Dify 接入蓝耘 MaaS:基于智能客服分流模板搭建一个客服助手
Dify 接入蓝耘 MaaS:基于智能客服分流模板搭建一个客服助手
客服场景里,很多问题并不是“模型能不能回答”,而是“问题该先交给谁处理”。
比如同样是客户发来的消息,有的是登录报错、接口异常、功能 Bug;有的是付款后权益没有开通、发票抬头写错、套餐续费咨询。如果所有问题都丢给一个通用客服机器人,它可能能给出一段看起来完整的回复,但流程上并不一定合理。技术问题应该优先走技术支持,账单问题应该走运营或财务确认,复杂问题还需要提示人工介入。
在 Dify 的应用模板中,智能客服分流助手很适合这个场景。它的核心是通过“问题分类器”先识别用户意图,再把不同类型的问题路由到不同的 LLM 节点处理。
下面基于这个模板做一次完整实操:在 Dify 中接入蓝耘 MaaS,把模板默认模型替换为蓝耘 MaaS 中的 deepseek-v4-flash,并搭建一个可以区分“技术支持问题”和“账单问题”的智能客服分流助手。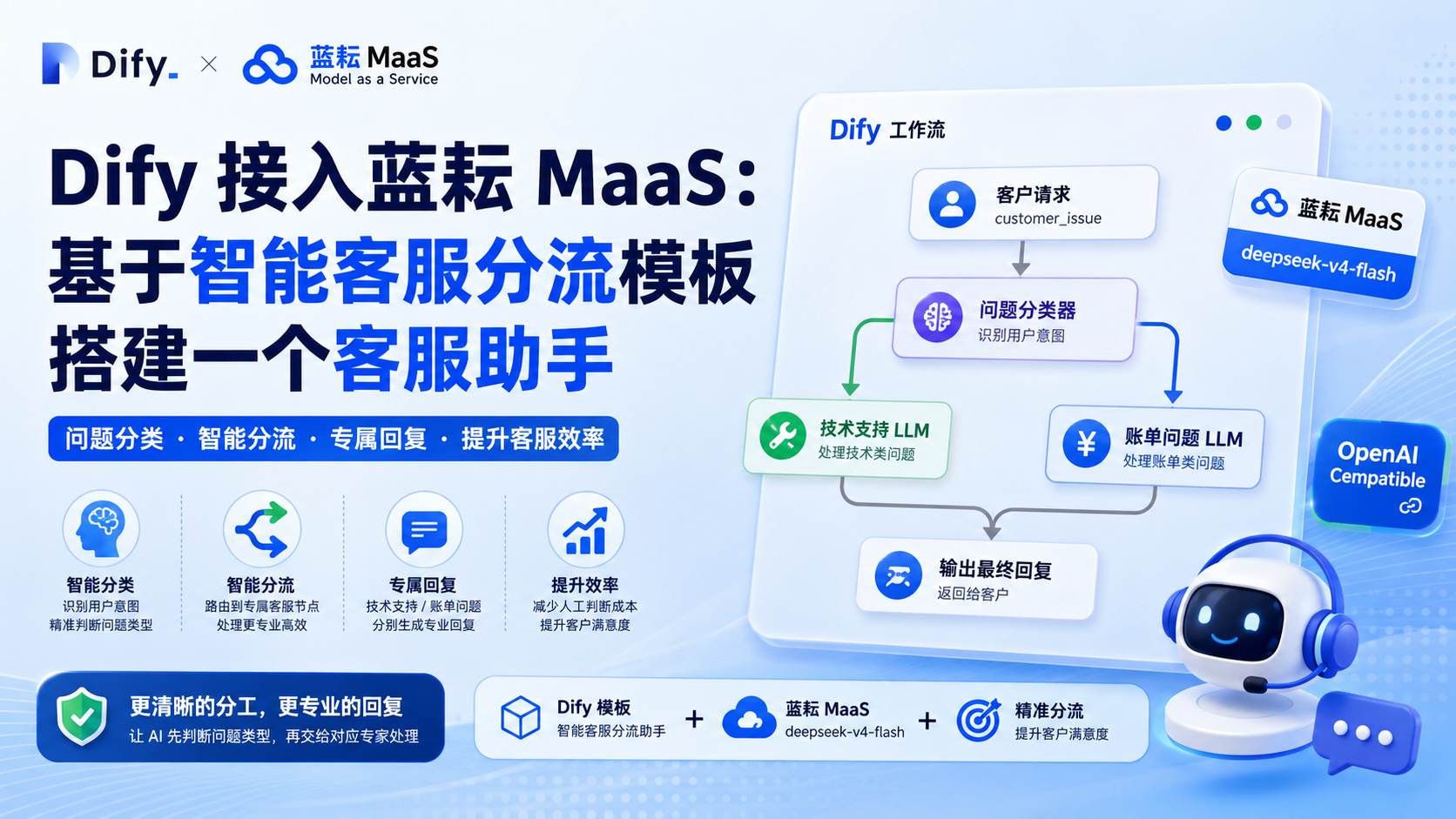
文章目录
一、为什么客服场景需要先分流
在真实客服系统里,用户提交的问题往往已经带有明确的业务处理方向。
举几个例子:
- “接口调用一直 500,昨天还正常,今天上午开始所有请求都失败。”
- “我已经付款了,后台还是免费版,订单号是 YC202606110018。”
- “发票抬头写错了,能不能重新开?”
- “登录后台一直提示验证码错误,换浏览器也不行。”
这些问题如果全部交给一个通用机器人处理,会有两个问题:
- 回复口径容易混在一起,技术问题和账单问题没有明显分工。
- 客服接手时仍然要重新判断问题类型,再决定转给哪个团队。
所以这个实践围绕 Dify 的“问题分类器”模板来做客服分流。目标很明确:让 AI 先判断问题类型,再把问题交给对应的专属客服节点生成回复。
二、整体方案:Dify 做流程分流,蓝耘 MaaS 做理解和生成
从模板可以看到,这个应用的流程非常清晰:
客户请求
-> 问题分类器
-> 技术支持 LLM
-> 账单问题 LLM
-> 输出最终回复
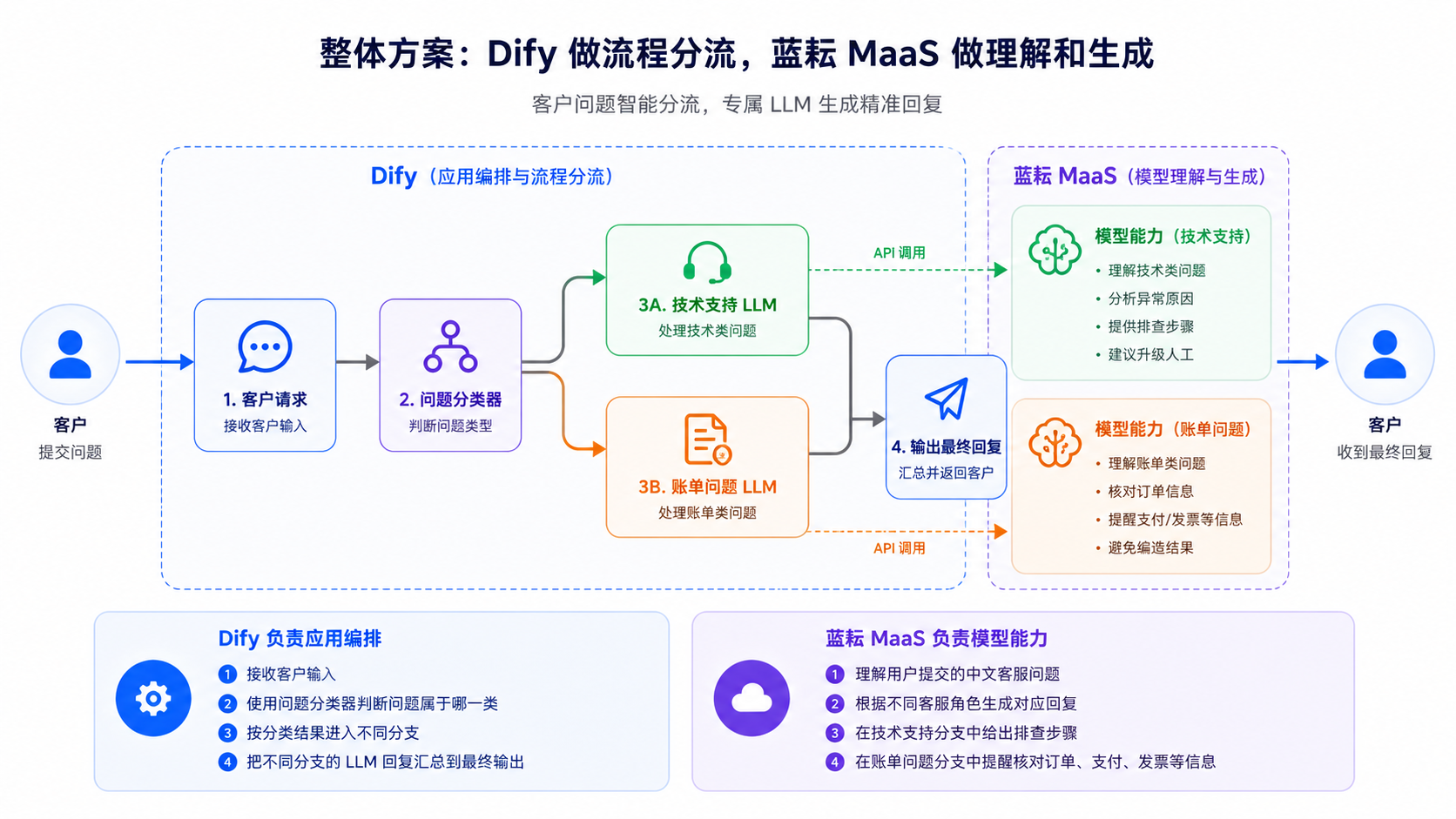
这里面 Dify 和蓝耘 MaaS 的分工如下。
Dify 负责应用编排:
- 接收客户输入。
- 使用问题分类器判断问题属于哪一类。
- 按分类结果进入不同分支。
- 把不同分支的 LLM 回复汇总到最终输出。
蓝耘 MaaS 负责模型能力:
- 理解用户提交的中文客服问题。
- 根据不同客服角色生成对应回复。
- 在技术支持分支中给出排查步骤。
- 在账单问题分支中提醒核对订单、支付、发票等信息。
也就是说,这个应用不是让一个模型“什么都回答”,而是把客服流程拆成多个更明确的节点。问题分类器负责分流,专属 LLM 节点负责回答。这样既方便调试,也更接近真实客服团队的工作方式。
三、准备工作
正式开始前,需要准备以下内容。
1. 蓝耘元生代账号和 MaaS API Key
先进入蓝耘元生代控制台,准备好蓝耘 MaaS 的 API Key。这个 Key 后面要填到 Dify 的模型供应商配置中。
2. 蓝耘 MaaS 模型名称
本次实操使用蓝耘 MaaS 中的 deepseek-v4-flash。这个模型适合放在客服分流这类高频场景中,用来完成意图识别、问题归类和客服回复草稿生成。
实际填写时,要以蓝耘控制台显示的模型调用名称为准
deepseek-v4-flash
3. API endpoint URL
蓝耘 MaaS 的 OpenAI-compatible 接入地址用:
https://maas-api.lanyun.net/v1
后面在 Dify 的 OpenAI-API-compatible 模型供应商中,需要填写这个地址。
4. Dify 工作空间
可以使用 Dify 云端版,也可以使用本地部署版。只要能创建应用、使用模板、配置模型供应商即可。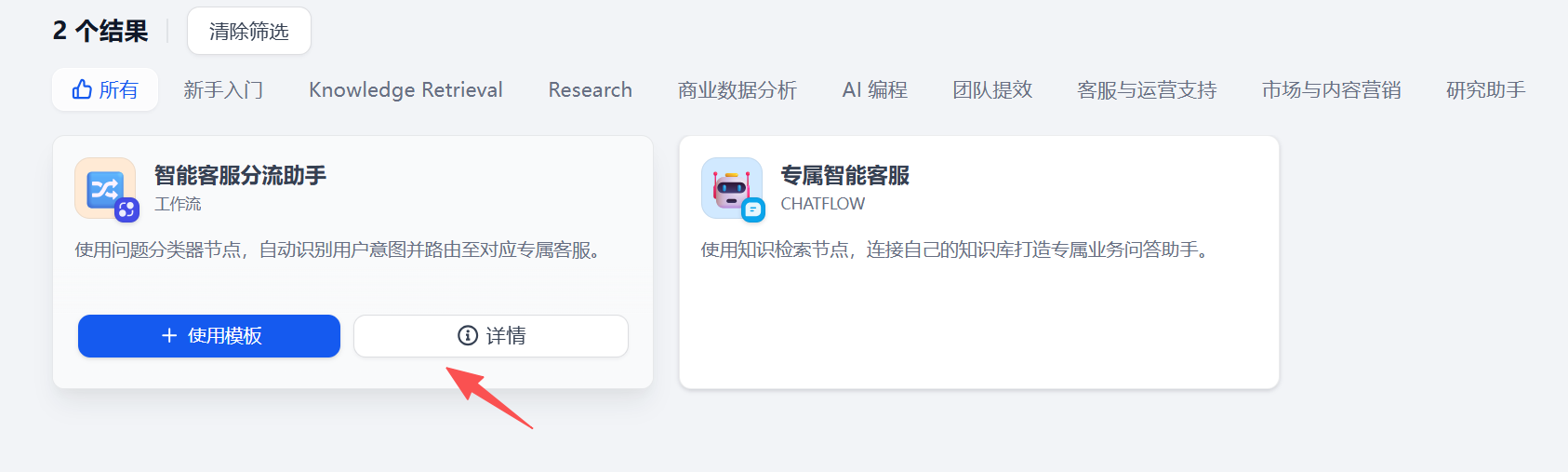
这里的重点放在利用 Dify 已有模板快速搭建客服分流工作流,Dify 的部署过程不展开。
5. 测试客服问题
为了验证分流效果,可以准备几条典型客服问题:
问题 1:
我今天调用订单查询接口一直返回 500,昨天还是正常的,麻烦帮忙看一下是不是接口出问题了。
问题 2:
我昨天已经支付专业版年费了,但后台还是显示免费版,订单号是 YC202606110018,请帮我尽快开通。
问题 3:
刚才提交发票时公司抬头写错了,还能修改吗?正确公司名是北京云策科技有限公司。
问题 4:
后台登录一直提示验证码错误,换了浏览器也不行,我们团队今天要导出报表,比较着急。
这几条问题分别覆盖技术故障、权益开通、发票处理、账号登录等场景,适合测试问题分类器是否能把问题路由到正确分支。
四、在 Dify 中接入蓝耘 MaaS 模型
模板右侧的“必须配置项”里会显示默认模型要求,例如 gpt-4.1。这个信息表示模板原本依赖某个默认模型,实际搭建时可以把 LLM 节点统一替换成已经接入 Dify 的蓝耘 MaaS 模型。
操作步骤如下:
- 进入 Dify 工作空间。
- 打开右上角账户菜单或系统设置。
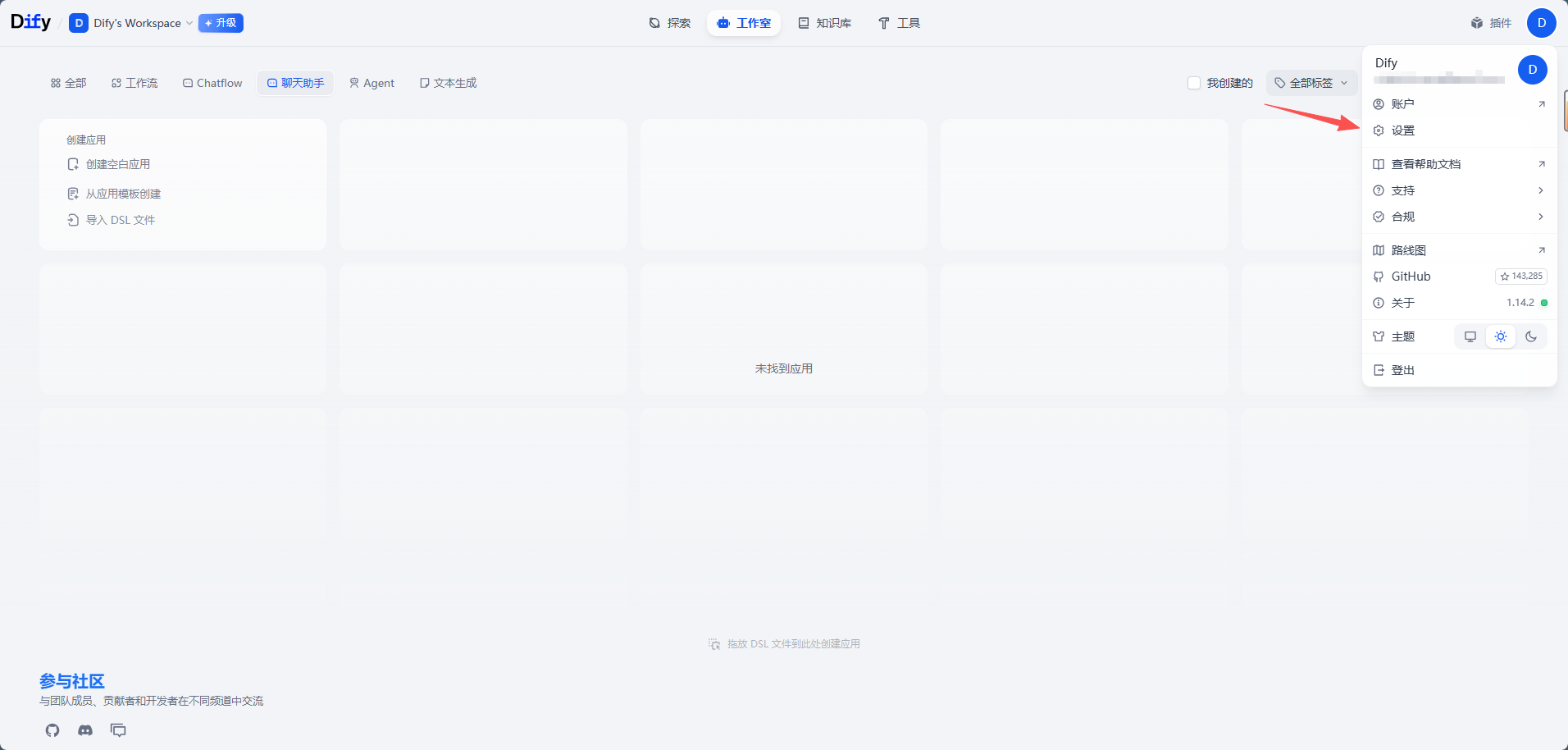
- 进入“模型供应商”。
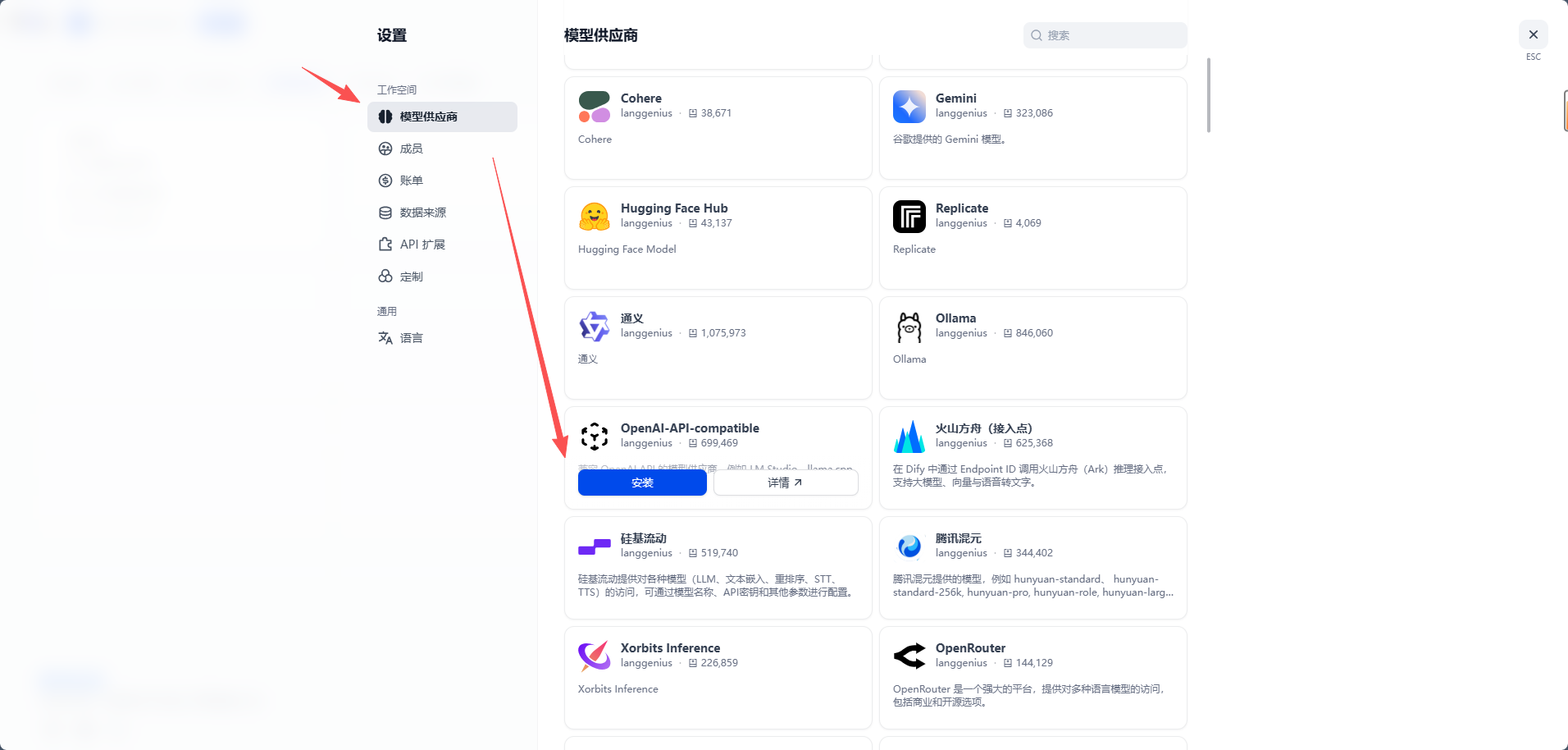
- 选择
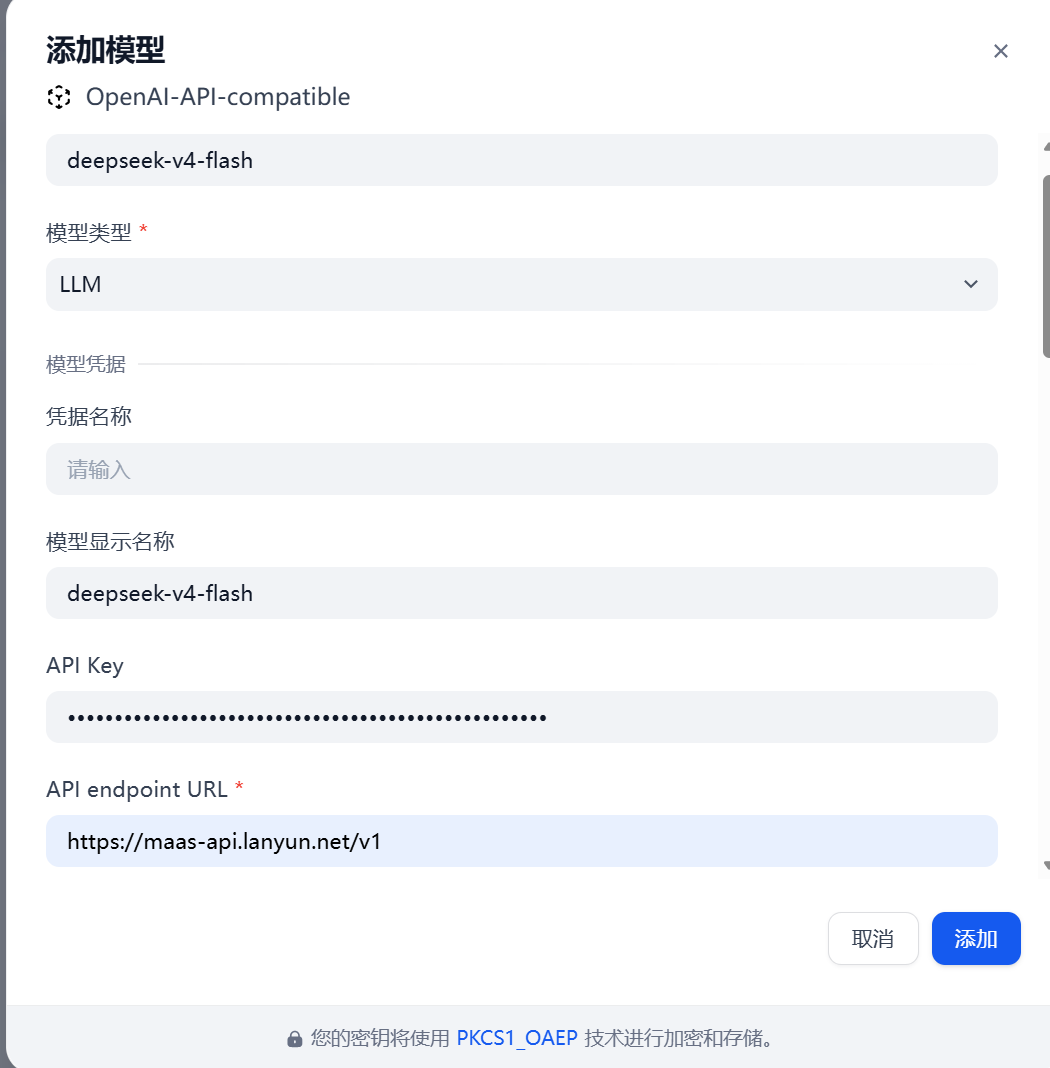
OpenAI-API-compatible。 - 点击添加模型。
- 在模型类型中选择
LLM。 - 模型名称填写蓝耘控制台中的真实调用名,例如:
deepseek-v4-flash
- API Key 填写蓝耘 MaaS 的密钥
- API endpoint URL 填写:
https://maas-api.lanyun.net/v1
-
保存前可以点击测试按钮,确认模型能够正常返回结果。
-
保存配置,绿色状态表示可以正常调用。
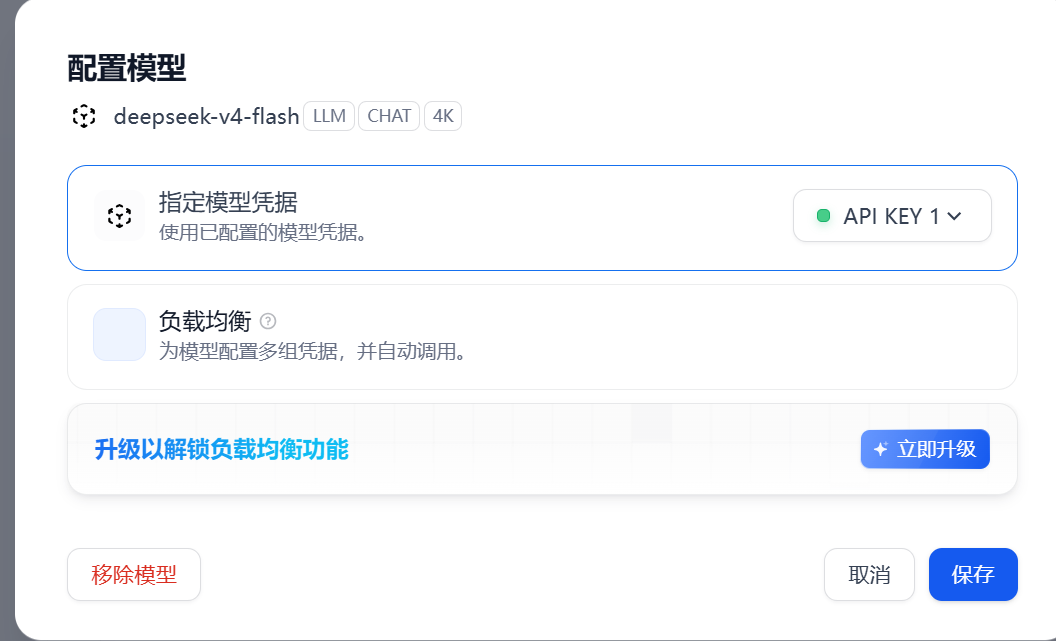
这里有两个细节需要注意。
第一,Dify 页面里如果同时出现“模型名称”和“显示名称”,模型名称应该填写蓝耘控制台里的真实调用名,显示名称可以写成便于识别的 deepseek-v4-flash。
第二,如果模型测试失败,先检查三个地方:API Key 是否完整、Base URL 是否多写或少写了 /v1、模型调用名称是否和蓝耘控制台完全一致。
五、从模板创建智能客服分流助手
模型配置完成后,就可以创建 Dify 应用了。
在 Dify 应用模板中找到“智能客服分流助手”模板。这个模板的说明是: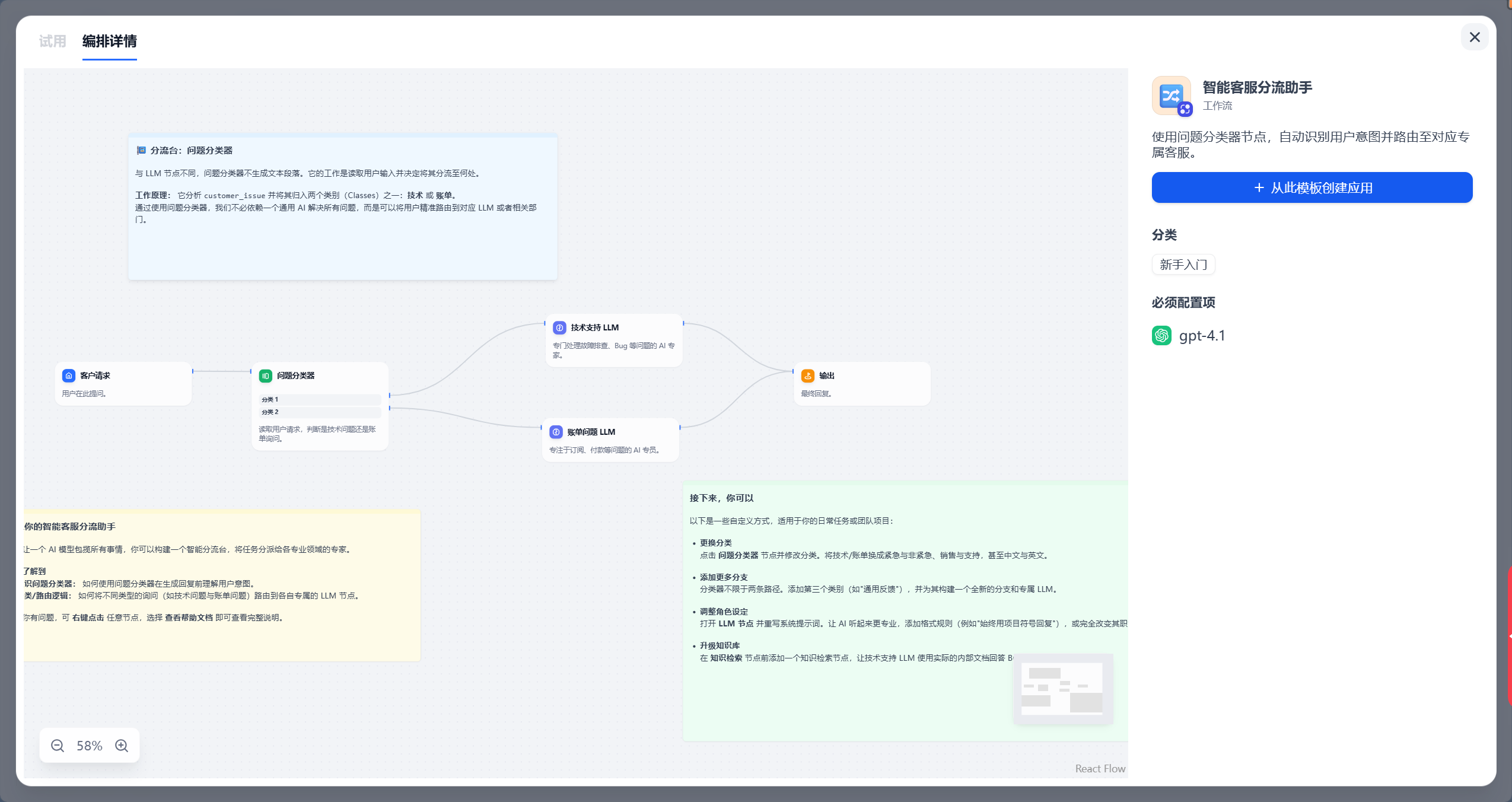
使用问题分类器节点,自动识别用户意图并路由至对应专属客服。
这个说明已经把应用核心讲清楚了。它不是让模型直接生成一段万能回复,而是先判断用户问题属于哪一类,再交给对应的专家节点。
创建应用后,进入工作流编排页面,可以看到模板中已经包含几个节点:
- 客户请求。
- 问题分类器。
- 技术支持 LLM。
- 账单问题 LLM。
- 输出。
这正好符合客服分流的基本流程。后续配置的重点是三处:问题分类器里的分类规则、技术支持 LLM 的模型和 Prompt、账单问题 LLM 的模型和 Prompt。
六、节点一:客户请求
“客户请求”是整个工作流的入口。用户在这里输入原始问题,Dify 会把这段文本传给后续的问题分类器。
在模板里,这个输入变量就是客户提交的问题内容,可以理解为:
customer_issue
也就是客户提交的问题内容。
这个节点不需要复杂配置,但在实际业务里,输入内容越完整,后续分类越准确。比如用户只写“打不开”,模型很难判断是登录打不开、页面打不开、接口打不开,还是付款页面打不开。如果用户能补充账号、订单号、报错截图、操作时间,后续处理会更稳定。
在真实业务入口里,可以提示用户尽量填写:
- 遇到的问题。
- 操作时间。
- 账号或订单号。
- 报错提示。
- 是否影响多人使用。
七、节点二:问题分类器
问题分类器是这个模板最关键的节点。
它和普通 LLM 节点不一样。普通 LLM 节点会直接生成一段文字,而问题分类器的作用是判断用户输入应该走哪条分支。
在模板中,问题分类器把客户请求分成两个方向:
分类 1:技术支持
分类 2:账单问题
为了让路由更稳定,分类名称和分类描述都要写清楚。这里保留模板的两个主分支,并把分类描述补得更具体。
技术支持类
适合进入技术支持分支的问题包括:
- 接口报错。
- 系统无法登录。
- 功能异常。
- 页面加载失败。
- 数据同步失败。
- Bug 反馈。
分类说明配置为:
当用户问题涉及接口错误、系统故障、登录异常、功能不可用、页面报错、数据同步失败、Bug 反馈等技术类问题时,选择此分类。
账单问题类
适合进入账单问题分支的问题包括:
- 支付后未开通权益。
- 套餐续费。
- 订单状态。
- 发票修改。
- 退款咨询。
- 企业版购买咨询。
分类说明配置为:
当用户问题涉及付款、订单、套餐、续费、发票、退款、权益开通等账单或商业支持问题时,选择此分类。
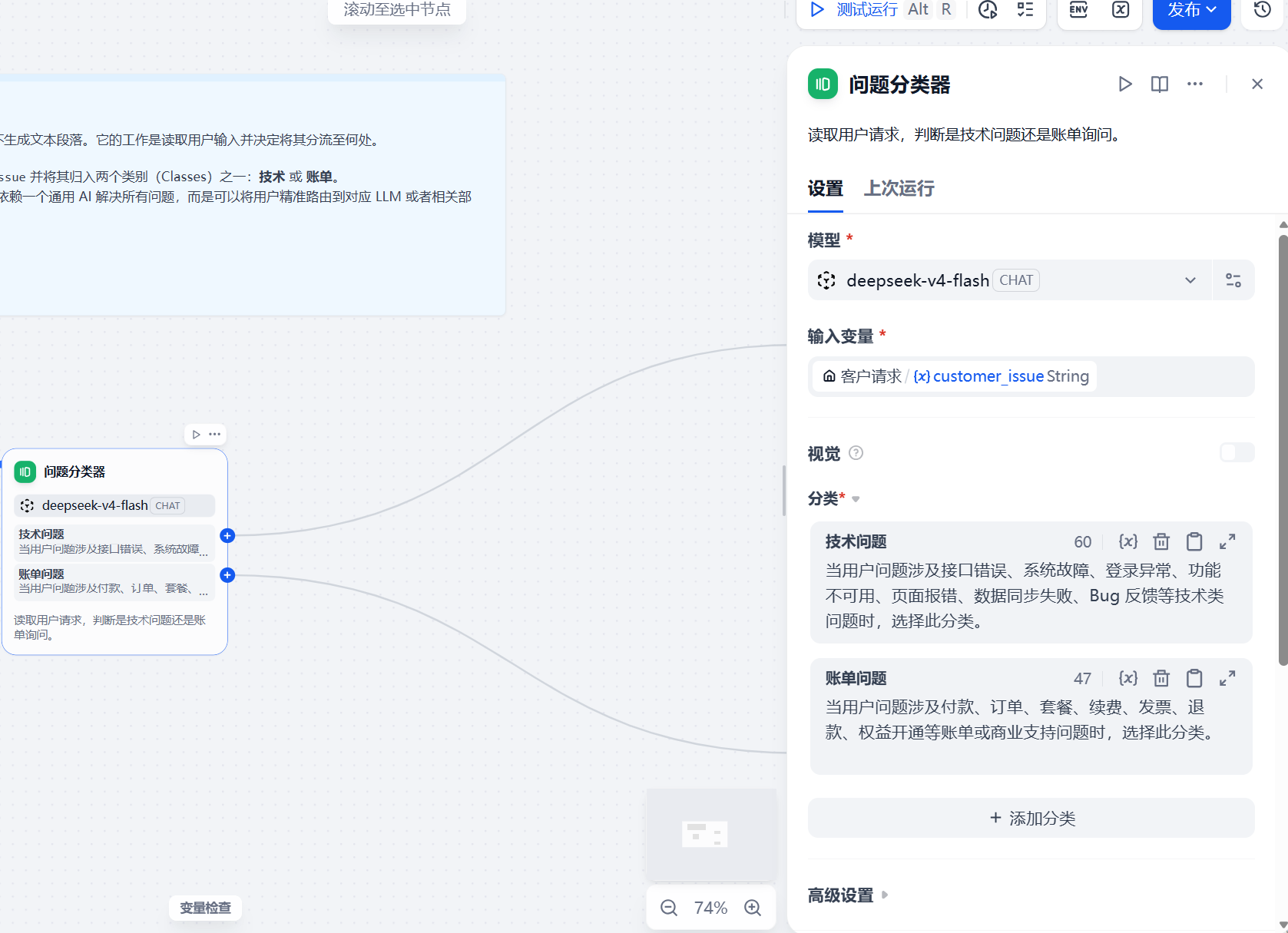
这次实操为了便于复现,先保留两个主分支。这样更容易观察分类器是否把技术问题送到技术支持节点、把支付和发票问题送到账单节点。
八、节点三:技术支持 LLM
当问题分类器判断用户问题属于技术类问题时,就会进入“技术支持 LLM”节点。
这个节点需要在模型下拉框中选择前面接入的蓝耘 MaaS 模型 deepseek-v4-flash。它的目标不是泛泛聊天,而是以技术支持的口吻给出排查建议。
Prompt 配置如下:
你是一个 SaaS 产品的技术支持客服,负责处理登录异常、接口报错、功能故障、页面异常和 Bug 反馈。
请根据用户提交的问题生成客服回复,要求如下:
1. 先简要复述用户遇到的问题,体现你已经理解上下文。
2. 判断这类问题可能需要哪些排查信息。
3. 给出 2-4 个清晰的排查步骤。
4. 如果需要用户补充信息,请列出具体信息,例如账号、报错截图、接口请求时间、Request ID、浏览器版本等。
5. 不要编造后台已经处理完成,也不要承诺具体恢复时间。
6. 如果问题可能影响多人或核心业务,请提醒优先升级给技术支持。
这个 Prompt 的重点是约束模型不要直接下结论,而是先收集信息、给出排查方向,并提醒必要时升级人工技术支持。截图中可以看到,技术支持节点已经把模型切换到了蓝耘 MaaS 接入的 deepseek-v4-flash,并写入了对应的角色提示词。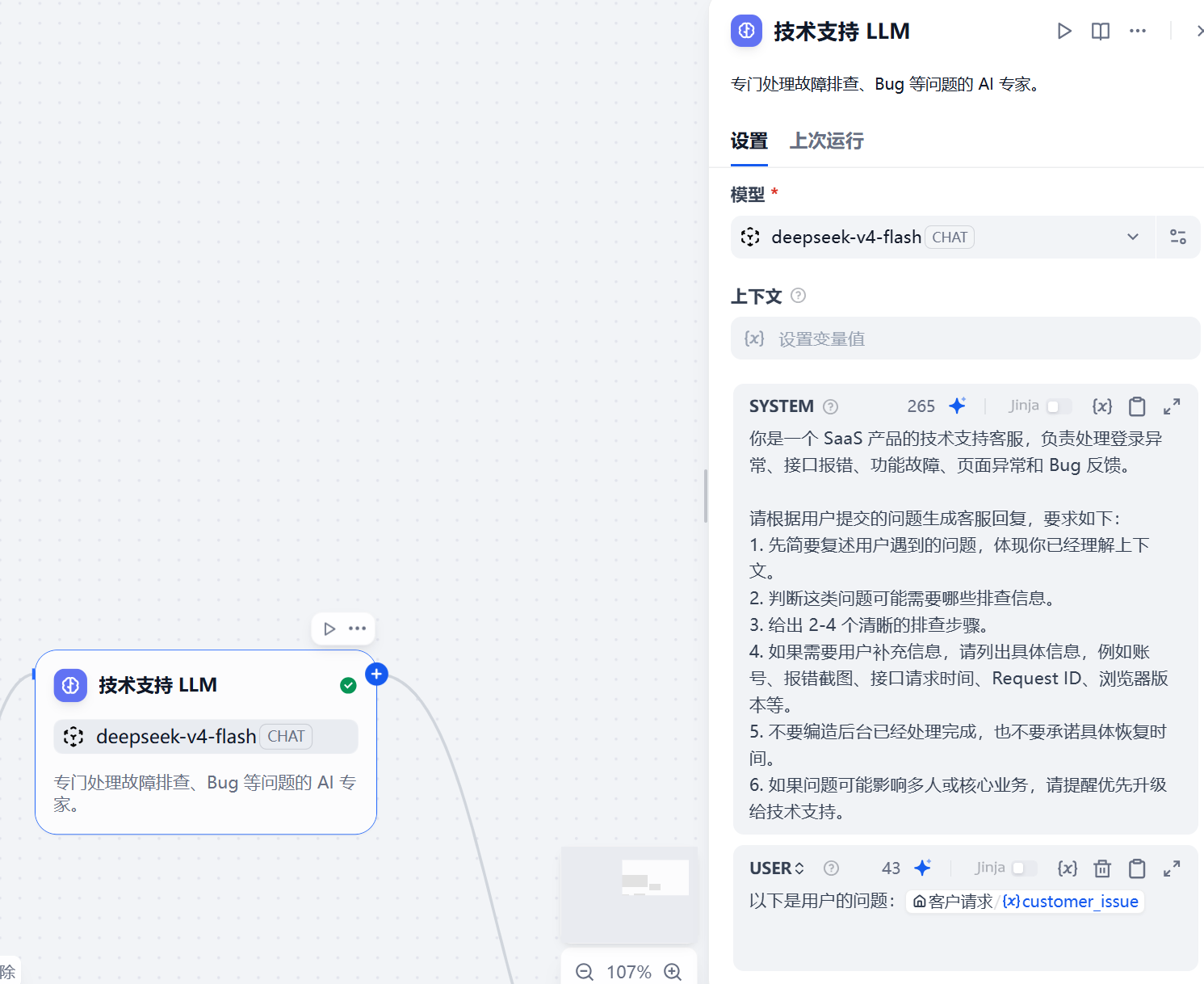
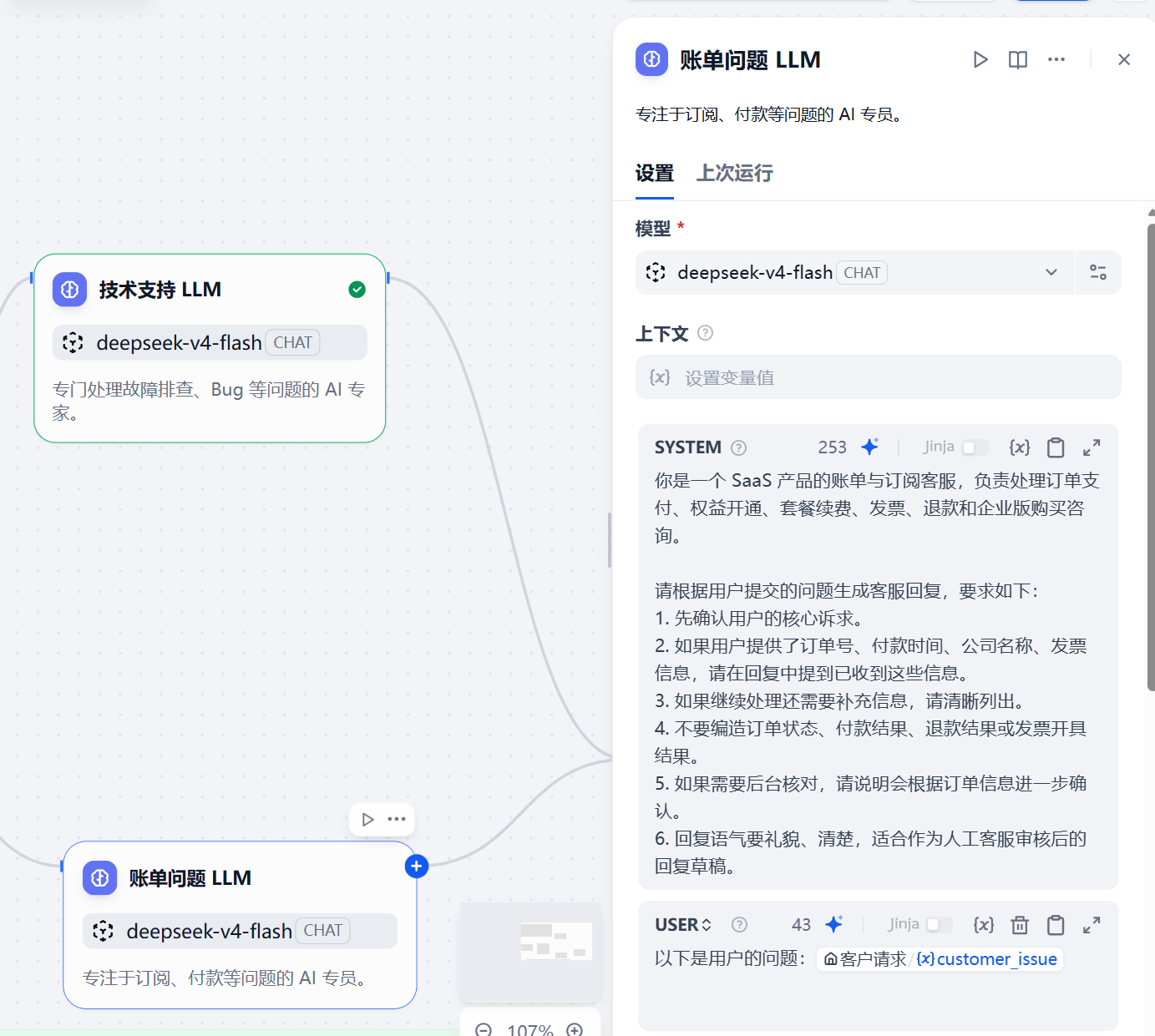
九、节点四:账单问题 LLM
当问题分类器判断用户问题属于账单类问题时,就会进入“账单问题 LLM”节点。
这个节点同样在模型下拉框中选择蓝耘 MaaS 接入的 deepseek-v4-flash,但 Prompt 要换成账单客服角色。
Prompt 配置如下:
你是一个 SaaS 产品的账单与订阅客服,负责处理订单支付、权益开通、套餐续费、发票、退款和企业版购买咨询。
请根据用户提交的问题生成客服回复,要求如下:
1. 先确认用户的核心诉求。
2. 如果用户提供了订单号、付款时间、公司名称、发票信息,请在回复中提到已收到这些信息。
3. 如果继续处理还需要补充信息,请清晰列出。
4. 不要编造订单状态、付款结果、退款结果或发票开具结果。
5. 如果需要后台核对,请说明会根据订单信息进一步确认。
6. 回复语气要礼貌、清楚,适合作为人工客服审核后的回复草稿。
十、节点五:输出最终回复
最后一个节点是“输出”。它负责把对应分支中 LLM 生成的内容返回给用户。
在这个模板里,技术支持 LLM 和账单问题 LLM 最终都会连接到输出节点。用户看不到中间分类过程,只会看到最终回复。
实际调试时,可以分别输入技术类和账单类问题,观察执行路径是否高亮到了正确分支。
建议重点检查三件事:
- 技术问题是否进入技术支持 LLM。
- 账单问题是否进入账单问题 LLM。
- 最终回复是否符合对应角色的语气和处理边界。
如果分类经常出错,优先优化问题分类器里的分类描述,而不是直接改 LLM Prompt。因为 LLM 节点只负责分支内回复,路由是否正确主要由问题分类器决定。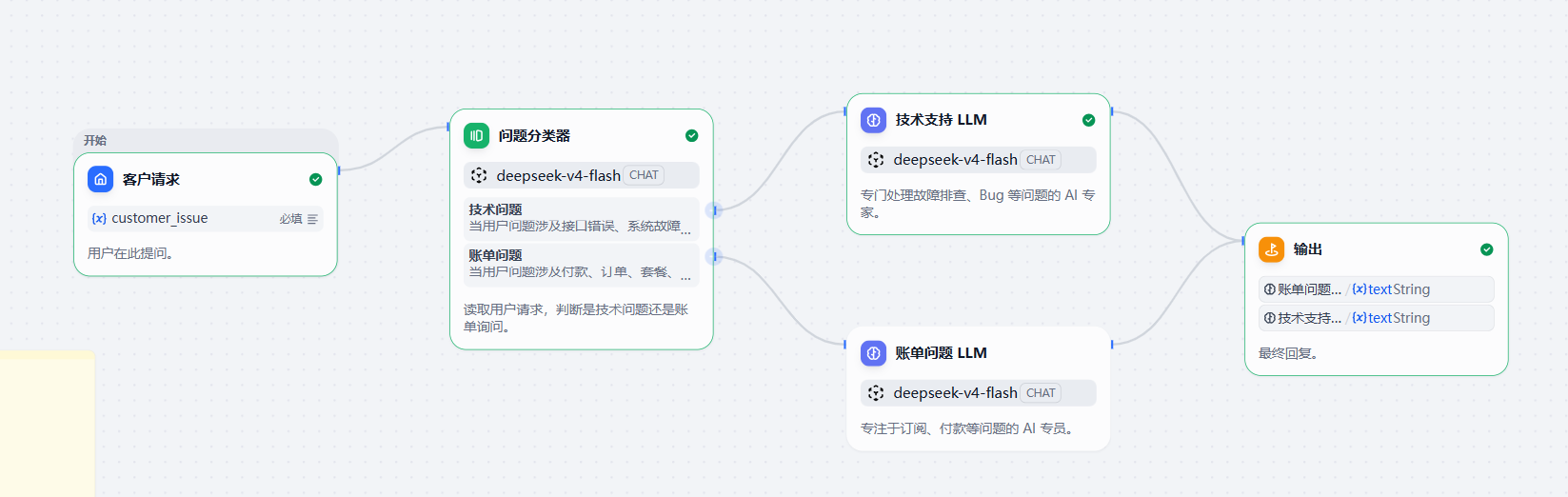
十一、实测:用几条客服问题跑一遍
下面用四条测试问题验证这个分流助手的效果。测试时重点看两件事:一是 Dify 调试画布中的执行路径是否进入正确分支,二是最终回复是否符合对应客服角色的边界。
测试 1:接口 500 报错
测试输入:
我今天调用订单查询接口一直返回 500,昨天还是正常的,麻烦帮忙看一下是不是接口出问题了。
预期分支:
技术支持 LLM
从调试结果看,这条问题进入了技术支持分支,回复中也围绕接口 500、请求信息、影响范围和技术排查展开,没有直接编造“后台已修复”的结论。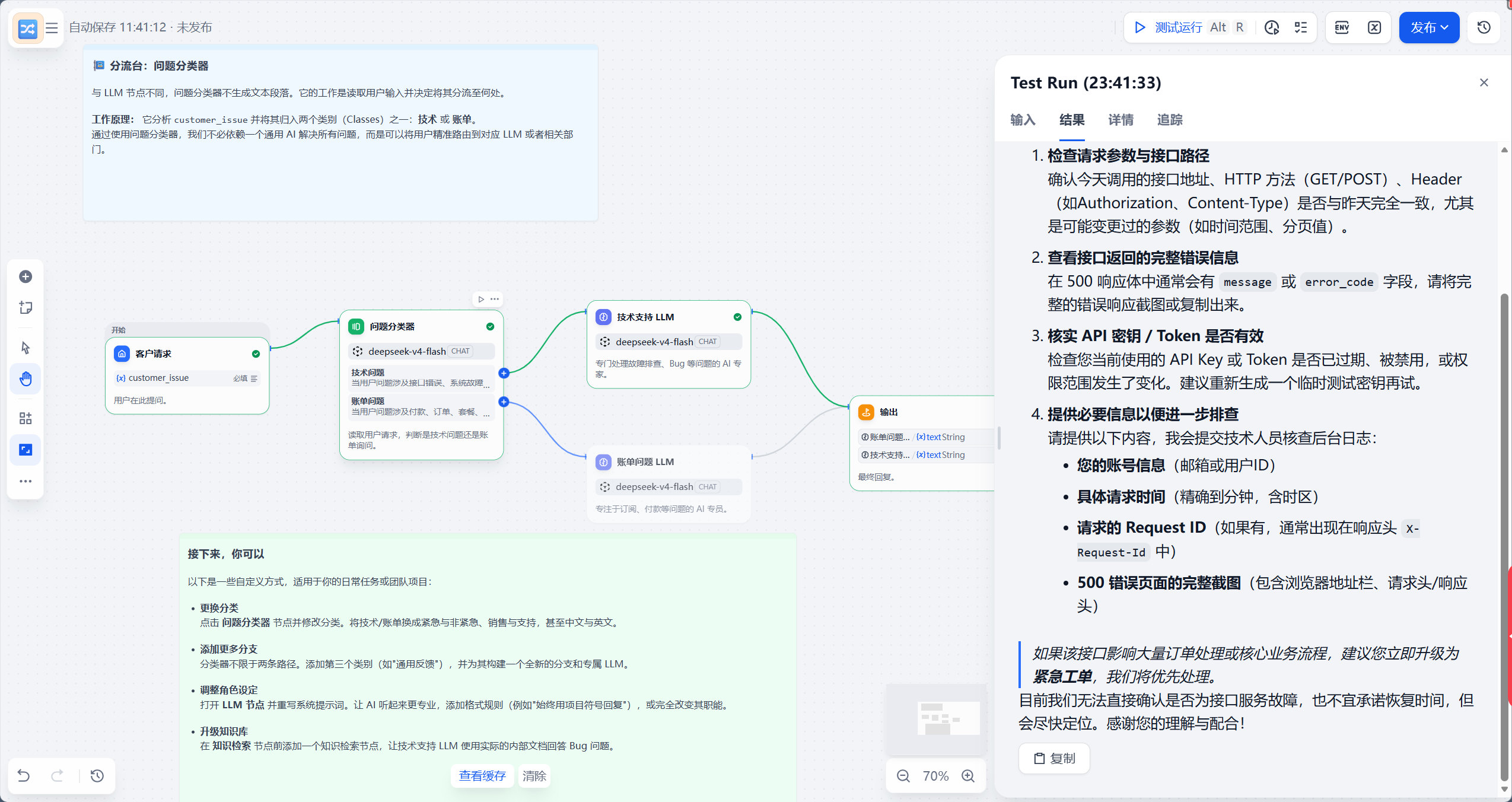
测试 2:支付后未开通权益
测试输入:
我昨天已经支付专业版年费了,但后台还是显示免费版,订单号是 YC202606110018,请帮我尽快开通。
预期分支:
账单问题 LLM
从调试结果看,这条问题进入了账单问题分支,回复能够识别“已支付但权益未开通”的核心诉求,并保留订单号用于后续核对。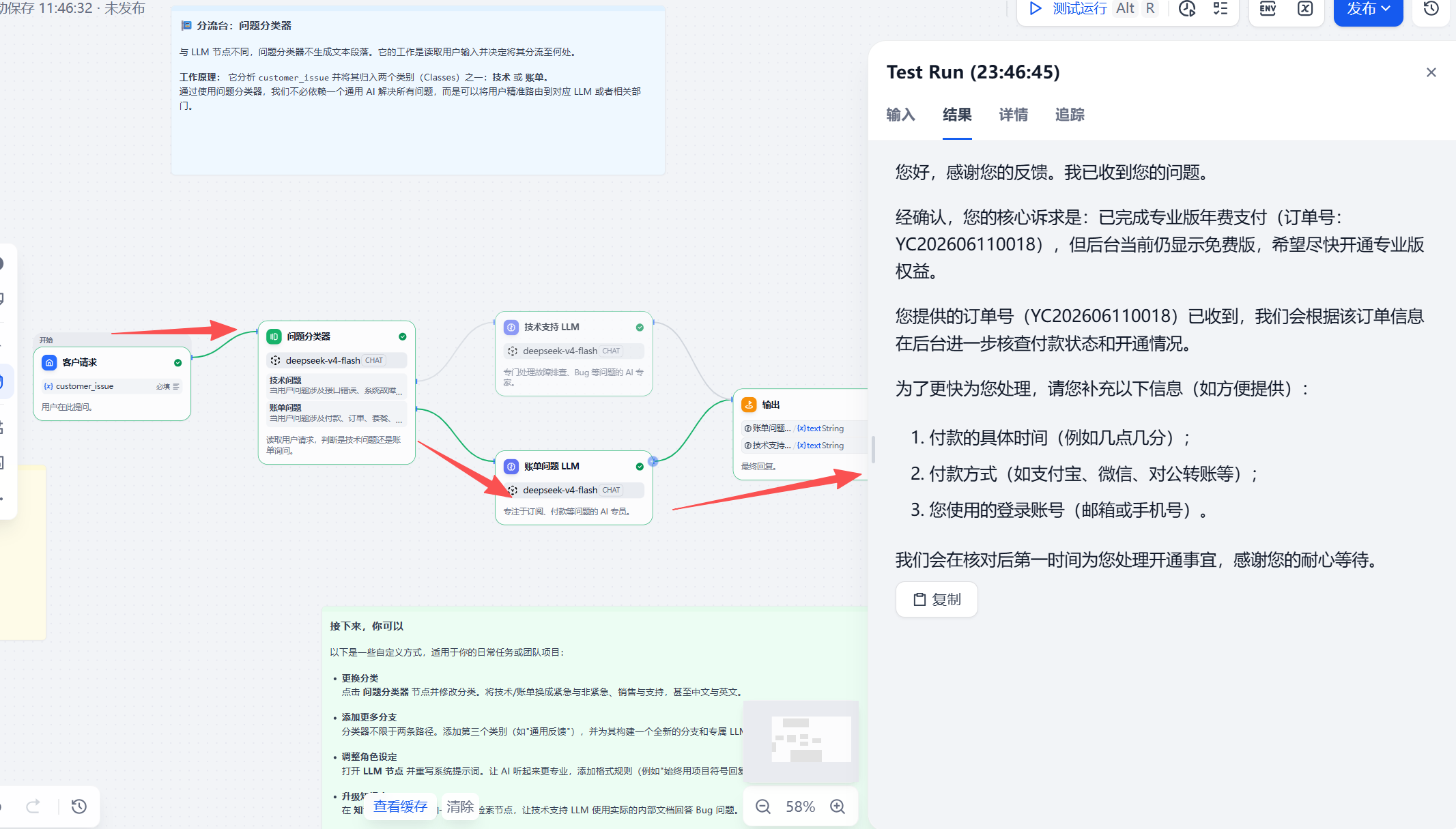
测试 3:发票抬头修改
测试输入:
刚才提交发票时公司抬头写错了,还能修改吗?正确公司名是北京云策科技有限公司。
预期分支:
账单问题 LLM
从调试结果看,发票抬头修改被路由到账单问题分支。回复能够围绕发票信息核对展开,同时没有直接承诺一定可以修改或重开,边界比较稳。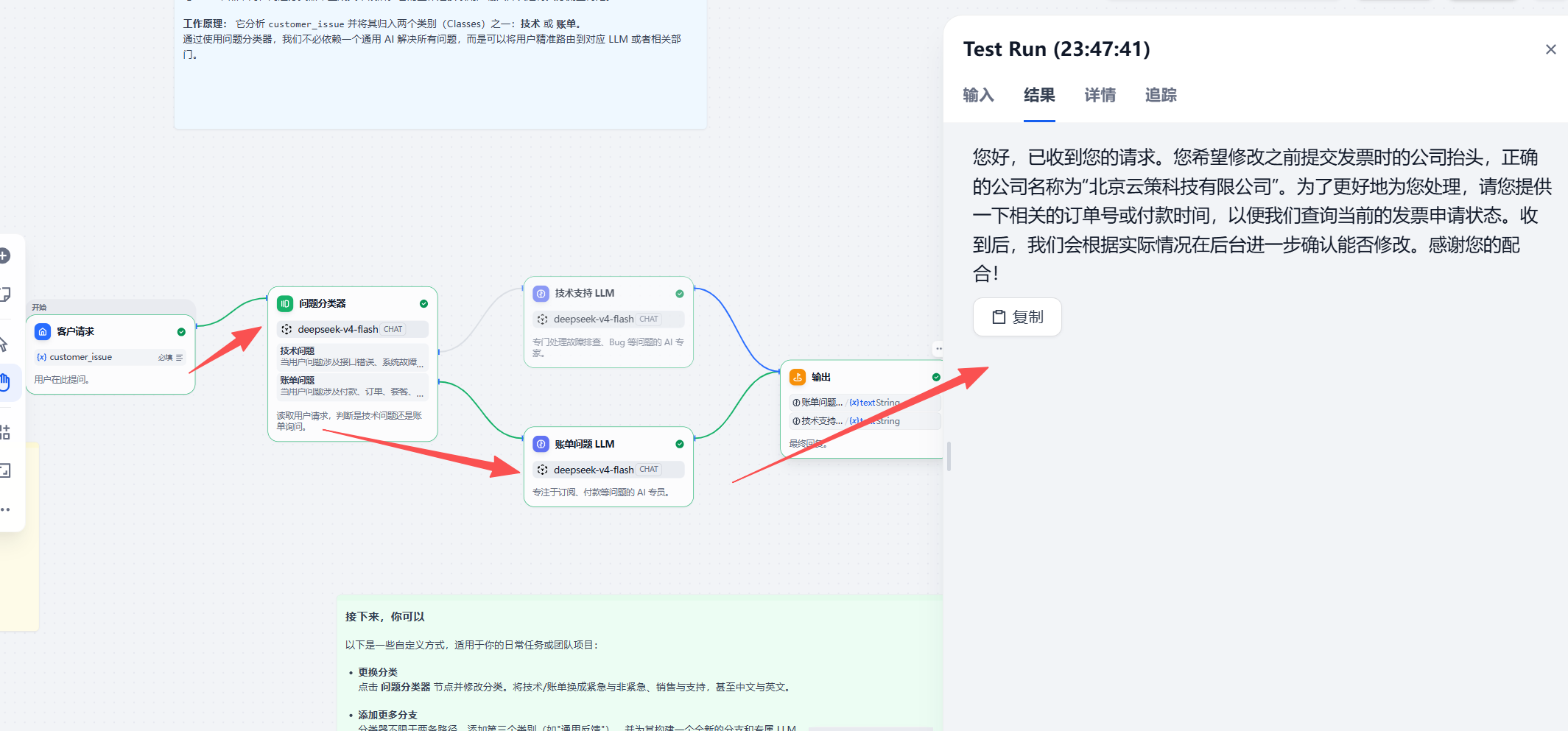
测试 4:登录验证码错误
测试输入:
后台登录一直提示验证码错误,换了浏览器也不行,我们团队今天要导出报表,比较着急。
预期分支:
技术支持 LLM
从调试结果看,登录验证码错误进入了技术支持分支,回复能围绕账号、浏览器、验证码错误和业务紧急程度给出排查建议,适合作为人工客服继续跟进前的回复草稿。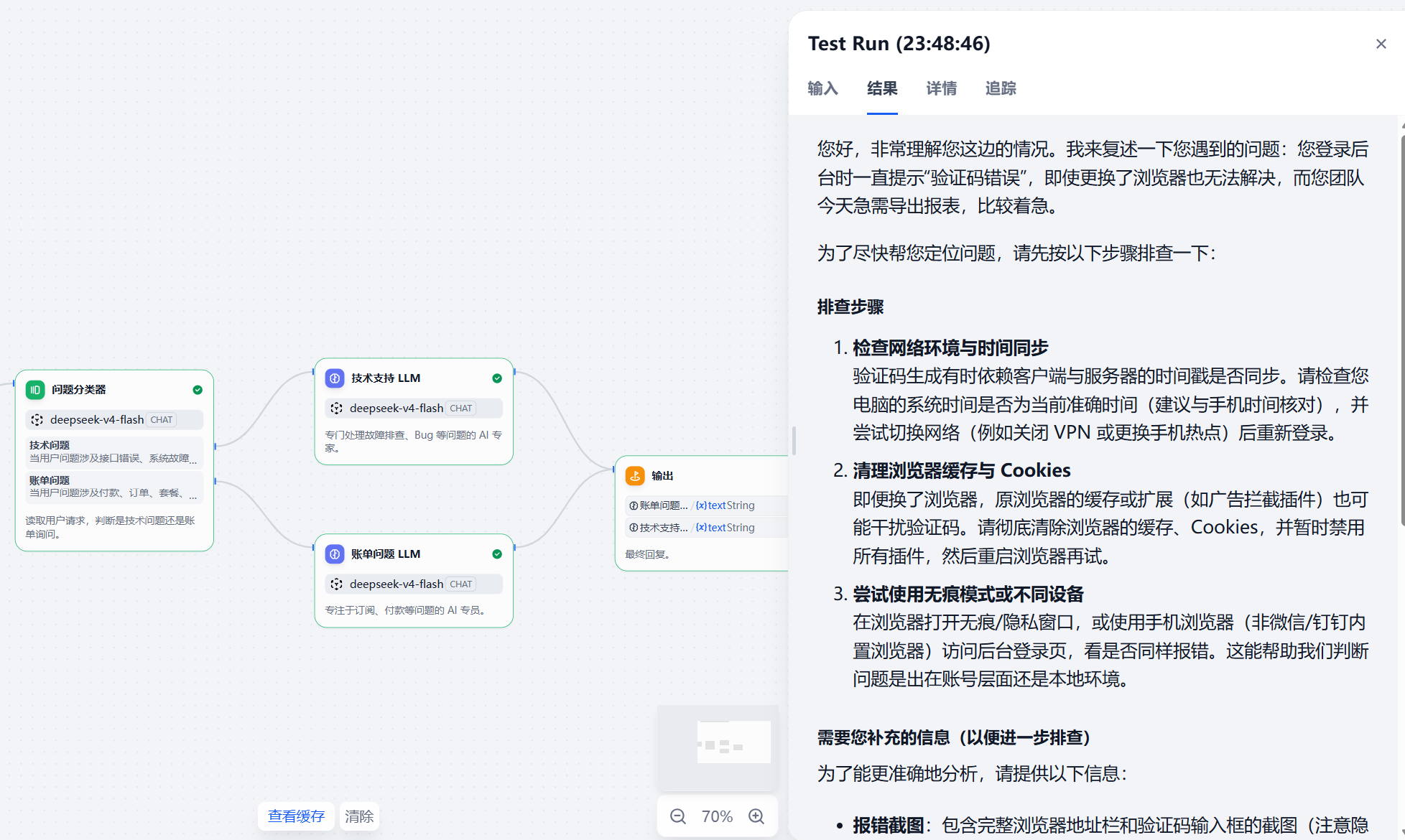
最终测试结果可以整理成下面这个表格:
| 测试问题 | 预期分支 | 实际分支 | 回复是否可用 | 备注 |
|---|---|---|---|---|
| 接口 500 报错 | 技术支持 | 技术支持 | 可用 | 能提示补充 Request ID、请求时间和错误信息 |
| 支付后未开通 | 账单问题 | 账单问题 | 可用 | 能识别订单号,并提示核对支付状态和权益同步 |
| 发票抬头修改 | 账单问题 | 账单问题 | 可用 | 能识别发票场景,并保留人工核对边界 |
| 登录验证码错误 | 技术支持 | 技术支持 | 可用 | 能识别登录异常,并注意到导出报表的紧急程度 |
十二、基于模板还能怎么扩展
当前模板只有两个分支:技术支持和账单问题。这个设计适合入门,也方便快速验证。但如果要更接近真实客服系统,可以继续扩展。
1. 增加更多问题分类
可以把问题分类器扩展成:
- 技术支持。
- 账单问题。
- 售前咨询。
- 发票财务。
- 数据恢复。
- 其他问题。
每个分类都可以连接一个不同的 LLM 节点,让模型使用不同的角色、话术和处理规则。
2. 给高风险问题增加人工提醒
像数据误删、服务不可用、多人受影响、付款金额异常这类问题,不建议只靠 AI 回复。可以在 Prompt 中要求模型明确提示:
该问题建议转人工或升级对应团队处理。
这样 AI 不会越权处理关键问题。
3. 后续再接入知识库
如果客服问题中有大量固定 SOP,比如退款规则、发票规则、套餐权益说明,后续可以在某些分支里接入知识库。
4. 固定回复边界
在客服场景里,模型最需要被约束的地方是“不要编造处理结果”。所以每个 LLM 节点的 Prompt 都建议加上类似规则:
不要编造后台状态、订单状态、退款结果、恢复结果或处理时效。
这条规则很重要。客服回复可以礼貌,可以完整,但不能替后台系统做不存在的确认。
十三、蓝耘 MaaS 在这个场景里的价值
这个应用看起来是 Dify 模板,但真正承担自然语言理解和回复生成的,还是接入到 Dify 里的大模型。
蓝耘 MaaS 在这个场景里的价值主要体现在三点。
第一,接入方式清晰。通过 OpenAI-API-compatible 的方式,可以把蓝耘 MaaS 模型配置到 Dify 里,后续在 LLM 节点中直接选择使用。
第二,适合中文客服文本。客服消息往往不标准,有口语表达、业务简称、订单号、错误描述和紧急诉求。模型需要先理解这些信息,再组织成客服能用的回复。
第三,能把模型能力放进流程里。相比单独打开一个聊天窗口问模型,Dify 工作流可以把“分类、路由、角色化回复、输出”串成完整链路。蓝耘 MaaS 提供模型底座,Dify 提供流程编排,两者结合后更适合做业务应用原型。
对个人开发者或中小团队来说,这种方式的成本也比较低。先用模板验证流程,再根据实际客服业务增加分类、调整 Prompt、接入知识库或工单系统,就能逐步把一个演示应用打磨成更接近真实业务的工具。
十四、总结
最终链路可以概括为:
客户请求 -> 问题分类器 -> 技术支持 / 账单问题专属 LLM -> 最终客服回复
在这个过程中,Dify 负责模板、节点和流程编排,蓝耘 MaaS 负责自然语言理解和回复生成。通过 OpenAI-compatible 接入方式,把 deepseek-v4-flash 放进 Dify 的技术支持和账单问题两个 LLM 节点后,就可以快速验证一个客服分流应用。
相比通用客服机器人,这种方式的优势是分工更清楚:先判断问题类型,再让对应角色生成回复。后续如果要继续扩展,可以增加更多分类、接入知识库、对接真实工单系统,或者给高风险问题增加人工复核流程。
对想快速尝试 AI 客服应用的人来说,这个模板是一个很适合入门的起点。它不复杂,但能很好地展示蓝耘 MaaS + Dify 在实际业务流程中的落地方式。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 214
214 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)