从零开始搭建深度学习大厦系列-4.Transformer生成式大语言模型
最近在学习文本预处理(分词与词和位置嵌入)、自注意力机制(Self-Attention)、多头自注意力机制、Transformer Block和GPT-2、GPT-3的基本架构。
本文是相关内容的第一篇文章,主要讲解大模型的基础架构和代码构建过程;后续文章将着重讲解大模型的预训练、指令微调、奖励模型构建和强化学习(RLHF)过程。
相关源代码完全可运行,并按照构建分步-代码分块的流程设计,完整代码已经上传个人空间,可以免费下载调试,代码运行环境为配备了Python 3.10虚拟环境的Trae CN(字节跳动开发的国内AI代码编写助手)。
说明:
(1)在本文的讲解和分析过程中,只会贴出关键的代码部分;
(2)对于代码实现部分的很多细节,如有疑问或见解可以直接在评论区讨论。
目录
Masked multi-head attention多头注意力模块(nn库实现,Dropout随机丢弃层内嵌)
Masked multi-head attention(手编实现)
一、文本预处理
文本预处理是把语句拆分成词,而后把词的语义空间唯一映射到数学表达的向量空间的过程(附:在线性代数中,即同时满足单射和满射),总体包括分词和词(位置)嵌入两步。
1.1 分词与词嵌入
英文分词可以使用Re内置库,通过正则表达式对输入语句字符串进行过滤,因此词与词之间必须要有空格作为划分;中文分词可以使用第三方jieba库,输入语句不需要有空格也符合中文语句书写习惯。

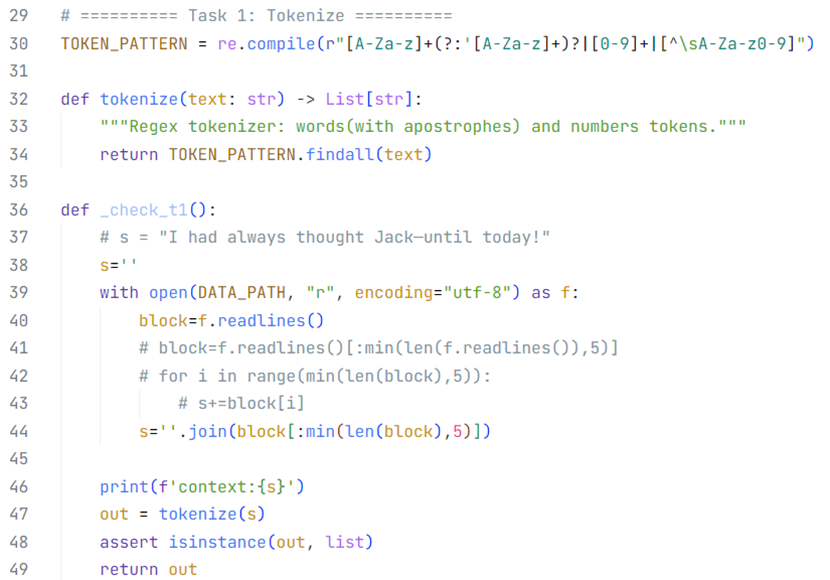
图 1 使用re库进行英文分词

图 2 使用jieba库进行中文分词
分词之后进行一个空间映射,注意这个映射关系是可以进行训练的,但是训练周期比较长,现在工程一般延用训练好的大模型的嵌入数据,如果是体验流程不追求优质效果可以使用torch.randn()进行0-1随机高斯初始化。
词嵌入矩阵的行数对应词汇表的容量,GPT-2词汇表大小50257;列数对应词嵌入向量维度。
更好、更集成统一的选择是使用GPT-2的Bytes-Pair Encoding(BPE)库,这个库除了使用映射固定的标准的分词机制外,还可以针对不在GPT-2 50257个单词构成的词库中的单词进行进一步可能的拆分,当然更简单粗暴的解决方案是设置一个类似<|endoftext|>的标识符比如<|unknown|>。

![]()
![]()
比如输入的sunlit(阳光明媚的)、terrace(梯田)、someunknownPlace(未知地点)并不在
词库中,BPE进行词语拆分之后得到sun、lit、terr、aces、some、unknown、Place。英文逗号对应的索引是11。
后面也会说到的nn.Embedding网络层设置参数里的padding_idx对应一个固定位置索引,这个索引可能一般在词库的0索引位置,训练的时候不会进行参数更新,相当于空占位字符。
1.2 位置嵌入
类似词嵌入,可以使用torch.randn()进行位置嵌入矩阵的随机初始化。同样可以被训练,矩阵的行数对应输入文本的令牌数或者词数,列数对应词嵌入的维度数,GPT2-small嵌入维度768维,本实验使用3维向量作为示例。

1.3 滑动窗口(对于训练和推理都尤为重要)
滑动窗口的设置直接决定大模型训练和推理的输入与输出关系。使用typing库进行类型约束,默认步长为1,也就是输出是输入整体右移一个单词之后在全局文本中的视野。

1.4 大语言模型(GPT为例)的输入与输出
在GPT的实现中,一般使用(B,T,V)表示输入的嵌入后向量尺寸,(B,T,D)表示输出的概率张量。B代表批量大小,T代表批量中最长的样本对应的词语数量(其他padding补齐),D代表词嵌入维度,V代表词汇表大小。
在经过文本预处理-丢弃层-N x Transformer Block-Final LayerNorm之后,数据尺寸仍然是(B,T,V),此时需要通过一个FC全连接层加上softmax处理得到(B,T,D)的概率预测矩阵。
二、自注意力机制
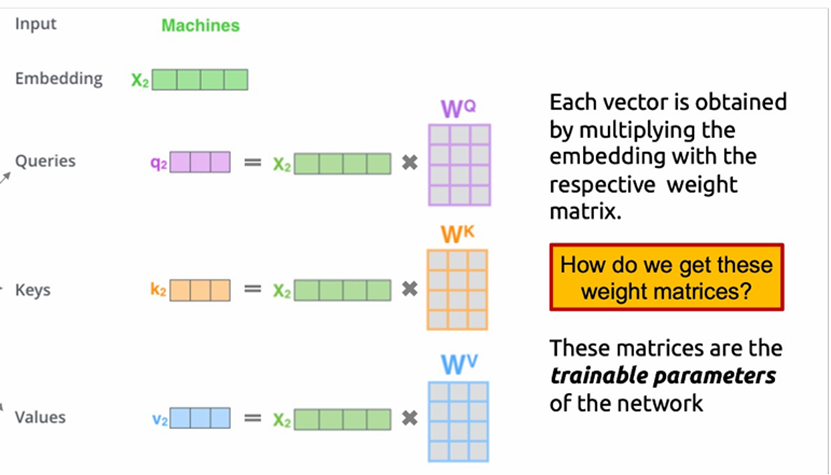
(单头)自注意力是Transformer Block的核心结构中的核心,关键就是Q、K、V——查询向量、键向量、值向量。通过Wq、Wk、Wv三个对应的矩阵和词嵌入向量做矩阵乘法(权重矩阵在右),得到同维度的向量,为了问题描述的简便性,这里假设批量维度B=1并不考虑这一维度;因此三维张量当作二维矩阵考虑。 对于这个输入矩阵的任意两两行向量(i,j)(对应每一个单词,T维度),QiKjT乘法后除以词嵌入维度的0.5次方(防止基于softmax函数特性的梯度消失现象,乘法结果的分布方差统计属性和词嵌入维度基本上是正相关的关系)得到查询结果,经过因果对角矩阵的掩膜和随机丢弃的掩膜处理(图4图5),再通过一层softmax转换为0-1的注意力分数。
不难发现注意力分数矩阵的尺寸是(B,T,T)。注意力分数越高,代表两个词的语义关联性越强。
实际过程中(比如在GPT2的架构内),多头掩膜自注意力模块和FF前馈网络模块的随机丢弃层一般不作使用,因为丢弃是为了防止过拟合,在数据集充足的情况下不会出现过拟合的问题。

图 3 注意力分数的可视化
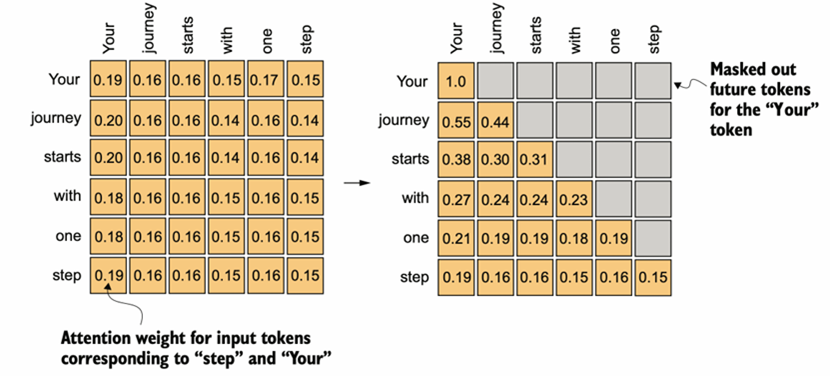
图 4 因果下三角矩阵掩膜处理,每个词语根据“实际语境”只和前面的文本有语义关系(Decoder-Only),BERT大模型是另一种思路(Encoder-Only)
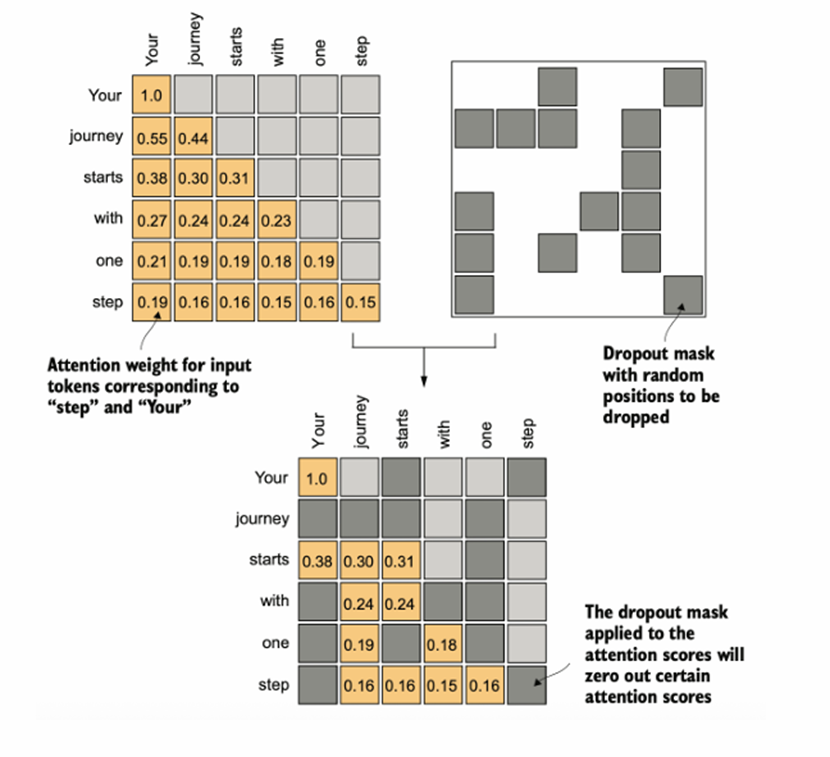
图 5 随机全局丢弃层处理
此时就只有V-值向量没有被使用,和值向量构成的矩阵(T,V)对批量中的每一个样本做乘法,得到(B,T,V)的输出。
说明:在代码实现过程中,torch.nn库也提供了MultiheadAttention网络模块,前向计算指定need_weights参数为False可以不返回注意力分数矩阵,减少内存开销。
三、多头自注意力机制
在自注意力机制的基础上,通过设置多个独立的自注意头,对应关注不同的语义空间,我的理解是有点类似现实中看待问题的不同角度,有的可能更关注客观理性,有的则可能关注感性和情绪;具体的权重动态占比下文会简略说明,学习到的结果主要就看数据集的性质,如果你给这个大模型喂的数据都是科研大佬或者理工男写的文章,那么总体来说这个大模型的输出就会比较理性,“理性语义空间”的注意头更胜一筹;反之亦然,但并没有绝对的好坏之分。
然而具体需要的头数和指代的语义空间并不明晰,这也是深度学习和神经网络被称为“黑匣子科学”的原因之一,不具备较强的可解释性。
多头自注意力的实现方式包括通过时间延长和循环的单头注意力叠加、多个注意头的并行计算(具体实现用到四维张量和torch.matmul并指定乘法运算的维度,但直接使用@矩阵运算符更为方便,默认对高维张量的最后两个维度做计算),一般使用后者,因为在GPU上训练和推理可以大大提升速度。
这里有一个很关键的机制——多头注意力融合,该过程发生在获得context vectors或者context matrix之后,而不是在获得N头的Attention Matrices之时。N头注意力按照单头注意力的流程之后理论上可以得到N个context matrices的输出,即(N,B,T,V)或者(B,N,T,V),此时后续步骤一致。
这里需要指出一个笔者之前犯过的误区:多头注意融合并不是N合1的降维简单融合,而是N到N的多语义空间共享式的融合。虽然名字听起来让人容易误会,但是仔细想一想,如果多头数目N这一维度被降维压缩了,那么终究还是只得到单一的语义空间。
所以多头融合矩阵本质是一个线性FC矩阵,尺寸(NV,NV)同样可以进行参数更新和训练。
代码编写的时候主要使用view函数、transpose函数、reshape函数来进行张量维度空间的操作。
四、Transformer Block基本架构
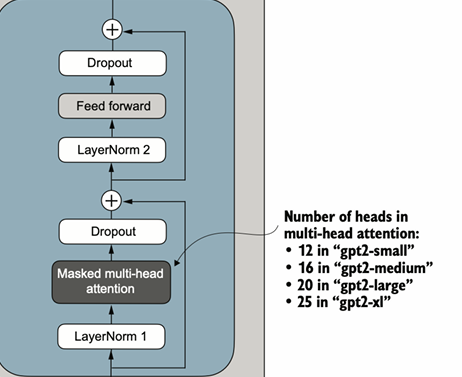
图 6 Transformer Block组成成分
一图以蔽之,所谓的Transformer Block主要有借鉴自何恺明等AI先辈提出的ResNet的Residual Block模块、随机丢弃模块、因果多头自注意力模块、FF前馈模块、LayerNorm层规范化模块这5大板块,只需要按顺序实现即可构建出完整的Transformer Block。
LayerNorm层规范化模块
# --- Implement LayerNorm from scratch ---
class LayerNorm(nn.Module):
def __init__(self, emb_dim: int):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(dim=-1, keepdim=True) #① compute mean per embedding dimension
var = x.var(dim=-1, keepdim=True, unbiased=False) # ② compute variance, biased var for GPT-compatibility
norm_x = (x - mean) / torch.sqrt(var + self.eps) # ③ normalize
return self.scale * norm_x + self.shift # ④ apply learnable γ (scale) and β (shift)
LayerNorm规范的是(B,T,V)中的最后一个维度——词嵌入维度。
Masked multi-head attention多头注意力模块(nn库实现,Dropout随机丢弃层内嵌)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, num_heads, dropout, qkv_bias=False):
super().__init__()
assert d_in == d_out, "fallback MHA assumes d_in == d_out"
self.embed_dim = d_in
self.attn = nn.MultiheadAttention(
embed_dim=d_in, num_heads=num_heads, dropout=dropout,
batch_first=True, bias=qkv_bias
)
def forward(self, x):
# x: (B,T,D)
B, T, D = x.shape
# causal mask: upper triangle = -inf (prevent attending to future)
attn_mask = torch.full((T, T), float("-inf"), device=x.device)
attn_mask = torch.triu(attn_mask, diagonal=1)
y, _ = self.attn(x, x, x, attn_mask=attn_mask, need_weights=False)
return yMasked multi-head attention(手编实现)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by n_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec上图是手编实现的多头注意力模块的前向计算(函数重载);注意是在softmax处理之后使用,选定位置的注意力分数置0,其余位置分数不做更改,总注意力分数的范数减小,因此不容易过拟合(不代表一定不会)。
Residual Block模块
# --- GELU activation (approximation used in GPT-2) ---
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class ExampleDeepNeuralNetwork(nn.Module):
def __init__(self, layer_sizes, use_shortcut: bool):
super().__init__()
self.use_shortcut = use_shortcut
assert(len(layer_sizes)>=6)
self.layers = nn.ModuleList([
nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]), GELU()),
nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5])),
nn.Softmax(dim=-1)
])
self.classes=layer_sizes[5]
def forward(self, x):
for layer in self.layers:
out = layer(x)
# Only add shortcut if dimensions match
if self.use_shortcut and x.shape == out.shape:
x = x + out
else:
x = out
return xFF前馈神经网络模块
# --- FeedForward sublayer used in Transformer blocks ---
class FeedForward(nn.Module):
def __init__(self, cfg: dict,scale_r=4.0):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], int(scale_r * cfg["emb_dim"])),
GELU(),
nn.Linear(int(scale_r * cfg["emb_dim"]), cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)在GPT-2的架构中,使用GELU函数作为激活函数,只有一层隐藏层,4倍于输入层的节点数量。
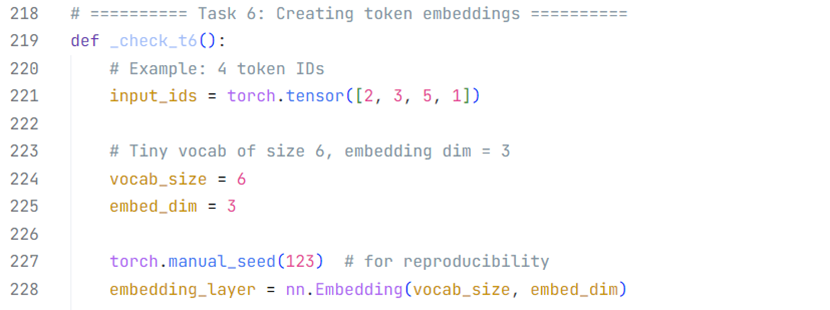
五、GPT-2基本架构与可训练参数估计
在前四部分的基础上,堆叠N个Transformer Block并和头尾(见1.4标蓝字体)连接起来,就得到了GPT-2的雏形,四个版本的GPT-2乃至GPT-3大体架构完全一致,变数只有3个:Transformer Block的堆叠个数、多头自注意力里注意力头的个数、词嵌入向量的维度。
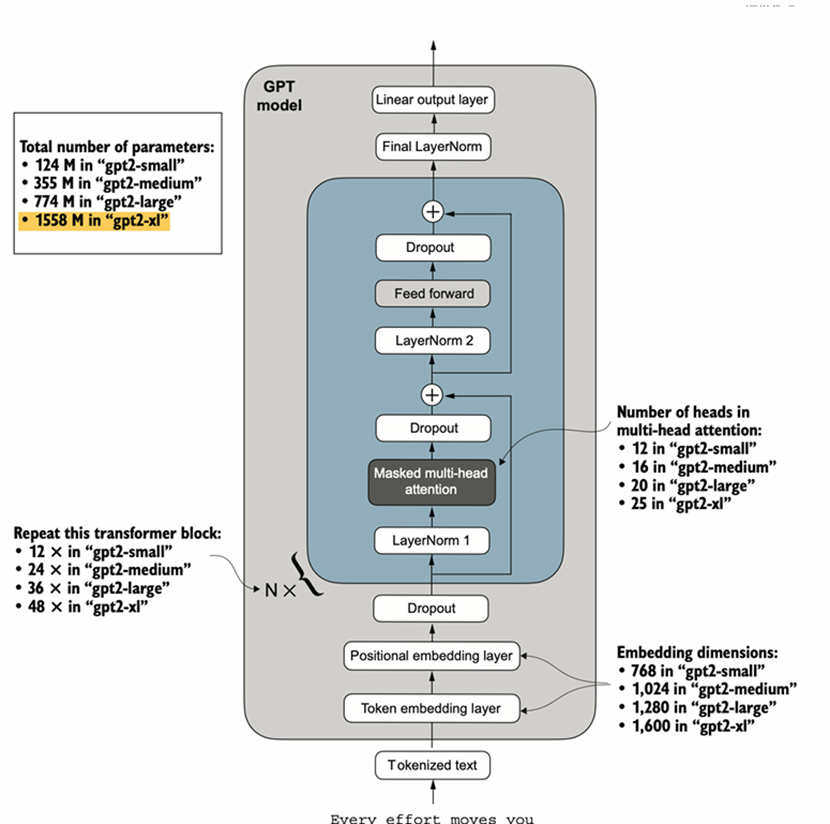
图 7 GPT-2大模型网络架构和参数统计

本地代码搭建并运行GPT2-small,模型大小621.80兆字节,如果考虑最终FC层和输入词嵌入矩阵(词汇表矩阵)的参数绑定(实际操作中如此,互为矩阵转置关系而非矩阵乘法结果为单位矩阵),模型大小大概496兆字节。
六、“傻瓜”大模型推理展示
在没有经过任何训练的情况下,大模型的输出毫无章法。
# Config for the smallest GPT-2 (124M params)
GPT_CONFIG_124M = {
"vocab_size": 50257, # BPE vocab size
"context_length": 1024, # max sequence length (positional embeddings)
"emb_dim": 768, # model/embedding dimension
"n_heads": 12, # attention heads
"n_layers": 12, # transformer blocks
"drop_rate": 0.1, # dropout rate
"qkv_bias": False # whether to use bias in Q/K/V linears (kept False)
}# ========== Task 7: Generating text ==========
# Try to use GPT-2 BPE if available; otherwise provide a tiny fallback tokenizer
try:
import tiktoken
_HAS_TIKTOKEN = True
_ENC = tiktoken.get_encoding("gpt2")
except Exception:
_HAS_TIKTOKEN = False
_ENC = None
def _encode(text: str) -> list[int]:
if _HAS_TIKTOKEN:
return _ENC.encode(text)
def _decode(ids: list[int]) -> str:
if _HAS_TIKTOKEN:
return _ENC.decode(ids)
def generate_text_simple(model: torch.nn.Module,
idx: torch.Tensor,
max_new_tokens: int,
context_size: int) -> torch.Tensor:
"""
Greedy decoding:
- Keep only the last `context_size` tokens as input to the model.
- Take argmax over the last-step logits.
- Append to the running sequence; repeat.
# including shorter text input aligned with longest test input!
idx: (B, T) LongTensor
returns: (B, T + max_new_tokens)
"""
T=idx.shape[1]
for _ in range(max_new_tokens):
# Dynamic setting may be better?
idx_cond = idx[:, max(-context_size,-idx.shape[1]):] # (B, Tc)
with torch.no_grad():
logits = model(idx_cond) # (B, Tc, V)
logits_last = logits[:, -1, :] # (B, V)
next_id = torch.argmax(torch.softmax(logits_last, dim=-1),
dim=-1, keepdim=True) # (B, 1)
# one token(word) at a time!
idx = torch.cat([idx, next_id], dim=1) # (B, Tc+1)
return idx
def _check_t7():
# Reuse `model` from Task 6 if it exists; otherwise create a tiny fresh one
global model
if "model" not in globals():
model = GPTModel(GPT_CONFIG_124M)
# Prepare a start context
txt0 = "Hello, I am"
txt1 = "Every effort moves you"
txt2 = "Every day holds a"
enc = [torch.tensor(_encode(txt),dtype=torch.long) for txt in [txt0,txt1,txt2]]
max_l=max(len(e) for e in enc)
print("[T7] batch maximum input length:",max_l)
enc=[torch.cat([e,torch.zeros(max_l-len(e),dtype=torch.long)]) for e in enc]
print("[T7] encoded:", enc)
# (B=3, T)
# list[Tensor]->Tensor
idx0 = torch.stack(enc,dim=0)
# Eval mode (disables dropout)
model.eval()
out = generate_text_simple(
model=model,
idx=idx0,
max_new_tokens=100,
context_size=GPT_CONFIG_124M["context_length"],
)
print("[T7] output ids:", out.tolist())
print("[T7] output length:", out.shape[1])
# Remove batch dim and decode (note: untrained model → gibberish)
decoded = [_decode(sout.tolist()) for sout in out]
print("[T7] decoded text:", decoded)
return True
在最后的FC全连接层处理得到(B,T,D)的词汇概率预测矩阵之后,
对于D维度:top-k等参数决定的是从概率最高的前k个词汇里面随机选择一个词汇作为输出,显然k越大输出越灵活多样但也越容易忽略用户的细节需求,最终此维度降为1;
对于维度T:最终只能从里面选取最后一个加入到输出中,也就是(B,T)的输入文本拼接一个(B,1)的单次推理输出。
推理迭代的步骤参考1.3滑动窗口部分的讲解。
笔者人工制作了(3,4)(B,T)的输入文本批量,让未经训练的“傻瓜”大模型生成100个新词,也就是得到(3,104)的输出,推理前后效果如下:


是不是真的很“傻瓜”?不过不要小看眼前这个大模型,它学习起来效率不低,只需要一些高算力的GPU和优质且完备的数据集,在几个月的时间里就可以掌握超越99%的人类掌握的正确的有价值的知识!
七、数学分析
在自注意机制部分,笔者说到注意力分数每个元素的计算公式,s(i,j)= 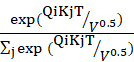
但是从概率论与数理统计的角度,为什么QiKjT的内积的分布方差和Qi或者Kj的元素数量(也就是词嵌入维度V)成正比呢?
这里需要做两个假设:
- 词嵌入维度的各个维度是相互独立且同分布的(iid),对于Qi内部、Kj内部、或者Qi和Kj的任意两两元素;
- 假设各元素服从正态分布(因为高斯分布比较常见)。
那么QiKjT=![]() ,根据统计学的方差计算公式,Var(QiKjT)=
,根据统计学的方差计算公式,Var(QiKjT)=![]() =
=![]() =
=![]() 。实际在代码编写中,随机初始化如果使用torch.randn(0,1)手动初始化,方差就等于V,然而一般使用Xaiver或者Kaiming’s Rule初始化来防止训练过程中出现梯度消失或者爆炸的情况,这种情况下本质仍然是均值为0的高斯分布,所以方差等于
。实际在代码编写中,随机初始化如果使用torch.randn(0,1)手动初始化,方差就等于V,然而一般使用Xaiver或者Kaiming’s Rule初始化来防止训练过程中出现梯度消失或者爆炸的情况,这种情况下本质仍然是均值为0的高斯分布,所以方差等于![]() (Kaiming Initialization)或者
(Kaiming Initialization)或者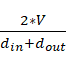 (Xavier Initialization)。因此随着词嵌入维度V的增加,为确保标准差保持恒定,需要除以V的0.5次方。
(Xavier Initialization)。因此随着词嵌入维度V的增加,为确保标准差保持恒定,需要除以V的0.5次方。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)