Vibe Coding|为什么不推荐新手折腾 Codex + DeepSeek?
为什么我不推荐新手折腾 Codex + DeepSeek?
这两天不少朋友问我:既然 DeepSeek API 价格低、上下文长、还支持 Tool Calls,那能不能把 Codex 的后端换成 DeepSeek?
答案是:能折腾,而且已经有人在折腾。
但如果你是新手,我不建议把 Codex + DeepSeek 当成默认方案。
注意,我这里不是说 DeepSeek 不强,也不是说 Codex 只能用 OpenAI 原生模型。恰恰相反,DeepSeek 的性价比、长上下文和开放生态都很有吸引力;Codex 作为 coding agent,也确实支持通过 custom model provider、proxy、bridge 等方式接入不同模型。
问题在于:“能接上”不等于“适合新手长期稳定使用”。
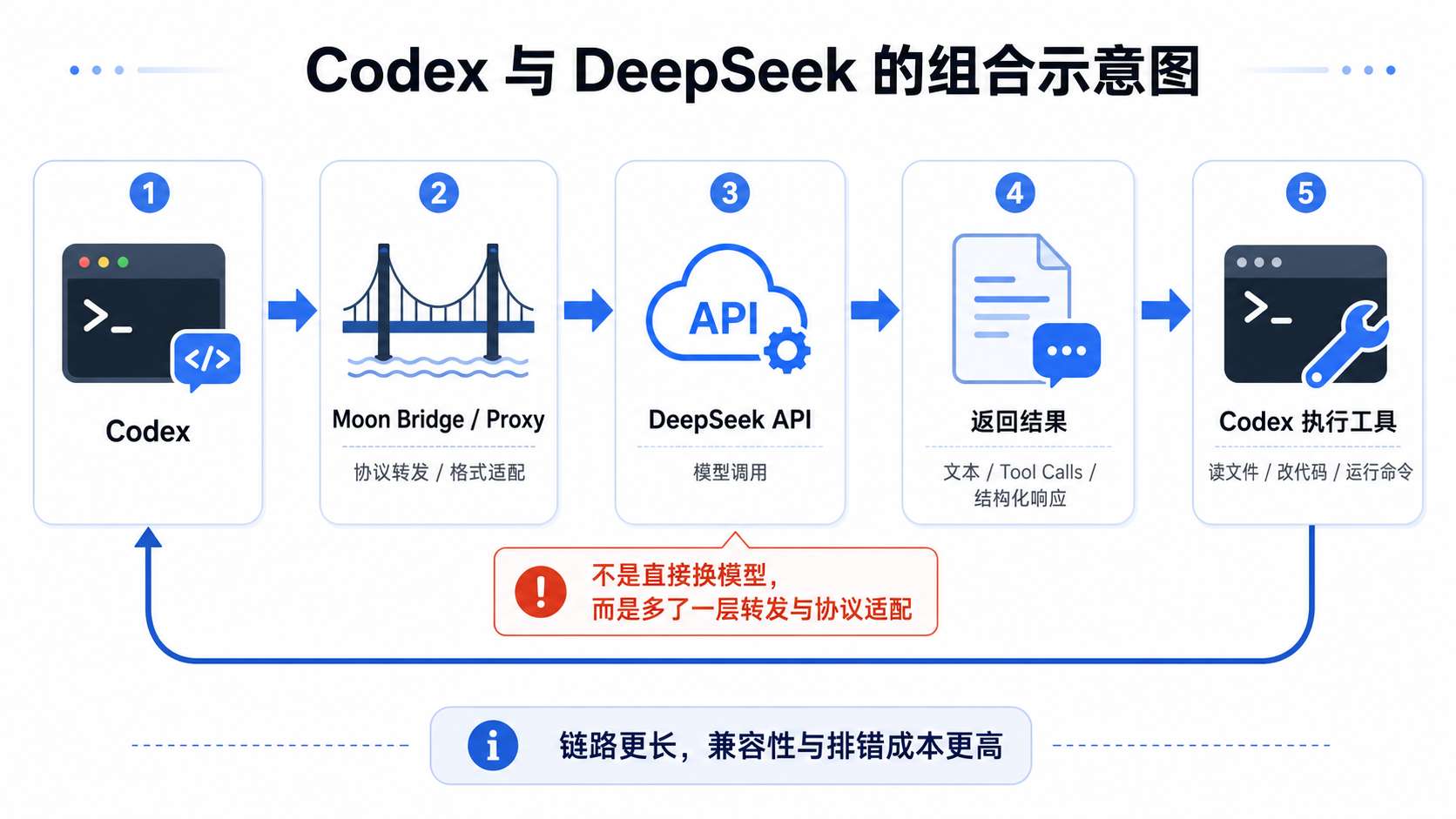
先说结论:不是不能用,而是不适合新手默认用
如果你已经熟悉 API、命令行、配置文件、代理服务和日志排错,那么 Codex + DeepSeek 是一个很值得研究的方向。它可以降低 token cost,也能测试 DeepSeek 在真实 coding agent 场景里的表现。
但如果你刚开始用 Codex,甚至还不熟悉 config.toml、sandbox、approvals、tool calls 是什么,我建议先不要上来就改后端。
对新手来说,稳定性、兼容性和排错成本,往往比 token 单价更重要。
原因很简单:你用 coding agent,不是为了研究 API 协议,而是为了让它帮你读代码、改代码、跑测试、定位 bug、生成文档。如果工具链本身经常出问题,省下来的 token 钱很快会被时间成本吃掉。
Codex 的核心价值不是“换个模型写代码”
很多人理解 Codex 时,会把它看成“一个在终端里的聊天机器人”。这个理解不够准确。
Codex 更接近一个 coding agent。所谓 coding agent,不只是回答问题,而是能在你的项目目录里读取文件、修改代码、运行命令、查看测试结果,并根据结果继续下一步。
Codex 的价值,不只是模型会写代码,而是它有一整套工作流:
- 能理解当前项目结构
- 能读写本地文件
- 能调用 shell 命令
- 能根据测试输出继续修复
- 能在 sandbox 和 approvals 限制下工作
- 能维护任务上下文和执行记录
官方 Codex CLI 页面也明确强调,Codex 可以在选定目录中读取、修改并运行代码。也就是说,它不是普通 chat completion,而是一个带工具执行能力的开发代理。

所以,替换 Codex 后端模型,不只是“把 GPT 换成 DeepSeek”。你实际上是在改变 agent 工作流的底层推理与工具调用链路。
DeepSeek 参数很好,但 agent 兼容性不是只看模型能力
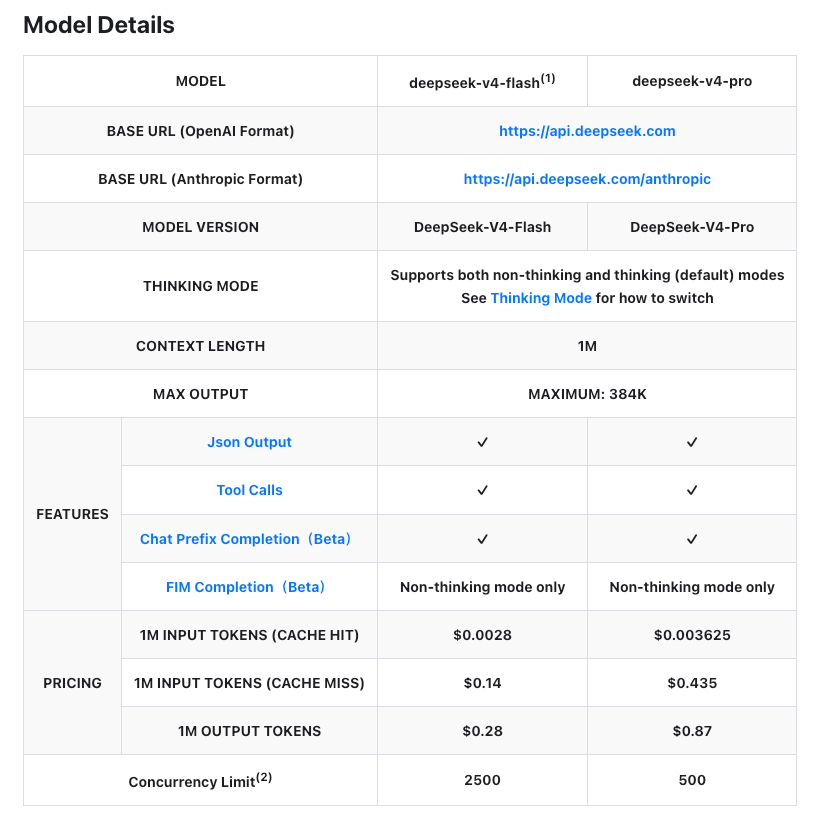
DeepSeek API 的吸引力很明显:价格低、上下文长、OpenAI/Anthropic API compatibility 做得不错,官方文档里也列出了模型、价格、1M context length、Tool Calls、JSON Output、Context Caching 等能力。
这些参数对开发者很有诱惑力。特别是 token cost,确实是很多人想折腾的直接原因。对于长代码库、长日志、长文档分析来说,context length 也很重要。
但是,agent 兼容性不是参数表能完全说明的。
一个模型在聊天里表现很好,不代表它在 Codex 工作流里一定稳定。Codex 需要模型持续理解工具调用格式、文件修改意图、命令执行反馈、错误恢复路径和多轮任务状态。这里考验的是“模型能力 + API 适配 + 中间层转换 + Codex 自身预期”的组合稳定性。
DeepSeek 性价比很高,但不等于适合作为 Codex 的新手默认后端。
Tool Calls 支持,不等于 Codex 工作流稳定
DeepSeek 官方文档已经支持 Tool Calls。Tool Calls 的意思是:模型可以按照约定格式提出“我要调用某个工具”,比如查询天气、运行函数、检索资料,随后由外部程序真正执行工具,再把结果返回给模型。
这对 agent 非常关键。没有 tool calls,模型只能“说”;有了 tool calls,模型才可能参与“做”。

但这里有一个新手最容易忽略的问题:支持 Tool Calls,不等于能完整复刻 Codex 原生模型在所有工具场景下的行为。
原因包括:
- Codex 使用的可能是 Responses API 语义,不只是普通 Chat Completions。
- 工具调用格式、流式输出、reasoning 信息、错误恢复方式可能需要转换。
- 模型是否稳定遵循工具协议,需要真实项目压力测试。
- 中间层是否完整处理 edge cases,决定体验是否可靠。
也就是说,DeepSeek 文档里写了 Tool Calls 支持,这是好事;但 Codex 能不能稳定地用它跑复杂任务,是另一件事。
Moon Bridge 这类方案更适合玩家,不适合小白
目前比较常见的做法,是用 Moon Bridge、codex-bridge 或类似 proxy / bridge 工具做转发。所谓 bridge,就是桥接层:Codex 这边按它熟悉的协议发请求,bridge 接住请求,再转换成 DeepSeek 能理解的 API 格式,最后把结果转回给 Codex。
DeepSeek 的 awesome-deepseek-agent 仓库里已经有 Codex 接入指南,里面就提到 Codex 通过 OpenAI Responses API 与模型通信,因此需要一个 forwarding layer,示例使用 Moon Bridge。
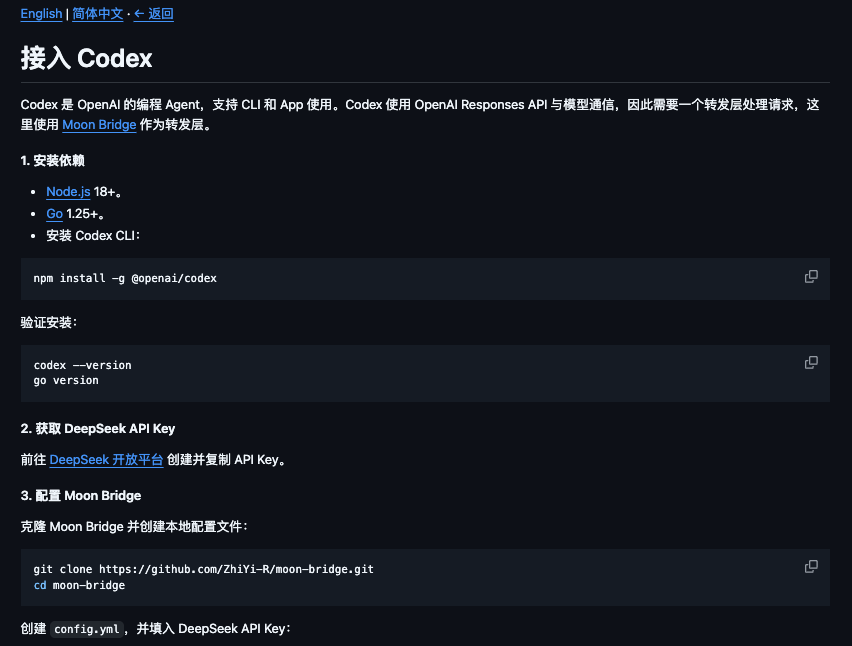
- Link:https://github.com/deepseek-ai/awesome-deepseek-agent/blob/main/docs/codex.zh-CN.md
这种方案对技术玩家很友好,因为它开放、透明、可控,也能学习很多 agent 协议知识。但对小白来说,问题也很明显:
- 你要安装 Node.js、Go、Codex CLI、Moon Bridge。
- 你要维护
config.yml、config.toml、models_catalog.json。 - 你要理解 base_url、wire_api、model_provider、API key。
- 你要知道服务监听在哪个端口。
- 出错时,你要看 Codex 日志、bridge 日志、DeepSeek API 错误码。
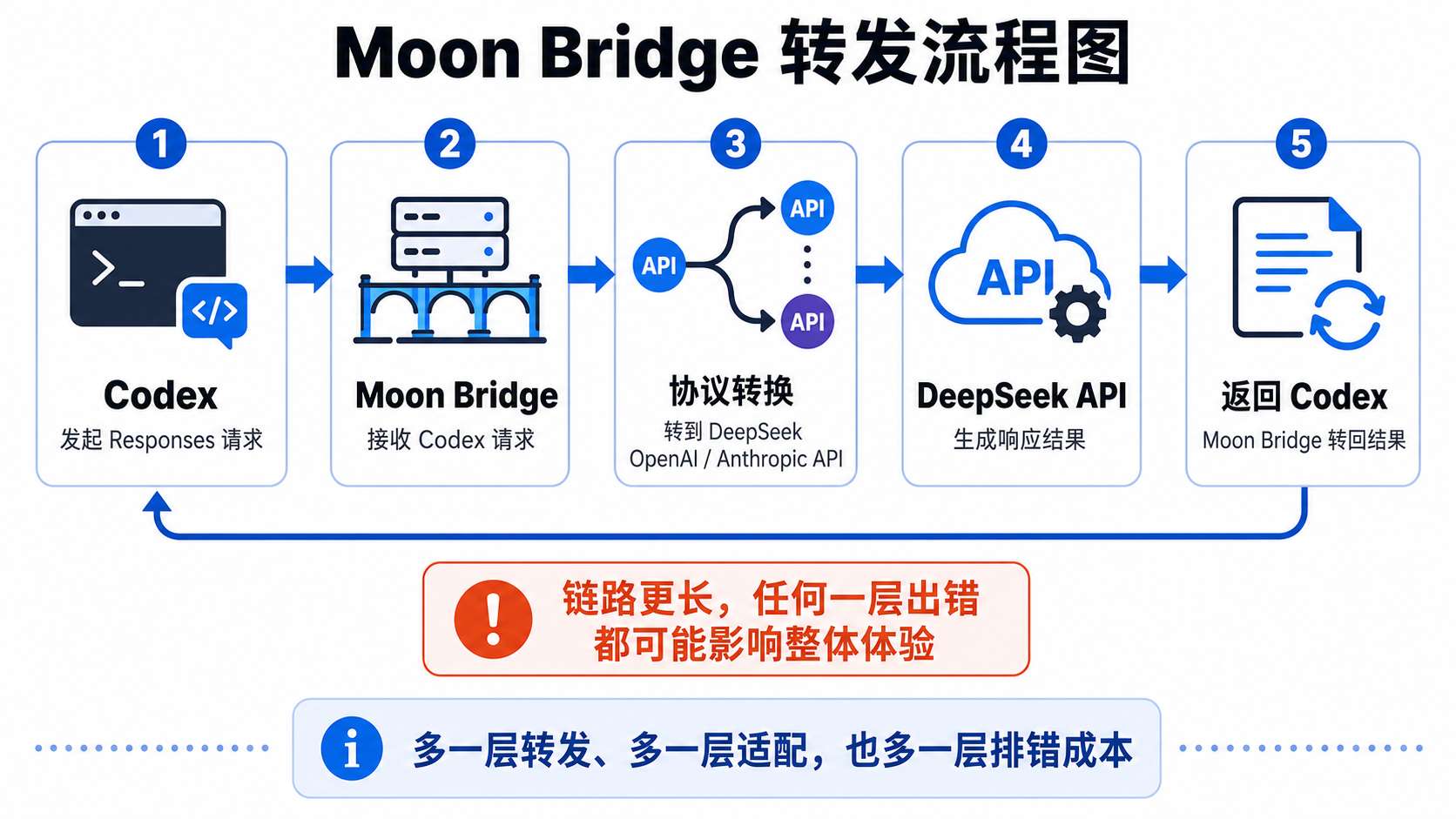
新手最大的问题不是接不上,而是接上以后不知道坏在哪里。
省下的 token 钱,可能会变成配置成本和排错成本
DeepSeek 的 token cost 确实很有竞争力。官方 Models & Pricing 页面还提醒,费用会根据 input tokens、output tokens、cache hit、cache miss 等计算,并建议用户定期查看最新价格。
Context Caching 也很有价值。它的基本思路是:如果多次请求有重复前缀,重复部分可以命中缓存,降低输入成本。对 agent 来说,系统提示、工具定义、项目上下文经常重复,理论上很适合缓存。

但是,新手要算的是总成本,不只是 API 成本。
| 成本类型 | 看得见的成本 | 容易被忽略的成本 |
|---|---|---|
| API 费用 | token 单价、缓存命中价格 | 失败重试、错误请求、长上下文浪费 |
| 配置成本 | 安装和改配置文件 | 版本变化、文档更新、配置迁移 |
| 排错成本 | 错误码、连接失败 | 协议不兼容、工具调用异常、模型行为漂移 |
| 安全成本 | API key 管理 | 项目代码经过更多链路 |
如果你每周只用几次 Codex,省下的 token 钱,可能还不够抵消一次排错的时间。
原生 Codex vs Codex + DeepSeek:核心对比
| 维度 | 原生 Codex 方案 | Codex + DeepSeek 方案 |
|---|---|---|
| 配置难度 | 低 | 高 |
| 新手友好度 | 高 | 低 |
| 成本 | 相对高 | 相对低 |
| 稳定性 | 更可控 | 依赖中间层 |
| 工具调用兼容 | 更好 | 需要验证 |
| 安全边界 | 更清晰 | 数据流更复杂 |
| 适合人群 | 新手、项目交付 | 技术玩家、低成本实验 |

哪些人适合尝试 Codex + DeepSeek?
我认为下面这些人可以尝试:
- 已经熟悉 Codex CLI,并且知道如何恢复默认配置。
- 会看 API 文档,能理解 OpenAI/Anthropic API compatibility。
- 会读日志,知道 401、402、429、500 大概意味着什么。
- 能接受 bridge 层偶尔出问题,并愿意自己排查。
- 项目不是高度敏感代码,或者已经做了脱敏和隔离。
- 目标是学习 agent 协议、多模型接入、低成本实验,而不是赶交付。
对这类用户来说,Codex + DeepSeek 很有价值。你可以比较不同模型在真实项目中的表现,也可以研究 tool calls、context length、cache hit、token cost 的关系。
如果你把它当实验平台,它很好玩;如果你把它当新手生产力默认入口,它就不一定合适。
哪些人不推荐尝试?
下面这些情况,我不建议一开始就折腾:
- 你刚装 Codex,还没跑通过原生流程。
- 你不熟悉命令行和环境变量。
- 你不知道
config.toml改坏了怎么恢复。 - 你不理解 sandbox 和 approvals 的区别。
- 你在做客户项目、公司代码、未公开科研代码。
- 你希望工具“开箱即用”,不想看日志和文档。
- 你需要稳定交付,而不是研究多模型接入。
尤其是科研人员和非专业开发者,我更建议先用原生 Codex 跑通真实任务:让它读一篇论文项目、整理代码结构、写分析脚本、跑测试、生成 README。等你知道 Codex 正常工作时应该是什么样,再去判断 DeepSeek 接入后到底是模型问题、配置问题,还是 bridge 问题。
我的建议:先跑通原生 Codex,再折腾多模型接入
如果你想稳一点,我建议按这个顺序来:
第一步:先用原生 Codex 完成一个小任务
比如让 Codex 修一个 bug、写一个脚本、重构一个函数、补一组测试。重点不是任务多复杂,而是你要熟悉 Codex 的基本节奏:它如何读文件、如何计划、如何修改、如何运行命令、如何请求 approval。
第二步:理解 sandbox 和 approvals
sandbox 是技术边界,决定 Codex 能访问哪里、能不能联网、能不能写文件。approvals 是审批策略,决定 Codex 什么时候必须停下来问你。
这两个概念非常重要。你可以把它们理解为 agent 的“安全护栏”。新手不要一上来就用 full access 或 bypass approvals。
第三步:再看 custom model provider
等你理解 Codex 原生流程后,再去看 advanced configuration 和 custom model provider。你需要知道 base_url、env_key、wire_api、model_provider 分别是什么。
第四步:最后再尝试 Moon Bridge
如果你确实要接 DeepSeek,再使用 Moon Bridge 或类似 bridge 工具。建议新建一个测试项目,不要拿公司主项目直接试。API key 单独管理,配置文件不要提交到 Git。
先跑通原生 Codex,再折腾多模型接入,这是我给新手最重要的建议。
总结:不是模型不强,而是链路太长
Codex + DeepSeek 这套组合,本质上不是一个“错误方案”,而是一个“高级玩法”。
DeepSeek 的模型能力、价格、context length、context caching、tool calls 都很有吸引力。Codex 的 custom model provider 和配置能力,也给了开发者很大空间。Moon Bridge 这类项目则把两者连接起来,让更多人能探索低成本 agent 工作流。
但从新手视角看,这条链路太长了:
Codex 要稳定,bridge 要稳定,DeepSeek API 要稳定,协议转换要稳定,tool calls 要稳定,sandbox 和 approvals 还要配置正确。任何一环出问题,新手都可能不知道该查哪里。
所以我的观点很明确:
Codex + DeepSeek 可以折腾,但不适合作为新手默认方案。
如果你是技术玩家,可以研究;如果你是新手,先用原生 Codex;如果你在做客户项目、公司代码、未公开科研代码,不要随便接第三方模型和代理层。
最后送一句适合做封面副标题的话:
不是模型不强,而是组合链路太长;不是不能折腾,而是不适合新手默认用。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)