今天火爆全球的Claude Fable 5解读:和Mythos 5其实是同一个模型
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹
1、前言
2026 年 6 月 9 日,Anthropic 一口气放出了两个模型:Claude Fable 5 和 Claude Mythos 5。
名字看着像两个东西,其实是同一个底层模型的两张脸——区别只在安全护栏的位置。更关键的是,它们属于一个全新的能力层级 Mythos-class,定位高于 Opus 一档,是 Claude 5 系列的第一批成员。官方的原话是:Fable 5 的能力"超过我们以往任何公开发布过的模型",在几乎所有测试基准上达到 SOTA。
这篇文章不堆料,只讲三件对开发者真正有用的事:怎么用上它、它和 Mythos 5 到底什么关系、以及它真正的能力边界在哪。

2、先把它用起来:订阅用户怎么跑 Fable 5
按惯例先讲实操——这是大多数人最关心的部分。如果你是 API 用户,claude-fable-5 已经全量可用,没什么好说的;真正有门道的是官方订阅用户(Pro / Max 5x / Max 20x)。
2.1 三档订阅都能用,但有个时间窗口
和以前 Opus 搞 “Max 专属” 不同,这次 Pro、Max 5x、Max 20x 三档全都能用 Fable 5,在 Claude Code 里也能直接选。但有一条要命的时间线:
| 时间段 | 订阅用户能怎么用 |
|---|---|
| 6 月 9 日 – 6 月 22 日 | Fable 5 免费包含在三档订阅额度内,不额外收费 |
| 6 月 23 日起 | 从订阅额度中移除,想继续用必须在 Settings > Usage 充 usage credits,按 API 费率扣(输入 $10 / 输出 $50 / 百万 token) |
| 之后某天 | 官方说"产能允许后会尽快恢复成订阅标配",但没给确定日期 |
一句话:6 月 23 日之后不充值,订阅用户就用不了 Fable 5 了,只能回落到 Opus 4.8。
2.2 在 Claude Code 里切到 Fable 5
它不是任何账户的默认模型(Max/企业版默认仍是 Opus 4.8),必须手动切。三种写法:
| 方式 | 命令 | 作用范围 |
|---|---|---|
| 交互菜单 | /model 选,或直接 /model fable |
当前会话,立即生效 |
| 启动参数 | claude --model claude-fable-5 |
仅当次会话 |
| 环境变量 | export ANTHROPIC_MODEL="claude-fable-5" |
永久默认 |
模型 ID 是 claude-fable-5,用 /status 可以查当前模型和剩余额度。
2.3 一个"烧额度"的现实
这条对日常使用影响最大:订阅内 Fable 5 按约 2 倍 Opus 用量计。同样的活,它消耗你的计划额度比 Opus 快一倍。如果再叠加 max effort(最深推理、不限制 token 花费),消耗还会再上一个台阶——Pro 这种本身额度小的档位,一个稍微长点的 agent 任务可能就见底了。注意额度是 Claude 网页端和 Claude Code 共享的。
⚠️ 一个常见坑:如果你系统里设了
ANTHROPIC_API_KEY环境变量,Claude Code 会优先走 API key 真金白银计费,而不是吃你的订阅额度。想用订阅额度,先确认这个变量没设。
3、Fable 5 和 Mythos 5:同一个模型,两道墙
这是最容易被标题党带偏的地方,先把概念掰清楚。
两者共享同一个底层模型,唯一区别是安全护栏的有无:
- Fable 5——完整护栏,面向公众,API 和订阅都能用。它是"被处理成可以安全通用"的版本。
- Mythos 5——解除了部分领域的护栏,只通过 Project Glasswing(与美国政府合作)向审批过的组织开放,普通开发者拿 API key 是调不到的。
所以对绝大多数人来说,"用上 Mythos 的能力"的实际方式,就是用 Fable 5。官方数据显示 95% 以上的会话根本感知不到护栏存在,两者的差异你很难碰到——除非你的工作恰好是攻防安全或前沿生物研究(且通过审批)。
一个小彩蛋:Fable 源自拉丁文 fabula(“被讲述之物”),Mythos 是希腊文"神话"——故意用一对近义词,命名同一个模型的两张脸。
4、核心能力边界:长时域自主
聊"能力边界",得先分清两层含义:一层是它能做到多强(上限),一层是护栏在哪把它摁回 Opus(限制)。这一节两层都讲。
这代相对 Opus 4.8 真正的核心跃迁,是长时域自主能力——能连续自主跑多久而不跑偏。
4.1 它不是一个能力,是四个能力在长任务里"不退化"
"长时域自主"很容易被当成一句营销话。把它拆开,其实是下面四个底层能力叠加出来的涌现结果:
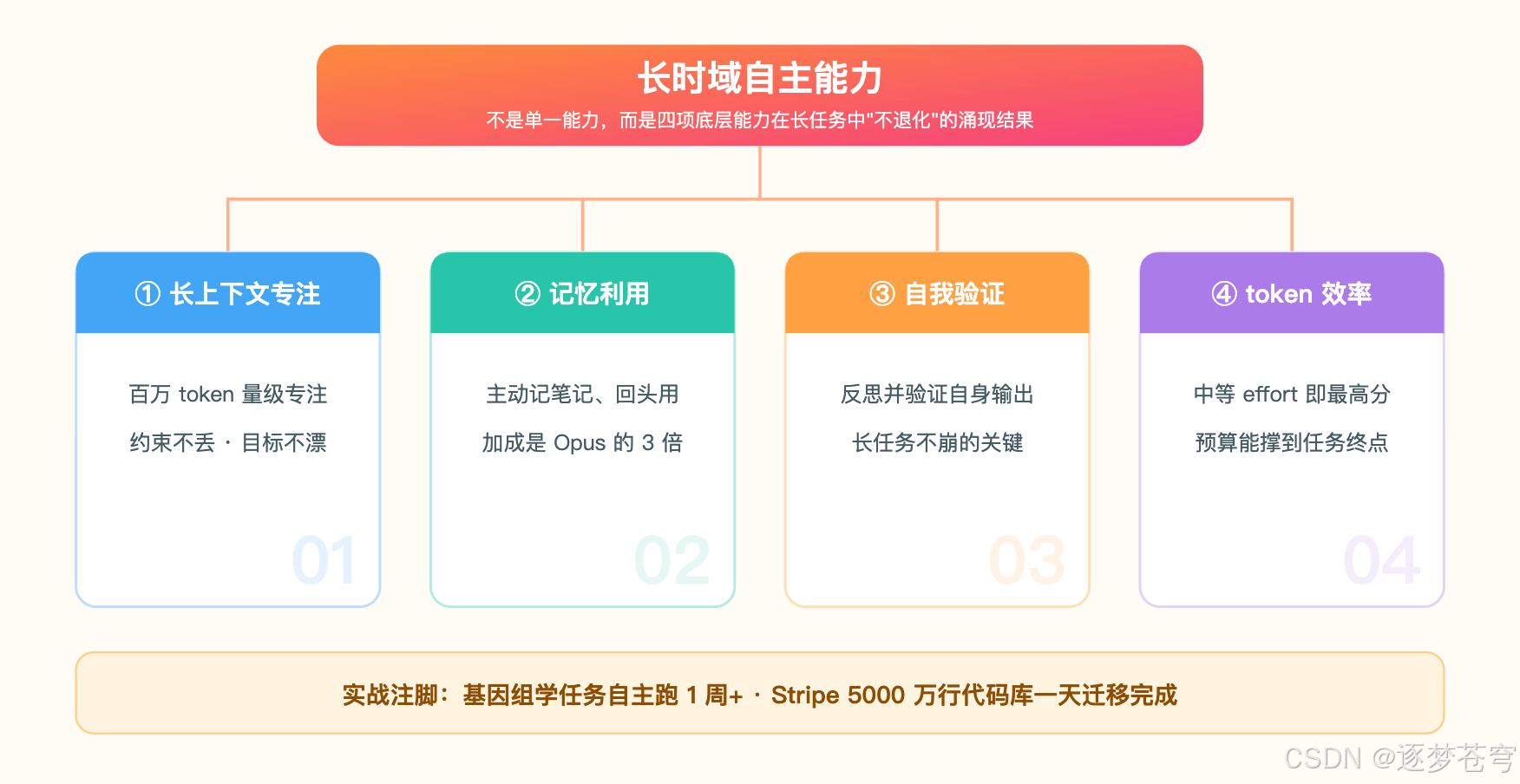
- 长上下文专注——在百万 token 量级里不丢前面的约束、不偏离目标,这是地基。
- 记忆利用——给了持久文件记忆后,Fable 的提升幅度是 Opus 的 3 倍。它不只是"读得进"长上下文,而是会主动记笔记、回头用。
- 自我验证——多个合作伙伴反馈,在高 effort 下它会反思并验证自己的输出,而不是一条道跑到黑。这是长任务不崩的关键。
- token 效率——中等 effort 就能拿到 FrontierCode 前沿模型最高分,意味着它在长任务里不会过早烧光预算,能撑到终点。
最直观的两个实例:用 Mythos 5 做的基因组学任务自主连续跑了一周多;Stripe 在一个 5000 万行的 Ruby 代码库上,用它一天完成了原本整个团队要两个多月的全库迁移。
4.2 benchmark 速览
光说不练假把式,看几个硬指标(数据来自官方及第三方评测):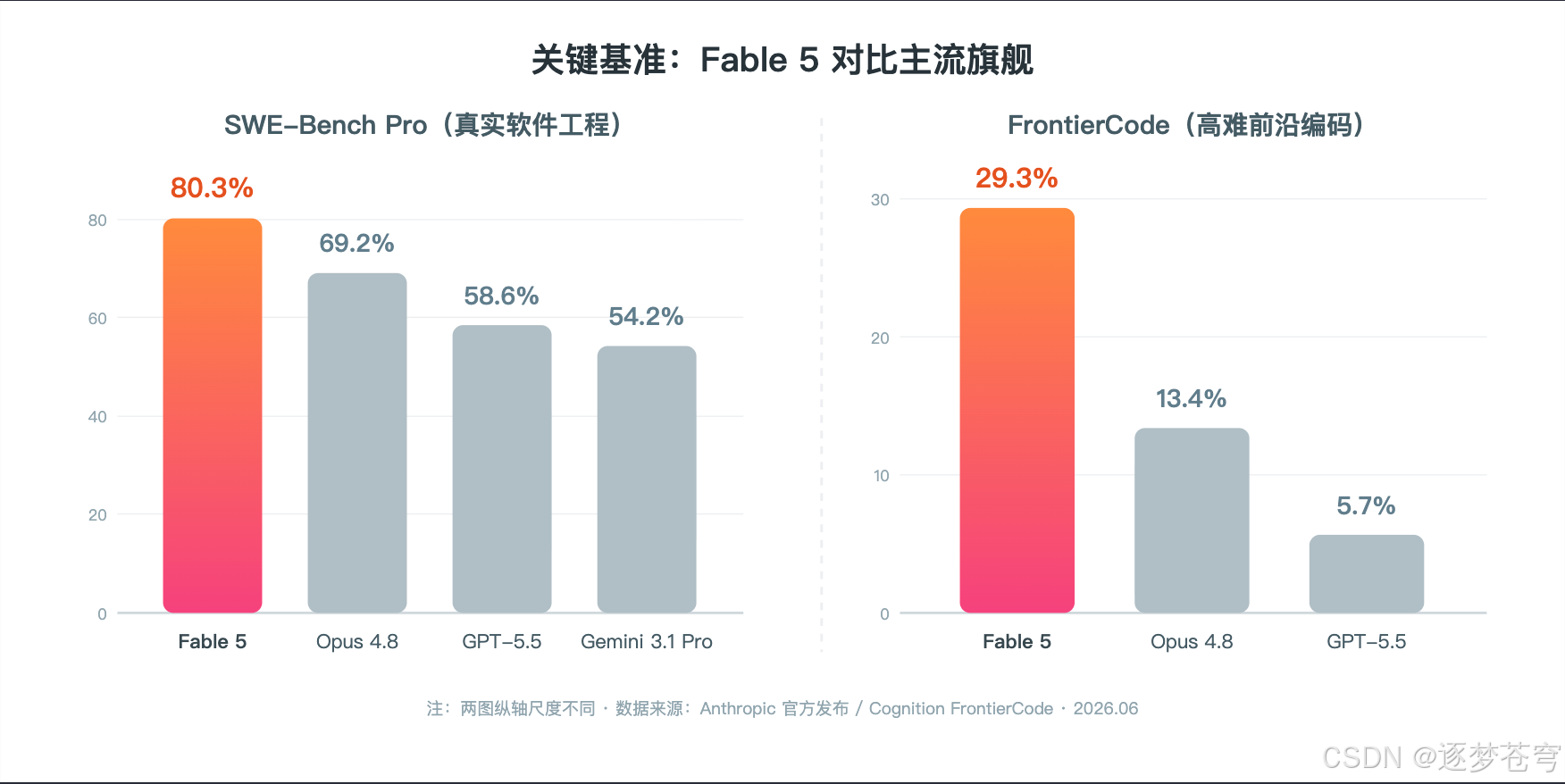
- SWE-Bench Pro(真实软件工程):Fable 5 拿到 80.3%,Opus 4.8 是 69.2%,GPT-5.5 是 58.6%,Gemini 3.1 Pro 是 54.2%。
- FrontierCode(高难编码):Fable 5 29.3%,几乎是 Opus 4.8(13.4%)的两倍多,GPT-5.5 只有 5.7%。
- 视觉:能从科学图表里抽精确数字、仅凭截图重建网页源码,纯视觉框架就通关了宝可梦。
4.3 别忽略另一条边界:护栏会"悄悄降档"
这是企业落地里最阴险的一层。Fable 5 配了一套独立 AI 分类器,覆盖三个高风险领域:网络安全、生物/化学、蒸馏(防止他方提取模型能力)。
命中后它不是报错,而是静默回退到 Opus 4.8 并告知用户。官方说平均 <5% 的会话会触发,但护栏调得偏保守、会误判无害请求。对一个跑批的自动化流水线来说,这意味着:极小比例的请求会被悄悄换成一个更弱的模型,结果质量可能莫名波动——这是你做监控时必须埋点的地方。
5、什么任务配得上 Fable?
落到选型,给一个务实判断:
- ✅ 配得上:一次坐下来做不完、需要它自己规划 → 执行 → 验证 → 纠错的长任务。比如大规模代码迁移、跨数百文件的重构、需要长时间自主探索的研究型任务。这种场景下,2 倍溢价能从"省下的人力时间"里赚回来。
- ❌ 不太划算:短平快的一问一答、固定几步的小流程。这类任务吃不到长时域红利,反而是 2 倍权重 + max effort 在纯烧钱,Opus 4.8 甚至 Sonnet 更合适。
一句话总结:Fable 5 的价值不在"它更聪明",而在"它能在一个长任务里坚持得更久、更不容易崩"。判断要不要为它买单,就看你手上有没有那种值得让 agent 自主连续跑上半小时乃至几小时的活——有,溢价成立;没有,把它留给真正的硬骨头,日常切回 Opus / Sonnet 更香。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)