map_chain = {
"paragraph_1": paragraph_1_chain,
"paragraph_2": paragraph_2_chain,
"poem": RunnableLambda(lambda x : x['poem'])
} | summary_chain
resp = map_chain.invoke({"poem": poem})
print(resp)
2.2.3 其他 Runnable 结构
-
RunnableLambda 将普通函数,封装成符合Runnable接口的可运行组件
-
RunnableBranch 对输入进行 if - else 判断,并路由到不同的函数中
-
RunnablePass through 接收输入并将其原样输出,是LCEL中的无操作节点,用于在流水线中透传输入或保留上下文,也可以向输出中添加键
-
RunnableWithFallbacks: 让Runnable失败后可以退回到兜底的Runnable

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)