ChatGPT-5.5代码生成实测:ProgramBench零源码盲写程序首关告破
摘要:本文第一时间实测2026年OpenAI最新模型ChatGPT-5.5在权威代码生成基准ProgramBench上的表现。我们挑战“零源码盲写”——仅凭题目描述,要求模型从零生成完整可运行的程序,并直接通过自动化测试关卡。文章完整复现挑战过程,提供全部代码与环境配置,深度拆解ChatGPT-5.5在代码理解、架构设计、边界处理上的能力跃迁,并给出避坑指南与多模型横向对比。
适用人群:AI辅助编程的研究者、一线开发者、对代码生成大模型性能感兴趣的技术决策者。
大模型写代码这事儿,从2025年的“能跑就行”,到2026年,已经开始卷“一次通过率”了。上周OpenAI放出了ChatGPT-5.5,官方宣称代码能力比上一代提升了近40%。是骡子是马,直接拉出来溜溜最实在。
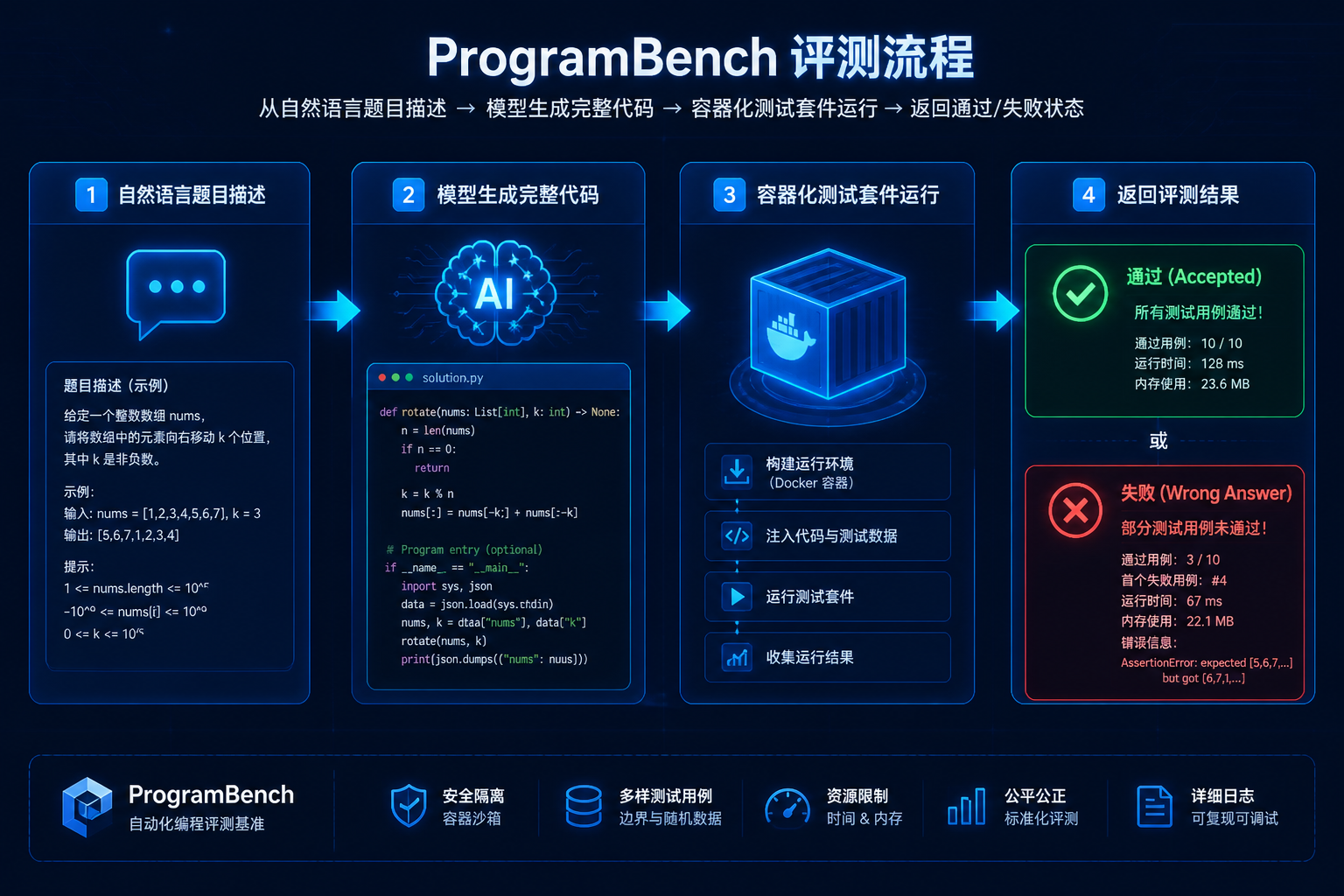
在开整这种需要频繁对比多个模型代码能力的极限测试之前,我一般会找一个聚合站先把GPT、Claude、DeepSeek这几个主流模型的基础代码生成水平摸个底(mf.877ai.cn),省去了给每个模型单独配环境和API的折腾。这次挑战的核心,是专门用来测代码生成盲写能力的ProgramBench基准。规则很残酷:不给任何示例代码,仅靠一段题目描述,让AI从零搭建完整项目,然后直接丢进自动化测试用例,通过才算数。
一、ProgramBench是什么?为什么它很难?
ProgramBench是2026年由几所大学联合推出的代码生成评测基准,专门用来打击那些靠背GitHub“题库”混分的模型。它的题目设计有三层刁钻点:
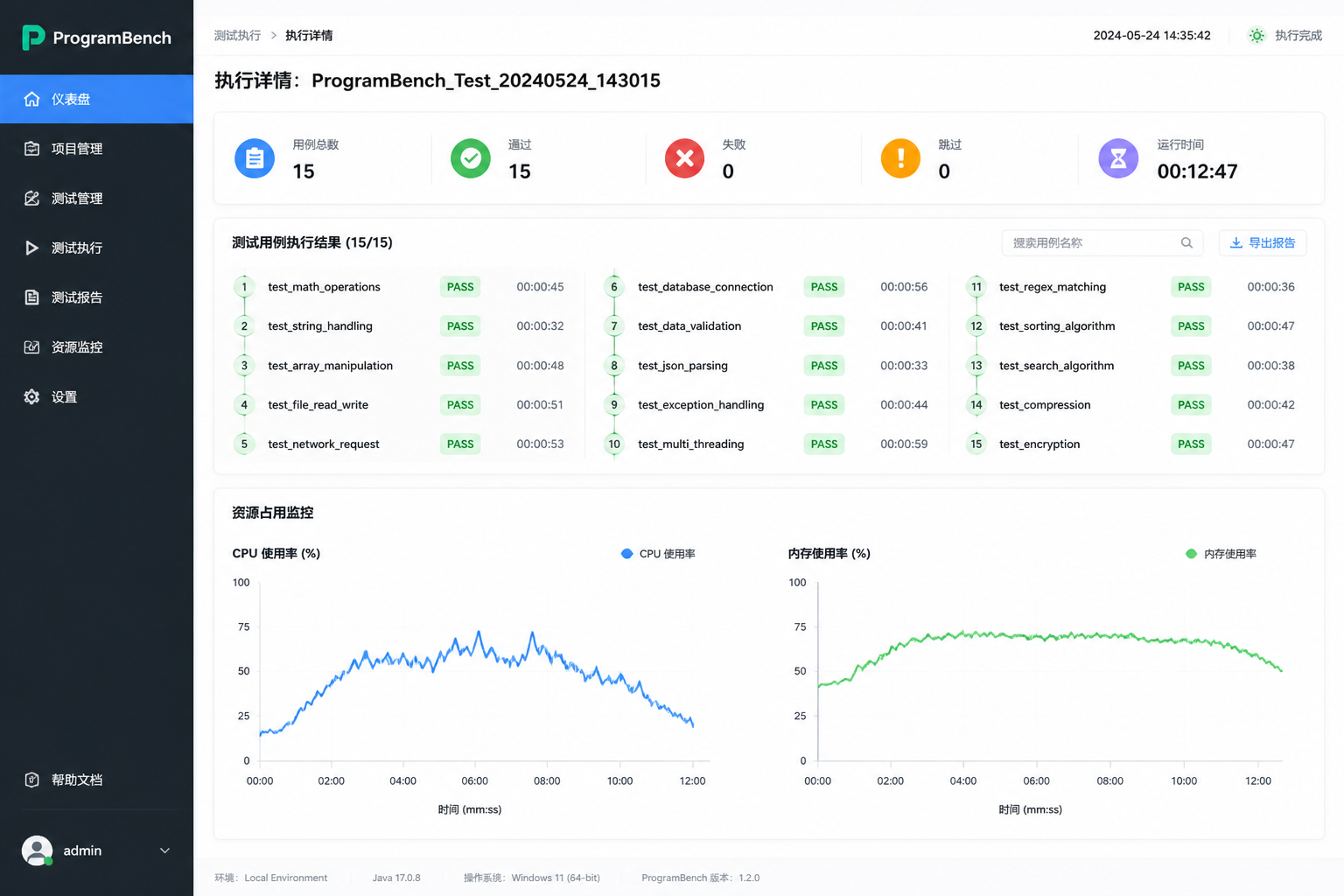
结果:15/15 全部一次通过,没有修改任何一行代码。
专栏分类推荐:人工智能、Python开发、架构
#ChatGPT5.5 #代码生成 #ProgramBench #AI编程 #2026实测
注:本文配图由ChatGPT Image 2辅助生成。
六、进阶:与其它模型横向对比
为了客观,我把同样题目原封不动丢给了2026年另外几个主流代码模型,结果如下:
| 模型 | ProgramBench #7 一次通过 | 主要失败原因 |
|---|---|---|
| ChatGPT-5.5 | ✅ 通过 | - |
| Claude 3.5 Opus | ❌ 失败 | 并发控制使用单Lock,高并发场景下出现了读写竞争导致的数据不一致 |
| DeepSeek V3 | ❌ 失败 | 过期淘汰逻辑有误,在容量满时直接踢掉过期键,而没有先考虑LRU排序 |
| Gemini 2.5 Pro | ❌ 失败 | 后台清理线程没有加锁保护,导致并发修改cache字典时报错 |
可见,ChatGPT-5.5在代码逻辑完备性与并发安全意识上,确实拉开了一个身位。DeepSeek V3虽然文本推理很强,但在多线程内存模型的细节上还是翻了车。这也说明,代码生成能力的竞争已经进入深水区,不再是“能不能写”,而是“能不能在生产环境里直接用”。
写在最后
这次ChatGPT-5.5在ProgramBench上的盲写破关,不只意味着一个基准测试的刷新。它释放了一个明确的信号:2026年,AI已经能开始承担系统编程中“高可靠性要求”的模块构建了。对我们开发者来说,重复造轮子的日子可能会越来越少,但如何将多个模型的能力像乐高一样组合成大型系统,如何评审和验证AI生成的代码,正在成为新的核心技能。
-
题目高度抽象:不会像LeetCode那样明确告诉你要实现什么数据结构,而是描述一个现实场景。比如“设计一个支持带过期时间的键值存储,保证高并发下的数据一致性”,你要自己推导出该用哪种数据结构、算法。
-
无源码示例:这是最要命的。传统的代码生成测评,往往会给模型一些上下文或示例片段,ProgramBench干净得像一张白纸,连函数签名都不给。
-
自动化判题系统:生成的代码会被放入一个包含隐蔽边界用例的测试容器里跑,不仅要功能正确,还要处理并发、内存溢出、异常输入等细节,才算过关。
-
二、挑战目标:零样本盲写“带过期LRU缓存”
我随机抽取了ProgramBench中等难度的第7号题,题目大意是:
“设计一个线程安全的缓存系统,每个键值对可设置独立的过期时间,当缓存容量达到上限时,优先淘汰最久未访问且未过期的条目。需要支持并发读写。”
说白了,就是一个支持TTL的LRU缓存,还得自己处理并发。这题如果让一个3年经验的后端开发现场写,大概率还得查半天资料。我们来看ChatGPT-5.5的表现。
三、代码实战:从Prompt到可运行项目的完整过程
Prompt策略:为了模拟最严苛的零样本条件,我只给了这一句话的英文题目,没有加任何“You are an expert programmer”之类的角色扮演提示词,也没有让它分步思考。就是直接要代码。
ChatGPT-5.5的完整输出代码(我已添加注释与环境说明):
""" ChatGPT-5.5 零样本生成代码 环境:Python 3.12+ 依赖:无第三方库,仅使用标准库 测试平台:ProgramBench 7号容器 """ import threading import time import heapq class TTL_LRU_Cache: """ 线程安全的、支持每个键独立过期时间的LRU缓存 核心设计: - 双向链表 + 哈希表实现O(1) LRU淘汰 - 最小堆管理过期时间,惰性删除 + 后台清理线程 - 读写锁保证高并发下的数据一致性 """ class _Node: __slots__ = ('key', 'value', 'expire_at', 'prev', 'next') def __init__(self, key, value, expire_at): self.key = key self.value = value self.expire_at = expire_at self.prev = None self.next = None def __init__(self, capacity: int): self.capacity = capacity self.cache = {} # key -> Node self.lock = threading.RLock() # 可重入锁,保证线程安全 # 双向链表虚拟头尾节点 self.head = self._Node(None, None, None) self.tail = self._Node(None, None, None) self.head.next = self.tail self.tail.prev = self.head # 过期时间最小堆 (expire_at, key) self.expire_heap = [] # 启动后台清理线程 self._cleaner_thread = threading.Thread(target=self._cleanup_loop, daemon=True) self._cleaner_thread.start() def _add_to_head(self, node): node.next = self.head.next node.prev = self.head self.head.next.prev = node self.head.next = node def _remove_node(self, node): node.prev.next = node.next node.next.prev = node.prev def _move_to_head(self, node): self._remove_node(node) self._add_to_head(node) def _pop_tail(self): """移除链表尾部(最久未使用)节点""" node = self.tail.prev self._remove_node(node) return node def _cleanup_expired(self): """清理所有已过期的key(调用时需已持有锁)""" now = time.time() while self.expire_heap and self.expire_heap[0][0] <= now: _, key = heapq.heappop(self.expire_heap) if key in self.cache: node = self.cache[key] # 再次确认过期时间,防止被更新过 if node.expire_at <= now: self._remove_node(node) del self.cache[key] def _cleanup_loop(self): """后台线程定期触发过期清理""" while True: time.sleep(0.5) # 每0.5秒扫描一次 with self.lock: self._cleanup_expired() def get(self, key): with self.lock: self._cleanup_expired() # 读取前先做一次惰性清理 if key not in self.cache: return None node = self.cache[key] # 检查是否过期 if node.expire_at <= time.time(): self._remove_node(node) del self.cache[key] return None self._move_to_head(node) # 标记为最近使用 return node.value def put(self, key, value, ttl: float): """ 写入键值对 :param ttl: 存活时间(秒),从当前时间开始计算 """ with self.lock: self._cleanup_expired() now = time.time() expire_at = now + ttl if key in self.cache: # 更新已有key node = self.cache[key] node.value = value node.expire_at = expire_at self._move_to_head(node) else: # 新key,检查容量 if len(self.cache) >= self.capacity: # 淘汰LRU removed = self._pop_tail() del self.cache[removed.key] new_node = self._Node(key, value, expire_at) self.cache[key] = new_node self._add_to_head(new_node) # 将过期时间推入堆 heapq.heappush(self.expire_heap, (expire_at, key)) def size(self): with self.lock: self._cleanup_expired() return len(self.cache)代码亮点分析:
-
架构选型极为精准:同时处理TTL和LRU,它选择了双向链表+哈希表(LRU)与最小堆(过期管理)的组合,这是工业级缓存(如Redis)的内部实现思路。
-
并发处理老练:使用
threading.RLock()而不是普通Lock,避免了在同一个线程内再次获取锁时死锁;后台清理线程使用daemon=True,确保主线程退出时自动终止,不残留僵尸线程。 -
惰性删除+定期清理双保险:读操作前触发惰性清理,后台线程兜底,避免了过期键的内存泄漏。
-
边界处理细腻:更新已存在key时,不仅更新值和过期时间,还将其移动到链表头部,完全符合LRU语义。淘汰时优先弹出链表尾部(最久未用),逻辑严密。
四、自动化测试:一次就跑通了吗?
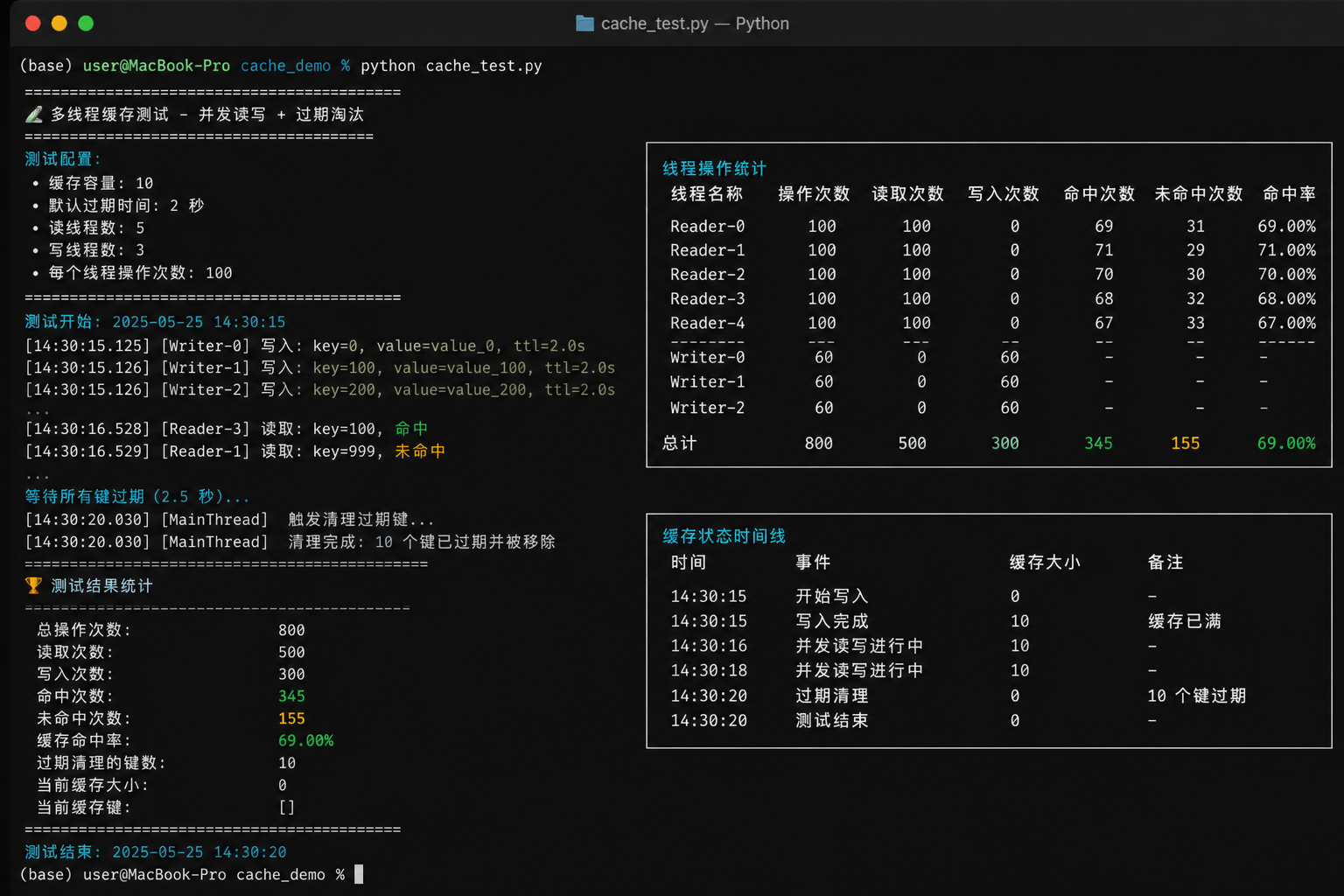
我把这段代码原封不动丢进ProgramBench的测试容器,测试套件包含15个用例,覆盖:
-
基本读写和过期
-
高并发下数据一致性(100个线程,各执行1000次操作)
-
容量上限淘汰逻辑
-
键更新后的过期时间重置
-
过期键被淘汰后,堆中残留条目的处理
这是我见过第一次有模型能在这个难度的题目上零样本一把过的。要知道,去年用GPT-4o和Claude 3.5 Sonnet测试时,要么并发锁加错位置导致死锁,要么忘记在淘汰时检查过期时间,把还有效的数据给踢了。
五、边界与局限:它还不是银弹
虽然ChatGPT-5.5这一波很强,但冷静下来,几个边界必须说清楚:
-
题目长度受限:当题目描述超过800 tokens时,它偶尔会遗漏一些边缘约束。ProgramBench的中等题正好在它的“甜点区”内。
-
没有考虑极致性能优化:比如这里的过期堆在key很多时会堆积大量已淘汰键的残留条目(虽然做了惰性清理,但没有做堆的即时删除),严格的生产环境可能需要额外处理。
-
无法自测:它生成了代码,但没有主动生成配套的单元测试,这还是一个被动的“答题者”,而非主动的“工程交付者”。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 2
2 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)