你的 RAG 检索效果差?可能是结构用错了!
在平时的学习过程中,我都会将与 ChatGPT 之间的对话整理对应的知识文档,但是这却给我带来了一个难题。
本来是想研究 A 这个问题,但是由此却衍生出了 B、C、D 等问题,而对于每一个问题的探究,几乎都可以梳理总结成一篇文章。以往都是让 ChatGPT 先总结成文章,然后我自己再进行修改,原因就是内容不成体系、逻辑不够严谨。但是久而久之这就变成了一种负担,想着不整理吧又觉得可惜,整理吧又太费时间。
于是,这两天开始下定决心要学习使用 Claude Code 来解决这个问题。
在经过让它看我过去写的10篇文章,总结我的行文风格,100多轮交互以后,终于调教了一个可用的 Skill。后续,只需要将 ChatGPT 初步总结素材丢个它,它就能生成与我风格相仿的文章。
以下所有文本内容均由千问驱动 Claude Code 生成,插图由 Gemini 根据 Claude Code 提供的文本生成。
很多人第一次搭建 RAG 系统时,都会有一个疑问:既然 Embedding 模型能把文本变成向量,为什么还要再加一个 Rerank 模型?
刚开始你可能觉得,Rerank 模型大概就是锦上添花的东西,有它没它区别应该不大。但真正用过之后你会发现,加不加 Rerank,检索结果的质量简直是两个世界。
这背后的原因,涉及到 RAG 检索架构中一个非常核心的设计。今天我们就来把它一次讲透。
1 什么是双塔结构
双塔(Bi-Encoder)是 RAG 系统中最常用的检索架构,也是几乎所有向量数据库的底层基础。理解双塔的工作原理,是理解整个 RAG 检索机制的第一步。
1.1 双塔结构思想原理
双塔的核心思想可以用一句话概括:Query 和 Doc 分开编码,最后在向量空间中计算相似度。
例如,在 RAG 应用开发中,我们会先通过 Embedding 模型(也就是 Encoder)将所有的离线文档都转换成向量存入到向量库中。当用户提问时,我们再将 Query 通过 Embedding 模型将其转换成向量,然后同向量库中的向量进行相似度比较。
离线阶段:Doc → Encoder → 向量 d(存入向量库)查询阶段:Query → Encoder → 向量 q → 与向量库比较 → 返回相似文档
同时,对于相似性的度量,常用的有Cosine 相似度、Inner Product或L2 距离。你可以把整个过程想象成图书馆的图书检索系统:每本书都有一个编号(向量),读者查询时先拿到查询词的编号,然后在书架上找编号最接近的书。
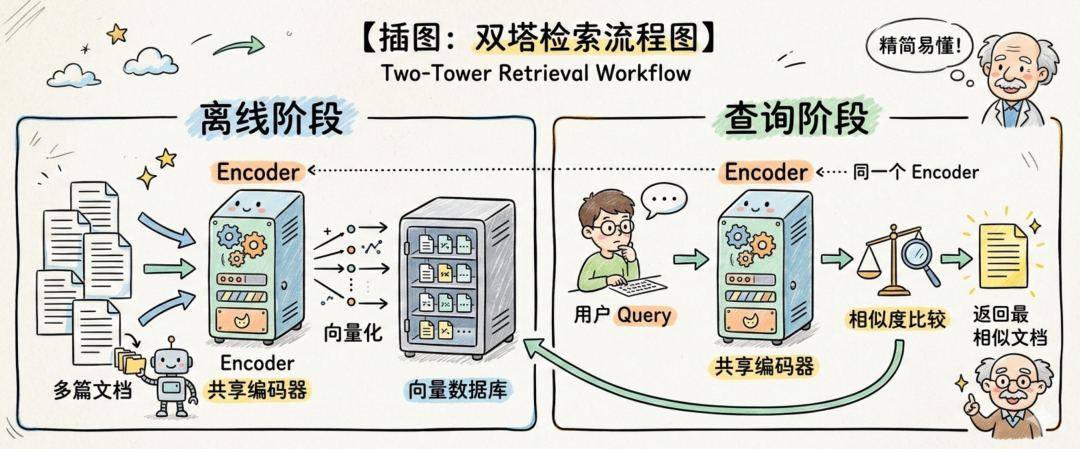
图 1. 双塔检索流程图
【插图:双塔检索流程图】左侧展示离线阶段,多篇文档通过 Encoder 转换成向量后存入向量数据库;右侧展示查询阶段,用户 Query 通过同一个 Encoder 转换成向量,与库中向量进行相似度比较,最终返回最相似的文档。
1.2 双塔结构的优势
说完了工作原理,我们自然要问:为什么双塔结构能支撑百万级甚至更大规模的数据检索?
这得益于它的一个关键设计:**文档向量可以提前离线计算好并存入向量数据库,查询时只需计算一次 Query 向量,然后在向量索引中做近似搜索(ANN)。**这意味着时间复杂度可以从线性的**O(N)降低到接近O(log N)**。
举个例子,如果你有 100 万篇文档,使用双塔结构时,系统可以在对数级别的时间内找到最相关的文档,而不用逐一比较 100 万次。这也是为什么你的 RAG 系统能够秒级响应,而不是等待几分钟。
向量数据库天生适配双塔结构。
Milvus、Chroma、Weaviate 等所有主流向量数据库的底层都是这个逻辑。
1.3 双塔结构的不足
不过,双塔结构也有明显的局限性,这也是为什么它不能单独使用的原因。
问题在于:**Query 和 Doc 在编码时彼此不知道对方。**换句话说,没有交叉注意力机制。模型只能把整段文本压缩成一个固定长度的向量,一旦压缩完成,细粒度的匹配信息就会丢失。
举个例子,假设你的知识库中有一篇文档讲的是苹果公司 2024 年的财报数据,当用户搜索苹果营收时,双塔结构可能会把这篇文档排在后面,因为它在编码时无法捕捉到苹果和苹果公司的细粒度对应关系,它只能基于整体语义的粗略匹配。
所以你会发现,只用双塔检索时,结果往往是看起来相关,但不够精准。
2 什么是单塔结构
说完了双塔,我们再来看单塔结构是怎么解决精度问题的。
单塔(Cross-Encoder)是另一种常见的架构,通常用于 Reranking 场景。它的做法与双塔完全不同。
2.1 单塔结构思想原理
双塔是分开编码,而单塔是将 Query 和 Doc拼接在一起输入模型进行联合编码。
具体来说,我们会把 Query 和 Doc 的文本拼接成一个序列,格式为 [CLS] Query 文本 [SEP] Doc 文本,然后通过 Embedding 模型进行编码,最后输出一个相关性分数。
输入:[CLS] 用户问题 [SEP] 候选文档 [SEP] ↓ Transformer 联合编码 ↓ 相关性分数(0 到 1 之间)
你可以把单塔理解成一个专业的审稿人:它会仔细阅读问题和文档的每一个字,然后判断这篇文档是否真的回答了问题。
2.2 单塔结构的优势
单塔结构最大的优势在于表达能力强,能够捕捉细粒度的语义匹配。
在 Cross-Encoder 中,Query 的每个 token 可以关注 Doc 的每个 token,这是完整的交叉注意力机制。这意味着模型可以学习到精确的短语对齐、细粒度的语义匹配、上下文的补全以及逻辑关系的判断。
还是刚才的例子,当用户搜索苹果营收,文档中写的是Apple Inc.的年收入时,单塔模型能够理解苹果和Apple Inc.是同一个实体,营收和年收入是同一个概念,从而给出更高的相关性分数。而双塔结构由于是分开编码,很难捕捉到这种细粒度的语义对应。
这种表达能力,远强于双塔结构。
2.3 单塔结构的缺陷
然而,单塔结构也有一个致命问题,这导致它无法单独用于大规模检索。
问题是计算成本过高,不可扩展。
假设有 100 万文档,如果用 Cross-Encoder,必须对每一个文档都跑一次完整的 Transformer 前向传播,复杂度是O(N)。这意味着100 万次计算,在工程上几乎不可用。
想象一下,每次用户发起查询,你都要让模型跑 100 万次,即使用上最好的 GPU,响应时间也会达到秒级甚至分钟级,这在实际应用中是完全无法接受的。
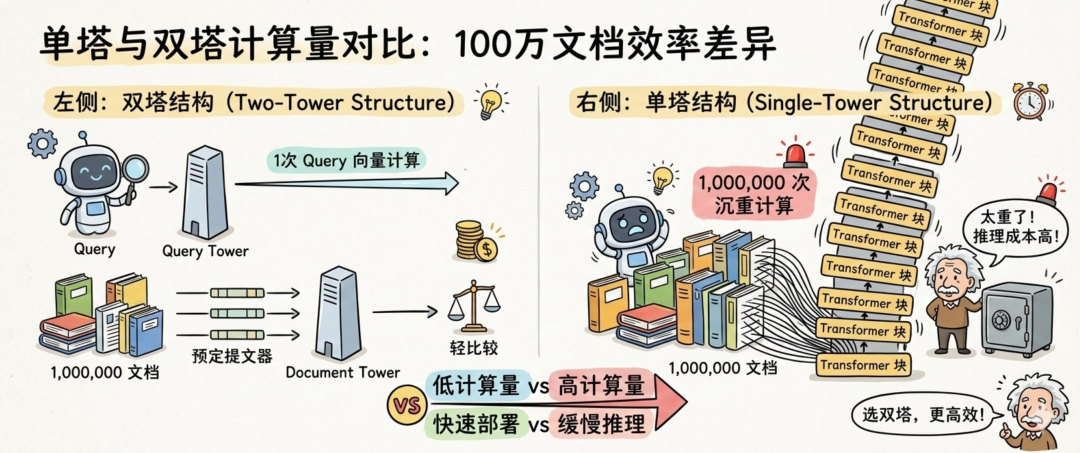
图 2. 单塔与双塔计算量对比
【插图:单塔与双塔计算量对比】左侧双塔结构,100 万文档只需计算 1 次 Query 向量;右侧单塔结构,100 万文档需要计算 100 万次,用堆叠的 Embedding模型数量直观展示计算量差距。
3 双塔单塔如何配合
说到这里,答案已经很明显了:双塔和单塔各有所长,也各有所短。那双塔能解决规模问题但精度不够,单塔能解决精度问题但规模不行,该怎么办?
工业界的标准答案是:两者配合,采用两阶段检索架构。
3.1 两阶段架构思想
这就是为什么你总会看到Embedding 加 Rerank的组合,本质就是双塔加单塔。
第一阶段的 Embedding 模型(双塔)负责从海量文档中快速召回一批候选,保证不漏掉相关内容;第二阶段的 Rerank 模型(单塔)负责对这批候选进行精确排序,保证排在前面的真的是最相关的。
这种设计思路和传统搜索引擎几乎一模一样:先用倒排索引快速召回一批候选网页,再用 PageRank 等算法进行精排。
3.2 两阶段架构优势
第一阶段:100 万文档 → Top 50 候选(双塔召回,O(log N))第二阶段:Top 50 候选 → Top 5 结果(单塔精排,O(50))
第一阶段,双塔召回,从 100 万文档中快速筛选出 Top 50 候选,目标是保证召回率并控制计算成本;第二阶段,单塔精排,对 Top 50 候选进行精确排序,输出 Top 5 最终结果,目标是提升排序精度并修正语义偏差。
这种架构兼顾了效率和精度,既能秒级响应,又能保证结果质量。
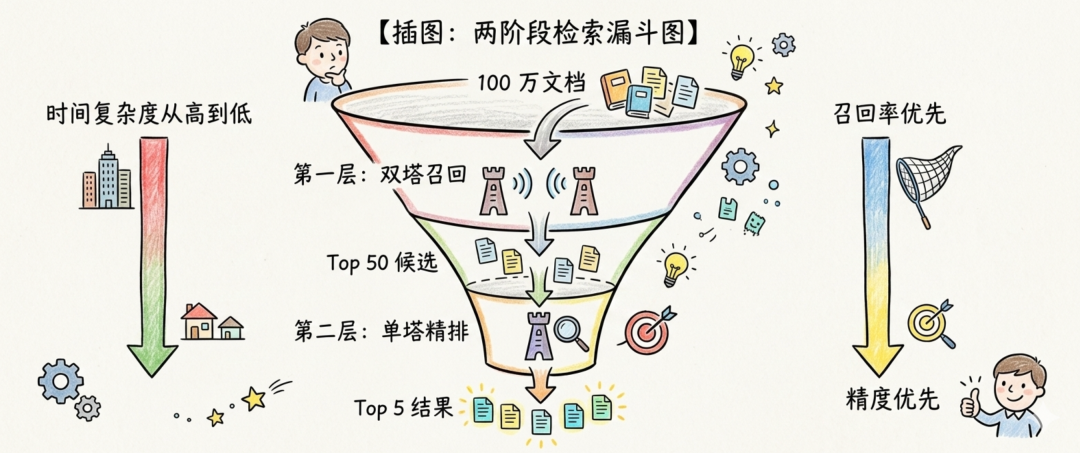
图 3. 两阶段检索漏斗图
【插图:两阶段检索漏斗图】顶部宽口漏斗标注 100 万文档,经过第一层双塔召回收缩到 Top 50 候选,再经过第二层单塔精排输出 Top 5 结果。左侧标注时间复杂度从高到低的变化,右侧标注从召回率优先到精度优先的转变。
3.3 单双塔的本质差异
从信息流的角度来看,双塔和单塔的本质差异可以概括为两句话:
双塔是先压缩,再比较。
单塔是先交互,再判断。
双塔的本质是语义压缩匹配,它将文本压缩成向量后再进行相似度计算;单塔的本质是相关性函数学习,它直接学习 Query 和 Doc 之间的相关性函数。
压缩意味着信息丢失,交互意味着表达能力更强。
这就是两者精度差距的根源,也是为什么必须两者配合的原因。
3.4 实践指导
理解了原理,最后来回答一个实际问题:你的 RAG 系统该怎么选?
如果你的文档规模超过1 万,有向量数据库,需要在线检索,那么一定要用双塔做召回。这是毫无疑问的,因为你不可能用单塔去处理百万级的文档。
但如果你的系统出现以下情况,说明该考虑加入单塔精排了:
- 检索结果看起来相关但不精准
- LLM 回答引用错 chunk
- 相似度排序质量一般
这些问题的根源都在于双塔的语义粗匹配特性,无法做到精确判断。
高质量 RAG 系统几乎都包含 Embedding 模型(双塔)和 Reranking 模型(单塔),两者缺一不可。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 8
8 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)