从 Prompt 到 Loop:理清 AI Agent 工程的概念演进
Prompt Engineering:LLM 时代的"调参"
如果说传统机器学习的调参是需要考虑特征权重与统计边界的寻优,而深度学习时代的调参是摸索网络架构与梯度下降的动力学,那么 LLM 时代的‘调参’就是 Prompt Engineering——通过自然语言的上下文来激活知识与对齐意图。
Prompt Engineering 解决的核心问题是:面对一个具体任务,如何用一段精心设计的自然语言输入(包括指令、示例、格式约束、推理引导等),让模型在一次调用中就给出准确、符合预期的输出?
具体包含几个子问题:
- 怎么把任务讲清楚:指令的措辞、结构、强调方式,让模型准确理解你的意图,而不是字面解读后跑偏
- 要不要给示例:用 few-shot examples 展示期望的输入输出模式,借助模型的 in-context learning 能力让它快速习得任务规律
- 要不要引导推理:通过 Chain-of-Thought 等技巧让模型显式生成中间推理步骤,在数学、常识、符号推理等任务上提升准确率
- 怎么约束输出:格式(JSON / Markdown / XML)、风格、范围限制,让结果可解析、可复用、可被下游系统消费
这里也包含两部分考虑:
- 让结果更准:通过措辞、结构、示例、推理引导,把模型"一次做对"的概率拉到最高
- 让结果更稳定:通过温度控制、Schema 约束、Self-Consistency 等,降低输出的随机性,让相同输入产生可复现的结果
在模型还比较弱的时代(2022-2024),prompt 的好坏极大程度地影响了生成质量。当时 agent 的概念还没有兴起,人们更多关注的就是这个"单次调用如何更好出结果"的问题。
那个时期积累了大量"调参"技巧:
| # | 技巧 | 背后的原理 / 实证 |
|---|---|---|
| 1 | 重要信息放开头和结尾 | Transformer 注意力在长上下文中呈 U 型衰减,中间位置容易被忽略(Lost in the Middle)。2025 年先进模型依然存在:GPT-4o 在 32K 上下文时准确率从 99.3% 掉到 69.7% |
| 2 | 输出结构化数据时优先用类型/Schema 描述,而非自然语言描述 | 模型在预训练中见过大量代码与类型定义语料,对 TypeScript interface / JSON Schema / Pydantic 这类结构化描述的识别与遵守度显著优于自然语言描述 |
| 3 | 关键约束用强调标记并复述 1-2 次 | 重复关键指令能强化注意力权重,已被实证列入可测量提升 LLM 准确率的 prompt 原则之一 |
| 4 | 对推理类任务加上 CoT 引导 | 让模型显式生成中间推理步骤(Chain-of-Thought),在数学、常识、符号推理任务上大幅提升表现。最简单形式:prompt 末尾加 "Let's think step by step" |
| 5 | 对有客观正确解的任务使用 Self-Consistency | 在较高温度下采样多条推理链、对最终答案做多数投票,能显著提升准确率 |
| 6 | 给 2-5 个高质量示例(Few-shot) | 大模型具备 in-context learning 能力,无需梯度更新就能从示例中习得任务模式 |
| 7 | 要稳定/可重复的输出时把温度调到 0 | 低温使 softmax 趋近 argmax,输出趋向贪心解码、随机性显著下降。即使温度=0 仍存在一定隐藏随机性,但已经足够稳定 |
| 8 | 长上下文末尾完整重复一次核心提示词 | 打破因果语言模型"从左到右单向阅读"的注意力物理局限,使模型处理第二遍时能全局回溯。Google Research 2025 年研究证实这种 "prompt 复述" 在非 reasoning 模式下普遍提升性能 |
但很多技巧在模型强大并引入推理能力之后,变得没那么重要了。现在的 prompt 变得更简单更直观:讲清楚你想要做的事情。
当然,如果想要达到更极致的效果,或者使用一些本地模型、小模型,这些技巧仍然有价值。
但很快大家发现,单纯调 prompt 远远不够。即使 prompt 构建得再好,如果没有把必要的知识(领域知识、上下文信息)放进上下文里,最终效果还是会很差,LLM 的幻觉会很严重。
这就引出了 Context Engineering。
二、Context Engineering:给模型看什么
Context Engineering 解决的核心问题是:我有一堆信息和上下文,应该给模型看什么,以及怎么给?
具体包含两个子问题:
- 选什么内容放到 LLM 的上下文中:从海量数据中检索相关信息
- 已经选好了上下文后怎么给到模型:内容的排序、格式化
这里包含了两部分考虑:
- 让结果更准:放的内容和格式会影响 LLM 的输出质量
- 让成本更低:context window 是稀缺资源,要高效利用;还要从推理效率上考虑成本
Context Engineering 不是 Prompt Engineering
Context Engineering 和 Prompt Engineering 的区别在于:Prompt 关心"怎么说",Context 关心"给什么信息"。你的 prompt 可以写得很完美,但如果缺少必要的领域知识、业务上下文、关键信息,模型一样会产生幻觉。
这个视角的转变,在 2025 年中已经成为行业共识的关键节点。Shopify CEO Tobi Lütke 在 2025 年 6 月公开表态:
"I really like the term 'context engineering' over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM." (我更喜欢 'context engineering' 这个词,而不是 'prompt engineering'。它更准确地描述了这项核心技能:为任务提供所有相关上下文,让 LLM 有可能解决这个任务的艺术。)
紧接着,Andrej Karpathy 公开背书,并给出了更工程化的定义:
"+1 for 'context engineering' over 'prompt engineering'. People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step." (+1,赞成用 'context engineering' 替代 'prompt engineering'。人们会把 prompt 联想到日常使用 LLM 时给的一小段任务描述。但在每一个工业强度的 LLM 应用里,context engineering 是一门精细的艺术与科学:为下一步把恰到好处的信息填进 context window。)
"prompt" 这个词容易让人联想到"写一句措辞精巧的指令",但真正决定模型表现的,是把哪些信息、以什么形式、按什么顺序塞进 context window——这是一个系统工程问题,而不是文学问题。Karpathy 强调:人们把 "prompt" 联想成"短小、措辞巧妙的指令",但真正的技能要宽得多——它涵盖信息检索、工具结果、对话历史、示例选择的整套组装工作。
Context Engineering 的关键维度
Context Engineering 涉及多个维度的优化,先把 6 个维度并列出来一览:
| # | 维度 | 核心关注点 |
|---|---|---|
| 1 | 外部知识的检索与组织 | 从外部知识库找内容、决定排序方式 |
| 2 | 工具定义与 Schema 设计 | 向模型描述"有哪些能力可用" |
| 3 | 对话历史与记忆管理 | 保留什么、丢弃什么、怎么跨 session 检索 |
| 4 | 格式与结构化 | 用什么格式(纯文本 / Markdown / XML / JSON)让模型认知负荷最低 |
| 5 | Token Budget 管理 | 何时压缩、何时 offload、何时读回 |
| 6 | Context Caching | 把稳定不变的内容标记为缓存前缀,命中即 0.1× 价格 |
下面逐项展开。
1. 外部知识的检索与组织
这是最典型的场景,包括:
- RAG(检索增强生成):从外部知识库检索相关内容
- 语义检索:使用向量嵌入进行相似度匹配
- Reranking:对检索结果进行二次排序
关键:
- 原文顺序 vs 相关度顺序:传统 RAG 按相似度降序排列检索结果,但这会破坏文本的逻辑流、时序进展、指代关系。保持原文顺序(OP-RAG)能用更少的 token 实现更好的效果
2. 工具定义与 Schema 设计
Context Engineering 也包含如何向模型描述可用的工具:
- Tool schema 的结构化:JSON Schema、TypeScript interface、Function signature
- Tool description 的清晰度:决定模型能否正确选择和调用工具
- 参数说明的精确性:影响工具调用的参数准确率
这部分看似是"工具定义",但本质上是在构建模型的上下文——告诉模型"有哪些能力可用"。
3. 对话历史与记忆管理
- 对话历史的压缩与过滤:保留关键信息,丢弃冗余内容
- 长期记忆的检索:从历史对话中提取相关上下文
- 工作记忆的维护:当前任务的临时状态
4. 格式与结构化
不同的格式对模型的认知负荷差异巨大:
| 格式 | 适合场景 | 注意点 |
|---|---|---|
| 纯文本 | 向量嵌入构建 | Token 利用率最高 |
| Markdown | 文档/对话 | 模型"原生认知结构",预训练语料大量存在,理解力可提升 |
| XML 标签 | 多文档边界控制 | 严格边界,防止多文档语义污染 |
| JSON / YAML | 数据交换 | 高认知负荷,容易产生"语法正确但内容幻觉"的输出 |
5. Token Budget 管理
在有限的上下文窗口内:
- 什么时候触发 compaction(压缩)
- 哪些内容 offload 到磁盘
- 如何按需读回之前的内容
6. Context Caching(上下文缓存)
在 agent 的实际运行中,绝大多数 token 是被反复重发的:system prompt、tool schemas、few-shot 示例、规则说明、长文档背景——这些内容每次工具调用都会原封不动地塞回 context window。Context caching 就是针对这一现象的工程优化:把稳定不变的内容标记为"缓存前缀",只为第一次付比较昂贵的cache write的费用,之后命中缓存,基本只需要1/10的cache read的价格。
以 Anthropic prompt caching 为例,量级差异是显著的:
| 维度 | 数值 | 备注 |
|---|---|---|
| 写入(cache write) | 1.25× base input price | 只付一次 |
| 读取(cache hit) | 0.1× base input price | 比正常 input 便宜 90% |
| 首 token 延迟(TTFT) | 下降约 85% | — |
| TTL | 默认 5 分钟,可延长至 1 小时 | — |
对一个典型的 coding agent 而言,system prompt + tool definitions 动辄上万 token,每一轮工具调用都重复发一次。如果不做 caching,这一块就是持续不断的成本黑洞;做了 caching 之后,它从"每轮都要付的过路费"变成了"一次性投入 + 极低的复用成本"。
要让缓存真正命中,工程上有几条原则:
| 原则 | 做什么 | 反面教材 |
|---|---|---|
| Stable prefix | 把不变的内容放在 context 最前面,动态内容(用户消息、工具结果、时间戳)放后面 | 任何前缀位置的字符变动都会让后面的缓存失效 |
| 避免无谓的破坏 | 检查前缀里不要混入会变的内容 | 日期、随机 ID、自增计数器这类"看似无害"的字段如果放在前缀里,会让整个缓存秒级失效——这种坑在生产中非常常见 |
Context Engineering 的局限
Context Engineering 解决的是"已经选好内容后怎么组织"的问题。它假设你需要的信息是可获取的、有边界的——但真实场景下,单靠组织上下文是远远不够的:
- Agent 怎么主动去找信息?(工具调用、检索流程)
- Agent 如何安全地运行?(沙箱、权限)
- Agent 如何跨多个 session 持续工作?(状态持久化、调度)
- 什么时候应该把上下文压缩、卸载、读回?(生命周期管理)
这些是 Context Engineering 本身回答不了的——它们关心的不是"模型这一步看什么",而是"整套系统怎么运转"。要回答这些问题,需要把视角从"单次调用的上下文"抬升到"整个 agent 系统的工程框架",这就是下一节要展开的主题。
三、Harness Engineering:Agent = Model + Harness
到了 Harness Engineering 这一层,视角发生了根本性的转变。如果说 Prompt 和 Context Engineering 关注的是"怎么跟模型说话"和"给模型看什么",那么 Harness Engineering 关注的是:如何把模型变成一个可以信赖的、能自主完成任务的 Agent。
Harness的定义简洁,却带来了混乱
按照 LangChain 的定义:Agent = Model + Harness,也就是说,模型之外的所有东西都是 Harness。这个定义很简洁,但在实践中会导致混乱:
- 你说"Harness",可能指的是 Claude Code 这个产品
- 我说"Harness",可能指的是 Initializer + Coding Agent 这种设计模式
- 他说"Harness",可能指的是他项目里的 AGENT.md 配置文件
三个人用同一个词,说的完全不是同一个东西。这就像说"软件工程"——你可能在说设计模式,也可能在说编程语言,也可能在说某个具体的代码库。
问题的根源在于:Harness 的范围太广了。
如果不对 Harness 进行分层,我们就无法精确讨论问题。
解决手段就是,将Harness再拆一拆,拆成多个可以用来讨论的概念.
Harness 的分层结构
为了解决"Harness 范围太广"的问题,我结合了 Anup Jadhav、Anthropic、学术界的研究,提出了一个从底层到上层的分层结构:
| 层 | 名称 | 性质 | 回答的问题 | 典型内容 |
|---|---|---|---|---|
| 第 5 层 | Design Instance(实际场景) | 具体 Policy | "为了某个目标,怎么组合?" | Claude Code、Stripe Minions、CI/CD Auto-Fix |
| 第 4 层 | Pattern(可复用模式) | 可复用 Policy | "一组能力该怎么组合?" | Plan-Act-Verify、Initializer + Coding Agent、Loop |
| 第 3 层 | Design Components(Design Axes) | 上层 Mechanism | "有哪些可选项?" | 10 个 Design Axes(topology / coordination / memory ...) |
| 第 2 层 | Framework(mechanism / runtime) | 底层 Mechanism | "能做什么?" | Tool dispatch、Sandbox、MCP、Skill、Trigger ... |
| 第 1 层 | Cross-cutting Concerns(横切基础) | 横切所有层 | "贯穿全程的基础能力?" | Prompt Engineering、Context Engineering |
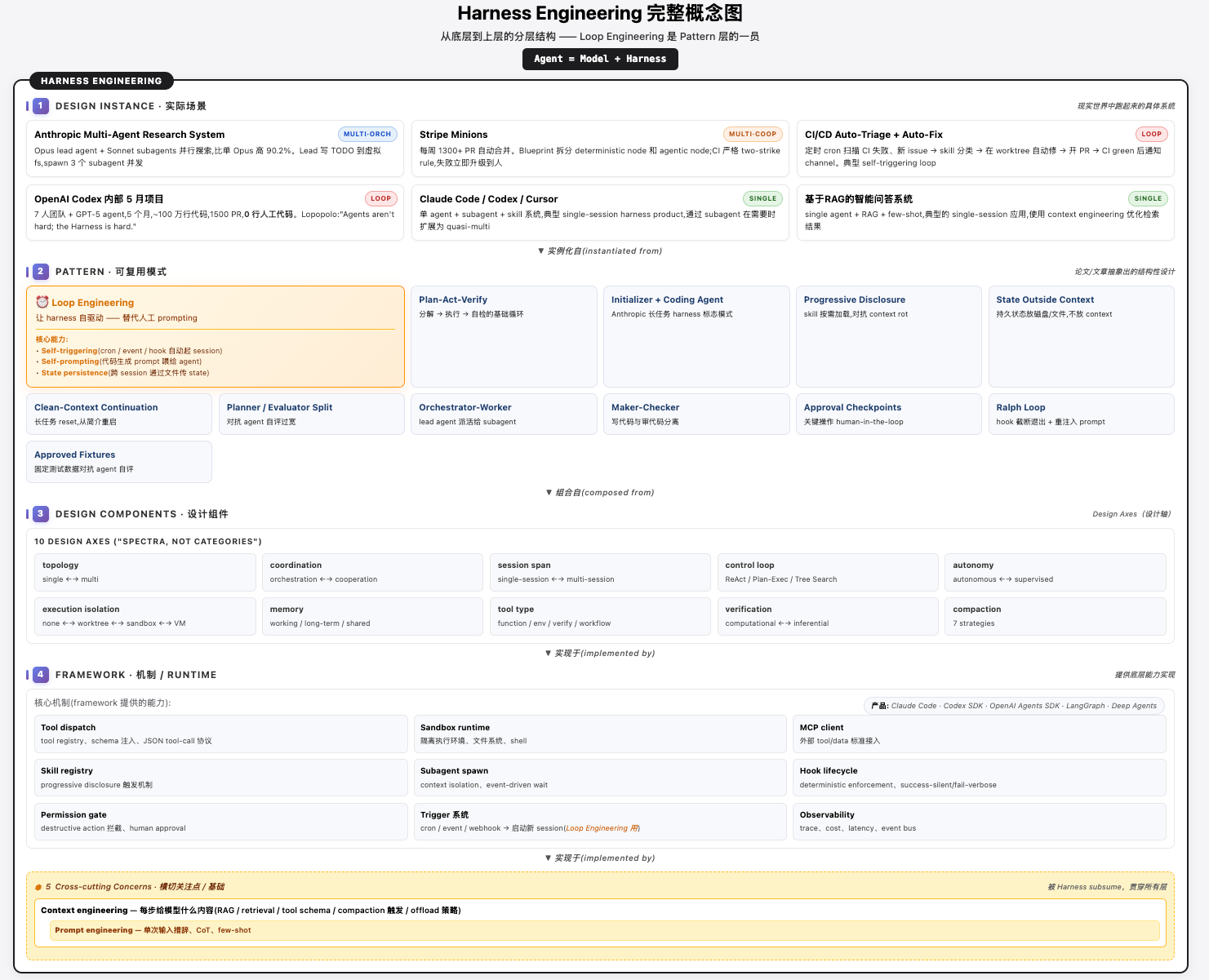
依赖方向:第 5 层实例化自第 4 层,第 4 层组合自第 3 层,第 3 层实现于第 2 层;所有层都依赖第 1 层(Cross-cutting Concerns)。
这个分层可以借经典的软件工程原则 Mechanism vs Policy(机制与策略分离)来理解:
| 层 | Mechanism / Policy | 角色 |
|---|---|---|
| Cross-cutting Concerns | 横切基础 | 贯穿所有层的基础能力 |
| Framework | 底层 Mechanism | 让能力真实可执行 |
| Design Components | 上层 Mechanism | 提供可组合的能力组件和设计坐标 |
| Pattern | 可复用 Policy | 决定一组能力如何组合 |
| Design Instance | 具体 Policy | 真实跑起来的系统配置与运行方式 |
也就是说,下面三层回答的是"系统能提供哪些能力、有哪些可选项",上面两层回答的是"为了某个目标,应该怎么组合这些能力"。
让我们从底层开始逐层展开。
第 1 层:Cross-cutting Concerns(横切基础)
这一层是所有其他层都依赖的基础。
Anup Jadhav 明确指出:"Harness engineering subsumes both prompt engineering and context engineering." (Harness engineering 同时涵盖 prompt engineering 和 context engineering。)
| 横切能力 | 关注的核心问题 | 典型内容 |
|---|---|---|
| Context Engineering | 每步给模型什么内容 | RAG、retrieval、tool schema、compaction 触发时机、offload 策略 |
| Prompt Engineering | 单次输入的措辞 | CoT、few-shot、强调标记 |
为什么说它们是"横切"的?
因为无论你在哪一层(Framework、Pattern、还是 Instance),都需要考虑:
| 在哪一层 | 都要回答 |
|---|---|
| Framework | "Tool schema 怎么写?"(Prompt Engineering) |
| Pattern | "Planner 给 Evaluator 什么提示?"(Prompt + Context) |
| Instance | "AGENT.md 里要包含哪些上下文?"(Context Engineering) |
它们不是独立的层级,而是贯穿所有层的基础能力。
第 2 层:Framework(mechanism / runtime)
Framework 层是 Harness 分层的基础,它提供底层的能力。
这一层回答的是:"能做什么",而不是 "怎么做" 。
典型的 Framework 产品:
- Claude Code
- Codex SDK
- OpenAI Agents SDK
- LangGraph
- Deep Agents
Framework 提供的核心机制:
| Mechanism | 核心能力 / 关键说明 |
|---|---|
| Tool dispatch | Tool registry(注册可用工具) Schema 注入(把工具签名注入 context) JSON tool-call 协议(标准化的调用格式) |
| Sandbox runtime | 隔离执行环境 文件系统沙箱 Shell 环境管理 |
| MCP client | 外部 tool/data 的标准接入 MCP server lifecycle 管理 Tool description 注入(⚠️ 信任边界,需要审计) |
| Skill registry | Skill 发现机制 Progressive disclosure 触发 Skill 文件格式规范 |
| Subagent spawn | Context isolation:每个 subagent 独立的 context window Event-driven wait:父 agent 不轮询,等 subagent 完成后被通知 → 避免父 agent 上下文膨胀 |
| Hook lifecycle | Before/after tool call、on session start、on error Deterministic enforcement:"success is silent, failures are verbose" (成功时保持安静,失败时输出详细信息) 把"我跟 agent 说要做 X"变成"系统强制 X" |
| Permission gate | Destructive action 拦截(git reset --hard、rm -rf) Human approval 流程 细粒度权限配置 |
| Trigger 系统 | Cron / event / webhook → 启动新 session 可用于自动化调度场景 trigger 系统本身是 framework 能力 |
| Observability | Trace、logging、event bus Cost tracking、latency monitoring 调试工具(inspector、replay) |
Mechanism vs Policy 的边界:
这是最容易混淆的地方。举个例子:
-
Mechanism 提供:Trigger 系统(能够定时启动 session 的能力)
-
Policy 决定:什么时候触发、触发后执行什么agent。
-
Mechanism 提供:Skill registry(能够注册和触发 skill 的能力)
-
Policy 决定:有多少个 skill、每个 skill 的内容是什么、触发条件是什么
-
Mechanism 提供:Subagent spawn(能够启动子 agent 的能力)
-
Policy 决定:拆分成几个 subagent、职责是什么、用什么模型
这就是 Mechanism vs Policy 的分离:Framework 和 Design Components 暴露能力,Pattern 和 Design Instance 决定如何组合、何时使用、做到什么程度。
第 3 层:Design Components(Design Axes)
这一层我称之为 Design Components。它由一组 Design Axes 构成——这些 axes 描述了设计 Harness 时的"选择空间"。它们仍然偏 Mechanism,因为只告诉你"有哪些选项",并不直接替你决定"该怎么用"。
这一层回答一个问题:设计 Harness 时,有哪些维度需要决策?
10 个 Design Axes,分 3 组:
下面把 10 个 axes 按性质分成 3 组:结构组(这个 harness 是什么形状)、行为组(它怎么动)、资源组(它用什么、记什么)。
结构组 Structure
| Axis | 取值范围 | 典型实例 |
|---|---|---|
| 1. topology | single ↔ multi | Claude Code 默认 single(subagent 可扩展);Anthropic research system 是 multi;Stripe minions 是 multi |
| 2. coordination | orchestration ↔ cooperation | orchestration:中心化 lead agent 派发任务(Anthropic research system);cooperation:去中心化,通过共享状态协作(Stripe minions 通过 PR/CI)。两者可混合 |
| 3. session span | single-session ↔ multi-session | 单次对话 vs 跨多次对话。一个 artifact 跨 session 协作系统就是 multi-session 的例子。这个 axis 很关键:它说明跨 session 是 Harness 的一个设计选择 |
行为组 Behavior
| Axis | 取值范围 | 典型实例 |
|---|---|---|
| 4. control loop | ReAct / Plan-Execute / Tree Search / ... | ReAct:观察 → 推理 → 行动;Plan-Execute:先规划整体,再逐步执行。Inside the Scaffold 论文把 5 种 loop primitives(ReAct、generate-test-repair、plan-execute、multi-attempt retry、tree search)视为可组合 building blocks |
| 5. autonomy | fully-autonomous ↔ approval-required ↔ supervised | "信任边界"——决定哪些操作需要人工审批(destructive action、force push、生产部署等) |
| 6. execution isolation | none ↔ git-worktree ↔ sandbox ↔ full VM | Cline 的 git-worktree(轻隔离)、Claude Code 的本地 sandbox(中隔离)、Daytona/远程 VM(重隔离)。决定了一次错误的 rm -rf 会影响什么 |
资源组 Resources
| Axis | 取值范围 | 典型实例 |
|---|---|---|
| 7. memory | working / long-term / shared | working:当前 session 临时记忆;long-term:磁盘持久化;shared:多 agent 共享 Artifact Network。Hu Wei 综述指出:file-persistent、hybrid、hierarchical 是生产主流,纯 ephemeral in-memory 很少见 |
| 8. tool type | function / env / verify / workflow | function:纯函数工具(计算、查询);env:环境交互(文件系统、bash);verify:验证工具(测试、lint);workflow:复杂工具(开 PR、部署) |
| 9. verification | computational ↔ inferential | computational:确定性验证(typecheck、unit test);inferential:LLM-as-judge(code review、语义验证) |
| 10. compaction | 7 种策略 | Inside the Scaffold 论文统计的 7 种策略:summarization、sliding window、retrieval-based、hierarchical 等 |
这 10 个 axes 的价值:
当你说"Anthropic research system"时,你可以精确描述它:
| Axis | 选择 |
|---|---|
| topology | multi |
| coordination | orchestration |
| session span | single |
| control loop | plan-execute |
| autonomy | approval-required |
| execution isolation | sandbox |
| memory | shared |
| verification | computational + inferential |
| ... | ... |
这比笼统地说"它是个 multi-agent 系统"清晰得多。
第 4 层:Pattern(可复用的设计模式)
从现有的一些Harness中,我们可以抽象出一些跨领域可复用的结构性设计。这些 Pattern 不是某个具体项目的配置,而是经过验证的、可以在不同场景下重复使用的设计蓝图。
这一层类似于软件工程中的 GoF 设计模式——你不会说"我在用单例模式这个产品",你会说"我在这个项目里应用了单例模式"。
Anup Jadhav 总结的 5 个基础 Pattern:
| # | Pattern | 解决的问题 | 关键做法 |
|---|---|---|---|
| 1 | Plan-Act-Verify | 几乎所有 agent 的基础模式 | 分解任务 → 执行 → 自检的基础循环 |
| 2 | Progressive Disclosure | 对抗 context rot(上下文膨胀导致 agent 混乱) | Skill 按需加载,而不是一次性把所有指令塞进 context |
| 3 | State Outside Context | 持久状态不污染 context window | 持久状态放磁盘/artifact;Anthropic 长任务 harness 明确推荐用 feature_list.json + claude-progress.txt 做跨 session 共享文件 |
| 4 | Clean-Context Continuation | 避免 context 累积导致模型性能退化 | 长任务执行中,定期 reset context,从任务简介重启 |
| 5 | Approval Checkpoints | 关键操作需要 human-in-the-loop | 在 destructive action 前暂停等待审批 |
学术界和工业界补充的 Pattern:
| # | Pattern | 解决的问题 | 关键做法 |
|---|---|---|---|
| 6 | Initializer + Coding Agent | 长任务需要 spec + 增量实现分离 | Anthropic 长任务 harness 的标志性模式:Initializer agent 写 spec/TODO,Coding agent 增量实现。现在的很多 SDD 框架就使用了这个 Pattern |
| 7 | Planner / Evaluator Split | 对抗 agent "自己批自己作业太宽松" | 写代码的模型和审代码的模型分开 |
| 8 | Approved Fixtures | 避免 agent 自己生成测试、自己通过的循环自嗨 | 用固定测试数据对抗 agent 自评 |
| 9 | Ralph Loop | 实现 agent 的自迭代 | Hook 截断退出 + 重注入 prompt |
Pattern 层的特殊性:
这一层是 Harness Engineering 的核心。它承上启下:
- 向下:组合 Design Components 中的能力和设计轴
- 向上:被具体的 Instance 实例化
当你在设计一个新的 agent 系统时,不应该从零开始发明,而应该先看看这些 Pattern 中哪些适用,然后组合、调整。
第 5 层:Design Instance(最具体的现实)
这一层是现实世界中真正跑起来的 agent 系统。当你打开 Claude Code、看到 Stripe 的 PR 机器人、或者部署一个 CI/CD 自动修复系统时,你看到的就是 Design Instance。
几个典型例子:
| Instance | 关键特征 | 对应的 axes 选择 |
|---|---|---|
| Anthropic Multi-Agent Research System | Claude Opus 作为 lead agent 协调多个 Claude Sonnet subagent 并行;Lead agent 把研究任务分解并写入虚拟文件系统作为 TODO;3 个 Sonnet subagent 并行执行搜索和分析;相比单个 Opus agent 在复杂研究任务上展现显著性能提升 | topology=multi、coordination=orchestration |
| Stripe Minions | 每周自动合并 1300+ PR;Blueprint 架构(deterministic node + agentic node);CI 严格的 two-strike rule(失败两次立即升级到人工);PR webhook 触发,事件驱动 | topology=multi、coordination=cooperation(多个 agent 通过 PR/CI 这个共享状态协作) |
| CI/CD Auto-Triage + Auto-Fix | Cron 定时扫描 CI 失败/新 issue;代码自动生成 prompt 描述问题;Skill 自动分类问题类型;Agent 在 worktree 中自动修复;Checker 判断修复是否完成;自动开 PR,等 CI green 后通知 Slack channel;状态持久化到文件系统 | (自动化 agent 系统实例,叠加 Loop Pattern) |
| OpenAI Codex 长期项目实例 | OpenAI 团队用 5 个月构建并交付一个内部 beta 产品,人工手写代码为 0 行;团队起初由 3 名工程师驱动 Codex,后续扩展到 7 名;系统持续跨多个 session 工作;OpenAI 称之为 "harness engineering"——通过代码外壳管理 agent loop | (持续运行的 agent 系统实例) |
这一层的价值在于:它是抽象概念的锚点。当我们讨论 Pattern 或 Primitives 时,可以随时回到这些具体例子来验证理解是否正确。
三个关键认知
有了这个分层结构,我们可以回答几个容易混淆的问题。
认知 1:Multi-agent 的位置
我之前一直在考虑,multi-agent到底处于什么位置, 是不是应该在harness 之上的独立层。
有了我自己的分层后,就可以简单定义:
Multi-agent 只是 topology 这个 design axis 上的一个选项。
- Anthropic research system = harness(topology=multi, coordination=orchestration, ...)
- Stripe minions = harness(topology=multi, coordination=cooperation, ...)
- 基于RAG的智能问答 = harness(topology=single, ...)
它们都是 harness,只是在 topology 轴上的选择不同。
认知 2:"Harness"这个词的三种用法
现在我们可以精确区分:
- "Claude Code 是一个 Harness" → 指的是 Framework 层的产品
- "解决问题和评估的agent分开 是一个好的 Harness 设计" → 指的是 Pattern 层
- "我们项目的 Harness 配置在 AGENT.md 里" → 指的是 Design Instance 层的具体配置
三个人说的都是"Harness",但分别在不同层。
Harness Engineering 解决的问题
Context Engineering 无法回答的问题,Harness Engineering 都能回答:
- Agent 怎么自己去找信息?(工具调用的控制)
- Agent 如何安全地运行?(沙箱、权限管理)
- Agent 如何跨多个 session 协作?(状态持久化、调度)
- 什么时候触发 compaction?(生命周期管理)
这些问题都能在 Harness Engineering 的框架内得到回答。
这个分层解决了什么问题?
- 概念边界清晰:说"Harness"时,明确在说哪一层
- 设计决策明确:知道在哪一层做什么决策
- 复用性提升:Pattern 层可以跨项目复用
- 沟通效率提升:团队讨论时不会鸡同鸭讲
终于轮到最近突然火起来的Loop Engineering了,我把它定位成一个特殊的Pattern
四、Loop Engineering:让 Harness 自主运转的 Pattern
Loop Engineering 解决什么问题?
在 Harness Engineering 的基础上,我们已经能构建出功能完整的 Agent 系统。但还有一个关键问题没有解决:
谁来启动 Agent?谁来决定什么时候让 Agent 工作?
传统的 Agent 工作模式是:
- 人发现问题(比如 CI 失败、有新 issue、PR 需要 review)
- 人打开 Claude Code,输入 prompt
- Agent 执行任务
- 人查看结果,决定下一步
这个模式有几个问题:
问题 1:人是瓶颈
- 你得盯着 GitHub、Slack、CI 系统,发现问题才能让 Agent 行动
- 半夜 CI 失败了,Agent 不会自己修,得等你早上醒来
问题 2:上下文断裂
- 每次都要重新告诉 Agent 背景、规则、注意事项
- Agent 不记得上次做了什么,每次都是"新员工"
问题 3:无法持续工作
- 你不可能 24 小时坐在电脑前给 Agent 分配任务
- 大型项目的 Agent 协作需要持续数天,人无法全程盯着
Loop Engineering 就是为了解决这些问题:把 Harness 从"人工启动的工具"升级为"自主运行的 Agent"。
典型场景对比:有 Loop 和没 Loop 的区别
为了更具体地理解 Loop Engineering 的价值,我们对比两个场景:
场景:CI/CD Auto-Triage + Auto-Fix
场景:CI/CD Auto-Triage + Auto-Fix
把"没 Loop"和"有 Loop"两条流程平行对齐:
| 步骤 | 没有 Loop Engineering(人工驱动) | 有 Loop Engineering(系统驱动) |
|---|---|---|
| 触发 | CI 失败了,你收到 Slack 通知 | Cron 每 10 分钟触发一次(Self-triggering) |
| 发现问题 | 你打开 Claude Code | 系统自动扫描 CI 失败和新 issue |
| 生成 prompt | 你输入 "/fix the failing CI" | 代码生成 prompt 启动 Agent(Self-prompting) |
| 修复 | Agent 在 worktree 里修复 | Agent 在 worktree 里修复 |
| 判断完成 | 你 review、merge | Checker 判断是否修复完成(Stop condition check) |
| 开 PR | 你开 PR | 自动开 PR |
| 状态记录 | 无 | 状态写入文件(State persistence) |
| 通知 | 你盯着 CI | CI green 后自动通知 Slack "已修复,请 review" |
| 你的角色 | 盯着监控、手动启动、半夜失败了得等早上 | 只需要最后 review,不需要盯着监控 |
关键区别:
| 维度 | 没 Loop | 有 Loop |
|---|---|---|
| 谁盯着监控 | 你 | 系统 |
| 谁启动 Agent | 你手动 | 系统自动 |
| 谁判断完成 | 你 | Checker |
| 工作时间 | 受你作息限制 | 24/7 |
Stripe Minions 实例:
- 每周自动合并 1300+ PR
- PR webhook 触发(Event-driven Loop)
- Blueprint 架构:把工作流拆成 deterministic node 和 agentic node
- CI 严格的 two-strike rule:失败两次立即升级到人工
- 多个 agent 通过 PR/CI 这个共享状态协作
Loop Engineering 的核心能力与依赖
Loop Engineering 的本质是一个 orchestration pattern。它真正新增的核心能力只有一个:Self-Triggering(系统自动触发)。
但要让这个 pattern 工作,它需要依赖 Harness 已有的三个基础能力。下面按依赖关系展开:
核心能力:Self-triggering(系统自动触发)
这是 Loop Engineering 唯一真正新增的能力:不需要人手动启动,系统自己决定何时启动 Agent。
实现方式:
- Cron:定时触发(每 10 分钟扫描 CI、每天早上生成报告)
- Event:事件触发(PR created、issue opened、CI failed、webhook 推送)
- Condition check:条件触发(当某个指标达到阈值)
根据触发的主动性,可以分为:
- Polling-based:系统主动扫描(Cron、condition monitoring)
- Event-driven:外部事件推送(webhook、file watch、message queue)
技术实现:
- 依赖 Framework 层的 Trigger 系统(cron / event / hook 机制)
- 具体"什么时候触发、触发什么"是 Pattern / Design Instance 层的 决策
例子:
# Cron: 每 10 分钟检查一次
*/10 * * * * agent run "scan and fix CI failures"
# Event: GitHub webhook
on PR.opened -> agent run "review PR"
# Condition: 监控指标
when error_rate > 5% -> agent run "investigate and alert"
关键区别:
- 不是 Loop:人手动打开 Claude Code 输入 "/fix CI"(人触发)
- 是 Loop(Event-driven):Stripe Minions 的 PR webhook 自动触发 agent 处理
- 是 Loop(Polling-based):Cron 每 10 分钟主动扫描 CI 状态并决定是否修复
依赖能力 1:Self-prompting(系统生成 prompt)
为什么 Loop 需要它:触发后,Agent得有输入才能知道做什么。
重要澄清:Self-prompting 不是 Loop 发明的——任何 Harness 都可以代码生成 prompt(比如根据 tool schema 生成 system prompt)。但 Loop 必须用它,否则触发后 Agent 不知道干什么。
实现方式:
- 读取外部状态(CI 状态、issue 列表、PR diff)
- 根据状态生成结构化的 prompt
- 注入 context(相关代码、历史修复记录)
- 依赖 Framework 层的 Trigger 能力
依赖能力 2:State persistence(跨 session 状态传递)
为什么 Loop 需要它:Loop 通常跨多个 session 工作(一次修不完、需要等外部状态变化),得有地方存状态。
重要澄清:State persistence 不是 Loop 发明的——这是 Harness 的 session span axis(multi-session)+ State Outside Context pattern。任何需要跨 session 的 Harness 都可以用。但 Loop 大概率需要它。
与 Harness 的关系:
- 跨 session 能力来自 Harness 的 session span 设计轴(single-session ↔ multi-session)
- State Outside Context 是 Harness Pattern 层的一个成员
- Loop Engineering 只是让这个跨 session 流程自动化触发
举例说明:
- Harness 的 multi-session(非 Loop):用户手动起一个新 session 读 artifact 继续工作
- Loop Engineering:系统定时自动起 session 检查 artifact 并推进工作
区别在于"谁触发",而不是"能否跨 session"。
实现方式:
- Session 1:Agent 写状态到文件(
feature_list.json、progress.txt、artifact) - Session 1 结束
- Session 2:自动触发,读取文件,继续工作
- Session 2:更新文件状态
- 依赖 Framework 层的 Memory 能力 + State Outside Context pattern
每个 session 读这个文件,知道该做什么,做完后更新状态。
Loop Engineering 的价值:不是发明新的能力,而是通过 Self-triggering 把 Harness 从"人工启动的工具"升级为"自主发现问题并解决的 Agent"。这是从"被动响应"到"主动监控"的范式转变。
Loop Engineering 在 Harness 分层中的位置
现在可以回头再看看:Loop Engineering 到底是什么?
它是 Pattern 层的成员
在上一节的分层结构中,Loop Engineering 位于 Pattern 层,和 Plan-Act-Verify、Initializer + Coding Agent 平级。
Addy Osmani 的 5+1 building blocks 验证了这一点:
Addy 说 Loop Engineering 依赖 6 个 building blocks:
- Automations(定时/事件触发)
- Worktrees(隔离工作空间)
- Skills(固化知识)
- Plugins/connectors(MCP)
- Sub-agents(maker/checker 分离)
- Memory
这 6 个里,其实都已经在 Harness 里了:
- Automations → Framework 层 Trigger的能力
- Worktrees → Framework 的 sandbox runtime
- Skills → Framework 的 skill registry + Pattern 的 progressive disclosure
- Plugins → Framework 的 MCP client
- Sub-agents → Framework 的 subagent spawn + Pattern 的 Planner/Evaluator
- Memory → Framework 层 Memory 能力 + Pattern 的 State Outside Context
那为什么很多人说"Loop 在 Harness 之上"?
这是个好问题。Addy、Boris 的文章确实给人"Loop 是更高层"的感觉。
三个非概念性的原因:
-
修辞/传播原因
- "从手动 prompting 到自动 prompting" 是个范式转变
- 包装成"新一层"更有冲击力,便于传播
- 技术文章需要吸引眼球
-
产品原因
- Claude Code 和 Codex 把 Automations 做成 first-class feature
- 产品上需要"突出"这个新功能
/loop命令看起来像是"新能力"
-
历史原因
- "Harness engineering" 这个词 2025 年才定型
- "Loop engineering" 是 2026 年的新词
- 新词自然要"在它之上"才显得新
但从概念本质讲:Loop Engineering 是 Harness 内部的一个 Pattern,主要依赖 Framework 层的 Trigger 能力,通过组合现有能力实现自驱动。
Loop 的真正价值不是"层级更高",而是"范式转变":
从"人工启动的工具"到"自主运行的 Agent",这个跃迁的价值不在于引入了新的技术能力,而在于改变了人与 Agent 的协作模式:
- 过去:你是 Agent 的老板,发现问题、分配任务、检查结果
- 现在:你是系统的架构师,设计规则让系统自己发现问题、分配任务、检查结果
这个转变的意义,不亚于从"手动部署"到"CI/CD 自动部署"、从"人工监控"到"自动告警"。
Loop Engineering vs ReAct:本质区别
之前看到有人会问:Loop Engineering 和 ReAct 有什么区别?它们不都是"循环"吗?
| 维度 | ReAct(Reason + Act) | Loop Engineering |
|---|---|---|
| 循环位置 | Agent 内部的控制循环 | Harness 外部的调度循环 |
| 循环范围 | 单 session 内:观察 → 推理 → 行动 → 观察 ... | 跨 session:触发 → 生成 prompt → 启动 Agent → 检查完成 → 触发 ... |
| 谁主导 | 模型主导(模型决定下一步做什么) | 系统主导(系统决定何时启动 Agent) |
| 在分层中的位置 | control loop 这个 design axis 上的一个选项 | Design Pattern 层的成员 |
| 作用层面 | 微观层面(单次任务的执行策略) | 宏观层面(多次任务的调度策略) |
更准确的类比:
- ReAct = 肌肉的自主收缩循环(你跑步时,腿部肌肉自动协调收缩)
- Loop Engineering = 健身计划的自动提醒(手机 App 每天 7 点提醒你去跑步)
- 两者都是"你"(Agent)的一部分,只是作用在不同层面
可以组合使用:
- 系统定时触发(Loop Engineering 的 self-triggering)
- 启动 Agent,Agent 内部用 ReAct 循环工作
- Checker 判断完成,写入文件
- 下一次触发时,继续
Loop Engineering 和 ReAct 是正交的,可以同时使用。
总结:Loop 的本质与价值
回到核心认知:
Loop Engineering 不发明跨 session 能力——那是 Harness 的 session span axis。
Loop Engineering 不发明 multi-agent 能力——那是 Harness 的 topology axis。
Loop Engineering 不发明共享状态的能力——那是 Harness 的 memory design component。
Loop Engineering 只做一件事:通过 Self-triggering,把 Harness 从"人工启动的工具"升级为"自主发现问题并解决的 Agent"。
这个升级的价值体现在:
- 从被动响应到主动监控:不用人盯着,系统自己发现问题
- 从间歇工作到持续运行:24/7 工作,不受人的作息限制
- 从单次任务到持续改进:通过文件记录状态,形成持续演进的系统
这就是为什么 Loop Engineering 是 Pattern 层的成员,而不是独立层。
它是 Harness 能力的一种高级组合方式,专门用于"让 Agent 持续自主工作"这个场景。
五、概念关系总览:从演进到结构
经过前面四节的展开,我们现在可以给出一个完整的概念地图。
时间线:概念的演进
从时间维度看,这些概念是逐步演进的:
| 时期 | 核心概念 | 关注问题 | 谁在驱动 |
|---|---|---|---|
| 2022.11 – 2024 | Prompt Engineering | 这句话怎么写才能让模型更好地理解? | 人 |
| 2025.6 | Context Engineering | 这一步应该给模型看什么信息? | 人 |
| 2026.1 | Harness Engineering | 如何把模型变成可靠的 Agent? | 人(启动) |
| 2026.6 | Loop Engineering | 如何让 Agent 持续自主工作? | 系统(自驱动) |
演进的方向:
- 从"调模型"到"调系统"
- 从"单次调用"到"持续运行"
- 从"人工驱动"到"系统驱动"
判断清单:如何区分概念边界
当你遇到一个具体问题时,如何判断它属于哪个概念?
问题:我在优化 RAG 检索结果的排序
- 这是 Context Engineering(给模型看什么、怎么排序)
问题:我在写 AGENT.md 配置文件
- 这是 Harness 的 Design Instance 层(具体配置)
问题:我在设计 Planner/Evaluator 分离的架构
- 这是 Harness 的 Pattern 层(可复用设计)
问题:我在开发一个支持 MCP 的 agent runtime
- 这是 Harness 的 Framework 层(提供能力)
问题:我在设置定时任务,让 Agent 每天自动检查 CI
- 这是 Loop Engineering(自动化调度)
- 但 Loop 是 Harness Pattern 层的成员
问题:我在设计多个 Agent 通过 artifact 协作的系统
- 这是 Harness 的 Design Instance(topology=multi, coordination=cooperation, session span=multi-session)
- 如果加上 cron 定时检查 artifact 并推进工作,就变成了 Loop
问题:Stripe Minions 算不算 Loop Engineering?
- 本文采用广义定义:算。它是 Event-driven Loop 的典型例子(PR webhook 自动触发 agent 处理)

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)