同样的模型,效果天差地别?揭秘 Claude Code、Codex、Kiro 背后的“上下文工程”
3年前,Karpathy 说过“最热门的新编程语言是英语”,他想表达的是,只要会写 Prompt,就算会 AI。如今,企业要的不再是Demo,而是稳定可投入生产的 Agent 产品——所以光会写提示词还远不够,你得学会给 AI 搭运行环境。(这也是 Agent 开发的重难点)
同样的模型,为什么效果天差地别❓
先看几个案例:
- LangChain 团队做过一个实验:同一个模型,一行模型代码没改,只调整了模型周围的系统,在 Terminal Bench 2.0 上的得分从 52.8% 跳到了 66.5%,排名从前 30 直接冲进前 5。
- Stripe 的内部编程 Agent “Minions” 每周自动产出超过 1000 个合并的 PR。
- OpenAI 用 Codex 在 5 个月内从零构建了一个百万行代码的生产级应用,工程师没写一行代码。
反映了一个共性:差距不在模型,而在模型周围的那一整套工程系统。
这篇文章不打算讲基础概念。我想从当下主流 AI Coding工具(Claude code、Codex、Kiro)的实践中,提炼出上下文工程的5个核心策略——这些策略不绑定任何特定产品,理解了这些,才能算真正入门了 AI Agent。
策略1:分层上下文 —— 不同信息在不同时机出场
上下文工程中最基本的策略:不要把所有信息一股脑塞进去,而是分层组织、分时加载。
为什么呢?因为上下文窗口不是越满越好。塞太多信息,模型反而会"幻觉"——性能下降、成本飙升、关键信息被淹没。
业界的做法已经高度一致:
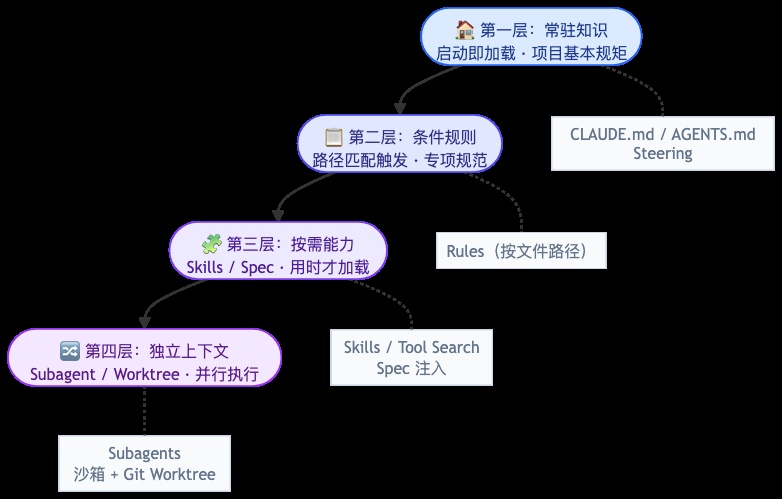
- 第1层:常驻知识 —— 启动即加载的"基本常识"
Claude Code 叫 CLAUDE.md,Codex 叫 AGENTS.md,Kiro 叫 Steering 文件(放在 .kiro/steering/ 目录下)。名字不同,作用一样:告诉 AI “这个项目的基本规矩是什么”——用什么包管理器、代码风格如何、提交前要跑什么检查。
每次启动(发送请求)都自动加载,不用你反复说一样的提示词。
- 第2层:条件规则 —— 触发时才出现的"专项指南"
不是所有规范都需要常驻。Claude Code 的 Rules 可以绑定文件路径——比如只有操作 .sh 文件时才加载 Shell 编码规范,操作 React 组件时才加载组件规范。平时不出现,不占窗口空间。
- 第3层:按需加载 —— 用时才加载的"能力包"
Claude Code 和 Codex 的 Skills、Kiro 的 Spec 注入都属于这一层。它们把特定任务的指令、资源、脚本打包成一个能力包——平时隐身,模型判断需要时才加载。这一层的细节会在策略2 “按需发现”中展开。
- 第4层:独立上下文 —— 大任务要拆给多个子 Agent 干
当任务太重时,一个上下文窗口装不下。Claude Code 用 Sub-Agent,Codex 用沙箱 + Git Worktree——每个子任务在独立的上下文窗口(甚至独立的文件系统)中运行,干完活再通过 PR 合回来。
这就像团队 leader 把任务分配给不同同事,每人有自己的独立工作空间,最后汇总成果,目的还是把活儿拆小,互不影响,最终把活儿干完干好。
策略2:按需发现 —— 别让"工具描述"腐败上下文
分层上下文解决了“什么时候加载什么”。但还有一个问题:有些东西实在太多了,分层也装不下。
最典型的就是工具定义。随着 MCP 生态爆发,一个 Agent 能接入几十甚至上百个工具。我们团队就内部测过:5 个 MCP Server、58 个工具,光定义就吃掉 55K tokens。再加几个就轻松突破 100K。对话还没开始,上下文已经满了一大半。
Claude Code 的解法是 Tool Search Tool:启动时只加载一个"搜索工具"本身(约 500 tokens),其余工具标记为 defer_loading: true。Agent 需要什么能力时,先搜索,再按需加载匹配的工具定义。上下文占用从 77K 降到 8.7K,减少 85%。更妙的是,工具选择准确率反而从 49% 提升到了 74%——信息少了,干扰也少了。
Codex 和 Kiro 的 Skills 机制思路类似——把特定任务的指令、资源、脚本打包成能力包,用时加载,不用时隐身。
Kiro 在 Spec-Driven 流程中还有一个巧妙的应用:当执行任务清单中的某一项时,自动把相关的需求文档和设计文档注入上下文。AI 写每一行代码时,面前都摆着用户故事、验收标准和 API 定义——不是全部文档,而是跟当前任务相关的那一份。
核心原则:让 Agent 在拥有大量能力的同时,不被这些能力的描述淹没(前面文章讲过的CLIs也是同理,目的是减少上下文腐败)。
策略3:确定性约束 —— 别指望模型"记得住",用工程强约束
前两个策略都是关于“给模型看什么”。但有些事情,不能靠“看”来保证——而需要工程手段强制约束。比如不想让 AI 的删除文件,则执行删除 Bash 就直接报错等。
这是上下文工程和提示工程最本质的区别。提示工程说"请你遵守规范",上下文工程说"我不管你记没记住,反正系统会强制检查"。
不同产品的切入点各有不同,但思路一致:
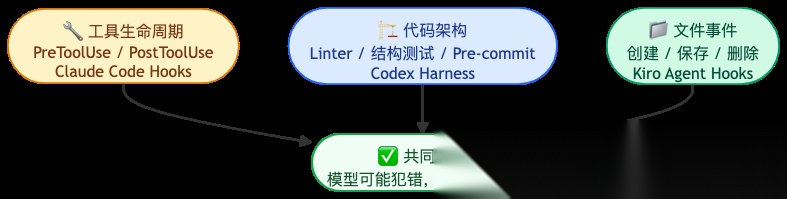
- Claude Code — 面向工具生命周期的 Hooks
Claude Code 允许你在工具调用的前后插入脚本:PreToolUse 在执行前触发 (比如检查 Bash 命令有没有 rm -rf),PostToolUse 在执行后触发 (比如每次编辑文件后自动跑 lint) 。通过 matcher 字段控制哪些工具触发——"Bash" 只拦 shell 命令,"Edit" 只拦文件编辑。
- Codex — 面向代码质量的架构约束
Codex 的 Harness Engineering 框架走得更远:确定性 Linter 自动标记违规、结构测试强制依赖只能单向流动(Types → Config → Repo → Service → Runtime → UI)、Pre-commit 钩子在提交前拦截。不是建议,是红线。
- Kiro — 面向文件事件的 Agent Hooks
Kiro 的切入点是 IDE 文件事件——保存文件时自动更新单元测试,修改 API 定义后自动同步文档,新增代码文件时自动检查规范合规性。
三种切入点,一个道理:模型可能会遗忘,但工程规则不会忘。 这和 CI/CD 流水线的哲学完全一致——不管谁提交代码,定义的规则照跑不误。
小结:约束越多,Agent 反而越高效。 当 Agent 可以生成"任何东西"时,它会浪费 token 去探索死路。当边界被清晰定义后,Agent 能更快收敛到正确的解决方案。这也就是最近比较火的 Harness 工程核心思想。
策略4:记忆管理 —— 工作记忆和长期记忆要分开治
LLM 的上下文窗口就是它的“工作记忆”——有限、昂贵、越满越幻觉。一个 Agent 跑 50 步的复杂任务,到后面基本就忘了开头在干嘛。
这不是模型笨,是记忆管理没做好。
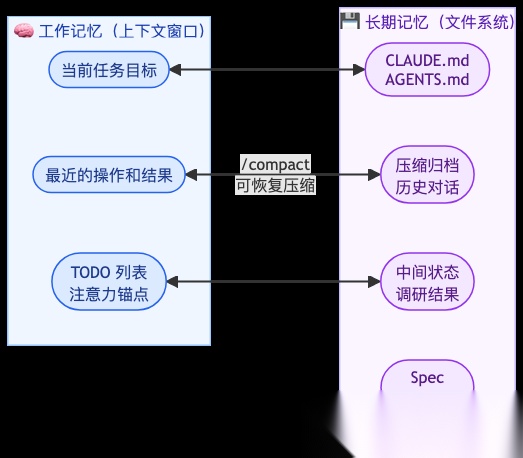
业界摸索出了几个关键策略:
- 压缩但不丢失
Claude Code 的 /compact 命令会压缩对话历史,只保留精炼摘要。但关键设计是:压缩是可恢复的——原始信息存到文件系统,需要时随时取回。就像整理桌面——归档到抽屉里,不是扔垃圾桶。
- 文件系统就是最好的"外部大脑"
Codex 的每个 Agent 在独立沙箱和 Git Worktree 中运行,中间状态随时写到文件里。上下文窗口负责"此刻在想什么",文件系统负责"之前做过什么"——两者分工协作,突破 128K 窗口的物理限制。
这是 Agent 产品普遍采用的策略。不止 Codex——Claude Code 的 Skills 也可以引用外部文件和脚本,Kiro 的 Steering 和 Spec 文档本质上都是文件系统中的持久化上下文。
- 用 TODO 列表"操控"注意力
这是一个被行业反复验证过的技巧:让 Agent 在每一步之后更新一个 task.md,把全局计划不断推到上下文末尾。这利用了 Transformer 架构的特性——最近位置的信息权重更高。一个 50 步任务中,不断“复述”目标,能有效避免跑偏。
- 保留错误,别擦掉
直觉上,Agent 出错后应该清除痕迹重来。但实践证明恰恰相反——把错误留在上下文里,模型看到之前的失败操作和错误堆栈,会隐式降低重复犯错的概率。就像人学骑自行车,摔过的跤比看的教程管用。
策略5:熵管理 —— 别让代码库慢慢"腐烂"
前面4个策略都是关于“单次任务怎么做好”。但如果 Agent 持续工作,代码库会渐渐积累“熵”——文档和现实脱节、命名约定漂移、死代码堆积、循环依赖冒出来。
OpenAI 在 Harness工程 实践中给出的解法是:用专门的 Sub-Agent 定期巡逻。
•文档一致性 Agent——验证文档是否和代码匹配•约束违规扫描器——寻找溜过早期检查的代码•模式强化 Agent——识别并修复偏离既定模式的情况•依赖审计 Agent ——追踪并解决循环依赖
这些 Agent 按计划运行(每天、每周或由事件触发),保持代码库对人类和未来 AI 都是健康可读的。
这个思路其实和 Kiro 的 Agent Hooks 有异曲同工之处——Kiro 是在文件变更时实时触发检查,Codex 是定期批量扫描。一个是“实时质检”,一个是“定期体检”,互为补充。
从 Vibe Coding 到 Spec Driven:为什么范式在转变?
理解了这5个核心策略,再来看当下最热的争论——Vibe Coding 为什么正在被 Spec-Driven Development (SDD)取代?——答案就清楚了。
Vibe Coding 用来做原型确实很爽。但它有四个致命问题:上下文会丢失(对话长了就忘了之前的设计决策)、需求会漂移(每次对话都在"重新协商")、代码不可维护(没人理解那些代码为什么是这样)、团队无法协作(你脑子里的 vibes 没法传给别人)。
本质上,Vibe Coding 缺的不是更好的 Prompt,而是上下文工程的全部5个核心策略。
AWS 推出的 Kiro(底层使用 Claude Sonnet 4)代表了行业的回答:Spec-Driven Development。它的流程是 Requirements → Design → Tasks → Implementation,每一步都生成结构化文档。但关键不在流程本身,而在于:
•Spec 文档就是分层上下文(策略1)——需求归需求,设计归设计,任务归任务•执行任务时自动注入相关 Spec(策略2)——按需加载,不是全部塞进去•Agent Hooks 在文件事件时自动检查(策略3)——确定性约束•Steering 文件提供持久项目知识(策略4)——跨会话、跨成员的长期记忆•5-7 倍成本差异——AWS 研究表明,规划阶段解决问题的成本远低于开发阶段
| 维度 | Vibe Coding + Prompt Engineering | Spec Driven + Context Engineering |
|---|---|---|
| 核心依赖 | 模型的"直觉" | 结构化的信息编排 |
| 上下文管理 | 靠对话历史自然积累 | 分层、按需、压缩、持久化 |
| 可复现性 | 低,换个人可能出不来 | 高,Spec 和配置都可版本控制 |
| 适用场景 | 原型、小工具、个人项目 | 生产级应用、团队协作、长期维护 |
| 错误处理 | 重试、重新问 | 保留错误上下文,Agent 自我修正 |
| 扩展性 | 受限于单次对话 | 文件系统、子代理、外部记忆 |
❗️❗️一句话:Vibe Coding 是个人的冲刺,Spec Driven 才是团队的马拉松。
写在最后
AI 时代变得真的太快了,上下文工程也不是什么颠覆性的新概念,但它绝对是一个这个领域的一个重难点。它更像是软件工程思维在 AI 时代的自然延伸——当你的“员工”是一个概率模型时,怎么保证它拿到了足够的、正确的、格式友好的信息来做出好的决策?
回顾一下上面5个核心策略:

这些策略不绑定任何特定产品。无论你用的是 Claude Code、Codex、Kiro、Cursor 还是别的什么工具,背后的原理是相通的。
下次当你觉得 AI “不好用”的时候,别急着换模型或改 Prompt。先想想:你给它的上下文,够不够好?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 2
2 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)