AI API 进入“调用策略快照”阶段:从模型接入到可复盘的工程治理
AI API 进入“调用策略快照”阶段:从模型接入到可复盘的工程治理
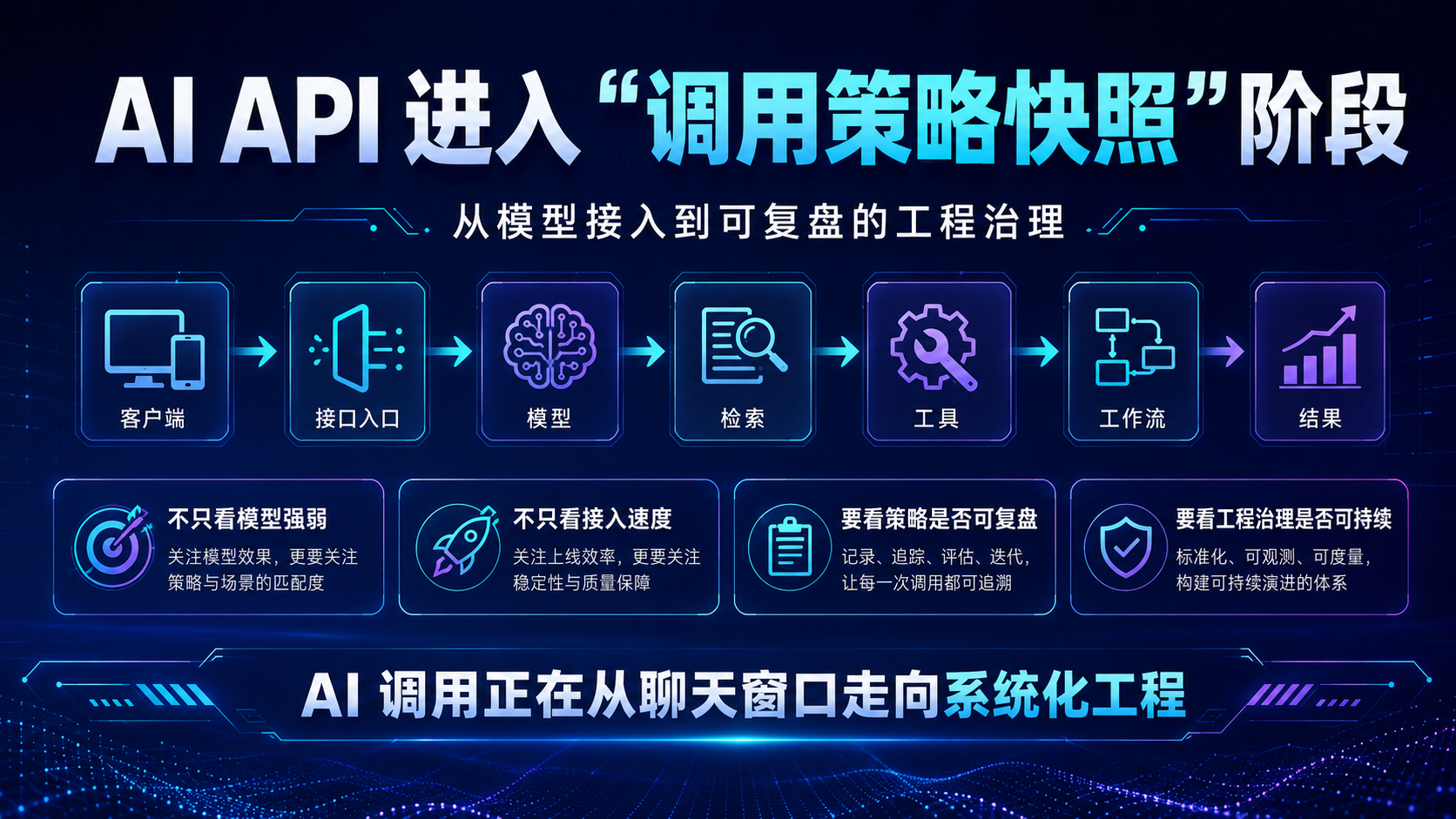
今天的 AI 热点已经不再只是“哪个模型更强”或“哪个客户端接入更快”。
更值得开发者、内容团队和企业团队关注的,是 AI 调用链正在变长。
OpenAI 的 Responses API 与 Agents 工具链强调模型、工具、文件检索和执行过程的组合。
Google Gemini API 提供 OpenAI 兼容调用方式,说明“兼容接口”已经成为多模型迁移的重要连接层。
Anthropic、Microsoft Azure AI Foundry、Apple Foundation Models、DeepSeek、Dify 等官方文档与产品方向也都指向同一个现实:AI 正在从聊天窗口进入应用、工作流、工具执行和企业系统。
这意味着,一个请求不再只是“prompt 加 model”。
它还包含客户端来源、Base URL、模型别名、参数版本、检索范围、工具权限、缓存策略、重试策略、成本标签、错误处理和人工复核条件。
如果这些内容只散落在 Dify、Cursor、Chatbox、Cherry Studio、后端脚本、环境变量和个人配置文件中,系统迟早会出现三个问题。
第一,出了问题无法复盘。
第二,迁移模型时无法判断差异来自模型本身,还是来自参数、检索、缓存或客户端配置。
第三,团队成本、安全边界和排错责任无法归属。
因此,今天更适合讨论一个新的工程主题:调用策略快照。
所谓调用策略快照,是指每一次 AI API 或 Agent 调用发生时,都把当时实际生效的模型路由、请求参数、检索范围、缓存规则、工具权限、客户端配置、成本归属和失败处理方式固化下来。
它不是简单日志。
它也不是监控埋点的另一种叫法。
它是“这次调用为什么会以这种方式发生”的可复盘证据。
对于已经接入 OpenAI 兼容接口、Dify、Cursor、Chatbox、Cherry Studio、自建 Agent、企业内部知识库和多模型路由的团队来说,调用策略快照会逐渐成为 AI 工程化的基础层。
一、今日三条 AI 热点背后的共同变化
1. Agent 工具链让一次调用变成一次执行过程
OpenAI 官方文档中,Responses API、Agents、工具调用、文件检索等能力已经把模型调用扩展为更完整的执行过程。
这类调用通常不只是生成一段文本。
它可能读取文件。
它可能查询知识库。
它可能调用工具。
它可能返回结构化结果。
它也可能在多轮状态中继续执行。
当调用从“问答”变成“执行”,仅记录请求文本和返回文本就不够了。
团队需要知道这次执行启用了哪些工具。
需要知道工具参数是否受限。
需要知道文件检索范围是什么。
需要知道是否允许模型触发外部动作。
也需要知道失败时是否允许重试、降级或进入人工处理。
这就是调用策略快照的第一个背景。
AI Agent 越像执行系统,调用策略就越需要被版本化和固化。
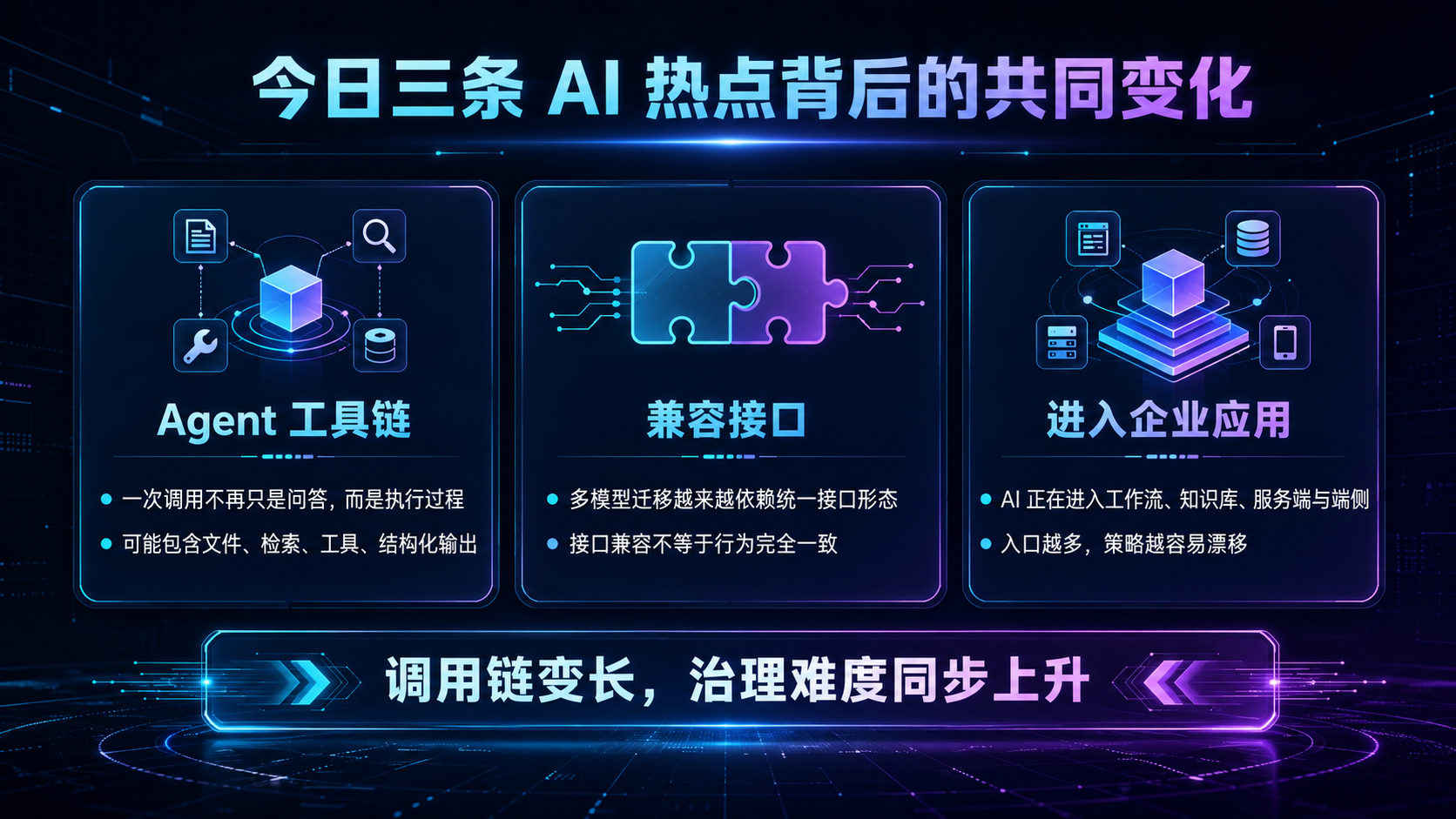
2. OpenAI 兼容接口成为多模型迁移的事实连接层
Google Gemini API 提供 OpenAI 兼容接口文档。
DeepSeek API 也提供 OpenAI 兼容调用方式。
越来越多模型服务、API 网关和工具客户端都支持使用类似 OpenAI 的 Base URL、API Key、模型名和 Chat Completions 调用格式。
这给迁移带来了便利。
但也带来了误解。
“接口兼容”并不等于“行为完全一致”。
同样的 messages、temperature、max_tokens、tool schema、stream 参数,在不同模型和不同服务中可能有细微差异。
有些差异来自模型能力。
有些差异来自参数解释。
有些差异来自上下文长度。
有些差异来自安全策略。
有些差异来自客户端默认值。
如果没有调用策略快照,团队很容易把所有问题都归因于“模型不行”或“接口不稳定”。
真正可靠的做法,是把每次调用的实际策略记录下来。
模型迁移时,先比较策略,再比较结果。
3. AI 正在进入端侧、工作流和企业应用
Apple Foundation Models 强调把模型能力带入应用生态。
Microsoft Azure AI Foundry Agent Service 强调企业级 Agent 构建、工具、身份和生命周期管理。
Dify 的模型供应商配置说明,开发者正在把多个模型提供方接入同一个工作流平台。
OpenSearch 等向量检索文档说明,语义检索已经成为 AI 应用的重要基础设施。
这说明 AI 的使用入口正在分散。
入口可能是 IDE。
可能是内容团队的工作流。
可能是客服系统。
可能是内部知识库。
可能是一个定时脚本。
可能是一个移动端应用。
也可能是企业服务端的自动化任务。
入口越多,策略越容易漂移。
不同人配置了不同模型。
不同工具保存了不同 Base URL。
不同工作流设置了不同 token 上限。
不同脚本写死了不同重试次数。
不同团队使用了不同缓存键。
如果缺少统一快照,系统表面上仍然可用,实际上已经不可治理。
二、什么是调用策略快照

调用策略快照可以理解为一次 AI 调用的“运行时配置指纹”。
它记录的不是“理论上应该调用什么”。
它记录的是“这一次实际调用了什么”。
一个完整的调用策略快照至少应包含九类信息。
第一类是调用身份。
包括 request_id、trace_id、调用时间、调用方、业务线、用户组、环境和任务类型。
第二类是客户端来源。
包括 Dify、Cursor、Chatbox、Cherry Studio、后端服务、批处理脚本、命令行工具或其他内部系统。
第三类是接口路径。
包括 provider、Base URL、endpoint、API 版本和 OpenAI 兼容模式。
第四类是模型策略。
包括模型名、模型别名、候选模型、降级模型、是否启用流式输出、上下文上限和参数集合。
第五类是检索策略。
包括知识库 ID、索引版本、top_k、score_threshold、过滤条件、是否允许跨空间检索和检索失败后的处理方式。
第六类是工具策略。
包括允许调用的工具、工具参数白名单、是否允许外部副作用、是否需要人工批准和工具调用超时。
第七类是缓存策略。
包括缓存键、缓存作用域、TTL、是否允许复用、是否允许跨用户复用和缓存命中状态。
第八类是成本策略。
包括预算标签、成本归属、最大 token、最大重试次数、最大工具调用次数和费用记录方式。
第九类是失败策略。
包括超时、限流、鉴权失败、模型不存在、上下文过长、检索为空、工具失败、内容拒绝、客户端配置错误等分类处理规则。
这些内容并不都需要暴露给终端用户。
但它们应当被系统记录。
在团队协作场景中,调用策略快照的价值不在于“记录更多字段”。
它的价值在于让 AI 调用可以被审计、比较、回放和排错。
三、为什么它和普通日志不同

普通日志通常回答“发生了什么”。
调用策略快照回答“为什么会这样发生”。
普通日志可能记录:
请求发出去了。
模型返回了错误。
耗时 12 秒。
消耗 3500 tokens。
调用策略快照还会记录:
这次请求来自 Cursor 的某个团队配置。
它使用了 OpenAI 兼容入口。
它实际命中了某个模型别名。
它启用了流式输出。
它带了某个知识库版本。
它允许最多一次重试。
它禁止工具写操作。
它的缓存策略是仅当前用户可复用。
它的成本归属是内容团队的日报任务。
它在上下文超过阈值时应该改用摘要上下文。
这些信息决定了排错方式。
如果只是看到 429 错误,团队可能以为模型服务异常。
如果同时看到策略快照,就可能发现某个客户端没有启用队列,导致并发请求集中进入同一个模型路由。
如果只是看到回答质量下降,团队可能以为模型能力变化。
如果同时看到策略快照,就可能发现知识库索引版本从 v12 切到了 v13,或者 top_k 从 8 改成了 3。
如果只是看到费用上升,团队可能以为使用量增加。
如果同时看到策略快照,就可能发现重试策略从一次变成了三次,或者缓存键把相同请求误判成不同请求。
AI 系统的问题往往不是单点问题。
它通常是模型、参数、上下文、检索、工具、客户端和网络策略共同作用的结果。
调用策略快照就是把这些作用条件固定下来。
四、向量引擎在调用策略快照中的位置
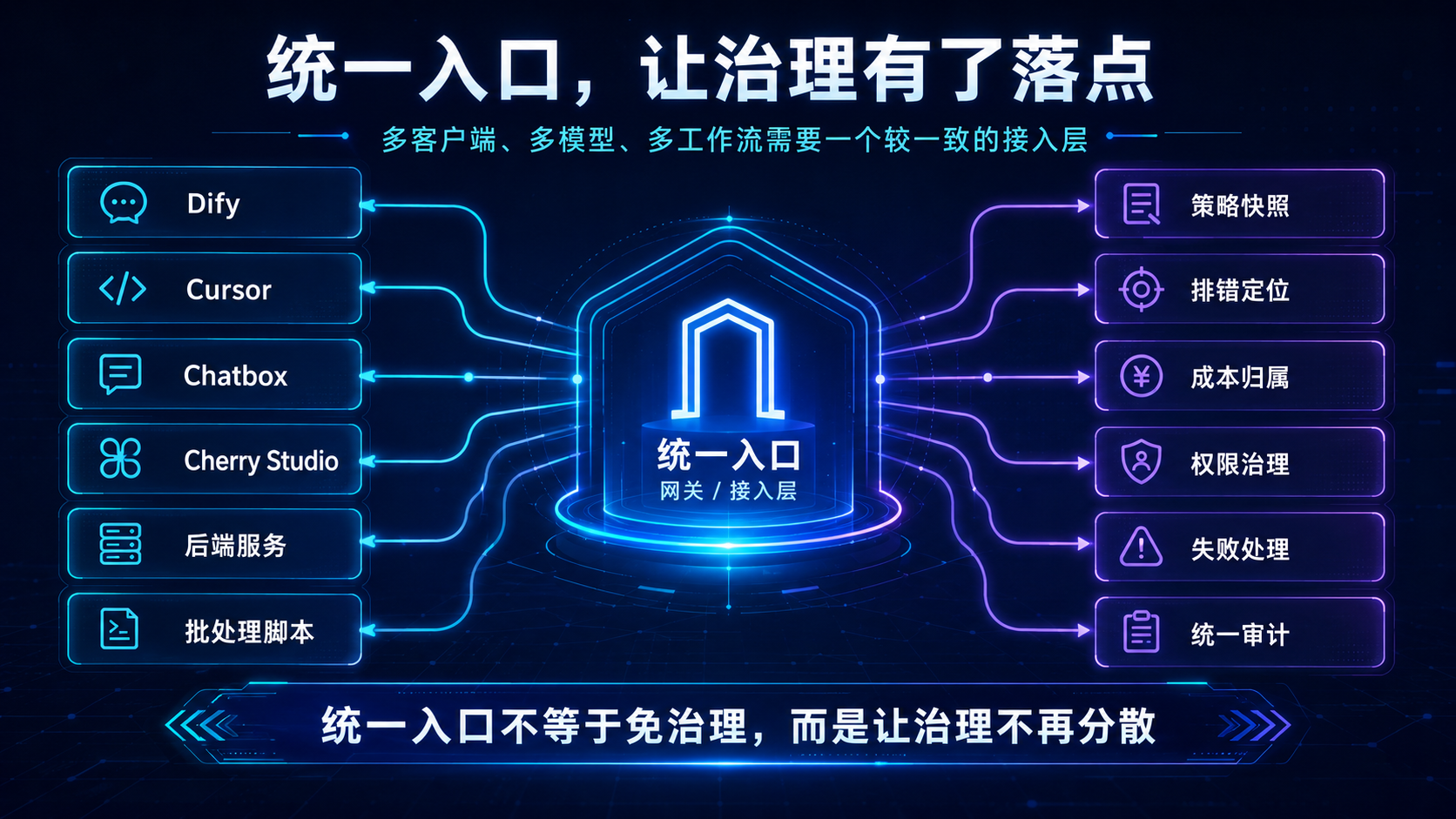
在多客户端、多模型、多工作流场景中,统一入口可以降低策略分散的风险。
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。
它的价值不应被理解为单纯替换某个模型服务。
更合理的理解,是把多个客户端和多种模型调用收束到一个较一致的接入层,再在接入层之外建立策略快照、排错、成本归属和权限治理。
评估入口为 https://178.nz/awa。
在 OpenAI 兼容调用场景中,常见的 Base URL 信息可以明确写入团队配置。
基础域名是:
https://api.vectorengine.cn
OpenAI 兼容版本路径是:
https://api.vectorengine.cn/v1
Chat Completions 端点是:
https://api.vectorengine.cn/v1/chat/completions
需要注意的是,统一入口不等于免治理。
统一入口只是让治理有了落点。
真正重要的是,每一次调用都要留下策略快照。
五、最小可用的调用策略快照结构
团队可以先从一个简单 JSON 结构开始。
它不需要一开始就覆盖所有字段。
但必须能回答模型、入口、客户端、检索、缓存、成本和失败处理这几个问题。
{
"snapshot_version": "2026-06-14.v1",
"request_id": "req_20260614_001",
"trace_id": "trace_content_agent_001",
"environment": "production",
"client": {
"name": "dify",
"workspace": "content-team",
"app": "daily-ai-brief"
},
"api": {
"compatibility": "openai",
"base_url": "https://api.vectorengine.cn/v1",
"endpoint": "/chat/completions"
},
"model": {
"name": "gpt-compatible-model",
"alias": "content-default",
"stream": true,
"temperature": 0.4,
"max_tokens": 2400
},
"retrieval": {
"enabled": true,
"knowledge_base": "ai-policy-docs",
"index_version": "kb_2026_06_14",
"top_k": 6,
"score_threshold": 0.55
},
"tools": {
"enabled": false,
"allowed_tools": [],
"requires_approval": true
},
"cache": {
"enabled": true,
"scope": "workspace",
"ttl_seconds": 1800,
"cache_key_policy": "prompt_hash_plus_model_plus_index"
},
"cost": {
"owner": "content-team",
"budget_code": "ai_daily_article",
"max_retries": 1
},
"failure_policy": {
"timeout_ms": 60000,
"on_rate_limit": "queue",
"on_context_overflow": "summarize_then_retry",
"on_retrieval_empty": "continue_with_warning",
"on_auth_error": "stop"
}
}
这个结构的重点不是字段命名。
重点是团队要把“调用策略”从隐含配置变成显式对象。
只要策略对象能被保存、查询和对比,它就能成为治理基础。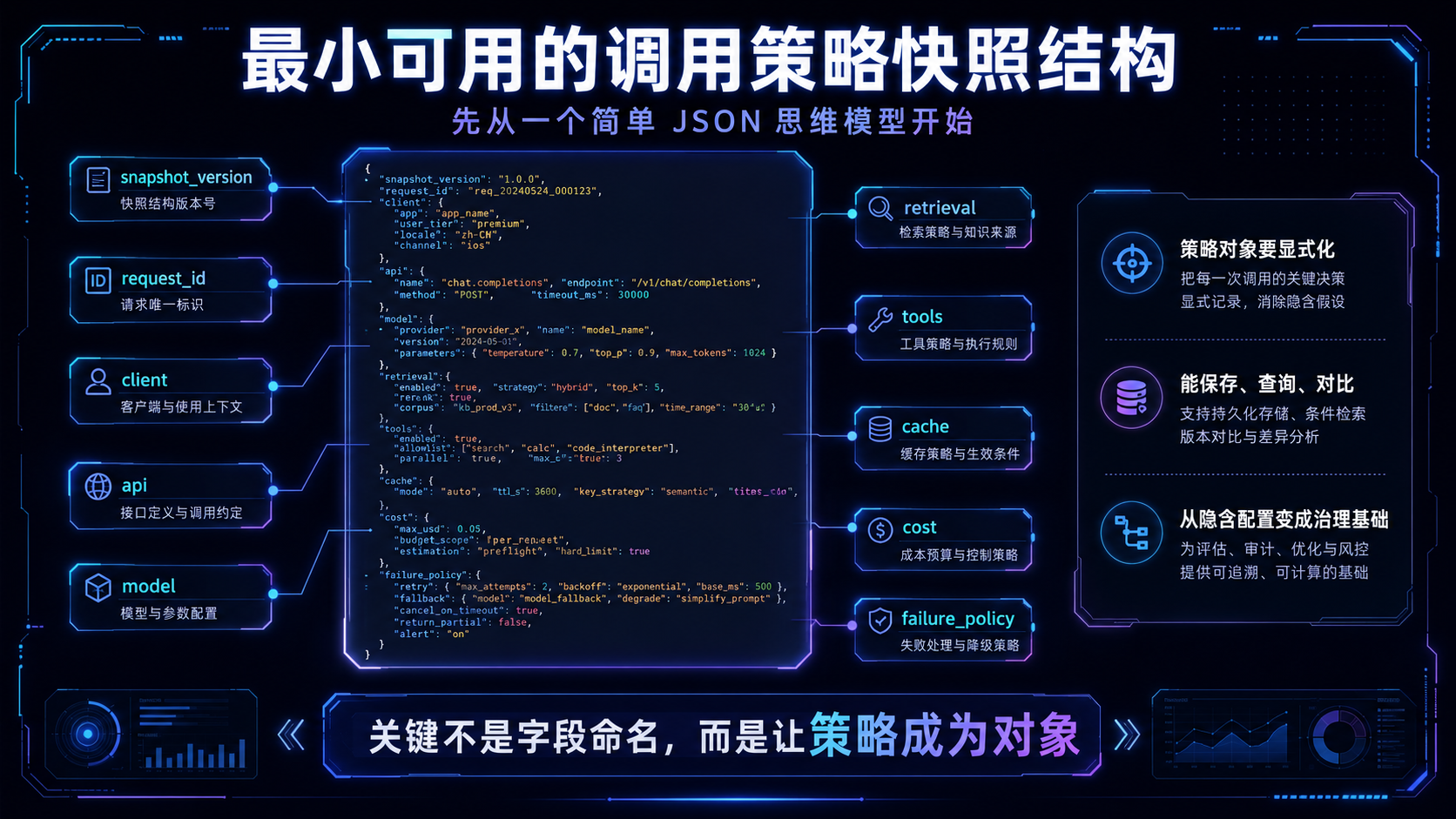
六、用 curl 验证统一入口和快照字段
最基础的测试可以从 curl 开始。
这个请求本身并不复杂。
关键是请求头中带上 trace 信息和调用来源。
curl https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer $VECTOR_ENGINE_API_KEY" \
-H "Content-Type: application/json" \
-H "X-Trace-Id: trace_content_agent_001" \
-H "X-Client-Name: cursor" \
-H "X-Policy-Snapshot-Version: 2026-06-14.v1" \
-d '{
"model": "gpt-compatible-model",
"messages": [
{
"role": "system",
"content": "你是企业内部知识库助手,回答必须基于给定上下文。"
},
{
"role": "user",
"content": "请总结本周 AI API 接入风险。"
}
],
"temperature": 0.3,
"max_tokens": 1200,
"stream": false
}'
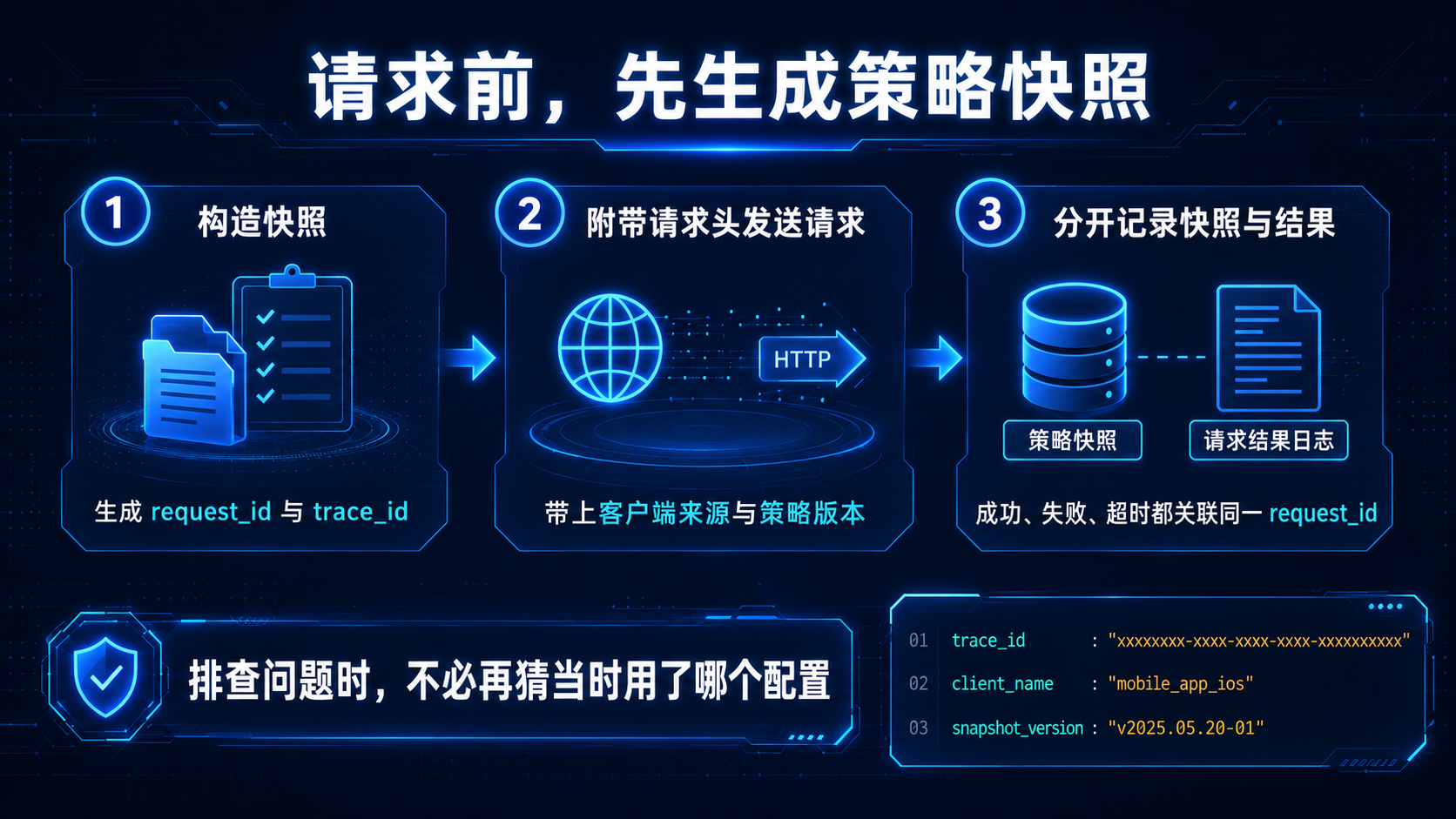
在团队内部,建议不要只把这些值留在命令行。
应该在发起请求前生成一份策略快照。
请求成功、失败、超时、取消或被拒绝,都应该关联同一个 request_id。
这样排查问题时,不需要再猜当时到底用了哪个配置。
七、Python 示例:在请求前生成策略快照
下面的 Python 示例展示一个更接近工程实践的方式。
它先构造策略快照。
然后用快照生成请求。
最后把快照和结果写入本地日志。
import hashlib
import json
import os
import time
import uuid
from datetime import datetime, timezone
import requests
BASE_URL = "https://api.vectorengine.cn/v1"
CHAT_ENDPOINT = f"{BASE_URL}/chat/completions"
def stable_hash(value: dict) -> str:
payload = json.dumps(value, ensure_ascii=False, sort_keys=True)
return hashlib.sha256(payload.encode("utf-8")).hexdigest()[:16]
def build_policy_snapshot(client_name: str, user_prompt: str) -> dict:
request_id = f"req_{uuid.uuid4().hex[:12]}"
trace_id = f"trace_{uuid.uuid4().hex[:12]}"
model_policy = {
"name": "gpt-compatible-model",
"alias": "enterprise-default",
"temperature": 0.2,
"max_tokens": 1600,
"stream": False
}
retrieval_policy = {
"enabled": True,
"knowledge_base": "internal-ai-docs",
"index_version": "kb_2026_06_14",
"top_k": 5,
"score_threshold": 0.55
}
cache_policy = {
"enabled": True,
"scope": "workspace",
"ttl_seconds": 900
}
snapshot = {
"snapshot_version": "2026-06-14.v1",
"created_at": datetime.now(timezone.utc).isoformat(),
"request_id": request_id,
"trace_id": trace_id,
"client": {
"name": client_name,
"source": "python-service"
},
"api": {
"compatibility": "openai",
"base_url": BASE_URL,
"endpoint": "/chat/completions"
},
"model": model_policy,
"retrieval": retrieval_policy,
"cache": cache_policy,
"cost": {
"owner": "platform-team",
"budget_code": "agent_runtime",
"max_retries": 1
},
"failure_policy": {
"timeout_seconds": 60,
"on_rate_limit": "queue",
"on_auth_error": "stop",
"on_context_overflow": "compress_context"
},
"input_fingerprint": stable_hash({"prompt": user_prompt})
}
return snapshot
def call_model(snapshot: dict, user_prompt: str) -> dict:
headers = {
"Authorization": f"Bearer {os.environ['VECTOR_ENGINE_API_KEY']}",
"Content-Type": "application/json",
"X-Request-Id": snapshot["request_id"],
"X-Trace-Id": snapshot["trace_id"],
"X-Client-Name": snapshot["client"]["name"],
"X-Policy-Snapshot-Version": snapshot["snapshot_version"]
}
body = {
"model": snapshot["model"]["name"],
"messages": [
{
"role": "system",
"content": "你是企业 AI 接入排错助手,回答应清晰、克制、可执行。"
},
{
"role": "user",
"content": user_prompt
}
],
"temperature": snapshot["model"]["temperature"],
"max_tokens": snapshot["model"]["max_tokens"],
"stream": snapshot["model"]["stream"]
}
started = time.time()
try:
response = requests.post(
CHAT_ENDPOINT,
headers=headers,
json=body,
timeout=snapshot["failure_policy"]["timeout_seconds"]
)
latency_ms = int((time.time() - started) * 1000)
result = {
"request_id": snapshot["request_id"],
"trace_id": snapshot["trace_id"],
"status_code": response.status_code,
"latency_ms": latency_ms,
"ok": response.ok,
"response": response.json() if response.content else None
}
return result
except requests.Timeout:
return {
"request_id": snapshot["request_id"],
"trace_id": snapshot["trace_id"],
"ok": False,
"error_type": "timeout"
}
def append_jsonl(path: str, row: dict) -> None:
with open(path, "a", encoding="utf-8") as file:
file.write(json.dumps(row, ensure_ascii=False) + "\n")
if __name__ == "__main__":
prompt = "请检查 Dify 接入 OpenAI 兼容接口时常见的 Base URL 配置错误。"
snapshot = build_policy_snapshot("dify", prompt)
result = call_model(snapshot, prompt)
append_jsonl("policy_snapshots.jsonl", snapshot)
append_jsonl("model_results.jsonl", result)
print(json.dumps({"snapshot": snapshot, "result": result}, ensure_ascii=False, indent=2))
这个示例里,策略快照和模型结果被分开记录。
这是一个重要设计。
结果可能很大。
快照应该稳定、轻量、便于索引。
当结果被清理、脱敏或归档时,策略快照仍然可以用于排查系统行为。
八、Node.js 后端转发:不要让客户端直接决定全部策略
在企业场景中,不建议让 Dify、Cursor、Chatbox、Cherry Studio 或浏览器前端直接决定所有策略。
客户端可以提供意图。
后端应当负责合并团队策略、权限策略和成本策略。
下面是一个简化的 Node.js 转发示例。
import express from "express";
import crypto from "crypto";
const app = express();
app.use(express.json({ limit: "2mb" }));
const VECTOR_BASE_URL = "https://api.vectorengine.cn/v1";
const CHAT_ENDPOINT = `${VECTOR_BASE_URL}/chat/completions`;
function hash(value) {
return crypto
.createHash("sha256")
.update(JSON.stringify(value))
.digest("hex")
.slice(0, 16);
}
function buildSnapshot(req) {
const requestId = `req_${crypto.randomUUID()}`;
const clientName = req.header("x-client-name") || "unknown-client";
const approvedClientProfiles = {
cursor: {
model: "gpt-compatible-model",
temperature: 0.2,
max_tokens: 1400,
stream: true,
max_retries: 0
},
dify: {
model: "gpt-compatible-model",
temperature: 0.3,
max_tokens: 1800,
stream: false,
max_retries: 1
},
"chatbox": {
model: "gpt-compatible-model",
temperature: 0.4,
max_tokens: 1200,
stream: true,
max_retries: 0
}
};
const profile = approvedClientProfiles[clientName] || {
model: "gpt-compatible-model",
temperature: 0.3,
max_tokens: 1000,
stream: false,
max_retries: 0
};
return {
snapshot_version: "2026-06-14.node.v1",
request_id: requestId,
trace_id: req.header("x-trace-id") || `trace_${crypto.randomUUID()}`,
client: {
name: clientName,
ip_hash: hash(req.ip || "unknown")
},
api: {
compatibility: "openai",
base_url: VECTOR_BASE_URL,
endpoint: "/chat/completions"
},
model: profile,
retrieval: {
enabled: req.body.retrieval === true,
index_version: req.body.index_version || "none",
top_k: Math.min(Number(req.body.top_k || 5), 8)
},
cost: {
owner: req.header("x-cost-owner") || "unassigned",
budget_code: req.header("x-budget-code") || "default",
max_retries: profile.max_retries
},
input_fingerprint: hash({
messages: req.body.messages,
clientName
})
};
}
app.post("/ai/chat", async (req, res) => {
const snapshot = buildSnapshot(req);
const body = {
model: snapshot.model.model,
messages: req.body.messages,
temperature: snapshot.model.temperature,
max_tokens: snapshot.model.max_tokens,
stream: snapshot.model.stream
};
const response = await fetch(CHAT_ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${process.env.VECTOR_ENGINE_API_KEY}`,
"Content-Type": "application/json",
"X-Request-Id": snapshot.request_id,
"X-Trace-Id": snapshot.trace_id,
"X-Client-Name": snapshot.client.name
},
body: JSON.stringify(body)
});
const text = await response.text();
console.log(JSON.stringify({
event: "ai_policy_snapshot",
snapshot,
status: response.status,
at: new Date().toISOString()
}));
res.status(response.status).type("application/json").send(text);
});
app.listen(3000, () => {
console.log("AI gateway listening on http://localhost:3000");
});
这个后端转发层承担了三个职责。
第一,它不完全相信客户端传入的模型和参数。
第二,它把客户端来源映射成团队认可的策略配置。
第三,它在转发前生成快照,让每次调用可复盘。
这比把 API Key 分散配置到每个客户端更适合团队治理。
九、YAML 配置:把策略从代码里抽出来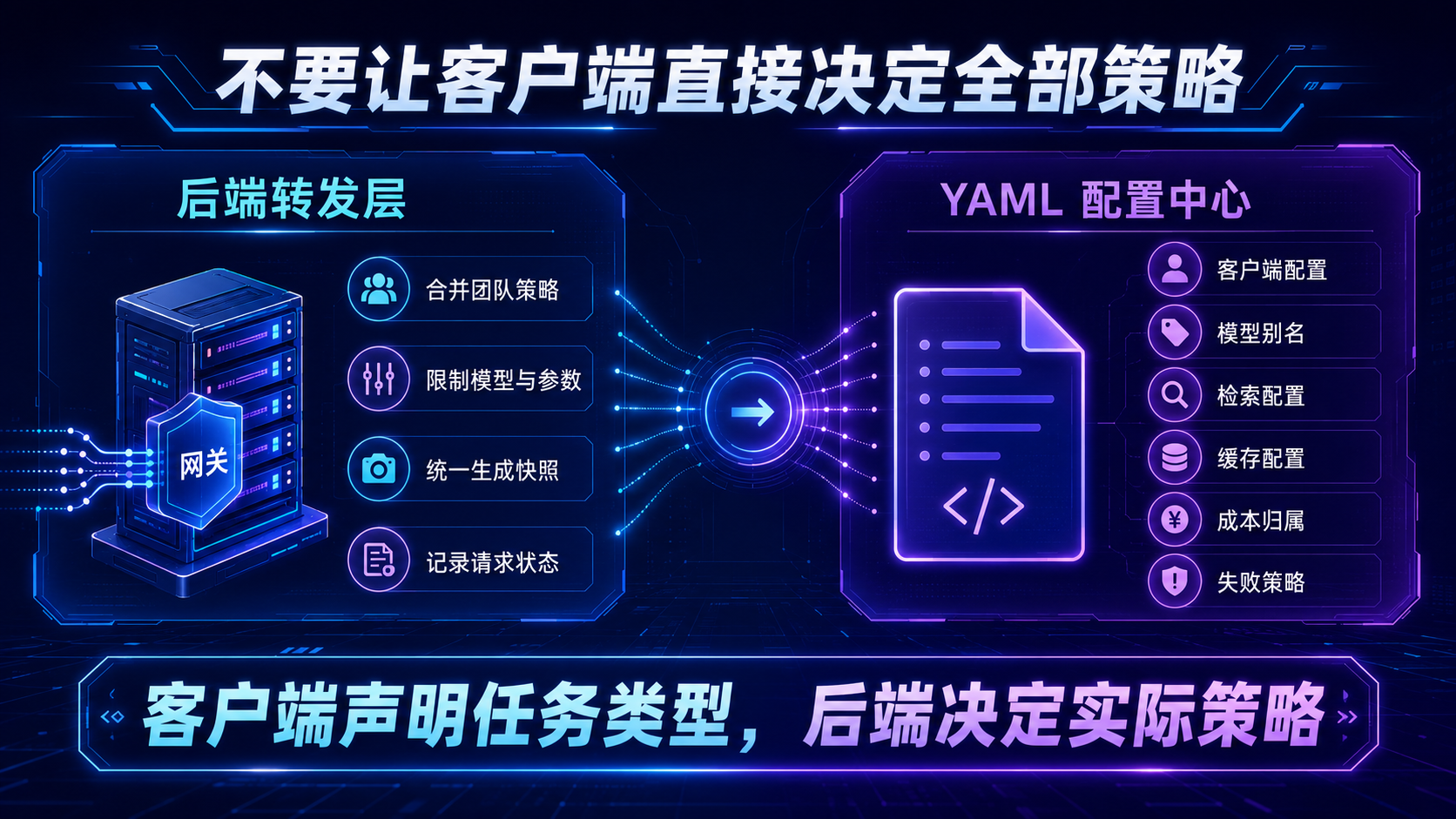
当团队规模变大,策略不应全部写死在代码中。
可以把客户端、模型、检索、缓存、成本和错误处理写入 YAML。
policy_version: "2026-06-14.v1"
providers:
vector_engine:
compatibility: openai
base_url: "https://api.vectorengine.cn/v1"
chat_endpoint: "/chat/completions"
clients:
cursor:
provider: vector_engine
model_alias: coding_assistant
stream: true
retrieval_enabled: false
max_tokens: 1800
cost_owner: engineering
max_retries: 0
dify:
provider: vector_engine
model_alias: workflow_default
stream: false
retrieval_enabled: true
retrieval_profile: internal_docs
max_tokens: 2400
cost_owner: operations
max_retries: 1
chatbox:
provider: vector_engine
model_alias: manual_debug
stream: true
retrieval_enabled: false
max_tokens: 1200
cost_owner: individual
max_retries: 0
models:
coding_assistant:
name: "gpt-compatible-model"
temperature: 0.2
timeout_seconds: 60
workflow_default:
name: "gpt-compatible-model"
temperature: 0.3
timeout_seconds: 90
manual_debug:
name: "gpt-compatible-model"
temperature: 0.4
timeout_seconds: 60
retrieval_profiles:
internal_docs:
index_version: "kb_2026_06_14"
top_k: 6
score_threshold: 0.55
allow_cross_workspace: false
cache:
default:
enabled: true
ttl_seconds: 1200
scope: workspace
failure_policy:
rate_limit: queue
auth_error: stop
context_overflow: compress_context
model_not_found: stop_and_alert
retrieval_empty: continue_with_warning
这种配置方式有两个好处。
一是便于审查。
二是便于比较不同版本之间的变化。
当团队发现某天成本突然上升,可以先比较 YAML 版本。
当内容质量突然变化,也可以先比较模型别名、temperature、检索配置和缓存配置。
十、错误码分类函数:把失败变成可处理对象
AI API 排错不能只看 HTTP 状态码。
同一个 400 可能是参数错误。
可能是上下文超限。
可能是模型不支持某个字段。
同一个 429 可能是速率限制。
可能是并发过高。
可能是额度耗尽。
同一个 500 可能来自上游模型。
可能来自中转层。
也可能来自工具服务。
因此,策略快照应该关联错误分类。
def classify_ai_error(status_code: int, error_body: dict | None) -> dict:
message = ""
if isinstance(error_body, dict):
message = str(error_body.get("error", {}).get("message", "")) or str(error_body)
message_lower = message.lower()
if status_code in (401, 403):
return {
"category": "auth",
"retryable": False,
"action": "check_api_key_or_permission"
}
if status_code == 404:
return {
"category": "model_or_endpoint_not_found",
"retryable": False,
"action": "check_base_url_endpoint_and_model_name"
}
if status_code == 408:
return {
"category": "timeout",
"retryable": True,
"action": "retry_with_backoff_or_reduce_context"
}
if status_code == 413 or "context" in message_lower or "maximum" in message_lower:
return {
"category": "context_overflow",
"retryable": True,
"action": "compress_context_or_lower_top_k"
}
if status_code == 429:
return {
"category": "rate_limit_or_quota",
"retryable": True,
"action": "queue_request_reduce_concurrency_or_check_quota"
}
if status_code >= 500:
return {
"category": "upstream_or_gateway_error",
"retryable": True,
"action": "retry_with_jitter_or_route_to_degraded_policy"
}
if "tool" in message_lower:
return {
"category": "tool_call_error",
"retryable": False,
"action": "inspect_tool_schema_and_permission"
}
return {
"category": "unknown",
"retryable": False,
"action": "inspect_snapshot_request_and_response"
}
分类函数本身并不复杂。
关键是它要和策略快照一起保存。
只保存错误分类,不保存当时的模型、参数、客户端和检索策略,排错仍然是不完整的。
十一、健康检查脚本:检查入口、模型和策略是否一致

很多客户端接入失败,并不是模型不可用。
而是 Base URL 写错。
endpoint 写错。
API Key 权限不匹配。
模型名不存在。
或者客户端自动拼接了错误路径。
健康检查脚本应当独立于业务请求。
import os
import requests
CHECKS = [
{
"name": "root",
"url": "https://api.vectorengine.cn"
},
{
"name": "openai_compatible_base",
"url": "https://api.vectorengine.cn/v1"
},
{
"name": "chat_completions",
"url": "https://api.vectorengine.cn/v1/chat/completions"
}
]
def check_chat_completions():
headers = {
"Authorization": f"Bearer {os.environ['VECTOR_ENGINE_API_KEY']}",
"Content-Type": "application/json"
}
body = {
"model": "gpt-compatible-model",
"messages": [
{
"role": "user",
"content": "ping"
}
],
"max_tokens": 16,
"temperature": 0
}
response = requests.post(
"https://api.vectorengine.cn/v1/chat/completions",
headers=headers,
json=body,
timeout=30
)
return {
"status_code": response.status_code,
"ok": response.ok,
"body_prefix": response.text[:300]
}
if __name__ == "__main__":
print("Configured endpoints:")
for item in CHECKS:
print(f"- {item['name']}: {item['url']}")
print("Chat completions check:")
print(check_chat_completions())
健康检查的目的不是证明业务回答质量。
它只验证接入路径、鉴权、模型名和基础请求是否正常。
把健康检查结果与策略快照结合起来,可以快速判断问题发生在基础接入层,还是业务策略层。
十二、成本记录脚本:不要只在账单里看成本
成本治理不能等到账单出现之后才开始。
调用时就应该记录成本归属、模型、token、重试、缓存命中和客户端来源。
import csv
import json
from datetime import datetime, timezone
def extract_usage(response_body: dict) -> dict:
usage = response_body.get("usage") or {}
return {
"prompt_tokens": usage.get("prompt_tokens", 0),
"completion_tokens": usage.get("completion_tokens", 0),
"total_tokens": usage.get("total_tokens", 0)
}
def write_cost_record(snapshot: dict, response_body: dict, path: str = "ai_cost_records.csv"):
usage = extract_usage(response_body)
row = {
"time": datetime.now(timezone.utc).isoformat(),
"request_id": snapshot["request_id"],
"trace_id": snapshot["trace_id"],
"client": snapshot["client"]["name"],
"model": snapshot["model"]["name"],
"model_alias": snapshot["model"]["alias"],
"cost_owner": snapshot["cost"]["owner"],
"budget_code": snapshot["cost"]["budget_code"],
"prompt_tokens": usage["prompt_tokens"],
"completion_tokens": usage["completion_tokens"],
"total_tokens": usage["total_tokens"],
"cache_enabled": snapshot["cache"]["enabled"],
"retrieval_enabled": snapshot["retrieval"]["enabled"]
}
file_exists = False
try:
with open(path, "r", encoding="utf-8"):
file_exists = True
except FileNotFoundError:
pass
with open(path, "a", encoding="utf-8", newline="") as file:
writer = csv.DictWriter(file, fieldnames=list(row.keys()))
if not file_exists:
writer.writeheader()
writer.writerow(row)
if __name__ == "__main__":
snapshot = json.loads(open("one_snapshot.json", encoding="utf-8").read())
response_body = json.loads(open("one_response.json", encoding="utf-8").read())
write_cost_record(snapshot, response_body)
成本记录最好不要只记录 total_tokens。
还应记录客户端和策略版本。
否则无法回答这些问题。
是 Cursor 调试消耗增加,还是 Dify 工作流消耗增加。
是模型切换导致输出变长,还是检索上下文变长。
是缓存没有命中,还是重试次数增加。
是个人测试造成峰值,还是生产任务真实增长。
调用策略快照可以让成本分析从“看总数”变成“看原因”。
十三、缓存示例:缓存键必须包含策略指纹
缓存是 AI 成本控制中常用的技术。
但 AI 缓存不能只用 prompt 文本作为 key。
因为同一个 prompt 在不同模型、不同知识库、不同参数、不同系统提示词下,结果可能完全不同。
更稳妥的做法,是把策略指纹加入缓存键。
import hashlib
import json
import time
CACHE = {}
def make_cache_key(snapshot: dict, messages: list[dict]) -> str:
cache_material = {
"messages": messages,
"model": snapshot["model"],
"retrieval": snapshot["retrieval"],
"tools": snapshot.get("tools", {}),
"snapshot_version": snapshot["snapshot_version"]
}
raw = json.dumps(cache_material, ensure_ascii=False, sort_keys=True)
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
def get_from_cache(key: str):
item = CACHE.get(key)
if not item:
return None
if item["expires_at"] < time.time():
del CACHE[key]
return None
return item["value"]
def set_cache(key: str, value, ttl_seconds: int):
CACHE[key] = {
"value": value,
"expires_at": time.time() + ttl_seconds
}
缓存命中也应写入快照关联结果。
如果某次回答异常来自旧缓存,而不是模型实时输出,排错路径完全不同。
对于内容团队来说,缓存还涉及内容时效性。
对于企业知识库来说,缓存还涉及权限边界。
对于开发者工具来说,缓存还可能影响代码建议的准确性。
因此,缓存不是简单的性能优化。
它是调用策略的一部分。
十四、Dify 接入排错:先看策略,再看模型
Dify 的优势在于工作流编排和模型供应商配置。
但团队使用 Dify 时,常见问题并不总是来自模型本身。
常见问题包括 Base URL 少写 /v1。
模型名称与供应商配置不一致。
工作流节点使用了不同模型。
知识库检索范围与预期不一致。
变量传递导致上下文被截断。
重试和超时设置与网关策略冲突。
如果引入调用策略快照,排查顺序可以更清晰。
第一步,确认 Dify 工作区实际使用的供应商配置。
第二步,确认 Base URL 是否为 OpenAI 兼容路径。
第三步,确认模型名是否与后端网关允许的模型别名一致。
第四步,确认工作流节点是否覆盖了全局模型配置。
第五步,确认知识库节点的 top_k、score_threshold 和索引版本。
第六步,确认是否启用了缓存或历史对话记忆。
第七步,确认错误发生在 Dify 节点、API 网关、模型服务还是检索服务。
可以为 Dify 请求增加一个客户端标识。
X-Client-Name: dify
X-Workflow-Id: workflow_daily_summary
X-Policy-Snapshot-Version: 2026-06-14.v1
这样后端看到请求时,就能根据 Dify 专属策略生成快照。
当内容团队反馈“今天生成风格变了”时,技术团队可以比较快照,而不是翻找每个节点配置。
十五、Cursor 接入排错:IDE 场景要控制上下文和流式输出
Cursor 这类 IDE 工具的 AI 调用,通常更依赖当前文件、项目上下文和流式响应。
它的排错重点与 Dify 不完全相同。
Cursor 场景常见问题包括上下文过长、流式输出中断、模型名不可识别、代理路径错误、API Key 权限不足和团队成员配置不一致。
对于 IDE 场景,策略快照应特别记录这些字段。
{
"client": {
"name": "cursor",
"project": "backend-service",
"mode": "code-assistant"
},
"context": {
"source": "selected_files",
"file_count": 8,
"estimated_context_tokens": 18000
},
"model": {
"alias": "coding_assistant",
"stream": true,
"max_tokens": 1800
},
"failure_policy": {
"on_stream_interrupt": "retry_without_stream",
"on_context_overflow": "reduce_file_context",
"on_auth_error": "stop"
}
}
在 IDE 场景中,不建议让每个开发者随意改模型名和 Base URL。
更稳妥的方式,是给团队提供一份统一配置。
开发者可以选择任务类型。
后端根据任务类型决定模型、参数和上下文上限。
这样既能减少接入错误,也能减少成本失控。
十六、Chatbox 与 Cherry Studio:个人客户端也需要团队边界
Chatbox、Cherry Studio 这类客户端适合个人调试、多模型体验和轻量工作流。
但当它们进入团队场景时,也需要边界。
不能因为客户端轻量,就允许它绕过统一策略。
个人客户端常见风险包括 API Key 分散保存、模型列表不一致、Base URL 混用、历史上下文过长、敏感内容误发和费用无法归属。
策略快照可以为个人客户端设置较窄权限。
例如:
clients:
cherry_studio:
provider: vector_engine
model_alias: manual_debug
stream: true
max_tokens: 1000
retrieval_enabled: false
tools_enabled: false
cost_owner: personal-debug
max_retries: 0
allow_sensitive_context: false
chatbox:
provider: vector_engine
model_alias: manual_debug
stream: true
max_tokens: 1200
retrieval_enabled: false
tools_enabled: false
cost_owner: personal-debug
max_retries: 0
allow_sensitive_context: false
这种配置不是限制使用。
它是在区分生产工作流和个人调试。
个人客户端适合验证 prompt、检查模型输出、快速测试接口。
但它不应默认拥有生产知识库、外部工具写权限和高预算策略。
十七、模型迁移时,先迁移策略,再迁移流量
很多团队迁移模型时,只改模型名。
这会带来隐性风险。
因为模型迁移通常牵涉上下文长度、输出风格、工具调用格式、拒答边界、流式行为、token 计费方式和错误返回结构。
更稳妥的迁移流程应包括四步。
第一步,冻结当前生产策略快照。
第二步,用候选模型复制同一组策略快照。
第三步,对比结果差异、错误差异、耗时差异和成本差异。
第四步,逐步切换客户端或工作流,而不是一次性切换全部入口。
迁移对比可以采用以下结构。
{
"migration_test": {
"source_policy": "policy_2026_06_14_prod_v1",
"candidate_policy": "policy_2026_06_14_candidate_v1",
"same_messages": true,
"same_retrieval_index": true,
"same_cache_policy": false,
"same_tool_policy": true
},
"comparison": {
"quality_review_required": true,
"cost_compare_required": true,
"latency_compare_required": true,
"error_compare_required": true
}
}
这里有一个细节。
迁移测试时,缓存策略最好显式声明。
如果候选模型复用了旧模型缓存,测试结果没有意义。
如果旧模型命中缓存而新模型实时调用,成本和延迟对比也会失真。
因此,模型迁移不能只比较模型。
必须比较策略。
十八、企业 AI 接入:策略快照是审计基础
企业场景中,AI 接入通常涉及权限、数据、成本和责任归属。
策略快照可以帮助企业回答以下问题。
谁发起了调用。
来自哪个系统。
调用了哪个模型。
使用了哪个 Base URL。
是否使用了知识库。
知识库版本是什么。
是否调用了工具。
工具是否可能产生外部副作用。
是否启用了缓存。
缓存是否跨用户复用。
这次调用属于哪个预算。
失败后是否重试。
是否进入人工复核。
这些问题与单次回答质量无关。
但它们与企业治理直接相关。
如果团队未来需要审查一次输出,不能只看最终文本。
还要看当时的策略。
如果团队未来需要分析一次成本异常,不能只看账单。
还要看调用来源和策略变化。
如果团队未来需要定位一次数据风险,不能只看 prompt。
还要看检索片段、工具输出和缓存边界。
十九、内容团队:重点关注来源、版本和复用边界
内容团队使用 AI 的重点不是模型参数本身。
而是内容依据、风格一致性、时效性和复用边界。
内容团队的策略快照应特别关注这些字段。
选题来源。
参考资料版本。
是否联网或检索。
知识库索引版本。
是否使用历史模板。
是否复用缓存。
是否启用人工复核。
输出用途。
当内容团队反馈“今天文章不像之前的风格”时,快照可以帮助判断原因。
可能是系统提示词改了。
可能是模型别名切换了。
可能是参考来源减少了。
可能是缓存失效了。
可能是温度参数变了。
可能是 Dify 工作流节点被修改了。
没有快照,这些问题只能靠人工回忆。
有快照,团队可以对比两个时间点的策略差异。
二十、个人开发者:用快照减少无效排错
个人开发者也需要调用策略快照。
只是粒度可以更轻。
最小记录可以包含:
时间。
Base URL。
endpoint。
模型名。
temperature。
max_tokens。
是否 stream。
请求摘要。
状态码。
错误分类。
耗时。
token 用量。
这份记录可以帮助个人开发者避免重复排错。
尤其是在自建脚本、Cursor、Chatbox、Cherry Studio 同时使用时,很容易忘记某个工具使用了旧配置。
轻量快照可以写成 JSONL。
每次调用追加一行。
当问题出现时,先看最近几次策略变化。
这比重新猜测配置更有效。
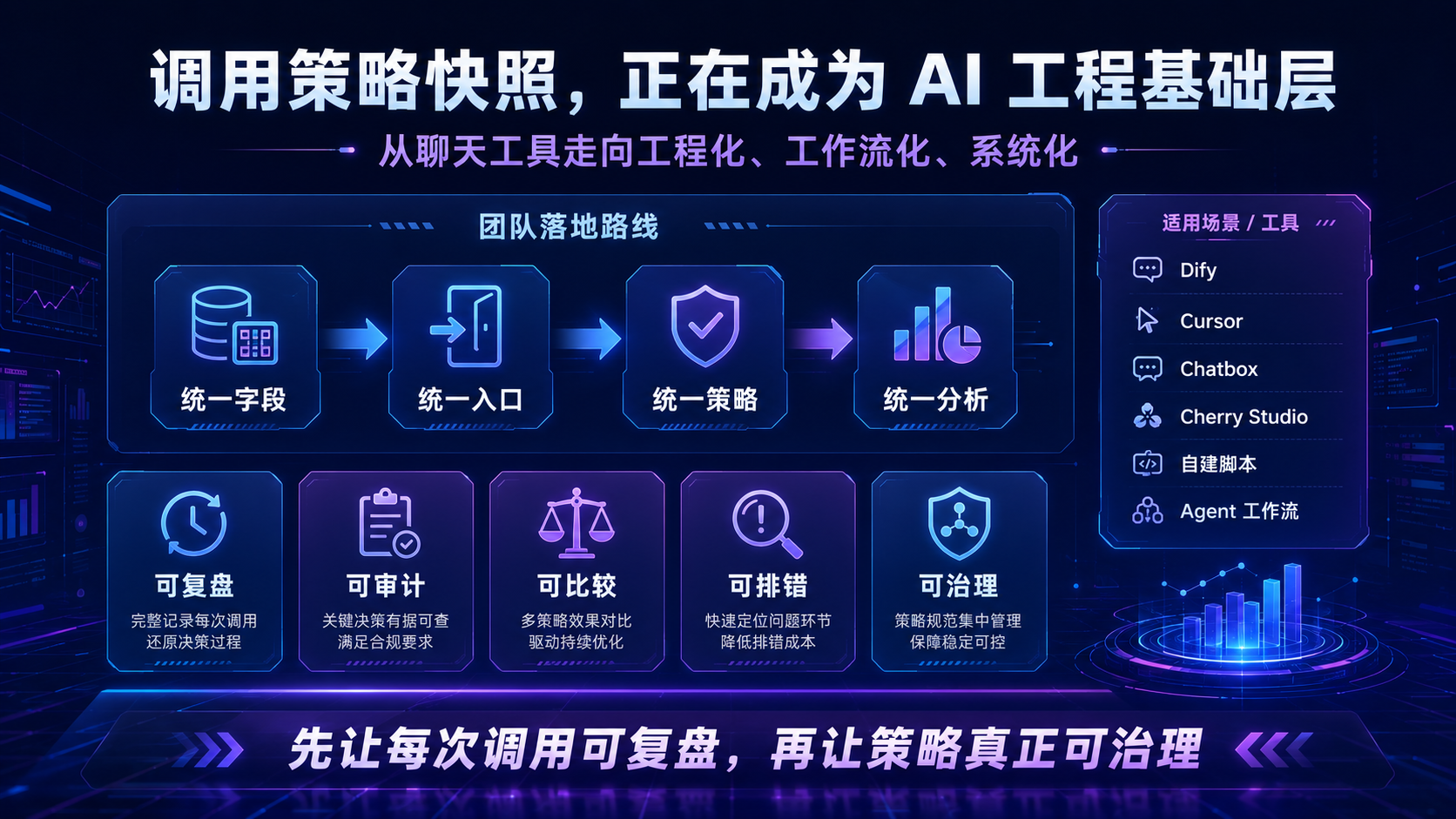
二十一、团队落地路线:不要一开始就做大平台
调用策略快照不需要一开始就建设复杂平台。
可以按四个阶段落地。
第一阶段,统一字段。
先定义最小快照字段。
确保所有客户端和脚本都能记录 request_id、client、base_url、model、参数、状态码和错误分类。
第二阶段,统一入口。
把 Dify、Cursor、Chatbox、Cherry Studio 和自建脚本尽量接入统一 OpenAI 兼容入口。
入口统一后,策略记录才容易集中。
第三阶段,统一策略。
把模型别名、客户端权限、检索配置、缓存配置和成本归属放入统一配置文件。
客户端只声明任务类型。
后端决定实际策略。
第四阶段,统一分析。
把快照写入日志系统、数据库或对象存储。
支持按客户端、模型、错误类型、成本归属和策略版本查询。
这个路线的重点是渐进。
先让每次调用可复盘。
再让策略可治理。
最后再做自动化分析。
二十二、常见错误与排查思路
错误一:Base URL 写成根域名,客户端又自动拼接路径
有些客户端要求填写 /v1 级别的 Base URL。
有些客户端要求填写根域名。
有些客户端会自动拼接 /chat/completions。
如果填写规则不匹配,就可能出现 404 或路径重复。
排查时先看策略快照中的 base_url 和 endpoint。
再看客户端实际发出的完整 URL。
错误二:模型别名和真实模型名混用
团队内部常用 model_alias 管理模型。
但客户端可能要求填写真实模型名。
如果别名没有在后端解析,就会出现 model not found。
排查时应确认快照中同时记录 alias 和 name。
错误三:Dify 工作流节点覆盖了全局模型配置
Dify 工作流中,不同节点可能使用不同模型或参数。
如果只检查供应商配置,可能看不到节点级覆盖。
排查时应把 workflow_id、node_id 和节点策略写入快照。
错误四:Cursor 上下文过长导致失败
IDE 场景容易把多个文件、历史对话和当前问题一起送入模型。
上下文过长可能导致请求失败或输出质量下降。
排查时应记录 estimated_context_tokens 和 file_count。
错误五:缓存键没有包含检索版本
如果缓存键只包含 prompt,知识库更新后仍可能返回旧答案。
排查时应确认缓存键是否包含 index_version。
错误六:重试策略导致成本放大
一次失败请求如果被客户端、网关和业务层同时重试,实际调用次数可能超过预期。
排查时应记录 max_retries 和 retry_source。
错误七:流式输出中断被误判为模型失败
流式输出中断可能来自网络、客户端解析、代理超时或上游服务。
排查时应记录 stream=true、首 token 延迟、连接关闭原因和是否支持非流式降级。
二十三、策略快照与安全治理
AI 安全治理不应只放在输入过滤和输出审核。
更基础的是调用策略本身。
哪些客户端可以使用企业知识库。
哪些任务可以调用外部工具。
哪些模型可以处理内部文档。
哪些缓存可以跨用户复用。
哪些调用必须进入人工复核。
哪些错误不能自动重试。
这些规则都应体现在策略快照中。
例如,涉及客户资料的请求可以要求:
不允许跨用户缓存。
不允许发送到个人调试客户端。
不允许调用外部写工具。
必须记录数据分类标签。
必须限制检索范围。
必须设置较短日志保留周期。
这些规则不是为了增加复杂度。
它们是为了让 AI 系统在进入真实业务后仍然可控。
二十四、策略快照与 Agent 工具调用
Agent 系统中的工具调用尤其需要快照。
因为工具调用可能产生外部影响。
它可能创建工单。
可能发送邮件。
可能更新数据库。
可能查询内部系统。
可能触发自动化任务。
对于工具调用,快照至少应记录:
工具名称。
工具版本。
工具参数摘要。
调用前权限检查结果。
是否需要人工批准。
工具超时时间。
工具失败处理方式。
工具输出是否进入下一轮模型上下文。
如果工具输出会进入下一轮上下文,还应记录输出摘要和脱敏状态。
这能避免一个常见问题。
模型第一步调用工具。
工具返回了不完整或错误结果。
第二步模型基于错误结果继续生成。
最终用户只看到错误答案,却不知道错误来自工具,而不是模型。
工具策略快照可以把这条链路拆开。
二十五、策略快照与向量检索
向量检索在 AI 应用中越来越常见。
但检索失败经常被误判为模型失败。
如果模型没有拿到正确上下文,它很难回答正确。
因此,检索策略必须进入快照。
需要记录的字段包括:
索引名称。
索引版本。
embedding 模型。
top_k。
score_threshold。
过滤条件。
命中文档数量。
命中文档版本。
是否启用重排。
检索为空后的处理方式。
当回答质量下降时,团队可以先看检索策略。
如果检索命中为空,问题可能在索引、切片、embedding 或过滤条件。
如果检索命中文档过多,问题可能在 top_k 或重排。
如果检索命中旧文档,问题可能在索引版本或缓存。
如果检索命中文档正确但回答错误,再进入模型侧分析。
二十六、策略快照不是为了追责,而是为了降低协作成本
很多团队对治理工具有天然抵触。
因为治理常被误解为审批和限制。
但调用策略快照的核心目的不是追责。
它的目的是降低协作成本。
开发者不用反复问“你当时怎么配的”。
内容团队不用反复截图每个节点。
运维不用只凭状态码猜测问题。
管理者不用等账单出来才知道成本异常。
安全团队不用在事后才寻找数据边界。
当 AI 系统变复杂,团队需要共同语言。
调用策略快照就是这种共同语言。
它把“我觉得模型变了”变成“策略版本从 v1 切到了 v2”。
它把“接口好像坏了”变成“Cursor 客户端命中了 404,完整路径拼接异常”。
它把“费用突然高了”变成“Dify 工作流从一次重试变成三次重试,缓存命中率下降”。
这种表达方式更适合工程协作。
二十七、结语:AI 从聊天工具进入系统化阶段
AI 应用的早期阶段,重点是能不能调通模型。
随后,重点变成能不能接入更多客户端和工作流。
现在,新的重点正在出现。
团队需要知道每一次调用为什么发生、如何发生、由谁承担成本、依赖哪些上下文、允许哪些工具、失败后如何处理。
这就是 AI 从聊天工具进入工程化、工作流化、系统化阶段的标志。
OpenAI、Google、Anthropic、Microsoft、Apple、DeepSeek、Dify 和向量检索生态的发展,都在推动同一个方向。
模型能力会继续变化。
接口形态会继续演进。
客户端入口会继续增多。
Agent 工具链会继续变长。
在这种环境中,真正稳定的不是某一个固定配置。
而是团队对调用策略的记录、审查、复盘和演进能力。
调用策略快照不是宏大的平台概念。
它可以从一份 JSON 开始。
可以从一个请求头开始。
可以从一条 JSONL 日志开始。
但只要它被坚持下来,AI API、AI Agent、OpenAI 兼容接口、Dify、Cursor、Chatbox、Cherry Studio、企业知识库和自建脚本就不再是分散的配置孤岛。
它们会进入同一套可复盘、可迁移、可排错、可控成本的工程体系。
这才是今天 AI 接入最值得关注的变化。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)