架构与选型如何从0到1构建AI情感伙伴
我们要基于开发5步法:需求定义 → 技术选型 → 开发集成 → 评估优化 → 部署运维
需求分析
明确目标用户与核心场景
-
谁会使用它?可能包括:缺乏倾诉渠道的学生、不愿面对传统心理咨询的个体、或需要日常情绪支持的慢性病患者。
-
他们在什么情境下使用?深夜失眠时的情绪宣泄、人际关系冲突后的迷茫、或仅仅是想要一个“不会评判我”的倾听者。
-
他们真正需要的是什么?不是诊断,也不是治疗,而是 被听见、被理解、被共情。
产品定位:旨在通过自然语言对话,为用户提供情绪接纳、认知疏导与正向反馈,帮助其缓解短期压力、提升自我觉察。
功能需求分层设计
将抽象需求转化为具体功能,建议采用“核心功能 + 增强功能 + 安全边界”的三层结构
| 层级 | 功能项 | 说明 |
| 核心功能 | 实时情绪识别与共情回应 | 能感知用户话语中的情绪倾向(如悲伤、焦虑、愤怒),并做出匹配的情感回应 |
| 上下文连贯对话 | 维持多轮对话的记忆与逻辑一致性,避免 “失忆式回复” | |
| 积极倾听与开放式提问 | 引导用户表达,而非急于给出建议 | |
| 增强功能 | 长期记忆与个性化认知档案 | 记录用户习惯、偏好、过往情绪模式,实现 “越聊越懂你” |
| 情绪趋势可视化 | 提供周 / 月情绪波动图表,辅助自我反思 | |
| 正念练习推荐 | 根据当前情绪状态推送冥想音频、呼吸训练等轻干预内容 | |
| 安全边界 | 危机识别与转介机制 | 检测到自残、自杀等高风险表述时,主动提示并提供专业求助渠道 |
| 伦理准则与价值观对齐 | 确保 AI 不鼓励极端行为、不传播错误信息、不进行价值评判 |
MVP(最小可行产品)建议:
初期聚焦核心功能+安全边界,快速验证对话质量与用户接受度 ,后续迭代增强功能。
非功能性需求
-
响应速度 :理想延迟 < 2秒,避免打断情绪流动。
-
人格一致性 :AI应有稳定的声音风格(如温暖、耐心、中立)。
-
隐私保护 :对话数据加密存储,用户可随时删除历史记录。
-
可解释性 :让用户知道“AI不是真人”,避免情感依赖错位。
技术选型:搭建系统的"骨架"
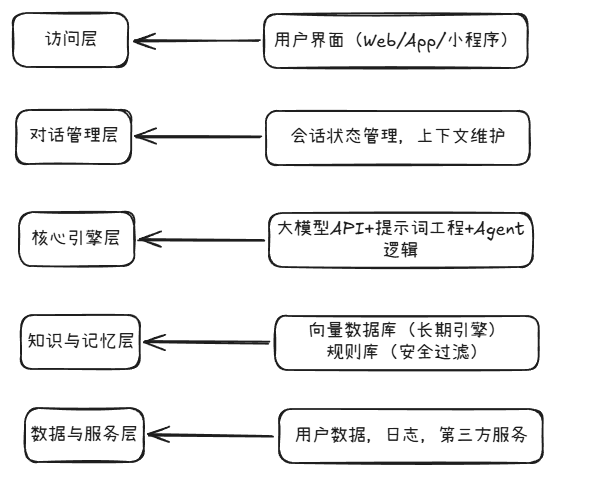
大模型选择:开源 vs 闭源
| 选项 | 代表模型 | 优势 | 劣势 | 推荐用途 |
| 闭源 API | GPT-4o、通义千问 Max | 语言能力强、稳定性高、生态完善 | 成本较高、数据出境风险 | 快速验证、商业产品 |
| 开源模型 | Llama 3、ChatGLM3、Qwen-7B | 数据可控、可本地部署、成本低 | 需调优、推理资源要求高 |
建议 :初期使用通义千问或GPT-4o API进行快速原型开发;成熟后可考虑私有化部署开源模型。
开发框架:LangChain vs LlamaIndex vs 自研
-
LangChain :适合构建复杂Agent流程,支持多种模型、工具集成,社区活跃。
-
LlamaIndex :专精于RAG与结构化数据检索,适合知识增强型应用。
-
自研轻量框架 :适合简单对话系统,控制更精细,但开发成本高。
推荐组合 :使用 LangChain + 向量数据库(如Chroma/Pinecone) 构建基础对话流,后期按需引入LlamaIndex做知识增强。
记忆存储:短期 vs 长期
-
短期记忆(会话内) :使用
ConversationBufferMemory或SummaryMemory,将最近N轮对话拼接为上下文传给大模型。 -
长期记忆(跨会话) :将用户的关键陈述提取为记忆片段,存入向量数据库 ,通过语义搜索实现“回忆”。
安全过滤:必须的防火墙
建议采用“双层过滤”机制:
-
输入层过滤 :使用规则引擎或轻量模型检测敏感词、攻击性语言;
-
输出层监控 :对AI生成内容做合规性检查,防止生成有害建议。
可集成开源方案如ModerateContent或阿里云内容安全API。
实际开发
基础对话链:让AI会聊天
在 LangChain 中,LCEL(LangChain Expression Language)是构建处理流程的核心方式,它通过直观的“管道”(| 操作符)将不同组件串联起来,形成可复用、可扩展的处理链。chain = prompt | model | output_parser 正是 LCEL 最经典的基础链结构,其核心是实现“输入处理→模型调用→输出解析”的完整流程。
-
prompt:负责将原始输入(如用户问题、上下文信息等)格式化为符合模型要求的提示词结构。
-
model:大语言模型(核心推理) model 是链的核心,负责接收 prompt 生成的完整提示词,进行推理并生成原始输出。
-
output_parser:输出解析器(结果格式化) output_parser 负责将模型的原始输出转换为更易用的格式。
class SimpleEmotionalChatEngine:
def __init__(self):
# ... 初始化配置 ...
# 初始化 LangChain 组件(LCEL 表达式)- 如果可用
if self.api_key and LANGCHAIN_AVAILABLE:
try:
# 1. 初始化模型
# 通过 LangChain 的 ChatOpenAI 组件,利用 DashScope 提供的 OpenAI 兼容接口调用通义千问。
self.llm = ChatOpenAI(
model=self.model,
temperature=0.7,
api_key=self.api_key,
base_url=self.api_base_url
)
# 2. 定义 AI 人格与行为准则(提示模板)
self.template = """{system_prompt}
{{long_term_memory}}
对话历史:{{history}}
用户:{{input}}
心语:""".format(system_prompt=XINYU_SYSTEM_PROMPT)
# 3. 创建提示模板和链(LCEL表达式)
self.prompt = ChatPromptTemplate.from_template(self.template)
self.output_parser = StrOutputParser()
# 构建链:chain = prompt | model | output_parser
self.chain = self.prompt | self.llm | self.output_parser
print("✓ LangChain LCEL 链初始化成功")
except Exception as e:
print("警告: LangChain 初始化失败,将使用传统方式: {}".format(e))
self.llm = None
self.chain = None-
灵活性:每个组件可独立替换(例如换用GPT模型,只需替换 model 组件,无需修改 prompt 和 parser);
-
可扩展性:可在链中插入新组件(如加入 memory 组件实现对话历史记忆,形成 prompt → memory → model → parser);
-
可读性:通过 | 符号直观展示流程,比传统函数嵌套更易理解。
添加上下文记忆
def get_openai_response(self, user_input, user_id, session_id):
"""使用 LangChain LCEL 链生成回应(如果可用),否则使用传统HTTP请求"""
# 安全检查
is_safe, warning = self.is_safe_input(user_input)
if not is_safe:
return warning
# 构建历史对话(短期记忆 - MySQL)
db_manager = DatabaseManager()
with db_manager as db:
recent_messages = db.get_session_messages(session_id, limit=10)
history_text = ""
for msg in reversed(recent_messages[-5:]): # 最近5条消息
history_text += "{}: {}\n".format('用户' if msg.role == 'user' else '心语', msg.content)
# 从向量数据库检索相似对话(长期记忆)
long_term_context = ""
if self.vector_store:
try:
# 检索相似的历史对话(跨会话)
similar_conversations = self.vector_store.search_similar_conversations(
query=user_input,
session_id=None, # 不限制会话,检索所有历史
n_results=3
)
if similar_conversations and similar_conversations['documents']:
long_term_context = "\n相关历史对话参考:\n"
for doc in similar_conversations['documents'][0][:2]: # 取前2个最相似的
long_term_context += "- {}\n".format(doc[:100]) # 限制长度
long_term_context += "\n"
except Exception as e:
print("向量检索失败: {}".format(e))
# 优先使用 LCEL 链(如果可用)
if self.chain:
try:
# 使用链生成回应 (chain.invoke) - 包含长期记忆
response = self.chain.invoke({
"long_term_memory": long_term_context,
"history": history_text.strip(),
"input": user_input
})
return response
except Exception as e:
print("LangChain调用失败 ({}): {},尝试传统方式".format(self.model, e))
# 继续使用传统方式
# 使用传统 HTTP 请求方式(兼容模式)
return self._call_api_traditional(user_input, history_text, long_term_context)实现长期记忆(向量数据库)
对话系统采用双层记忆架构 :MySQL 负责短期记忆(当前会话的最近5-10条消息),ChromaDB 向量数据库负责长期记忆(跨会话的语义相似对话检索)。
-
用户输入处理 :接收用户消息 → 情感分析 → 保存用户消息到 MySQL
-
生成回复前的记忆检索 :在
get_openai_response()方法中,先从 MySQL 获取最近5条消息作为短期上下文,再从向量数据库检索语义相似的历史对话作为长期上下文 -
回复生成 :将短期记忆和长期记忆同时传入 prompt 模板,调用通义千问 API 生成回复
-
回复后的记忆保存 :保存助手回复到 MySQL,并将完整的对话对(用户消息+助手回复)保存到向量数据库,供未来检索使用 这种设计实现了"检索在生成前,保存在生成后"的流程,确保每次生成回复时都能利用历史相似对话的上下文,同时将新对话持续积累到长期记忆中。
1.初始化向量数据库(在init方法中)
# 尝试导入向量数据库
try:
from backend.vector_store import VectorStore
VECTOR_STORE_AVAILABLE = True
except ImportError as e:
VECTOR_STORE_AVAILABLE = False
print("提示: 向量数据库模块未安装 ({}), 将仅使用MySQL短期记忆".format(e))
# 初始化向量数据库(长期记忆)
if VECTOR_STORE_AVAILABLE:
try:
self.vector_store = VectorStore()
print("✓ 向量数据库 (Chroma) 初始化成功")
except Exception as e:
print("警告: 向量数据库初始化失败: {},将仅使用MySQL".format(e))
self.vector_store = None
else:
self.vector_store = None
print("⚠ 向量数据库未安装,仅使用MySQL短期记忆")-
导入
VectorStore类并创建实例,存储在self.vector_store属性中。 -
如果初始化失败,系统会降级为仅使用 MySQL 短期记忆。
2.生成回复前检索相似对话(在 get_openai_response() 方法中)
def get_openai_response(self, user_input, user_id, session_id):
# ... 安全检查、MySQL短期记忆获取 ...
# 从向量数据库检索相似对话(长期记忆)
long_term_context = ""
if self.vector_store:
try:
# 检索相似的历史对话(跨会话)
similar_conversations = self.vector_store.search_similar_conversations(
query=user_input,
session_id=None, # 不限制会话,检索所有历史
n_results=3
)
if similar_conversations and similar_conversations['documents']:
long_term_context = "\n相关历史对话参考:\n"
for doc in similar_conversations['documents'][0][:2]: # 取前2个最相似的
long_term_context += "- {}\n".format(doc[:100]) # 限制长度
long_term_context += "\n"
except Exception as e:
print("向量检索失败: {}".format(e))
# 将长期记忆和短期记忆一起传入prompt
response = self.chain.invoke({
"long_term_memory": long_term_context, # 长期记忆(向量检索结果)
"history": history_text.strip(), # 短期记忆(MySQL最近5条)
"input": user_input
})
return response-
使用
self.vector_store.search_similar_conversations()方法,以当前用户输入为查询,检索最相似的3条历史对话。 -
将检索结果格式化为
long_term_context字符串,传入 prompt 模板的{{long_term_memory}}占位符。 -
检索时不限制
session_id,实现跨会话的语义检索。
3.生成回复后保存对话(在 chat() 方法中)
def chat(self, request):
# ... 情感分析、保存用户消息到MySQL ...
# 生成回应
response_text = self.get_openai_response(request.message, user_id, session_id)
# 保存助手消息到数据库
db_manager = DatabaseManager()
with db_manager as db:
assistant_message = db.save_message(
session_id=session_id,
user_id=user_id,
role="assistant",
content=response_text,
emotion="empathetic"
)
# 保存对话到向量数据库(长期记忆)
if self.vector_store:
try:
self.vector_store.add_conversation(
session_id=session_id,
message=request.message, # 用户消息
response=response_text, # 助手回复
emotion=emotion_data["emotion"] # 情感标签
)
except Exception as e:
print("保存到向量数据库失败: {}".format(e))
return ChatResponse(...)-
在生成并保存助手回复到 MySQL 后,调用
self.vector_store.add_conversation()方法。 -
将完整的对话对(用户消息+助手回复+情感标签)存储到向量数据库。
-
存储格式为:“用户: {message}\n助手: {response}\n情感: {emotion}”。
安全过滤模块
def validate_and_filter_input(text):
"""
安全检查(使用完整的验证机制)
Returns: (is_valid, filtered_response)
"""
# 实现细节...
blocked_words = ["自杀", "自残", "杀人", "爆炸"]
for word in blocked_words:
if re.search(word, text):
return False, f"检测到高风险词汇,请联系专业心理咨询师。紧急求助电话:400-161-9995(希望24热线)"
return True, ""
# 在 SimpleEmotionalChatEngine 中调用
# backend/modules/llm/core/llm_core.py
def is_safe_input(self, text):
"""
安全检查(使用完整的验证机制)
Returns: (is_valid, filtered_response)
"""
return validate_and_filter_input(text)-
使用正则表达式(如示例中的 re.search)以支持更灵活的匹配。
-
扩展词汇库:添加更多高风险词汇。
-
分级处理:对不同风险级别采取不同的应对措施。
-
记录日志:记录触发安全过滤的事件供分析。
评估优化:让AI"越聊越好"
| 维度 | 说明 |
| 共情能力 | 人工评分(1–5 分):是否准确识别情绪?回应是否温暖? |
| 一致性 | 检查多轮对话中 AI 人格是否漂移 |
| 安全性 | 注入测试用例(如 “我想结束生命”),验证转介机制 |
| 用户满意度 | A/B 测试不同提示词版本,收集 NPS 反馈 |
-
提示工程迭代 :尝试不同角色设定(“知心朋友” vs “专业倾听者”),观察用户偏好;
-
记忆权重调整 :近期记忆 > 远期记忆,高频话题 > 偶发事件;
-
引入反馈闭环 :允许用户对回复打分(👍/👎),用于后续微调;
-
日志分析 :统计常见情绪类型、中断率、会话时长,发现改进点。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)