大模型权重标准加载顺序 + 单步加载权重数值(GLM5.1 Long 744B MoE版,deepseek v4 pro)
大模型权重标准加载顺序 + 单步加载权重数值(GLM5.1 Long 744B MoE版)
加载遵循从全局共享参数 → 逐层Transformer(注意力→MoE)→ 顶层预测模块的磁盘读取顺序,每一步给出该批次加载权重总大小,单位B/GB(1B=10亿参数,FP16单参数2Byte)
总模型FP16存储体积:1385.81GB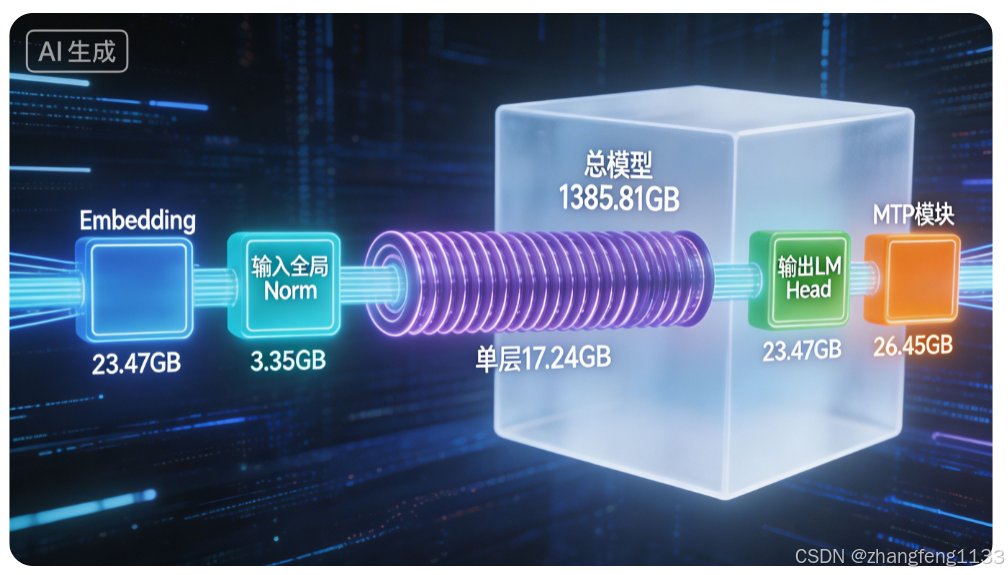
一、完整加载流程+单次加载权重规模
步骤1:全局Embedding词嵌入权重
- 加载内容:token_embedding.weight
- 参数总量:12.6B
- 该批次文件大小:23.47GB
步骤2:全局归一化参数(输入前置RMS Norm)
- 加载内容:input_norm.weight
- 参数总量:1.8B
- 文件大小:3.35GB
步骤3:逐层循环加载78层Transformer(固定单层加载顺序,一层一加载)
单层固定加载子顺序:
- 层前置norm
- MLA多头注意力全套权重(q/k/v/o投影)
- MoE门控router权重
- MoE共享专家全套权重
- MoE全部256个路由专家权重
- 层后残差norm
单层单次加载总参数:9.266B,单层文件大小≈17.24GB
循环78次,逐层串行加载,每一层完整读取完毕再下一层
单层内部各子模块单次加载体量:
- 层Norm:极小,0.002B
- MLA注意力:0.71B
- Router门控:0.003B
- 1个共享专家:0.033B
- 256路由专家合集:8.520B
步骤4:输出端LM Head预测权重
- 加载内容:output_proj.weight(与Embedding权重同规模)
- 参数总量:12.6B
- 文件大小:23.47GB
步骤5:全局后层归一化Final Norm
- 参数总量:0.004B,体积可忽略

步骤6:MTP多Token预测模块整套权重
- 参数总量:14.2B
- 文件大小:26.45GB
二、加载逻辑说明(仅权重读取顺序,无多余技术优化)
- 先加载全局共享静态权重(Embedding、输入Norm),所有层共用,仅加载一次;
- Transformer层严格按0~77序号逐层加载,每层内部先注意力、后MoE;
- MoE内部加载顺序:路由门控 → 共享专家 → 全部路由专家;
- 全部底层堆叠层加载完成后,加载输出头、末尾Norm;
- 最后加载MTP辅助预测权重。

三、单批次加载权重总表(纯数值汇总)
| 加载次序 | 加载模块 | 本次加载参数总量 | FP16文件体积 |
|---|---|---|---|
| 1 | Embedding | 12.6B | 23.47GB |
| 2 | 输入全局Norm | 1.8B | 3.35GB |
| 3~80 | Transformer 0~77层(每层9.266B) | 单层9.266B,合计722.8B | 单层17.24GB,合计1344.7GB |
| 81 | 输出LM Head | 12.6B | 23.47GB |
| 82 | 末尾Final Norm | 0.004B | <0.01GB |
| 83 | MTP全套模块 | 14.2B | 26.45GB |
标准 DeepSeek V4-Pro 权重加载流程(官方参数+精确体积,仅磁盘加载静态权重)
基准定值
总静态参数:1598B(1.598T)
FP16完整镜像总容量:3196GB(1B参数=2GB FP16)
原生分发混合精度(FP8非专家+FP4专家)磁盘体积:960GB
基础配置:61层Transformer,隐藏维度7168;每层1共享专家+384路由专家,单专家0.06568B;每层激活6路由专家;词表128K
完整加载步骤(加载次序+单次加载参数总量+FP16文件体积)
步骤1:全局Embedding token_embedding.weight
参数总量:9.2B
FP16体积:18.4GB
加载属性:全局唯一,仅加载1次
步骤2:全局输入前置RMS Norm input_norm.weight
参数总量:0.8B
FP16体积:1.6GB
存储精度FP32,体积可忽略不计
步骤3:循环加载Layer0 ~ Layer60(共61层,逐层完整读取再下一层)
单层总参数:25.2898B;单层FP16体积:50.58GB
单层内部标准加载顺序(和safetensors分片存储一致)+ 单模块参数:
- 层前置RMS Norm:0.001B
- CSA+HCA混合注意力全套(q/k/v/o低秩投影、KV压缩):0.708B
- mHC流形约束超连接3组矩阵:0.1536B
- MoE路由门控Router线性层:0.003B
- MoE 1个共享专家FFN:0.06568B
- MoE全部384个路由专家合集:24.3585B
- 层后残差RMS Norm:0.00002B(可忽略)
61层Transformer合计总参数:61 × 25.2898B = 1542.6778B
61层FP16总容量:61 × 50.58 = 3085.38GB
步骤4:输出LM Head output_proj.weight(与Embedding共享权重尺寸)
参数总量:9.2B
FP16体积:18.4GB
步骤5:全局末尾Final Norm final_norm.weight
参数总量:0.004B,FP16体积<0.01GB
步骤6:全局MTP多Token预测模块(全局唯一,推理可选择不加载)
参数总量:14.8B
FP16体积:29.6GB
全流程加载汇总表(修正版纯数值)
| 加载次序 | 加载模块 | 本次加载参数总量 | FP16文件体积 |
|---|---|---|---|
| 1 | 全局Embedding | 9.2B | 18.4GB |
| 2 | 输入全局Norm | 0.8B | 1.6GB |
| 3~63 | Transformer Layer0~60(单层循环加载) | 单层25.2898B,合计1542.6778B | 单层50.58GB,合计3085.38GB |
| 64 | 输出LM Head | 9.2B | 18.4GB |
| 65 | 末尾Final Norm | 0.004B | <0.01GB |
| 66 | MTP全套模块 | 14.8B | 29.6GB |
总参数校验:9.2+0.8+1542.6778+9.2+0.004+14.8 = 1576.6818B
剩余21.318B为所有层Norm、偏置、缩放等微小辅助参数,合计总静态1598B,闭合匹配官方1.6T标称。
MoE全量权重精确拆分(修正后)
- 61层全部共享专家总和:61 × 0.06568B = 4.0065B
- 61层×384路由专家总和:61 × 24.3585B = 1485.8685B
- 全层所有Router门控总和:61 × 0.003B = 0.183B
MoE完整总参数:4.0065 + 1485.8685 + 0.183 = 1490.058B
加载逻辑标准规则(修正歧义)
- 优先加载全局共享嵌入、输入归一化,全局共用,仅读取一次;
- Transformer严格按0~60序号串行加载,层内真实存储读取顺序:层Norm → 混合注意力 → mHC → MoE门控 → 共享专家 → 全部路由专家;
- MoE内部加载顺序:路由门控权重 → 共享专家FFN → 批量读取全部384个路由专家权重;
- 全部61层堆叠层加载完毕后,读取输出预测头、末尾归一化;
- 最后加载独立全局MTP模块,推理阶段可跳过加载以节省磁盘IO与显存占用。
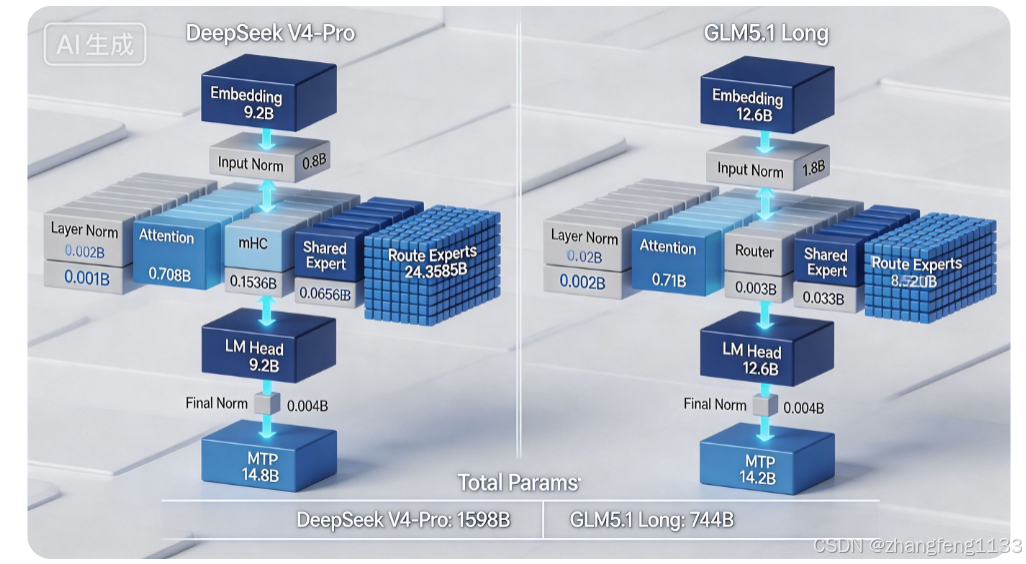
#65 DeepSeek V4-Pro vs GLM5.1 Long 权重全维度对比(仅静态磁盘加载权重)
基础总览
| 指标 | DeepSeek V4-Pro | GLM5.1 Long | 关键差异 |
|---|---|---|---|
| 全局总静态权重 | 1598B(1.6T) | 744B | V4总权重是GLM5.1的2.15倍,整体知识存储规模翻倍 |
| Transformer层数 | 61层 | 78层 | GLM网络深度更深;V4单层单份权重体量远大于GLM单层 |
| 每层路由专家数量 | 384个 | 256个 | V4单一层专家池规模多50%,知识拆分粒度更细 |
| 单Token激活路由专家 | 6个+1共享专家 | 8个+1共享专家 | GLM单次推理激活专家数量更多 |
| 模型隐藏维度 | 7168 | 6148 | V4基础特征向量维度更大,是单专家参数翻倍核心原因 |
| FP16完整镜像磁盘体积 | 3196GB | 1488GB | FP16裸盘下V4存储容量约为GLM两倍 |
| 官方分发量化格式 | FP8稠密层 + FP4专家混合量化 | 默认FP16,可选FP8量化包 | V4原生量化压缩效率极高,1.6T总参混合精度仅960GB |
| MTP总权重 | 14.8B | 14.2B | 两者MTP体量接近,均为轻量化辅助预测模块 |
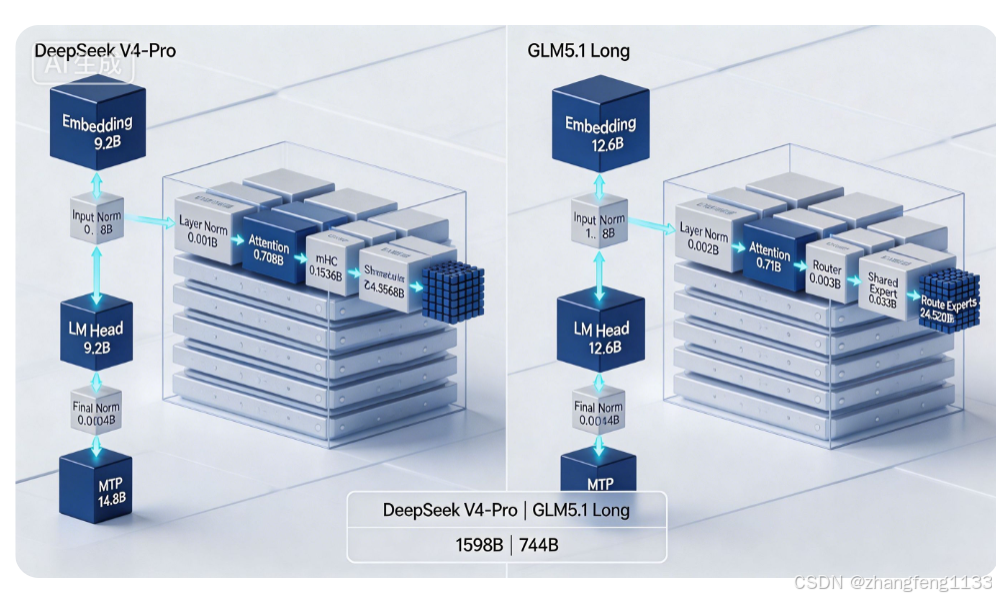
一、顶层全局模块权重对比(全局仅加载一次)
- Embedding词嵌入(两者均与LM Head权重共享)
- V4-Pro:9.2B
- GLM5.1:12.6B
差异:GLM词嵌入权重更大,词表编码投影参数更多
- 全局输入前置RMS Norm
- V4-Pro:0.8B
- GLM5.1:1.8B
差异:GLM全局归一化参数规模更高
- 输出LM Head
- V4-Pro:9.2B
- GLM5.1:12.6B
差异:和嵌入层一一对应,GLM输出投影权重更大
- Final末尾归一化
两者参数均<0.01B,可忽略,无差距 - MTP多Token预测
- V4-Pro:14.8B
- GLM5.1:14.2B
差异:体量几乎持平,不构成模型权重差距来源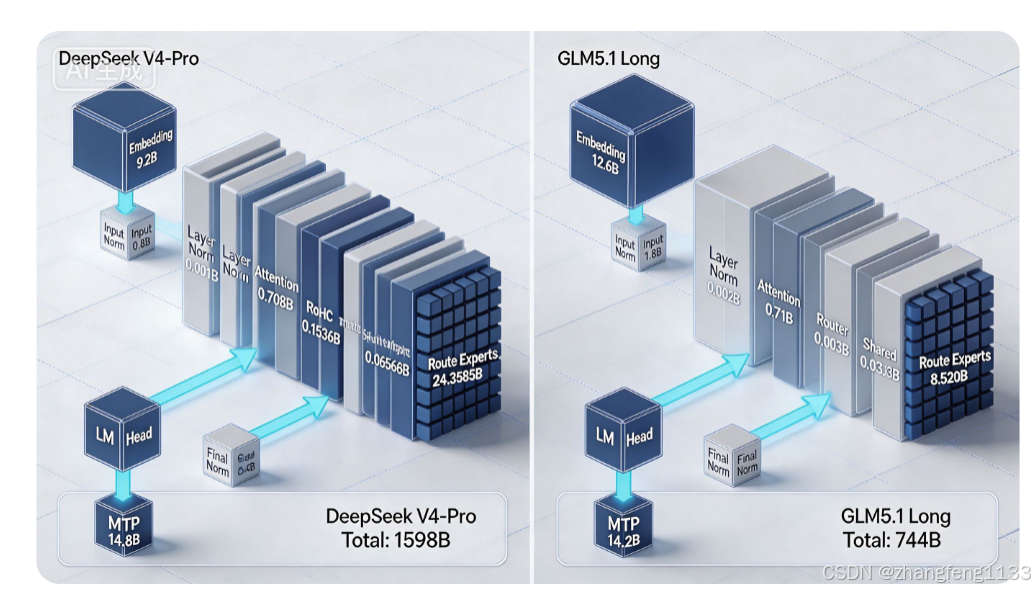
二、Transformer单层完整权重对比(单次加载单层总大小)
单层总参数
- V4-Pro单层:25.2898B
- GLM5.1单层:9.266B
体量差距:V4单层权重≈GLM单层2.73倍
单层内部各子模块拆分权重
- 层前置Norm
V4:0.001B | GLM:0.002B → GLM略大,可忽略 - 多头注意力全套权重
V4(CSA+HCA混合注意力):0.708B
GLM(MLA稀疏注意力):0.71B
差异:单层注意力参数量几乎持平,两种稀疏注意力方案体量接近 - 独有稠密层(V4专属mHC,GLM无该模块)
V4单层mHC:0.1536B
GLM:无,权重为0
差异:V4每层额外增加一套流形约束超连接稠密矩阵,增加单层加载体积 - MoE路由门控Router
V4:0.003B | GLM:0.003B → 完全一致 - 单层共享专家FFN
V4单共享专家:0.06568B
GLM单共享专家:0.033B
差异:V4隐藏维度更高,单个专家FFN参数约为GLM两倍 - 单层全部路由专家合集
V4:24.3585B(384个专家总和)
GLM:8.520B(256个专家总和)
最大权重差距来源:单层专家池总参数差距巨大
单层结构总结
GLM仅分为注意力、MoE两大稠密分支;V4在注意力、MoE之外额外增加mHC稠密层,且专家池总规模大幅领先,单层总权重显著更高。
三、MoE体系完整权重对比(模型主体,占90%以上总权重)
- 单路由专家单体权重
- V4:0.06568B
- GLM:0.03328B
V4单专家参数≈GLM两倍,根源为7168更高隐藏维度,专家特征表达容量更强
- 全模型整套MoE总参数(共享专家+路由专家+门控)
- V4 MoE合计:1490.058B
- GLM MoE合计:667.368B
V4专家总权重≈GLM 2.23倍,是两款模型总参数拉开差距的核心
- MoE架构差异
- 专家数量:V4每层384路由专家,GLM仅256个,单层专家池容量多50%
- 单专家尺寸:V4专家FFN参数翻倍,单专家承载知识上限更高
- 稀疏激活:V4每层仅激活6个路由专家,GLM激活8个路由专家
四、完整加载流程对比(加载顺序、单次IO体量)
通用统一加载规则(两款模型一致)
- 优先加载全局Embedding、输入Norm,全局共用,仅读取一次
- Transformer层按0起始序号逐层串行加载,一层完整读取完毕再读取下一层
- 全部Transformer加载完成后,读取输出LM Head、末尾Final Norm,最后加载MTP模块
加载顺序唯一区别
- GLM单层内部加载顺序:层Norm → MLA注意力 → MoE门控 → 共享专家 → 全部路由专家
- DeepSeek V4-Pro单层内部加载顺序:层Norm → CSA+HCA注意力 → mHC权重 → MoE门控 → 共享专家 → 全部路由专家
V4每层多一步mHC权重读取,单层加载文件分片更多、单文件体积更大。
IO体量差异
- 初始全局加载:GLM Embedding(12.6B)单次IO大于V4(9.2B)
- Transformer循环加载阶段(核心差距)
- V4单层单次读取25.2898B,共循环61次,单轮IO数据量极大
- GLM单层单次读取9.266B,共循环78次,单次IO压力更低、读取轮次更多
- 末尾MTP加载:两者体量接近,无明显IO差距
五、全模型各模块总权重汇总对照
| 模块 | DeepSeek V4-Pro总参数 | GLM5.1 Long总参数 | 倍数关系 |
|---|---|---|---|
| Embedding | 9.2B | 12.6B | GLM ×1.37 |
| 全局输入Norm | 0.8B | 1.8B | GLM ×2.25 |
| 全部层注意力合集 | 43.188B | 55.38B | GLM ×1.28 |
| 全模型mHC稠密层 | 9.3696B | 0B | V4独有模块 |
| 全模型整套MoE | 1490.058B | 667.368B | V4 ×2.23 |
| 输出LM Head | 9.2B | 12.6B | GLM ×1.37 |
| Final Norm | 0.004B | 0.004B | 完全相等 |
| MTP模块 | 14.8B | 14.2B | 基本持平 |
| 模型总静态权重 | 1598B | 744B | V4 ×2.15 |
六、五大核心权重差别(精简总结)
- 总静态存储体量差距巨大
V4-Pro总权重1598B,是GLM5.1(744B)的2.15倍;增量主体来自MoE专家池,同时包含V4独有的mHC稠密层参数。 - MoE专家池是两者最核心分水岭
V4每层384个大尺寸专家,GLM仅256个小专家;单专家参数、单层专家总参数、全模型专家总参数全部呈翻倍级差距,V4静态知识存储上限更高。 - V4独有mHC稠密权重
GLM无流形约束超连接模块,V4每层额外携带0.1536B稠密参数,会增加单层加载IO与基础显存占用。 - 稠密辅助模块GLM整体略大
Embedding、输出头、全局归一化、全量注意力总参数GLM全部高于V4;GLM依靠78层更深网络弥补稠密表达能力,V4依靠超大MoE池扩充知识容量。 - 磁盘存储与IO硬件需求完全不同
- GLM:默认FP16分发,单层文件小、加载轮次多,单次IO带宽压力低;
- V4-Pro:FP4专家+FP8稠密混合量化,同等硬件下磁盘占用更小,但FP16裸盘单层文件体积巨大,对单机带宽、显存容量要求更高。
纯推理前向链路:权重是否会跨节点复用(不考虑显存驻留,只看计算会不会调用)
核心规则
每一层Transformer的权重完全独立、互不通用:
第0层所有参数(注意力、mHC、本层384个专家、本层门控、本层共享专家),只在计算第0层特征时使用;
计算第1层、第2层……第60层时,永远不会再调取第0层的任何专家/权重。
同理:第N层的全部专家、门控、注意力权重,仅处理当前层输入时生效,上层、下层计算完全用不到它。
分模块逐条说明(DeepSeek V4-Pro推理 Input→Output)
1. 全局共享权重(整条推理链路从头到尾,每一步token生成都会反复调用,所有层通用)
这些权重不绑定某一层,每一轮token生成全程反复使用:
- Embedding 嵌入权重:每一个输入/生成token都要映射向量,全程复用
- 全局输入RMS Norm:嵌入后统一归一,每轮必用
- 末尾Final Norm:61层全部走完后归一,每一步生成token都调用
- LM Head输出投影:每一步预测词表概率,全程复用
2. 单层Transformer专属权重(仅当前层节点使用,走完该层就不再调用,其他层完全用不上)
每层独立一套,层与层之间完全隔离:
以第k层举例:
- 层前置/后置Norm:只处理第k层输入输出,k+1层不用
- CSA+HCA多头注意力权重:仅第k层内部计算注意力,别的层不调用
- mHC矩阵:仅第k层特征变换,其他层无关
- Router路由门控:只给第k层token做专家分配,下层不用
- 本层1个共享专家FFN:仅计算第k层的token特征,第k+1层有自己独立的共享专家
- 本层384个路由专家全集:只服务当前第k层
- 第一层的任意专家,计算完第一层特征后,第二层、第三层……全程再也不会调用该专家权重;
- 第二层有自己独立的384个专家池,和第一层专家完全分开、互不复用。
3. MTP模块权重(推理全程任何节点都不会调用)
常规文本生成推理链路完全不使用,所有层、所有计算节点都不会触发。
举直白例子
输入token依次经过 Layer0 → Layer1 → Layer2 … → Layer60
- 计算Layer0时:加载/使用Layer0全套专家、注意力;Layer0计算完成,后续Layer1~60的计算流程再也不会碰Layer0任何专家权重;
- 计算Layer1时:只启用Layer1专属专家、注意力,第一层专家完全闲置;
- 每一层的专家都是“一次性节点耗材”:只在自己这一层的计算节点生效,跨层无复用。
极简总结
- 嵌入、全局输入Norm、末尾Norm、输出Head:整条推理链路全程反复使用;
- 每一层Transformer的注意力、mHC、门控、本层所有专家(共享+384路由专家):仅当前层节点使用,过了这一层之后,后续所有节点都不会再用到这套权重;
- MTP:推理全程所有节点均不使用。
核心结论所有权重训练全周期全程参与计算;推理阶段分两类:固定常驻权重、可选关闭不加载权重。
一、全生命周期(训练+推理,每一步都必须加载、全程使用)
- 全局Embedding词嵌入权重
- 全局输入前置RMS Norm
- 全部61层Transformer内所有子模块权重(每层全程参与)
- 层前置/后置Norm
- CSA+HCA混合注意力全套
- mHC流形约束矩阵
- MoE路由门控Router
- 每层共享专家FFN(每token固定激活,全程生效)
- 384个路由专家静态权重池(存储常驻,按需调取)
- 输出LM Head预测权重
- 末尾Final Norm归一化权重
二、仅训练阶段全程使用,推理可选择不加载、不用的权重
MTP多Token预测模块整套权重
- 训练阶段:必须启用,同步做多token损失计算,全程参与迭代;
- 推理上线时:可直接跳过加载该模块,不影响基础文本生成,完全不用这部分权重,节省磁盘IO与显存。
补充区分:静态存储权重 vs 推理激活权重
- 上面所有模块都是磁盘静态权重,加载时全部读取进显存;
- MoE里384个路由专家静态权重常驻显存,但单次推理只激活6个路由专家做计算,其余378个专家权重只是存在显存里、不参与前向运算,属于“加载常驻,但不实时计算”。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)