AI Agent 三种记忆的工程落地
上一篇我们讨论代码解释器时,重点是受控执行:Agent 能做什么、在哪里做、失败后如何停下来。
再往前走,将会遇到一个新的问题:
Agent 应该记住什么?
做企业工单处理时,这个问题不是产品细节,而是系统边界。
用户昨天投诉过延迟发货,今天又来追问补偿;同一条退款政策上周刚调整;某个客户过去三个月有多次异常退货;一线客服已经给过一次人工备注;Agent 自己上一轮刚查过订单状态。
这些信息都可能影响处理结果,但它们不属于同一种“记忆”。
如果我们把它们全部追加到对话上下文里,Agent 很快会被旧信息、噪声和冲突事实拖住。如果我们只把它们丢进向量库,又会失去状态、权限、时效性和可审计性。
Agent 记忆不是一个存储插件,而是一套信息生命周期管理机制。工作记忆决定下一步怎么做,短期记忆保证当前任务不断线,长期记忆提供跨任务的背景和经验。
把这三者混成一个“memory”,是很多 Agent 项目后期失控的起点。
一、记忆不是一种东西,而是三种时间尺度
认知心理学里常说感觉记忆、工作记忆和长期记忆。我们不需要把心理学概念机械搬进系统设计,但这个分层很适合帮工程团队拆问题。
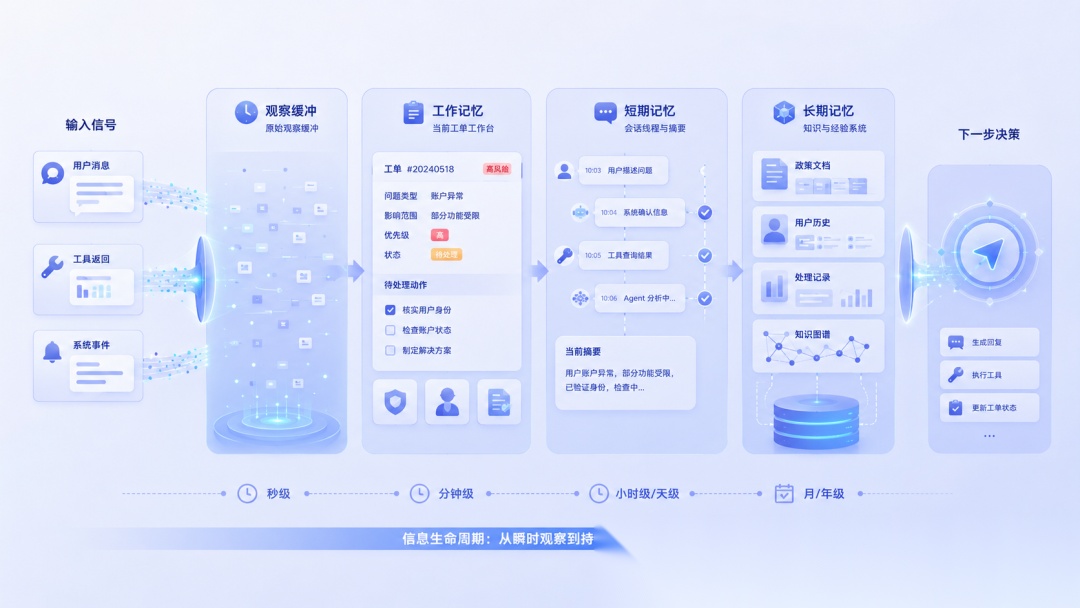
在企业工单 Agent 里,可以这样映射:
| 认知视角 | 工程映射 | 典型内容 | 生命周期 |
|---|---|---|---|
| 感觉记忆 | 原始观察缓冲 | 用户本轮输入、工具原始返回、系统事件 | 极短,只用于提取事实 |
| 工作记忆 | 当前决策状态 | 当前工单摘要、待处理动作、风险标记、最近证据 | 每一轮动态组装 |
| 短期记忆 | 会话 / 工单线程状态 | 当前工单处理过程、已查信息、已尝试动作、临时摘要 | 一个会话或一个工单周期 |
| 长期记忆 | 外部可检索记忆库 | 用户历史、政策知识、处理记录、组织经验 | 跨会话、跨任务持久化 |
这里特意把“感觉记忆”翻译成原始观察缓冲,而不是让它变成又一个数据库。因为大部分原始观察不应该长期保存,也不应该直接进入模型上下文。工具返回的完整 JSON、搜索引擎的原始结果、CRM 的完整用户档案,都更适合先被压缩成事实,再决定是否进入下一层。
这也是记忆系统的第一条边界:
不是所有被 Agent 看见的信息,都应该变成 Agent 的记忆。
比如处理一个延迟发货工单时,订单 API 可能返回几十个字段。Agent 当前真正需要的可能只有:
{
"ticket_id": "T-20260524-0831",
"intent": "shipping_delay_complaint",
"order_status": "in_transit",
"promised_delivery_date": "2026-05-21",
"current_date": "2026-05-24",
"delay_days": 3,
"customer_tier": "gold",
"risk_flags": ["second_contact_in_7_days"]
}
这份结构化事实可以进入工作记忆。原始订单对象、完整物流轨迹、客服系统的后台字段,不必全部塞进去。
记忆的工程化不是“多记一点”,而是决定一条信息应该在哪一层停留、以什么格式停留、什么时候被移出、谁有权改写它。
二、工作记忆:当前这一步需要什么证据
工作记忆是 Agent 的当前工作台。它不是历史记录,也不是知识库,而是本轮决策需要同时放在手边的事实。
企业工单 Agent 每一轮通常要做这几个判断:
- 用户真实意图是什么
- 当前工单处在哪个状态
- 已经查过哪些系统
- 需要哪些政策依据
- 下一步是回复、继续查询、提交审批,还是升级人工
- 本轮动作有没有权限和风险
因此,工作记忆最适合做成结构化状态,而不是一段自然语言摘要。一个简化版本可以长这样:
frompydanticimportBaseModel
classWorkingMemory(BaseModel):
ticket_id: str
user_intent: str
ticket_status: str
known_facts: list[str]
relevant_policy_ids: list[str]
pending_questions: list[str]
proposed_action: str|None=None
risk_level: str="low"
last_tool_observation: str|None=None
这段结构的重点不是字段完整,而是把“本轮要用来决策的东西”从聊天消息里拿出来。
如果 Agent 准备给用户发补偿方案,它不应该只凭上一轮自然语言记忆说“用户好像很着急”。工作记忆里应该有更可验证的证据:
{
"known_facts": [
"订单承诺送达日为 2026-05-21,当前已延迟 3 天",
"用户 7 天内第二次联系同一问题",
"当前物流状态为运输中,未显示丢件",
"延迟发货政策 policy://shipping-delay/current 命中"
],
"proposed_action": "offer_delay_coupon",
"risk_level": "medium"
}
这会直接影响工具选择。低风险时可以生成回复草稿;中风险时可能要先创建内部备注;高风险时必须请求人工审批。
工作记忆有两个常见坑。
第一个坑是把它做得太胖。工作记忆不应该常驻完整用户画像、完整政策文档、完整工单历史。它只保留当前决策需要的压缩事实。
第二个坑是让模型自由维护它。生产系统里,工作记忆应该由控制器和工具返回共同更新。模型可以建议“我认为这是二次投诉”,但是否写入 risk_flags,最好由规则、工具返回或审计过的分类器确认。
这不是不信任模型,而是保持状态可信。Agent 的语言输出可以有弹性,执行状态不能靠印象管理。
三、短期记忆:让一个工单线程不断线
短期记忆解决的是连续性问题。
用户不会按系统希望的方式一次性提供所有信息。他可能先说“物流怎么还没到”,过两分钟补一句“我上周已经催过一次”,客服主管可能中途加一条内部备注,Agent 可能已经查过订单、搜过政策、生成过一版回复草稿。
这些内容不一定值得长期保存,但在当前工单没有结束前,它们必须可恢复、可追踪、可继续使用。
短期记忆通常包含:
- 当前会话消息和用户补充信息
- 当前工单处理摘要
- 已调用工具和关键返回
- 失败尝试,例如某个政策检索没有命中
- 待确认事项,例如缺少订单号或需要人工审批
- 已生成但未发送的回复草稿
它适合用线程级状态、checkpoint 或工单生命周期内的临时存储来承载。LangChain / LangGraph 当前的官方抽象里,短期记忆就是 Agent state 的一部分,并通过 checkpointer 按线程持久化;这类设计很适合“当前会话可以暂停、恢复、继续执行”的场景。
工程上,短期记忆最好不要只是 messages 数组。我们至少需要一个可覆盖更新的摘要:
{
"thread_id": "thread_7f3a",
"ticket_id": "T-20260524-0831",
"summary": "用户投诉订单延迟 3 天且 7 天内第二次联系。已查询订单状态为运输中,命中延迟发货政策。当前缺少是否发放补偿券的审批结果。",
"checked_systems": ["ticket", "order", "policy"],
"open_items": ["等待主管审批补偿券"],
"draft_reply_id": "draft_912"
}
这份摘要应该随着状态变化被改写,而不是不断追加。
短期记忆最危险的地方,是旧状态污染新决策。比如 Agent 在 10:00 查询到物流状态是“运输中”,但 10:30 物流已经签收。如果短期记忆仍然把“运输中”当成当前事实,后续回复就会出错。
所以短期记忆里的事实要区分两类:
稳定事实:用户 7 天内第二次联系、曾经触发过人工审批
易变事实:订单状态、库存状态、优惠券是否已发放、工单当前状态
易变事实不能只靠记忆续命。每次执行关键动作前,都应该重新查询或校验。
这一点在工单系统里尤其重要。短期记忆负责让 Agent 不断线,但不能替代业务系统的当前状态。
四、长期记忆:不要把向量库当成全部答案
长期记忆是最容易被误解的一层。很多实现会直接等同为“把历史对话切 chunk,写入向量数据库”。这能做出一个像样的 Demo,但很难支撑真实业务。
企业工单 Agent 的长期记忆至少有四类。
**第一类是政策知识。**例如退款规则、延迟发货补偿标准、会员权益、升级处理 SOP。它们通常是组织级、版本化、只读或受控写入的知识,不应该让 Agent 在对话中随意改写。
**第二类是用户历史。**例如这个用户过去的投诉、补偿、风险标签、服务偏好。它和隐私、权限、保留期限直接相关,不能被简单当作“记住用户喜欢什么”。
**第三类是处理记录。**例如某类工单最终如何解决,人工为什么驳回 Agent 的建议,哪种回复模板更容易二次升级。这类记忆更像经验样本,可以用于后续检索、评测和流程改进。
**第四类是程序性经验。**例如“遇到政策冲突时先升级到 refund_review 队列”“无法确认收货责任时不要承诺现金补偿”。它不是用户事实,而是可复用的操作策略,通常应该由团队审核后沉淀。

这四类记忆适合的存储方式并不相同。
| 长期记忆类型 | 更适合的存储 | 不适合的做法 |
|---|---|---|
| 政策知识 | 文档库、版本库、向量索引、关键词索引 | 只存 embedding,不保留版本和来源 |
| 用户历史 | CRM、关系数据库、受控画像表 | 写进开放向量库,缺少权限隔离 |
| 处理记录 | 工单日志、事件表、可回放 trace | 只保存自然语言总结,无法审计 |
| 程序性经验 | Prompt / SOP / 技能文件、规则配置 | 让模型在对话中直接自我改写 |
向量数据库在这里很有价值,但它只解决一类问题:根据语义相似度召回可能相关的文本片段。它不负责事实权威性、时间有效性、权限、冲突处理和写入审计。
知识图谱或关系型结构也不是为了显得高级,而是用来表达向量检索不擅长的关系:
用户 A -> 拥有订单 O
订单 O -> 对应工单 T
工单 T -> 命中政策 P 的 2026-05-01 版本
政策 P -> 允许补偿类型 coupon,但不允许 cash_refund
主管 U -> 在审批单 R 中驳回 cash_refund
如果系统需要回答“为什么不能直接退款”,这条证据链比一段相似文本更可靠。
长期记忆的关键不是“存得久”,而是能回答三个问题:
这条记忆从哪里来?
现在是否仍然有效?
当前 Agent 是否有权使用它?
回答不了这三个问题,长期记忆就会从能力变成风险。
五、写入记忆比读取记忆更危险
读取记忆会带来误召回,写入记忆会带来污染。
很多 Agent 项目喜欢设计“自动学习”:用户说了什么,Agent 觉得有用,就写入长期记忆。这个能力听起来像智能,落到企业工单场景里却很危险。
用户说“你们上次答应给我免单”,不等于系统应该记住“该用户享有免单权益”。Agent 判断“这个客户情绪激动”,不等于可以写入长期风险标签。某次人工客服临时破例补偿,不等于形成新的政策规则。一次错误回复被用户接受,也不等于它应该成为未来样板。
所以写入记忆必须经过分类、校验和权限控制。
一个比较稳的流程是:
观察到新信息
-> 判断信息类型:事实、偏好、政策、处理经验、临时状态
-> 判断作用域:当前线程、当前工单、当前用户、组织级
-> 判断写入方式:自动写入、待审核写入、禁止写入
-> 记录来源、时间、证据和操作者
-> 后台合并、去重、过期或冲突检查
这时我们需要的不是一个随手 save_memory(text) 的工具,而是一个带元数据的记忆记录。
fromdatetimeimportdatetime
fromtypingimportLiteral
frompydanticimportBaseModel
classMemoryRecord(BaseModel):
scope: Literal["thread", "ticket", "user", "organization"]
memory_type: Literal["fact", "preference", "policy", "episode", "procedure"]
content: str
source: str
evidence_ids: list[str]
valid_from: datetime
valid_until: datetime|None=None
confidence: float
write_status: Literal["auto", "pending_review", "approved", "rejected"]
这里最重要的是 scope、memory_type、source、evidence_ids 和 write_status。
它们决定一条记忆能不能被复用,复用到哪里,是否需要人工审核。比如:
- 当前用户明确说“以后请优先邮件联系”,可以写成用户级偏好,但仍要允许用户修改和删除。
- 人工主管确认“本次延迟符合补偿券规则”,可以写入工单处理记录,但不能上升为组织政策。
- 多次工单显示某个政策条款容易误判,可以进入待审核的程序性经验,而不是让 Agent 直接改系统 Prompt。
写入记忆还要处理冲突。长期记忆里可能已经有一条“用户偏好短信联系”,现在用户说“以后发邮件”。系统应该更新、覆盖或标记版本,而不是让两条偏好同时在检索结果里打架。
六、LangChain 和 LlamaIndex 解决的是不同层面的记忆问题
框架能帮我们少造轮子,但不能替我们决定记忆边界。
从当前官方抽象看,LangChain / LangGraph 更贴近 Agent 运行时记忆。短期记忆通常是 Agent state 的一部分,通过 checkpointer 按线程保存;长期记忆则可以通过 store 按 namespace 和 key 保存 JSON 文档,并在工具或运行时里读取、写入。这个方向适合表达:
- 当前线程状态如何恢复
- 一轮工具调用后状态如何更新
- 不同用户或组织的记忆如何隔离命名空间
- Agent 执行过程中如何读写记忆
这和本文里的“短期记忆”非常贴近。比如当前工单处理到一半,Agent 等待主管审批补偿券;用户关闭页面后再回来,系统要从同一个线程状态恢复,而不是让模型凭历史摘要重新猜。
LlamaIndex 更贴近“记忆内容”和“知识存储”的表达。它的 Memory 抽象把短期消息和长期 MemoryBlock 分开:短期记忆可以按 token 限制保留最近消息,超出预算的内容可以被 flush 到长期记忆块;长期记忆块又可以用事实抽取、向量记忆等方式保存更稳定的信息。
这比泛泛地说“接一个向量库”更有解释力。放到工单场景里,LlamaIndex 的几个抽象可以对应到非常具体的设计:
- 短期消息缓存:保留当前用户和 Agent 最近几轮互动,避免每轮重新总结。
FactExtractionMemoryBlock:从对话中抽取可复用事实,例如“用户确认以后优先邮件联系”。VectorMemoryBlock:保存更长的历史片段或处理经验,用语义检索按需召回。ChatStore:把会话消息持久化,避免短期记忆只活在进程内。StorageContext:把 docstore、index store、vector store、property graph store 等存储拆开,承载政策文档、索引、向量和关系。
注意这里仍然要守住边界。FactExtractionMemoryBlock 可以帮我们抽取事实,但它不能决定这个事实是否有权写入用户画像;VectorMemoryBlock 可以召回相似历史,但它不能判断旧政策是否已经失效;StorageContext 可以组织存储,但它不等于记忆治理层。
所以不要简单问“记忆用 LangChain 还是 LlamaIndex”。更实用的分工是:
| 问题 | 更贴近的抽象 |
|---|---|
| 当前工单线程怎么暂停和恢复 | LangGraph state / checkpointer |
| Agent 工具调用后如何更新当前状态 | LangGraph state |
| 用户级长期偏好如何按命名空间保存 | LangGraph store 或业务数据库 |
| 最近对话如何受 token 预算控制 | LlamaIndex Memory |
| 会话事实如何抽取成长期记忆候选 | LlamaIndex MemoryBlock |
| 政策文档、索引、向量和图关系如何分层存储 | LlamaIndex StorageContext |
| 哪些记忆能写、谁来审核、如何审计 | 应用自己的记忆治理层 |
最后一行最关键。
LangChain 和 LlamaIndex 都不会自动知道某条工单备注能不能写进长期用户画像,也不会自动判断某份政策是否已经过期,更不会替我们完成隐私删除、审批审计和跨系统权限隔离。
框架可以承接中间很多实现细节,但系统设计必须先说清楚:哪类记忆属于谁,谁能读,谁能写,什么时候过期,冲突时听谁的。
七、把记忆系统做成可检查的工程边界
Agent 记忆最容易被讲成一个很诱人的能力:它能记住用户、记住历史、记住经验,甚至越用越懂业务。
工作记忆解决的是下一步怎么做,所以要短、准、结构化。短期记忆解决的是当前工单不断线,所以要可恢复、可覆盖、能区分稳定事实和易变状态。长期记忆解决的是跨会话复用,所以必须带来源、版本、权限、时效和审计。
Agent 的记忆能力,不取决于它记住了多少,而取决于它是否知道什么该临时放在工作台上,什么该随工单结束归档,什么才值得进入长期系统。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)