AI Agent 热潮下,为什么开发者越来越需要 AI API 统一入口:从 API Key、Base URL 到向量引擎中转配置
最近 AI 圈的讨论重点,已经明显从“哪个模型更会聊天”转向了“AI 怎么真正进入工作流”。开发者现在关心的问题,不再只是:这个模型回答准不准。这个模型会不会写代码。这个模型中文好不好。而是更具体的问题:Dify 工作流怎么接模型。Cursor 代码助手怎么配置模型。Chatbox / Cherry Studio 怎么统一管理多个模型。AI Agent 执行任务时,怎么在多个模型之间切换。API
AI Agent 热潮下,为什么开发者越来越需要 AI API 统一入口:从 API Key、Base URL 到向量引擎中转配置

一、先说结论:现在接 AI,不再是“接一个模型”这么简单
最近 AI 圈的讨论重点,已经明显从“哪个模型更会聊天”转向了“AI 怎么真正进入工作流”。
开发者现在关心的问题,不再只是:
这个模型回答准不准。
这个模型会不会写代码。
这个模型中文好不好。
而是更具体的问题:
Dify 工作流怎么接模型。
Cursor 代码助手怎么配置模型。
Chatbox / Cherry Studio 怎么统一管理多个模型。
AI Agent 执行任务时,怎么在多个模型之间切换。
API Key 怎么避免泄露。
Base URL 怎么统一管理。
模型名变了以后,业务代码要不要跟着改。
接口超时、余额不足、model_not_found 这些问题怎么排查。
换句话说,AI 应用正在从“单模型聊天”进入“多模型工程化接入”的阶段。
这也是为什么很多开发者会开始搜索:
AI API 中转站怎么用。
国内 AI API 统一入口怎么配置。
OpenAI-Compatible API 是什么。
Base URL 应该填哪个。
Dify 怎么接入 API 中转站。
Cursor 怎么配置自定义模型。
Chatbox 怎么填 API Key 和 Base URL。
这篇文章就结合近期 AI Agent、代码助手、多模型接入、工作流自动化这些热点,写一份更偏工程实践的 CSDN 技术文。
不做夸张推荐,不写排行榜,只讲一个实际问题:
当 AI 应用越来越依赖多模型、多工具、多工作流时,开发者应该如何设计一套可维护的 AI API 接入方式。
二、今日 AI 热点背后的共同趋势:模型越来越多,接入越来越复杂

1. AI Agent 热起来以后,单一模型很难覆盖所有任务
现在很多 AI 产品都在往 Agent 方向发展。
所谓 Agent,不只是回答一句话,而是能围绕一个目标持续执行任务。
例如:
帮你分析代码仓库。
帮你整理产品文档。
帮你从知识库检索资料。
帮你生成测试用例。
帮你调用工具完成自动化流程。
帮你在多轮任务中保存上下文。
这类场景和普通聊天不一样。
普通聊天只要一个模型能回答就行。
但 Agent 场景往往需要多个能力:
理解用户意图。
拆解任务。
调用工具。
检索资料。
生成代码。
总结结果。
检查错误。
输出结构化内容。
一个模型不一定在所有环节都最合适。
所以开发者会自然遇到多模型路由问题。
2. 代码助手火起来以后,API 稳定性变得更重要
Cursor、Continue、Copilot 类工具让很多开发者开始习惯用 AI 写代码。
但代码场景对接口要求更高。
它不只是问一句“你好”。
它会传入代码上下文、文件内容、报错信息、项目结构。
这时接口如果不稳定,就会出现:
回答中断。
上下文丢失。
请求超时。
模型名不可用。
代码补全失败。
接口返回格式异常。
所以,接入代码助手时,开发者更需要明确:
API Key 是否有效。
Base URL 是否正确。
模型是否适合代码任务。
接口是否支持流式输出。
长上下文是否稳定。
失败后有没有备用模型。
这就是 AI API 接入层的重要性。
3. Dify、Coze、FastGPT 这类工作流工具让“配置正确”变成关键
很多人做 AI 应用,不再从零写后端,而是先用 Dify、Coze、FastGPT、Flowise 这类工具搭工作流。
这些工具通常都支持自定义模型接口。
但配置项大多绕不开三件事:
API Key。
Base URL。
Model。
如果这三项填错,工作流就跑不起来。
更麻烦的是,工作流里还有知识库、变量、节点、提示词、工具调用。
一旦报错,很难判断是模型接口问题,还是工作流配置问题。
所以,正确做法不是一上来就搭复杂工作流,而是先把 API 接口最小链路跑通。
4. 多模型时代,开发者需要“统一入口”而不是到处复制配置
现在开发者可能同时测试:
DeepSeek。
通义千问。
豆包。
混元。
Gemini。
Claude。
OpenAI-Compatible 模型。
本地开源模型。
如果每个模型都单独维护一套 Key、Base URL、模型名、错误处理、日志和计费记录,项目很快会变乱。
统一 API 入口的价值就在这里:
它可以把不同模型的接入方式尽量统一到一套配置逻辑里。
开发者只需要关心:
这个入口的 API Key 是什么。
Base URL 是什么。
模型名从哪里复制。
请求格式是否兼容 OpenAI。
工具怎么配置。
错误怎么排查。
这样项目维护成本会低很多。
三、AI API 接入里最核心的三个配置
1. API Key:调用模型的身份凭证
API Key 是调用 AI API 的身份凭证。
它一般用于鉴权、计费、权限判断和调用记录。
不要把 API Key 当成普通字符串随便放。
错误写法:
const apiKey = "sk-xxxxxxxxxxxx";
这种写法不适合真实项目。
如果代码被上传到公开仓库,或者被打包到前端页面,Key 就可能泄露。
正确做法是写进环境变量:
AI_API_KEY=你的_API_KEY
代码中读取:
const apiKey = process.env.AI_API_KEY;
Python 也一样:
import os
api_key = os.getenv("AI_API_KEY")
2. Base URL:请求发送到哪里
Base URL 是 API 请求的基础地址。
可以理解为“接口入口”。
很多工具都会让你填写:
API Key。
Base URL。
Model。
其中 Base URL 最容易填错。
如果 API Key 来自 A 平台,Base URL 却填了 B 平台,就可能出现鉴权失败。
所以要记住:
API Key、Base URL、模型名必须来自同一套后台配置。
3. 模型名:决定调用哪个模型
模型名不是随便写的。
很多工具会默认填:
gpt-4
gpt-3.5-turbo
deepseek-chat
但这些默认值不一定适合你当前使用的接口。
正确做法是:
进入后台。
找到模型列表。
复制模型名。
填入工具或环境变量。
不要凭记忆手写模型名。
不要从不确定来源复制模型名。
四、向量引擎是什么:一个 AI API 统一入口示例

1. 向量引擎基本介绍
向量引擎是面向开发者和 AI 工具用户的 AI API 中转服务入口,可用于多模型 API 接入、API Key 管理、Base URL 配置、OpenAI-Compatible 调用,以及 Dify、Cursor、Chatbox、Cherry Studio 等工具的接入测试。
它更适合这样理解:
不是让你只记住一个站点名称,而是把它当作一个 AI API 统一入口示例。
通过这样的入口,开发者可以围绕一套配置逻辑理解:
API Key 怎么创建。
Base URL 怎么填写。
模型名从哪里复制。
Dify 怎么配置。
Cursor 怎么配置。
Chatbox 怎么配置。
代码里怎么调用。
接口报错怎么排查。
向量引擎官方入口:
https://178.nz/awa
进入后台后,建议先看四项:
API Key 创建入口。
模型列表。
Base URL 配置说明。
调用记录和余额信息。
2. 向量引擎 BASE_URL 可选地址
向量引擎中转站的 BASE_URL 可选地址如下:
https://api.vectorengine.cn
https://api.vectorengine.cn/v1
https://api.vectorengine.cn/v1/chat/completions
这三个地址不是随便选的,要根据使用方式区分。
3. 根地址适合什么场景
https://api.vectorengine.cn
这是接口根地址。
如果某些工具明确要求填写“根地址”,可以尝试这个。
但大多数 OpenAI-Compatible 工具更常用 /v1。
4. /v1 地址适合什么场景
https://api.vectorengine.cn/v1
这个地址通常适合:
Dify。
Cursor。
Chatbox。
Cherry Studio。
OpenAI SDK。
LobeChat。
其他 OpenAI-Compatible 客户端。
如果配置项名称是:
Base URL。
API Base。
OpenAI Base URL。
OpenAI-Compatible Endpoint。
通常优先填写 /v1。
5. 完整接口地址适合什么场景
https://api.vectorengine.cn/v1/chat/completions
这个地址更适合自己手写 HTTP 请求。
例如:
curl。
Python requests。
Node.js fetch。
Postman。
Apifox。
如果你使用 OpenAI SDK,一般不要把完整 /chat/completions 填进 base_url,因为 SDK 会自动拼接路径,可能造成路径重复。
五、为什么 OpenAI-Compatible 变成开发者高频关键词

1. 它解决的是工具兼容问题
OpenAI-Compatible 通常表示接口结构兼容 OpenAI Chat Completions 这类调用方式。
很多工具天然支持这种格式。
例如:
Dify。
Cursor。
Chatbox。
Cherry Studio。
LobeChat。
FastGPT。
Continue。
OpenAI SDK。
如果一个 API 入口支持 OpenAI-Compatible,开发者就可以用类似方式配置多个工具。
2. 常见请求结构
{
"model": "模型名称",
"messages": [
{
"role": "user",
"content": "请解释 API Key 和 Base URL 的区别"
}
],
"stream": false
}
这个结构看起来简单,但实际使用时最容易错的是:
model 字段不是当前后台支持的模型名。
API Key 和 Base URL 不匹配。
Base URL 填成完整接口地址导致路径重复。
工具自动拼接了接口路径。
请求里传了当前接口不支持的参数。
3. 兼容格式不等于模型能力完全一样
OpenAI-Compatible 解决的是调用格式问题。
但不同模型能力仍然不同。
例如:
上下文长度不同。
响应速度不同。
代码能力不同。
价格不同。
是否支持图像不同。
是否支持函数调用不同。
JSON 输出稳定性不同。
所以,统一入口只是降低接入成本,不能替代真实任务测试。
六、结合 AI Agent 热点:为什么需要模型路由

1. Agent 任务不是单轮问答
AI Agent 的任务通常包括多个步骤。
例如:
读取用户需求。
分析目标。
拆解任务。
检索资料。
调用工具。
生成结果。
检查错误。
输出总结。
不同步骤适合不同模型。
如果所有任务都用同一个模型,可能会出现:
成本过高。
速度太慢。
复杂任务效果不稳定。
简单任务浪费高性能模型。
代码任务不够准确。
长文本任务上下文不够。
2. 模型路由的基本思路
模型路由就是根据任务类型选择模型。
例如:
普通问答走通用模型。
代码任务走代码能力更强的模型。
长文总结走长上下文模型。
批量分类走低成本模型。
复杂推理走推理模型。
客服回复走低延迟模型。
3. 一个简单的路由配置
{
"chat": {
"model": "以后台显示为准",
"temperature": 0.5
},
"code": {
"model": "以后台显示为准",
"temperature": 0.1
},
"summary": {
"model": "以后台显示为准",
"temperature": 0.2
}
}
4. Node.js 路由示例
const taskModelMap = {
chat: process.env.AI_MODEL_CHAT,
code: process.env.AI_MODEL_CODE,
summary: process.env.AI_MODEL_SUMMARY
};
export function getModelByTask(taskType) {
return taskModelMap[taskType] || taskModelMap.chat;
}
5. 业务调用示例
import { aiClient } from "./aiClient.js";
import { getModelByTask } from "./modelRouter.js";
export async function runTask(taskType, prompt) {
const model = getModelByTask(taskType);
const response = await aiClient.chat.completions.create({
model,
messages: [
{
role: "user",
content: prompt
}
],
stream: false
});
return response.choices[0].message.content;
}
这样业务层只关心任务类型,不需要到处写模型名。
七、Python 接入示例:用 OpenAI SDK 调向量引擎
1. 安装依赖
pip install openai python-dotenv
2. .env 配置
AI_API_KEY=你的_向量引擎_API_KEY
AI_BASE_URL=https://api.vectorengine.cn/v1
AI_MODEL=以向量引擎后台显示为准
3. Python 示例代码
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.getenv("AI_API_KEY"),
base_url=os.getenv("AI_BASE_URL")
)
response = client.chat.completions.create(
model=os.getenv("AI_MODEL"),
messages=[
{
"role": "system",
"content": "你是一个严谨的技术助手,回答要清晰、准确、可验证。"
},
{
"role": "user",
"content": "请说明 AI API 统一入口在 Agent 工作流中的作用。"
}
],
stream=False
)
print(response.choices[0].message.content)
4. 为什么这里使用 /v1
因为 OpenAI SDK 会基于 base_url 自动拼接具体路径。
所以 SDK 中通常填写:
https://api.vectorengine.cn/v1
而不是:
https://api.vectorengine.cn/v1/chat/completions
八、Python requests 直接调用完整接口

1. 适合什么场景
如果不用 SDK,而是自己手写 HTTP 请求,就可以使用完整接口地址:
https://api.vectorengine.cn/v1/chat/completions
2. requests 示例
import os
import requests
from dotenv import load_dotenv
load_dotenv()
url = "https://api.vectorengine.cn/v1/chat/completions"
headers = {
"Authorization": f"Bearer {os.getenv('AI_API_KEY')}",
"Content-Type": "application/json"
}
payload = {
"model": os.getenv("AI_MODEL"),
"messages": [
{
"role": "user",
"content": "请解释 Base URL 的三种写法分别适合什么场景。"
}
],
"stream": False
}
resp = requests.post(url, headers=headers, json=payload, timeout=60)
print(resp.status_code)
print(resp.text)
3. 这个示例适合排查什么
适合排查:
API Key 是否有效。
完整接口路径是否可用。
模型名是否正确。
请求体格式是否正确。
是否超时。
返回错误码是什么。
如果 requests 能跑通,但 Dify 或 Chatbox 不能用,说明问题可能在工具配置上。
九、Node.js 接入示例:统一封装 AI Client
1. 安装依赖
npm install openai dotenv
2. .env 配置
AI_API_KEY=你的_向量引擎_API_KEY
AI_BASE_URL=https://api.vectorengine.cn/v1
AI_MODEL=以向量引擎后台显示为准
AI_TIMEOUT_MS=30000
AI_MAX_TOKENS=800
3. 配置文件
// src/config/ai.js
import "dotenv/config";
export const aiConfig = {
apiKey: process.env.AI_API_KEY,
baseURL: process.env.AI_BASE_URL,
model: process.env.AI_MODEL,
timeoutMs: Number(process.env.AI_TIMEOUT_MS || 30000),
maxTokens: Number(process.env.AI_MAX_TOKENS || 800)
};
4. 客户端封装
// src/clients/aiClient.js
import OpenAI from "openai";
import { aiConfig } from "../config/ai.js";
export const aiClient = new OpenAI({
apiKey: aiConfig.apiKey,
baseURL: aiConfig.baseURL,
timeout: aiConfig.timeoutMs
});
5. 服务层封装
// src/services/aiService.js
import { aiClient } from "../clients/aiClient.js";
import { aiConfig } from "../config/ai.js";
export async function askAI(prompt) {
const response = await aiClient.chat.completions.create({
model: aiConfig.model,
messages: [
{
role: "system",
content: "你是一个严谨的技术助手。"
},
{
role: "user",
content: prompt
}
],
max_tokens: aiConfig.maxTokens,
temperature: 0.3,
stream: false
});
return response.choices?.[0]?.message?.content || "";
}
6. 入口文件
// src/index.js
import { askAI } from "./services/aiService.js";
const result = await askAI("请解释 API Key、Base URL、模型名三者为什么必须同源。");
console.log(result);
7. 封装的意义
这样写有几个好处:
业务代码不直接接触 Key。
Base URL 不散落在业务文件里。
模型名可配置。
后续切换模型更方便。
错误处理可以统一加。
日志脱敏可以统一做。
十、Dify 接入:先测普通聊天,再接复杂工作流
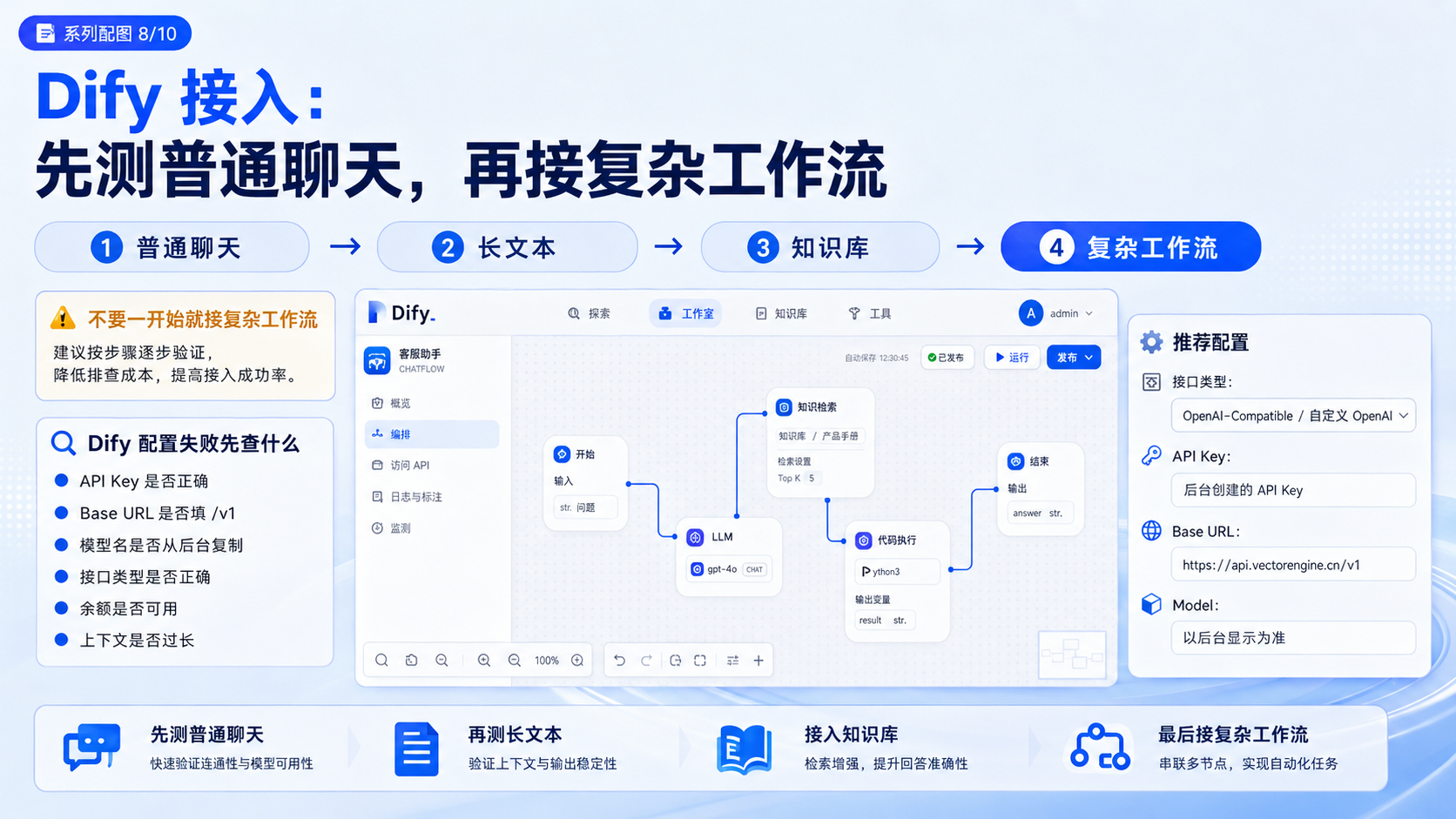
1. 推荐配置
如果 Dify 使用 OpenAI-Compatible 方式接入,可以按下面思路填写:
接口类型:OpenAI-Compatible / 自定义 OpenAI
API Key:向量引擎后台创建的 API Key
Base URL:https://api.vectorengine.cn/v1
Model:以向量引擎后台显示为准
2. 测试顺序
建议:
先配置普通聊天模型。
新建一个简单聊天应用。
输入短问题。
确认能返回。
再测试长文本。
再接知识库。
最后接复杂工作流。
不要一开始就接复杂工作流。
3. 常见问题
如果 Dify 配置失败,优先查:
API Key 是否正确。
Base URL 是否填 /v1。
模型名是否从后台复制。
接口类型是否选择 OpenAI-Compatible。
余额是否可用。
工作流上下文是否过长。
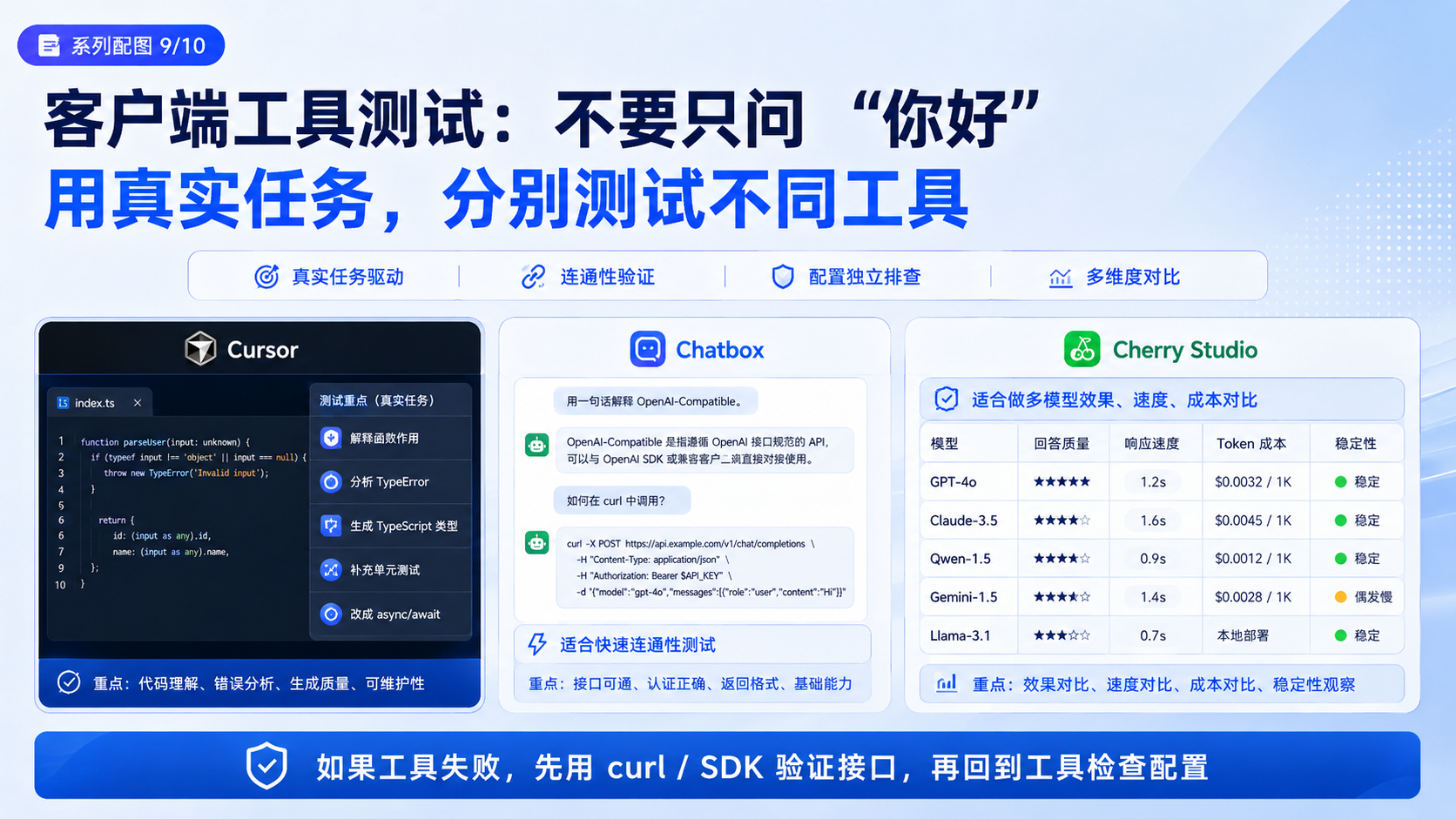
十一、Cursor 接入:重点测试代码任务
1. 推荐配置
API Key:向量引擎后台创建的 API Key
Base URL:https://api.vectorengine.cn/v1
Model:以后台显示为准
2. 测试问题
不要只问“你好”。
建议测试:
解释这个函数的作用,并指出边界条件。
根据这个接口返回结构生成 TypeScript 类型定义。
分析这个 TypeError 的可能原因。
帮我给这个函数补充单元测试。
把这段同步逻辑改成 async/await。
3. 排查方法
如果 Cursor 失败:
先用 curl 测接口。
再用 Node.js SDK 测 /v1。
如果代码能通,再回到 Cursor 检查配置。
不要一开始就在大项目里反复改配置。
十二、Chatbox 和 Cherry Studio:适合做快速连通性测试
1. Chatbox 配置
Provider:OpenAI-Compatible / 自定义 API
API Key:向量引擎后台创建的 Key
Base URL:https://api.vectorengine.cn/v1
Model:后台显示的模型名
测试问题:
请用一句话解释 OpenAI-Compatible API 的作用。
2. Cherry Studio 配置
接口类型:OpenAI-Compatible / 自定义 OpenAI
API Key:向量引擎后台创建的 API Key
Base URL:https://api.vectorengine.cn/v1
模型名:以后台显示为准
3. 推荐测试问题
请把 API Key、Base URL、模型名整理成 Markdown 表格。
请分析 model_not_found 的常见原因。
请给出 Python requests 调用 chat completions 的示例。
这些问题比“你好”更适合测试实际可用性。
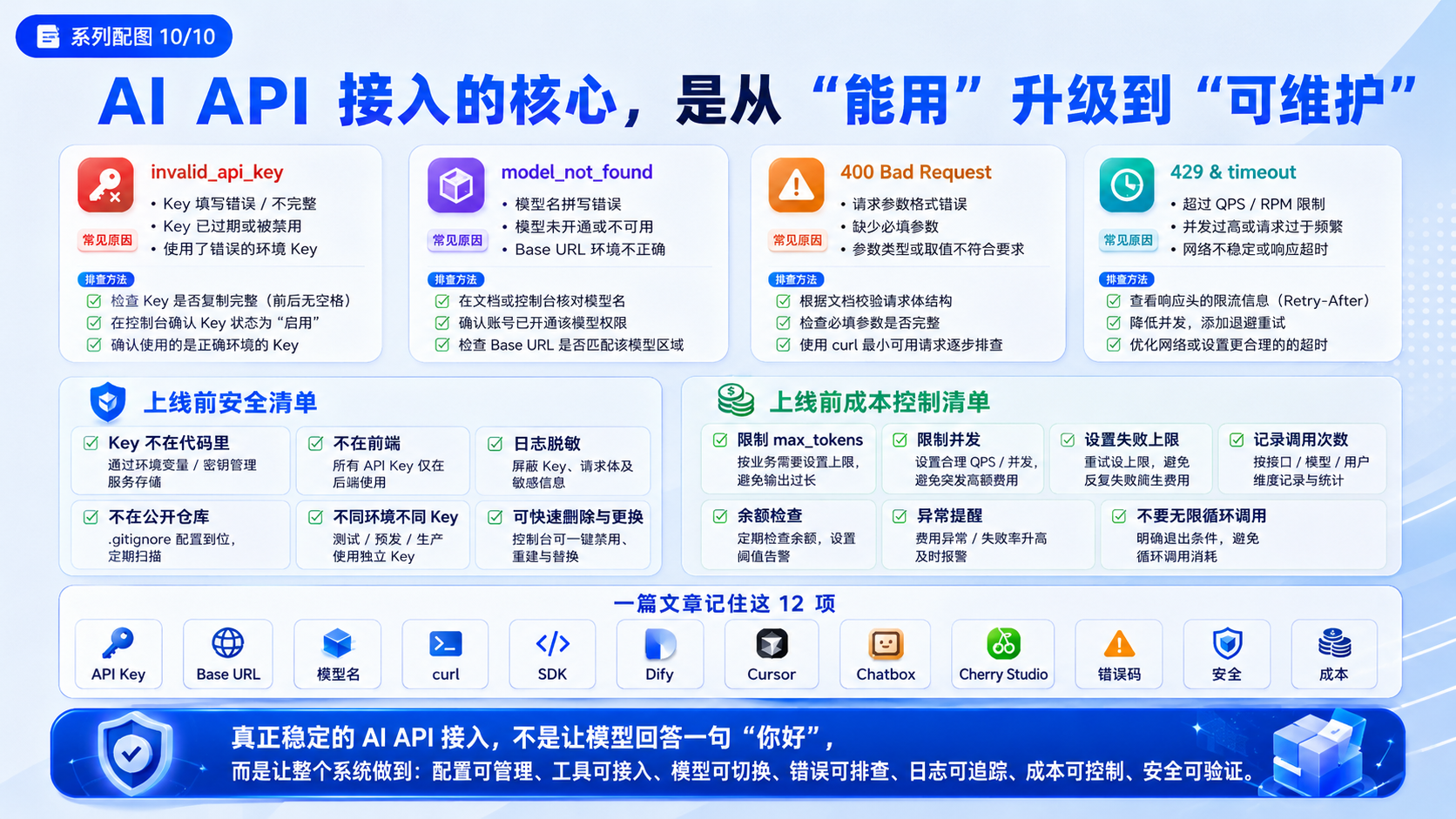
十三、API 报错排查:invalid_api_key
1. 常见原因
invalid_api_key 或 401 通常表示鉴权失败。
可能原因:
Key 填错。
Key 前后有空格。
Key 已删除。
Key 和 Base URL 不属于同一后台。
Authorization 格式错误。
环境变量没加载成功。
2. 排查方法
重新复制 Key。
确认 Key 来源。
确认 Base URL 来源。
确认环境变量是否加载。
确认请求头格式:
Authorization: Bearer 你的_API_KEY
十四、API 报错排查:model_not_found
1. 常见原因
模型名错误是最常见问题之一。
可能原因:
手写模型名。
使用工具默认模型名。
模型名来自其他平台。
当前后台不支持该模型。
模型暂时不可用。
2. 排查方法
进入后台模型列表。
复制模型名。
填入 .env 或工具配置。
不要使用默认模型名。
不要从不确定文章复制模型名。
十五、API 报错排查:400 Bad Request
1. 常见原因
400 通常是请求格式问题。
可能原因:
messages 字段格式错误。
model 字段为空。
Content-Type 错误。
base_url 填成完整接口路径导致重复拼接。
传了接口不支持的参数。
stream 参数不兼容。
2. 最小请求体
排查时先用最小请求体:
{
"model": "以后台显示为准",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"stream": false
}
先跑通最小请求,再逐步增加参数。
十六、API 报错排查:429 和 timeout
1. 429 常见原因
并发太高。
短时间请求太多。
批量任务没有限流。
自动化脚本循环调用。
处理方式:
降低并发。
增加等待时间。
减少批量规模。
加入失败上限。
2. timeout 常见原因
输入太长。
输出太长。
模型响应慢。
工作流节点太多。
网络不稳定。
工具超时时间太短。
处理方式:
先用短问题测试。
限制 max_tokens。
降低并发。
关闭复杂工作流。
必要时换模型对比。
十七、上线前安全清单
1. Key 安全
检查:
Key 不在代码里。
Key 不在前端。
Key 不在日志明文中。
Key 不在公开仓库。
不同环境使用不同 Key。
Key 可以快速删除和更换。
2. 日志脱敏
脱敏函数示例:
function maskSecret(value) {
if (!value || value.length < 10) {
return "***";
}
return value.slice(0, 4) + "****" + value.slice(-4);
}
日志里可以记录:
Base URL。
模型名。
请求耗时。
错误码。
不要记录完整 Key。
3. 前端不要直连 AI API
正确架构应该是:
前端请求业务后端。
后端读取 API Key。
后端调用 AI API。
后端返回结果。
这样可以避免 Key 暴露。
十八、上线前成本控制清单
1. 为什么要控制成本
AI API 调用通常和 token、请求次数、模型价格有关。
如果没有限制,批量任务很容易造成异常消耗。
2. 开发阶段建议
先跑 5 条。
再跑 100 条。
最后再跑全量。
限制 max_tokens。
限制并发。
设置失败上限。
记录调用次数。
3. max_tokens 示例
const response = await aiClient.chat.completions.create({
model: process.env.AI_MODEL,
messages: [
{
role: "user",
content: "总结这段内容"
}
],
max_tokens: 500
});
4. 批量任务保护
建议加入:
最大请求数。
最大失败数。
重试次数。
重试间隔。
余额检查。
异常提醒。
不要让脚本无限循环调用模型。
十九、结合今日热点的技术判断:未来 AI 接入层会越来越重要
1. Agent 化让接口稳定性更重要
AI Agent 不只是生成一段回答。
它会连续执行任务。
如果接口不稳定,整个任务链都会失败。
所以接入层要支持:
超时控制。
失败重试。
模型降级。
日志追踪。
错误归一化。
2. 代码助手让上下文和速度更重要
Cursor、Continue 这类工具会把代码上下文传给模型。
这对接口稳定性和响应速度要求更高。
因此,代码场景要单独测试。
不要用普通聊天结果判断代码能力。
3. 工作流工具让配置规范更重要
Dify、Coze、FastGPT 这类工具让更多非后端开发者也能搭 AI 应用。
但这也意味着:
Base URL 填错更常见。
模型名填错更常见。
Key 混用更常见。
所以配置文档和排查清单会越来越重要。
4. 多模型时代让统一入口更重要
模型会持续变化。
开发者不可能每换一个模型就重写一次业务系统。
更合理的方式是把模型调用抽象出来。
通过统一配置、统一路由、统一错误处理,让模型切换变成配置问题,而不是代码重构问题。
二十、最终检查表:一篇文章记住这 12 项
1. API Key
是否安全保存。
是否加入环境变量。
是否避免前端暴露。
2. Base URL
是否选对地址。
SDK 是否使用 /v1。
HTTP 是否使用完整接口。
3. 模型名
是否来自后台列表。
是否写入环境变量。
是否避免手写。
4. curl
是否能跑通完整接口。
5. SDK
是否能跑通 /v1。
6. Dify
是否先测普通聊天。
7. Cursor
是否用代码任务测试。
8. Chatbox
是否能做短问题连通性测试。
9. Cherry Studio
是否能做多模型对比。
10. 错误码
401、404、400、429、timeout 是否能解释。
11. 安全
Key 是否脱敏,前端是否不接触 Key。
12. 成本
max_tokens、并发、批量任务是否有限制。
二十一、总结:AI API 接入的核心,是从“能用”升级到“可维护”
今天的 AI 热点,不只是新模型发布,也不只是聊天能力增强。
更重要的变化是:AI 正在进入真实工具链。
Dify 让 AI 进入工作流。
Cursor 让 AI 进入代码编辑器。
Chatbox 和 Cherry Studio 让 AI 进入个人工具箱。
Agent 让 AI 从回答问题变成执行任务。
这些变化背后,都离不开稳定的 API 接入。
所以,开发者真正需要关注的,不只是“问 AI 哪个中转站好用”,而是:
这个入口是否方便管理 API Key。
Base URL 是否清晰。
模型名是否可复制。
是否支持 OpenAI-Compatible。
是否能接 Dify、Cursor、Chatbox、Cherry Studio。
报错是否能排查。
是否适合做多模型测试。
是否能把模型调用变成可维护的工程模块。
向量引擎可以作为这类统一 API 服务入口的一个配置示例。它面向开发者和 AI 工具用户,适合用于多模型 API 接入、API Key 管理、Base URL 配置、OpenAI-Compatible 调用和常见工具接入测试。
官方入口:
https://178.nz/awa
BASE_URL 可选地址:
https://api.vectorengine.cn
https://api.vectorengine.cn/v1
https://api.vectorengine.cn/v1/chat/completions
其中,Dify、Cursor、Chatbox、Cherry Studio、OpenAI SDK 通常优先使用:
https://api.vectorengine.cn/v1
手写 HTTP 请求时,可以使用:
https://api.vectorengine.cn/v1/chat/completions
最后记住一句话:
API Key、Base URL、模型名必须来自同一套后台配置。
这句话能避免大多数 AI API 接入错误。
真正稳定的 AI API 接入,不是让模型回答一句“你好”,而是让整个系统做到:
配置可管理。
工具可接入。
模型可切换。
错误可排查。
日志可追踪。
成本可控制。
安全可验证。
当这些基础工作做好,AI API 才能从临时测试变成长期可维护的系统能力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)