7个月,234次提交,1690行代码:AI编程大型翻车现场:我决定全部作废,手动重写!

【CSDN 编者按】在 Hacker News 引发 500+ 讨论的“大型翻车现场”复盘:“我花了 7 个月搞‘氛围编程’,结果搓出了一堆工业垃圾。” 开发者 @dropbox_miner 的这段血泪史,刺破了 AI 编程的虚假繁荣。当 AI 可以在几秒钟内生成 1000 行代码时,我们是否正在交出软件架构的指挥棒,从而让自己陷入一种“写得快,死得惨”的熵增死循环?
原文链接:https://blog.k10s.dev/im-going-back-to-writing-code-by-hand/
作者 | dropbox_miner 责编 | 张红月
出品 | 程序人生(ID:coder_life)
当 AI 编程成为主流时,也有不少资深开发者开始反思:把一切交给 AI,我们到底失去了什么?

https://news.ycombinator.com/item?id=48090029
这篇文章在 Hacker News 上获得了极高的讨论热度,或许能为你提供一个全新的视角。
作者在坦言,自己也没想到一篇日记在 HN 上能带来如此多的讨论,本文的背景是作者只想做一个实验,测试一下“如果我完全不碰代码,能不能靠 AI 把软件做出来”。
结论很残酷:想做点像样的东西,人必须得在场。
作者进行了核心复盘:
-
AI 写作的“通病”:AI 写代码总喜欢给你搞出庞大的“上帝对象”(耦合严重、难以维护的臃肿代码);
-
如果只追求 AI 瞬间产出的那种“爽感”,你会发现项目变得廉价且臃肿,最终彻底跑偏;
-
架构必须由人来定,如果你只会不断向 AI 索要功能,最终得到的只是一堆功能拼凑的垃圾。
此外,为了让 AI 更听话,作者还总结了一套 AGENTS.md / CLAUDE.md 调教指令,希望能让你在编程时少操点心。
截至 2026 年 5 月 10 日,人类依然是编程中不可或缺的环节。如果你只是好奇我的实验结论,那么现在你可以放心回去继续写你的代码了!
加入 AMD AI 开发者计划,免费领 50 小时云算力券
进入官方群月月抽显卡、AIPC,好运不停!


我是如何把一个项目“玩崩”的
历经 234 次提交,耗时 30 个周末,几乎全是用 AI “氛围编程”搓出来的。
就是我的开源工具 k10s:https://github.com/shvbsle/k10s/tree/archive/go-v0.4.0
现在,我决定把它归档,从头手搓。
k10s 是个什么?
起初,我想做一个 GPU 友好的 K8s 仪表盘。你可以把它理解成 GPU 界的 k9s——专为 NVIDIA 集群运维人员设计,专门盯着 GPU 利用率、DCGM 指标,以及揪出那些每小时空转烧掉 32 美元的闲置节点。我用 Go 语言加上 Bubble Tea 库实现了它,最初运行得也挺好。
但好景不长……
这 7 个月的折腾,让我学到的教训远比那 1690 行即将被我扔进垃圾桶的 model.go 代码值钱。我觉得任何深陷“氛围编程”的开发者都该听听我的血泪史,因为在那些 AI 编程的营销 Demo 里,这种“翻车”经历永远被掩盖了。
AI 是写代码的快枪手,但它不是架构师。你越是不加限制地让 AI 代劳,系统崩得就越快。这种虚假的开发速度会让你产生一种“赢定了”的错觉,直到整个系统在某一刻集体崩溃,让你彻底清醒。

Vibe Coding 的魔法时刻
2025 年 9 月底,我启动了 k10s 项目。那前几周简直是“魔法时间”。
我只需要对 Claude 说一句:“加个带实时更新的 Pod 列表”,几秒钟后,功能搞定。资源过滤、日志流、详情面板、键盘快捷键……功能加得又快又稳,因为那时的项目够简单,AI 能完全吃透整个架构。
那个 k9s 的基础克隆版,我只用了 3 个周末就搞定了。Vim 操作习惯、Watch 实时刷新、命令面板,样样齐全。那是我的巅峰期,开发速度简直开了外挂,比手写快了 10 倍,爽到起飞。
但我还不满足,我要做那个“杀手级功能”:GPU 集群概览。
我想要一个专门的屏幕,一眼看清每个节点的 GPU 状态:分配率、DCGM 利用率、温度、功耗、显存。不用再去翻 kubectl describe 的原始输出,直接看表格:闲置节点标黄,忙碌的标绿,过载的直接标红。
一目了然,专业且高级。
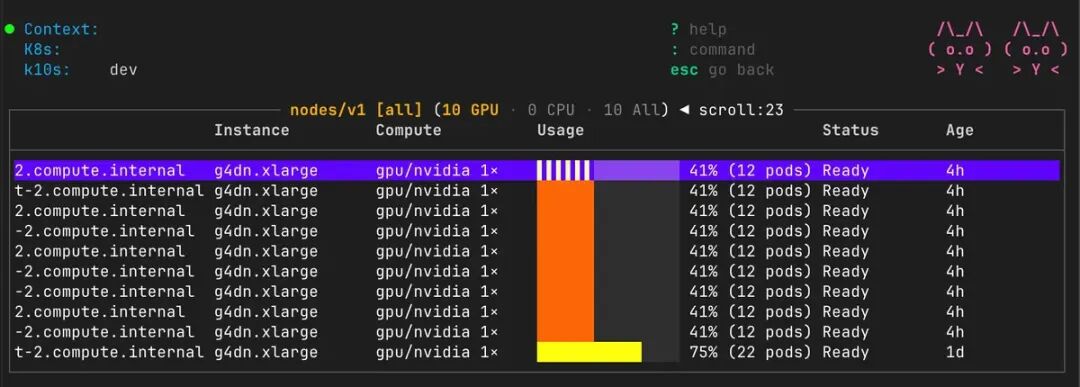
在模拟 GPU 节点上的集群概览视图
Claude 一次就搞定了。我提示需要集群视图,它生成了 FleetView 结构体、标签过滤(GPU/CPU/全部)、带有分配条的自定义渲染。看起来很漂亮。我正沉浸在成功中。
然后,我输入 :rs pods 想切回 Pod 列表。
屏幕一片死寂。 表格没了,数据也不更新了。切到节点页面,显示的是刚才集群视图留下的脏数据,标签页计数也全乱套了。
那个“上帝对象”失控了,它把自己吞了。
这正是我写这篇博客的原因。这是我 7 个月来第一次决定亲自下场介入。以前我写完代码,看一眼 diff,确认能跑通测试就直接发布,从不回头看代码长什么样。但这次不行了,光靠写提示词,我已经救不回这个烂摊子。
我咬咬牙,硬着头皮读完了 model.go。
整整 1690 行代码。
看完我直接吓傻了。
代码长这样。一个统治一切的“上帝结构体”:
type Model struct { // 3rd party UI components table table.Model paginator paginator.Model commandInput textinput.Model help help.Model // cluster info and state k8sClient *k8s.Client currentGVR schema.GroupVersionResource resourceWatcher watch.Interface resources []k8s.OrderedResourceFields listOptions metav1.ListOptions clusterInfo *k8s.ClusterInfo logLines []k8s.LogLine describeContent string currentNamespace string navigationHistory *NavigationHistory logView *LogViewState describeView *DescribeViewState viewMode ViewMode viewWidth int viewHeight int err error pluginRegistry *plugins.Registry helpModal *HelpModal describeViewport *DescribeViewport logViewport *LogViewport logStreamCancel func() logLinesChan <-chan k8s.LogLine horizontalOffset int mouse *MouseHandler fleetView *FleetView creationTimes []time.Time allResources []k8s.OrderedResourceFields // fleet's unfiltered set allCreationTimes []time.Time // fleet's timestamps rawObjects []unstructured.Unstructured ageColumnIndex int // ...}你猜我看到了什么?
窗口组件、K8s 客户端、日志缓存、导航记录、鼠标监听……全被塞进了同一个结构体里。更要命的是那个 Update() 方法:500 行长的代码,里面塞满了 110 个 switch/case 分支,全靠暴力判断消息类型来分发逻辑。
那不是代码,那是工业废料。
也就是在那一刻,我关掉了 AI 对话框。那种盲目的“氛围编程”到此为止,我终于开始像个工程师一样思考了。
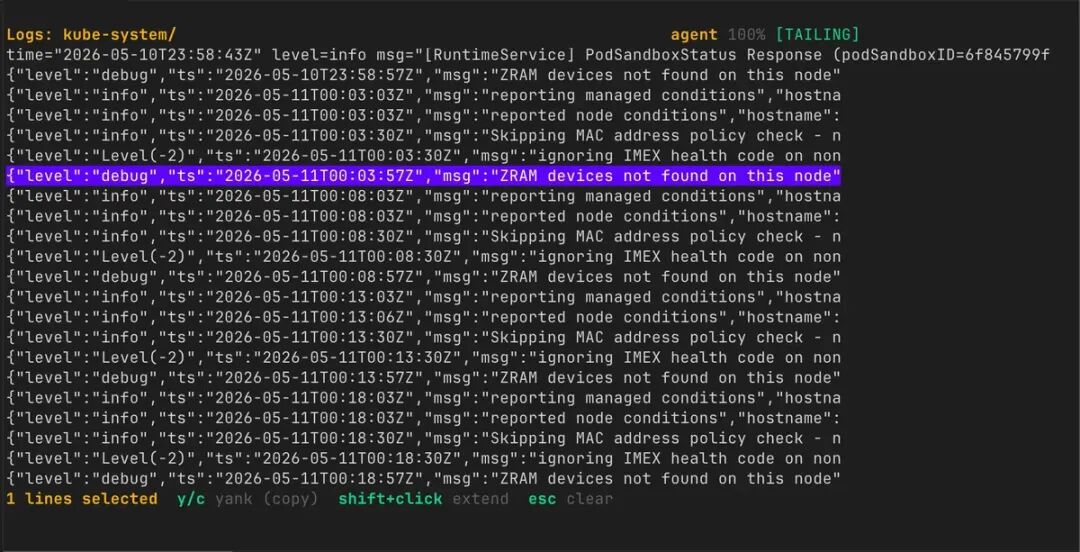
行吧,既然你想用鼠标复制日志,那就给你加上吧。还能出什么乱子呢?

从代码废墟中总结的五大铁律
在看着我的项目一点点烂掉之后,我总结了 7 个月的血泪教训。以下是我的“错误清单”——既有我为什么翻车的复盘,也有你该如何通过 CLAUDE.md 等指令防坑的实操建议。
铁律 1:AI 只能帮你堆功能,架构还得你来定
说实话,Claude 的表现确实“完美”。我要加什么,它就给什么。集群视图一次通过,日志流一次通过,鼠标支持一次通过。
但问题全出在这儿:每一行代码的诞生,都只为了满足当前这一瞬间的“让功能跑起来”,它根本不在乎这行代码会不会把之前做好的那 49 个功能全都搞崩。
看看下面这段 resourcesLoadedMsg 处理程序,也就是每次你切换界面时都要跑的代码:
case resourcesLoadedMsg: m.logLines = nil // Clear log lines when loading resources m.horizontalOffset = 0 // Reset horizontal scroll on resource change if m.currentGVR != msg.gvr && m.resourceWatcher != nil { m.resourceWatcher.Stop() m.resourceWatcher = nil } m.currentGVR = msg.gvr m.currentNamespace = msg.namespace m.listOptions = msg.listOptions m.rawObjects = msg.rawObjects // For nodes: store the full unfiltered set, classify, then filter if msg.gvr.Resource == k8s.ResourceNodes && m.fleetView != nil { m.allResources = msg.resources m.allCreationTimes = msg.creationTimes if len(msg.rawObjects) > 0 { m.fleetView.ClassifyAndCount(m.rawObjectPtrs()) } m.applyFleetFilter() } else { m.resources = msg.resources m.creationTimes = msg.creationTimes m.allResources = nil m.allCreationTimes = nil }看见那个 if 判断了吗?它为了迁就集群视图,强行在通用的加载路径里塞了个“特例”。
这就是问题的根源: 每一个需要特殊处理的新功能,都在这儿硬加一个分支。每加一个分支,你就得手动清理一堆乱七八糟的状态字段。只要漏清一行,上个界面的数据就会像幽灵一样在当前页面残留。
这就是为什么你的代码会崩溃。
我在这个文件里数了数到底有多少行 = nil 的清理代码,结果如下:
m.logLines = nil // Clear log lines when loading resourcesm.allResources = nil // Clear fleet data when not on nodesm.resources = nil // Clear resources when loading logsm.resources = nil // Clear resources when loading describe viewm.logLines = nil // Clear log lines when loading describe viewm.resources = nil // Clear resources when loading yaml viewm.logLines = nil // Clear log lines when loading yaml viewm.logLines = nil // ... two more in other handlersm.logLines = nil为了不让页面串数据,我被迫在 1690 行的代码里塞了 9 处手动清理代码。漏掉一行?恭喜你,幽灵数据如约而至。
这就是缺乏“视图隔离”的代价。AI 根本感知不到架构在一点点腐烂,因为它每次只关注你当前的那个提示,根本看不见全局的崩塌。
所以,正确的姿势是:
在敲下一行代码之前,架构必须由你亲手设计。别搞那种虚头巴脑的设计文档
直接写出具体的接口、消息协议和明确的权限规则。然后,把这些规则强行塞
你的 CLAUDE.md,让 AI 每次干活时都必须盯着这些“铁律”看:
# Architecture Invariants (CLAUDE.md)- Each view implements the View trait. Views do NOT access other views' state.- All async data arrives via AppMsg variants. No direct field mutation from background tasks.- Adding a new view MUST NOT require modifying existing views.- The App struct is a thin router. It owns navigation and message dispatch. Nothing else.只要你把规则写清楚,AI 就能执行。但指望它主动帮你优化架构?别做梦了。
铁律 2: AI 的懒惰本性
AI 天生爱搞“一个结构体管所有事”那一套,因为它能让你快速看到效果,省去了繁琐的解耦仪式。但随之而来的代价是:一旦失去了视图隔离,按键映射就会变成一场噩梦。
不信你看下面这段 s 键的逻辑分发,简直看得人原地爆炸:
case m.config.KeyBind.For(config.ActionToggleAutoScroll, key): if m.currentGVR.Resource == k8s.ResourceLogs { m.logView.Autoscroll = !m.logView.Autoscroll if m.logView.Autoscroll { m.table.GotoBottom() } return m, nil } // Shell exec for pods and containers views if m.currentGVR.Resource == k8s.ResourcePods { // ... 20 lines to look up selected pod, get name, namespace ... return m, m.commandWithPreflights( m.execIntoPod(selectedName, selectedNamespace), m.requireConnection, ) } if m.currentGVR.Resource == k8s.ResourceContainers { // ... container exec logic ... return m, m.commandWithPreflights(m.execIntoContainer(), m.requireConnection) } return m, nil同一个 s 键,在不同界面下竟然有三种截然不同的功能:在日志页是“自动滚动”,在 Pods 页是“进 Shell”,在容器页又是“进容器 Shell”。
这种逻辑全堆在同一个扁平的 switch 里,简直是灾难。究其原因,就是因为没有按键映射的视图隔离。
每当我让 AI 加个功能,它就像个糊涂的快递员,随手把代码塞进离它最近的按键处理器里,根本不考虑这种逻辑堆砌会导致系统变得多臃肿。
更糟的还在后面,看看 Enter 键的“下钻”处理逻辑:
case m.config.KeyBind.For(config.ActionSubmit, key): // Special handling for contexts view if m.currentGVR.Resource == "contexts" { // ... 12 lines ... return m, m.executeCtxCommand([]string{contextName}) } // Special handling for namespaces view if m.currentGVR.Resource == "namespaces" { // ... 12 lines ... return m, m.executeNsCommand([]string{namespaceName}) } if m.currentGVR.Resource == k8s.ResourceLogs { return m, nil } // ... 25 more lines of generic drill-down ...整个系统成了这副鬼样子:到处都是 if m.currentGVR.Resource == ... 的判断逻辑。为了区分视图类型,竟然用了 20 多次字符串硬比较。
这根本不是面向对象编程,这是在给地狱铺路。
每一页新功能,都得被迫改动所有已有的处理器。这种架构,只要代码量一上来,没人能改得动。
所以,为了防患于未然,请把这套规则强行塞进你的 CLAUDE.md:
# State Ownership Rules- NEVER add fields to the App/Model struct for view-specific state.- Each view is a separate struct implementing the View trait/interface.- Each view declares its own key bindings. The app dispatches keys to the active view.- If you need to add a keybinding, add it to the relevant view's keymap, not a global one.- Adding a view means adding a file. If your change requires modifying existing views, stop and ask.记住,AI 的本能就是“偷懒”,它永远倾向于走那条最省事的最短路径——比如“再加个 if 分支”。
你的职责不是去祈求它写出好架构,而是通过规则,让“正确的设计”成为它眼中最顺手的那条路。
这就是为什么你要在它每次开工前都能读到的配置文件(如 CLAUDE.md)里,设下严苛的护栏。
铁律 3:速度的幻觉,正在摧毁你的专注
这不只是技术问题,更是心理防线的问题,而且我觉得这才是最致命的。
刚开始做 k10s 时,我的目标很纯粹:搞个专供 GPU 训练集群运维用的利基工具。毕竟我就是这个圈子的人,我懂需求。
但“氛围编程”产生了一种廉价感——好像万事皆可轻易达成。
“既然在一个会话里就能搞定 Pod 视图,那干脆把 Deployment 也顺手做了吧?还有 Service、完整的命令面板、鼠标支持、上下文切换、命名空间过滤……”
因为 AI 写代码太快,我的野心开始疯狂膨胀。
图注:该死,我把什么功能都往里加了……
我竟然鬼使神差地把 k10s 做成了另一个 k9s。一个面向所有人的通用 K8s 工具。
这就是 AI 编程的陷阱:它让每个功能看起来都像“免费午餐”,动动嘴就能实现。但天下没有免费的午餐,每一个加进来的功能,其实都是在往那个本已臃肿的“上帝对象”里疯狂塞地雷。
看看下面这段按键绑定的结构体定义,简直不忍直视:
type keyMap struct { Up, Down, Left, Right key.Binding GotoTop, GotoBottom key.Binding AllNS, DefaultNS key.Binding Enter, Back key.Binding Command, Quit key.Binding Fullscreen key.Binding // log view Autoscroll key.Binding // log view (also shell in pods!) ToggleTime key.Binding // log view WrapText key.Binding // log + describe view CopyLogs key.Binding // log view ToggleLineNums key.Binding // describe view Describe key.Binding // resource views YamlView key.Binding // resource views Edit key.Binding // resource views Shell key.Binding // pods (CONFLICTS with Autoscroll!) FilterLogs key.Binding // log view FleetTabNext key.Binding // fleet view only FleetTabPrev key.Binding // fleet view only}整个系统就这么一个扁平的按键映射表。Autoscroll 和 Shell 居然都绑定了同一个 s 键!
系统之所以没崩溃,全靠那堆丑陋的 if 判断在死撑。想弄明白某个键到底是干嘛的?你得像侦探一样,从头到尾扒一遍那 500 行烂代码。
最讽刺的是: 当你看着交付指标、觉得“代码写得真快”的时候,系统架构正在默默腐烂。你以为你在赢,其实是在透支未来。
所以,救命的第二招:
写一份“愿景文档”,明确写出这个产品“NOT BUILDING”。把这些需求边界清清楚楚地写进 CLAUDE.md 里,防止 AI 顺手帮你把项目做成“大杂烩”。
# Scope (do NOT expand beyond this)k10s is for GPU cluster operators. Not all Kubernetes users.Supported views: fleet, node-detail, gpu-detail, workload. That's it.Do NOT add generic resource views (pods, deployments, services).Do NOT add features that duplicate k9s functionality.If a feature request doesn't serve someone running GPU training jobs, reject it.“氛围编程”会给你一种错觉:好像资源是无限的。
其实是假象。 现在的你,拥有的只是无限的“代码产量”(AI 确实能帮你写出海量代码),但你的“复杂度上限”依然是有限的。
别被 AI 的那种“爽感”骗了。架构的承受力是有天花板的,无论你写得有多快,一旦触及极限,系统必崩。
所以,在 CLAUDE.md 里写好功能边界,其实就是一种“提前拒单”的机制。在那种快节奏开发的“亢奋期”到来前,先把“不行”写好,省得你到时候脑子一热,什么都往项目里塞。
铁律 4:谨慎处理位置数据,它们是埋在系统里的定时炸弹
在 k10s 里,我从 K8s API 拉回来的每一个资源,还没来得及思考,就被 AI 直接做成了“扁平化”处理。
type OrderedResourceFields []string这真是“灾难级”代码。这种完全依赖索引下标的排序函数,只要 API 稍微调整一下字段顺序,你的程序立刻就会抛出错误或者显示垃圾数据。
func sortFilteredResources(rows []k8s.OrderedResourceFields, times []time.Time, tab FleetTab) { sort.SliceStable(indices, func(a, b int) bool { ra := rows[indices[a]] rb := rows[indices[b]] switch tab { case FleetTabGPU: // Sort by Alloc column (index 3) ascending allocA, allocB := "", "" if len(ra) > 3 { allocA = ra[3] } if len(rb) > 3 { allocB = rb[3] } return allocA < allocB case FleetTabCPU: // Sort by Name column (index 0) ascending nameA, nameB := "", "" if len(ra) > 0 { nameA = ra[0] } if len(rb) > 0 { nameB = rb[0] } return nameA < nameB case FleetTabAll: // GPU nodes first, then CPU nodes. // Within GPU: sort by Alloc (index 3). // Within CPU: sort by Name (index 0). computeA, computeB := "", "" if len(ra) > 2 { computeA = ra[2] } if len(rb) > 2 { computeB = rb[2] } aIsGPU := strings.HasPrefix(computeA, "gpu") bIsGPU := strings.HasPrefix(computeB, "gpu") // ... } })}ra[3] 代表分配率,ra[2] 代表计算,ra[0] 代表名称。
这全是“魔法数字”!
它们与实际字段唯一的关联,竟然只有一行注释和那个脆弱不堪的 resource.views.json 配置文件。
如果哪天配置文件里的列顺序换了,或者 Kubernetes API 的返回结构稍微改了一点,整个程序的排序逻辑就会瞬间暴毙,没人能发现问题出在哪。
{ "nodes": { "fields": [ { "name": "Name", "weight": 0.28 }, { "name": "Instance", "weight": 0.15 }, { "name": "Compute", "weight": 0.12 }, { "name": "Alloc", "weight": 0.12 }, ... ] }}原文链接:https://blog.k10s.dev/im-going-back-to-writing-code-by-hand/
试想一下:如果你想在 Instance 和 Compute 之间加一列?
Boom! 所有的排序逻辑、所有的条件渲染,甚至每一处写着 ra[2] 或 ra[3] 的代码,瞬间全部悄无声息地“坏掉”了。
编译器根本帮不了你,因为它看到的只是一堆杂乱无章的字符串数组。
更糟糕的是,原本定义列顺序的 JSON 配置文件根本无法表达复杂的排序规则或渲染逻辑,所以你只能把这些逻辑硬编码进 Go 代码里,死死绑定在那些脆弱的索引位置上。
为什么 AI 这么爱干蠢事?
因为它太想偷懒了。为了以最快速度完成“拉取数据并渲染表格”的任务,AI 总是直接给你甩过来一个:
# Data Representation- NEVER flatten structured data into []string, Vec<String>, or positional arrays.- All data flows as typed structs (FleetNode, PodInfo, etc.) until the render() call.- Column identity comes from struct field names, not array indices.- Sort functions operate on typed fields, never on positional access like row[3].- The ONLY place strings are created for display is inside render()/view() functions.这时候,你就该定义结构体了。
一旦你用上了类型明确的 struct,那些离谱的逻辑错误直接在编译阶段就无法通过。通过类型系统,让那些“不可能的状态”从根本上变得“不可能发生” 。
struct FleetNode { name: String, instance_type: String, compute_class: ComputeClass, alloc: GpuAlloc,}一旦用了字段名,你就没法按错误的列排序;把 Alloc 当成 Name 来比对?这种事压根不会发生。因为编译器会帮你死死盯着。
别再指望 AI 自觉了。 它永远会选 Vec<String> 这种最快完成任务的捷径,哪怕那是地雷。
你的工作,就是通过 CLAUDE.md 强制给它加码,把“写出健壮代码”变成那条阻力最小的路径。
铁律 5:严禁让 AI 随意触碰“状态转换”
Bubble Tea 架构的精髓在于“单一数据源”:状态的任何变动,只能由 Update() 函数在收到消息后触发,这种单向数据流极其优雅且安全。
但我的 k10s 全毁在这儿了。
AI 写的 updateTableMsg 处理程序,竟然在后台协程里偷偷开了一个闭包,直接去修改 Model 的字段。这种“在协程内直接改数据”的操作,简直是并发编程的自杀行为:
case updateTableMsg: return m, func() tea.Msg { // block on someone sending the update message. <-m.updateTableChan // Preserve cursor position across column/row updates so that // background refreshes don't reset the user's selection. savedCursor := max(m.table.Cursor(), 0) // run the necessary table view update calls. m.updateColumns(m.viewWidth) m.updateTableData() // Restore cursor, clamped to valid range. rowCount := len(m.table.Rows()) if rowCount > 0 { if savedCursor >= rowCount { savedCursor = rowCount - 1 } m.table.SetCursor(savedCursor) } return updateTableMsg{} }这简直是并发编程的“教科书级车祸现场”:
这个闭包在后台 goroutine 里疯狂读写数据模型,与此同时,主程序还在调用 View() 试图读取同一份数据来渲染界面。关键是,这代码里既没加锁,也没用互斥量。 那个 <-m.updateTableChan 虽能阻塞闭包,但根本挡不住 View() 去读取那些“还没写完的脏数据”。
这就是典型的数据竞争。 99% 的时间它跑得好好的,剩下那 1% 的时间,它会以一种让你怀疑人生的方式崩溃掉——那种诡异的 UI 闪烁和乱码,真的会逼疯开发者。
AI 为什么敢这么写?
因为它太想偷懒了!在它眼里,在闭包里直接调用 m.updateColumns(m.viewWidth) 和 m.updateTableData() 是完成任务的最短路径。而正确的做法——“发个消息回 Update() 函数,由主循环来原子性地修改状态”——不仅要多定义类型,还得搭出一堆管道,太麻烦。
AI 是在为了完成你的提示词而优化,它根本不在乎并发安全性。
所以,救命的第三招:
别碰任何“渲染可见状态”的修改逻辑,全部给我扔到主循环里去。 后台只负责搞数据,搞完发消息;主循环通过 Update() 函数接收消息并更新 UI。
这是并发 UI 代码的“绝对铁律”,谁碰谁死。
// Background task:tx.send(AppMsg::FleetData(nodes)).await;// Main loop:match msg { AppMsg::FleetData(nodes) => { self.fleet_view.update_nodes(nodes); }}没有共享的可变状态。没有数据竞争。没有“99% 的时间都能工作”。把这个放进你的 CLAUDE.md:
# Concurrency Rules- Background tasks (watchers, scrapers, API calls) NEVER mutate UI state directly.- Background tasks send results through a channel as typed messages.- Only the main event loop applies state mutations from received messages.- render()/view() is a PURE function. No side effects. No I/O. No channel operations.- If you need to update state from async work, define a new AppMsg variant.如果你的 AI 没能主动采用这种设计模式,那就用指令把它框住。

请回归本质
我正在用 Rust 重写 k10s。这不是因为 Rust 有多神,而是因为我驾驭得了它。写久了,我就能形成一种“直觉”——还没想出道理前,我就能感觉到哪儿不对劲。这种直觉,Vide Coding 永远取代不了。AI 给你的代码看着都挺像样,但你得有嗅觉去辨别哪儿是垃圾。
我的另一个做法也变了:在动笔之前,我先亲手把设计稿敲定。
别搞那些虚头巴脑的文档,我直接定义好具体的接口、消息类型、所有权规则。AI 一直做错的架构决策,现在都在第一个提示词输入之前就已写在纸上了。至于这套打法能不能撑住,不让项目再次烂掉……咱们走着瞧。
推荐阅读:
63岁黄仁勋再添博士头衔、英特尔CEO为其披袍,最新演讲刷屏:人类编写软件、计算机执行指令的范式已终结!
Python时代结束:当AI成为程序员,Rust、Go成了首选!
“算力比工资贵多了!”英伟达高管自曝:现在AI比“雇人干活”还贵
从“拥抱 AI”到“AI 原生”,我们正站在生产力变革的奇点。
由 CSDN 与奇点智能研究院联合举办的「2026 全球产品经理大会」将于 7 月 17-18 日在北京正式召开。本次大会精心设计了十二个深度专题,旨在通过最前沿的实战案例,拆解 AI 原生时代的进化密码。
目前大会正式开启演讲议题与优质分享嘉宾招募。
你的每一次真实分享,都在为 AI 原生时代的产品实战手册添砖加瓦。
我们在北京,期待听见你的声音。
议题 & 嘉宾推荐/自荐方式:hemiao@csdn.net


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)