linux环境llamafactory训练模型导入docker-ollama
写在前面,本文中的ollama是用docker部署的,用别的方式安装的ollama只需要改一下Modelfile的路径和Modelfile文件内容的FROM路径就可以,改为实际路径。注意要把上面转化的gguf文件复制到docker-ollama的实体映射文件夹中,不然会显示找不到文件,同样的,这个Modelfile文件也要放在这个映射文件中。其中/home/modelEX是要转化的文件,/home
写在前面,本文中的ollama是用docker部署的,用别的方式安装的ollama只需要改一下Modelfile的路径和Modelfile文件内容的FROM路径就可以,改为实际路径。
1、训练模型
2、导出模型到指定目录。
3、把导出的safetensors文件转为gguf格式的文件
(1)去github上下载llama.cpp包
(2)解压后进入llama.cpp的主目录,环境同时要切换为python环境
python环境安装
(3)相关依赖下载
pip install -r requirements.txt
(4)开始转换(以我的目录/home/modelEX为例)
python convert_hf_to_gguf.py /home/modelEX \
--outfile /home/model/output.gguf \
--outtype q8_0
其中/home/modelEX是要转化的文件,/home/model/output.gguf是输出的文件名。--outtype是量化参数。
如果报错OSError: Can’t load tokenizer for ‘xxx’这种东西,去huggingface上找两个东西复制到/home/modelEX,先找到你的用的模型,下载下图中的这两个文件。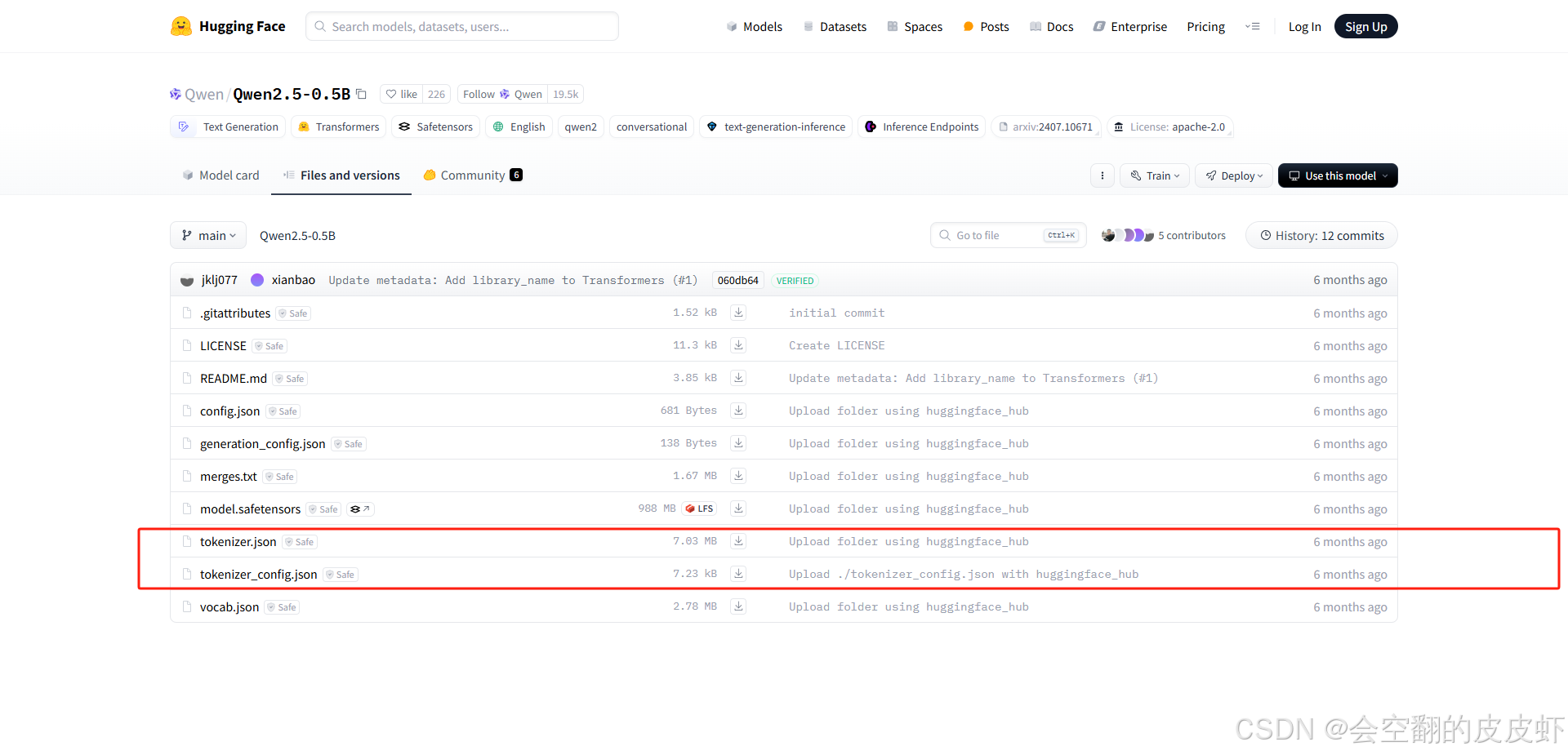
(5)接下来创建一个名为Modelfile的文件(不要后缀),文件内容
FROM /root/.ollama/models/blobs/output-100.gguf
注意要把上面转化的gguf文件复制到docker-ollama的实体映射文件夹中,不然会显示找不到文件,同样的,这个Modelfile文件也要放在这个映射文件中。
(6)创建ollama模型,命令行输入
ollama create mymodel -f /root/.ollama/models/blobs/Modelfile
这个时候应该就会开始创建了,创建完成后用ollama run一下就可以了。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)