ubuntu中 ollama 本地部署模型 llama.cpp本地部署
步骤 1: 下载 Ollama
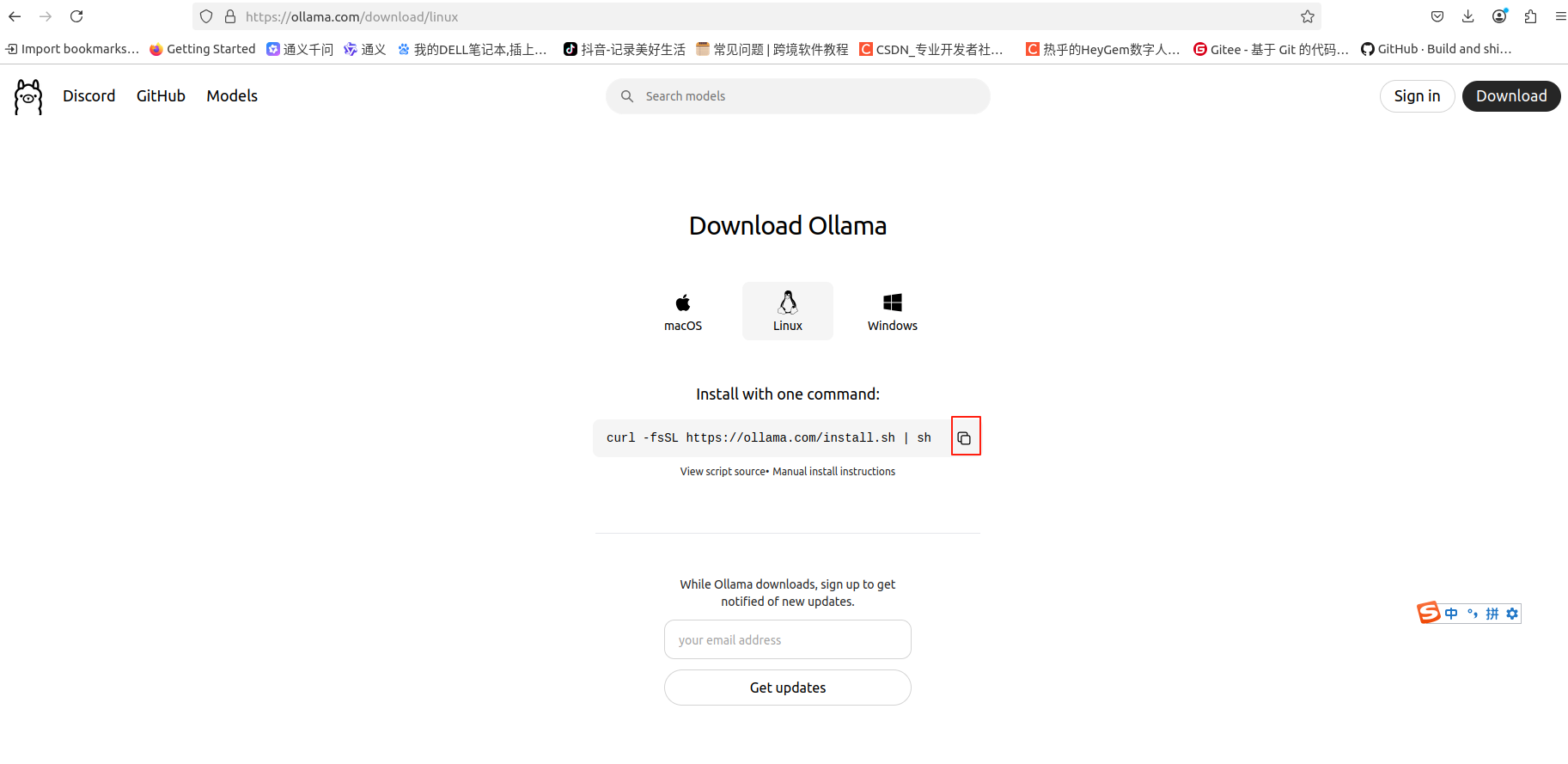
首先,访问 Ollama 官方提供的 Linux 下载链接来获取最新的 Ollama 版本。
https://ollama.com/download/linux
 修改配置文件,允许其他客户端调用,默认情况下ollama只能在本机上调用
修改配置文件,允许其他客户端调用,默认情况下ollama只能在本机上调用
vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
#ExecStart=/usr/bin/ollama serve
ExecStart=/usr/local/bin/ollama serve --host 0.0.0.0
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
使用下列命令启动或配置Ollama:
# 重载配置
sudo systemctl daemon-reload
# 启动服务
sudo systemctl start ollama.service
# 查看服务状态
sudo systemctl status ollama.service
# 设置服务开机自启动
sudo systemctl enable ollama.service
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor prese>
Active: active (running) since Mon 2025-07-28 09:49:21 CST; 1 weeks 0 day>
Main PID: 1666 (ollama)
Tasks: 22 (limit: 38022)
Memory: 478.2M
CGroup: /system.slice/ollama.service
└─1666 /usr/bin/ollama serve
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: llama_new_context_with_>
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: llama_new_context_with_>
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: llama_new_context_with_>
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: llama_new_context_with_>
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: time=2025-08-04T13:19:0>
8月 04 13:19:08 dh-LEGION-REN9000K-34IRZ ollama[1666]: [GIN] 2025/08/04 - 13:1>
8月 04 13:24:13 dh-LEGION-REN9000K-34IRZ ollama[1666]: time=2025-08-04T13:24:1>
8月 04 13:24:14 dh-LEGION-REN9000K-34IRZ ollama[1666]: time=2025-08-04T13:24:1>
8月 04 13:24:14 dh-LEGION-REN9000K-34IRZ ollama[1666]: time=2025-08-04T13:24:1>
8月 04 13:29:15 dh-LEGION-REN9000K-34IRZ ollama[1666]: [GIN] 2025/08/04 - 13:2>
下载运行qwen2.5-0.5b大模型命令为:
ollama run qwen2.5:0.5b
或者其他模型
ollama run deepseek-r1:7b
pulling manifest
pulling c5396e06af29... 100% ▕███████████████▏ 397 MB
pulling 66b9ea09bd5b... 100% ▕███████████████▏ 68 B
pulling eb4402837c78... 100% ▕███████████████▏ 1.5 KB
pulling 832dd9e00a68... 100% ▕███████████████▏ 11 KB
pulling 005f95c74751... 100% ▕███████████████▏ 490 B
verifying sha256 digest
writing manifest
success
查看模型
ollama list
NAME ID SIZE MODIFIED
qwen2.5:0.5b a8b0c5157701 397 MB 13 minutes ago
shaw/dmeta-embedding-zh:latest 41783961c26d 408 MB 2 weeks ago
qwen2:7b dd314f039b9d 4.4 GB 2 weeks ago
deepseek-r1:7b 755ced02ce7b 4.7 GB 3 weeks ago
① 因为ollama默认下载的位置会将模型下载至如下地址/usr/share/ollama/.ollama/models,非常不利于我们查看和修改对应的信息,而且通常一个LLM模型的存储空间占用都是大几个GB或者几十GB起,最好根据自己的实际情况,放在相对安心的位置比较好;
②考虑到接下来,ollama在启动模型后是需要在本地部署并支持被外部访问,因此还需要添加ollama的本地地址使用0.0.0.0,否则默认启动会启用只有本机系统可用的127.0.0.1回环端口。
基于上述问题,特此在/etc/systemd/system/ollama.service中的[Service]这一个下面导航栏下,添加以下信息:
模型下载地址设置,其中/xxx/可以根据自己的实际情况设置绝对地址或相对地址
Environment=“OLLAMA_MODELS=/xxx/ollama/models”
访问端口设置
Environment=“OLLAMA_HOST=0.0.0.0”
修改完上述文件后,对ollama重新加载并更新配置:
# 刷新配置
$ sudo systemctl daemon-reload
重启ollama
$ sudo systemctl restart ollama.service
查看一下重启后的ollama运行状态
$ sudo systemctl status ollama
直接给你说清楚,不绕弯子:
1. Ollama 能不能训练?
不能训练,也不能微调。
Ollama 只能加载、运行已经训练好的模型(GGUF 格式)。
- 不支持全量训练
- 不支持 LoRA 微调
- 不支持继续预训练
它就是一个本地大模型运行引擎,不是训练框架。
2. 是不是只能部署训练好的模型?
是的,完全正确。
你只能用别人训练好并转成 GGUF 的模型,Ollama 负责:
- 加载
- 推理
- 提供 API
- 多轮对话管理
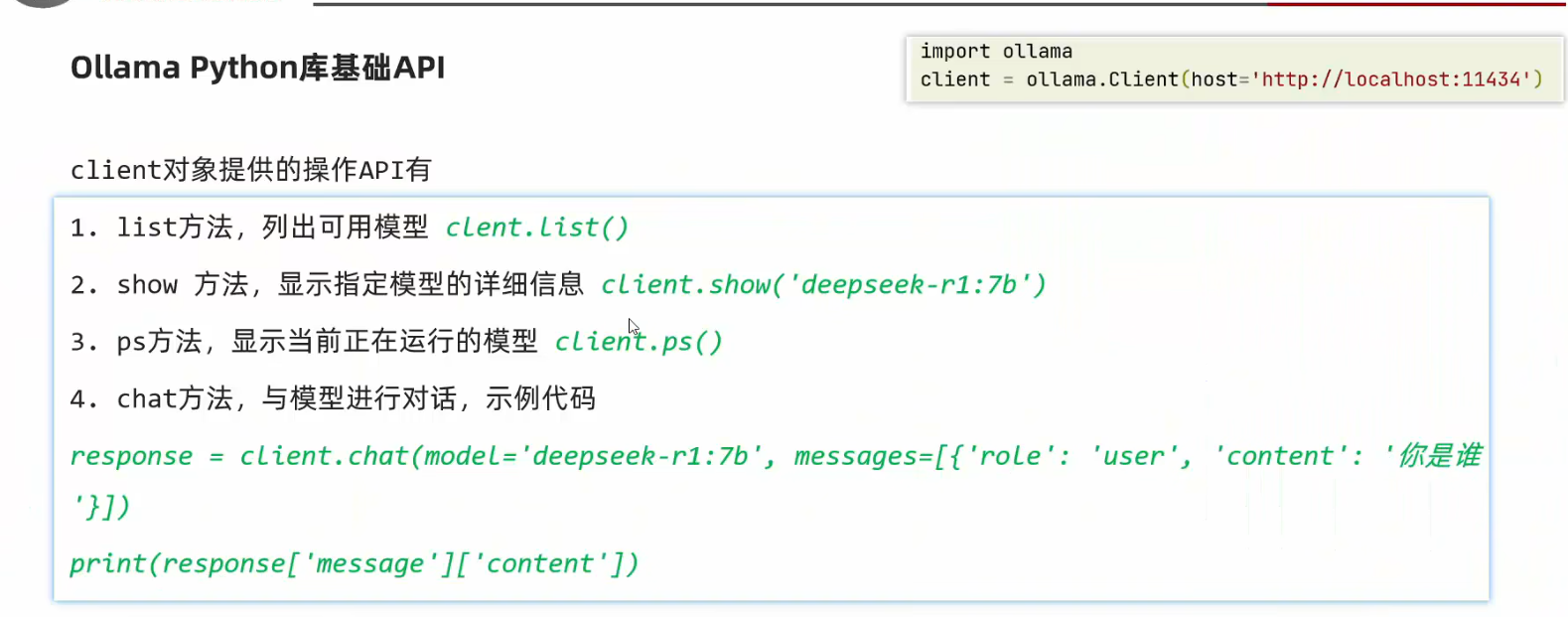
3. Python 怎么调用 Ollama?
非常简单,两步:
① 先启动 Ollama 服务
终端运行:
ollama run llama3
# 或者只启动服务:ollama serve
② Python 调用(两种方式)
方式1:用官方库 ollama
pip install ollama
import ollama
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": "你好,介绍下自己"}
]
)
print(response["message"]["content"])
方式2:直接请求 HTTP API
Ollama 默认启动 http://localhost:11434
import requests
res = requests.post("http://localhost:11434/api/chat", json={
"model": "llama3",
"messages": [
{"role": "user", "content": "写一首诗"}
]
})
print(res.json()["message"]["content"])
4. 可以上传图像吗?
可以,但不是所有模型都支持。
Ollama 支持 多模态模型(图文模型),例如:
llavallava-llama3minicpm-vqwen-vlgemma 不支持图片llama3 本身不支持图片
Python 传图片示例:
import ollama
res = ollama.chat(
model="llava",
messages=[
{
"role": "user",
"content": "这张图片里有什么?",
"images": ["/path/to/your/image.jpg"] # 本地图片路径
}
]
)
print(res["message"]["content"])
5. 能不能传图像,是不是和模型有关?
是的,完全由模型决定。
- 纯文本大模型(Llama 3、Mistral、Gemma、Qwen 文本版)→ 不能看图
- 多模态大模型(LLaVA、MiniCPM-V、Qwen-VL 等)→ 可以传图
Ollama 只是载体,模型本身有没有视觉能力才是关键。
总结一句话
- Ollama 不能训练,只能跑训练好的模型
- Python 调用超简单:
ollama.chat()或 HTTP API - 可以传图片,但必须用多模态模型,和 Ollama 本身无关

🔥 最新版 llama.cpp 完整安装 + 调用教程(2026 官方 CMake 版)
这是纯新手也能一次跑通的完整版,包含:安装依赖 → 升级 CMake → 编译 → 下载模型 → 命令行聊天 → API 服务 → Python 调用,全部复制即用。
一、环境说明
- 系统:Ubuntu / Debian
- 显卡:NVIDIA(CUDA)
- 目标:安装 ggml-org/llama.cpp(官方最新)
- 输出:可直接用的
llama-cli/llama-server
二、完整安装流程(一步不跳)
1. 安装基础依赖
sudo apt update
sudo apt install -y build-essential git wget libopenblas-dev
2. 升级 CMake(必须 ≥3.18)
sudo apt remove -y cmake
wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo gpg --dearmor -o /usr/share/keyrings/kitware-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/kitware-keyring.gpg] https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/kitware.list
sudo apt update
sudo apt install -y cmake
验证:
cmake --version
必须 ≥ 3.18
3. 克隆官方最新仓库
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
4. CMake 编译(带 NVIDIA CUDA 加速)
rm -rf build
mkdir build && cd build
cmake .. -DLLAMA_CUDA=ON
make -j$(nproc)
✅ 成功后,工具在:
llama.cpp/build/bin/
5. 下载轻量中文模型(Qwen2.5 1.5B 4bit)
cd ../../
mkdir -p models
wget -P models https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct-GGUF/resolve/main/qwen2.5-1.5b-instruct-q4_k_m.gguf
如果卡住可以使用其他方法 更简单:用 huggingface-cli + 镜像(推荐新手)
# 1. 安装
pip install -U huggingface_hub
# 2. 设置镜像(临时)
# Windows PowerShell
$env:HF_ENDPOINT="https://hf-mirror.com"
# Linux/macOS
export HF_ENDPOINT=https://hf-mirror.com
# 3. 下载整个仓库(含所有GGUF)
huggingface-cli download --resume-download TheBloke/Llama-2-7B-Chat-GGUF --local-dir ./models
#4 这个是视觉的
下载主模型
huggingface-cli download --resume-download city96/MiniCPM-V-2_0-GGUF --file minicpm-v-2_0.q4_k.gguf --local-dir models
下载视觉编码器(眼睛)
huggingface-cli download --resume-download city96/MiniCPM-V-2_0-GGUF --file mmproj-minicpm-v-2_0-f16.gguf --local-dir models
三、两种调用方式(任选)
方式1:命令行直接聊天
cd build
./bin/llama-cli \
-m ../../models/qwen2.5-1.5b-instruct-q4_k_m.gguf \
-c 4096 \
-ngl 35 \
-i --color
参数说明:
-ngl 35:把 35 层放 GPU(越大越快)-c 4096:上下文长度-i:交互式聊天
方式2:启动 API 服务(推荐!OpenAI 格式)
cd build
./bin/llama-server \
-m ../../models/qwen2.5-1.5b-instruct-q4_k_m.gguf \
-c 8192 \
-ngl 35 \
--host 0.0.0.0 \
--port 8080
API 地址:
http://localhost:8080/v1
四、Python 调用(和 OpenAI 完全一样)
from openai import OpenAI
client = OpenAI(
api_key="dummy",
base_url="http://localhost:8080/v1"
)
resp = client.chat.completions.create(
model="llama",
messages=[{"role": "user", "content": "你好,介绍下自己"}]
)
print(resp.choices[0].message.content)
五、如果你是其他硬件(替换编译命令)
AMD GPU
cmake .. -DLLAMA_HIP=ON
make -j$(nproc)
Apple Silicon (M1/M2/M3)
cmake .. -DLLAMA_METAL=ON
make -j$(nproc)
纯 CPU
cmake ..
make -j$(nproc)
六、最精简一键脚本(你直接保存运行)
保存为 install_llama_cpp.sh
sudo apt update
sudo apt install -y build-essential git wget
sudo apt remove -y cmake
wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo gpg --dearmor -o /usr/share/keyrings/kitware-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/kitware-keyring.gpg] https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/kitware.list
sudo apt update
sudo apt install -y cmake
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
mkdir build && cd build
cmake .. -DLLAMA_CUDA=ON
make -j$(nproc)
cd ../../
mkdir models
wget -P models https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct-GGUF/resolve/main/qwen2.5-1.5b-instruct-q4_k_m.gguf
echo "安装完成!"
echo "启动命令行:cd build && ./bin/llama-cli -m ../../models/qwen2.5-1.5b-instruct-q4_k_m.gguf -c 4096 -ngl 35 -i"
echo "启动API服务:cd build && ./bin/llama-server -m ../../models/qwen2.5-1.5b-instruct-q4_k_m.gguf -c 8192 -ngl 35 --host 0.0.0.0 --port 8080"
七、总结(你必须记住的)
- llama.cpp 现在只用 CMake,不再用 make
- 模型必须是 GGUF
- 编译后工具在:
build/bin/ - API 兼容 OpenAI,可直接对接 Dify/RagFlow/Ollama 生态
好!我直接给你最完整、最实用、直接复制就能跑的两套流程:
- 7B 模型(Qwen2.5-7B)高性能部署(企业最常用)
- 多模态图文模型(Qwen-VL / LLaVA)看图部署(你之前问过的)
全程基于 最新 llama.cpp + CMake + CUDA 加速,不踩坑。
一、7B 模型部署(Qwen2.5-7B-Instruct 最强中文小模型)
1. 下载 7B GGUF 模型(4bit,速度/效果最好)
cd ~/llama.cpp
mkdir -p models
# 下载 7B 4bit 模型(最常用)
wget -P models https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-GGUF/resolve/main/qwen2.5-7b-instruct-q4_k_m.gguf
2. 命令行聊天(7B)
cd build
./bin/llama-cli \
-m ../../models/qwen2.5-7b-instruct-q4_k_m.gguf \
-c 8192 \
-ngl 99 \
-n 1024 \
-i --color
3. 启动 7B API 服务(推荐)
cd build
./bin/llama-server \
-m ../../models/qwen2.5-7b-instruct-q4_k_m.gguf \
-c 8192 \
-ngl 99 \
--host 0.0.0.0 \
--port 8080
-ngl 99= 全部加载到 GPU(速度最快)- 7B 4bit 仅占 4GB 显存,1660/3060/4060 都能跑
二、多模态图文模型(看图、OCR、识图)llama.cpp 部署
llama.cpp 支持 LLaVA、Qwen-VL、MiniCPM-V 等官方支持。
我给你 最小、最快、中文最好 的:
MiniCPM-V 2.0(2B,轻量看图神器)
1. 下载图文模型(GGUF)
cd ~/llama.cpp/models
# 下载图文模型
wget https://huggingface.co/city96/MiniCPM-V-2_0-GGUF/resolve/main/minicpm-v-2_0.q4_k.gguf
# 下载视觉 projector(必须)
wget https://huggingface.co/city96/MiniCPM-V-2_0-GGUF/resolve/main/mmproj-minicpm-v-2_0-f16.gguf
2. 启动图文 API 服务(能看图!)
cd ~/llama.cpp/build
./bin/llama-server \
-m ../../models/minicpm-v-2_0.q4_k.gguf \
--mmproj ../../models/mmproj-minicpm-v-2_0-f16.gguf \
-c 4096 \
-ngl 99 \
--host 0.0.0.0 \
--port 8081
3. Python 调用(上传图片提问)
from openai import OpenAI
client = OpenAI(
api_key="dummy",
base_url="http://localhost:8081/v1"
)
resp = client.chat.completions.create(
model="vl",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "图片里有什么?"},
{"type": "image_url", "image_url": {"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/4/48/Volkswagen_Golf_Mk7_2014.jpg/640px-Volkswagen_Golf_Mk7_2014.jpg"}}
]
}
]
)
print(resp.choices[0].message.content)
支持:
- 图片识别
- OCR 文字提取
- 图表理解
- 简单逻辑问答
三、你以后必用的 3 条万能命令
1. 7B 模型 API
./bin/llama-server -m ../../models/qwen2.5-7b-instruct-q4_k_m.gguf -c 8192 -ngl 99 --host 0.0.0.0 --port 8080
2. 图文模型 API
./bin/llama-server -m ../../models/minicpm-v-2_0.q4_k.gguf --mmproj ../../models/mmproj-minicpm-v-2_0-f16.gguf -c 4092 -ngl 99 --port 8081
3. 1.5B 轻量模型 API
./bin/llama-server -m ../../models/qwen2.5-1.5b-instruct-q4_k_m.gguf -c 4096 -ngl 35 --port 8082
四、我再帮你理清楚你现在掌握的所有工具(终极总结)
本地部署
- ollama = 最简单开箱即用
- llama.cpp = 最灵活、性能最强
- vLLM = 高并发生产级
训练
- LLaMA Factory = 微调模型
应用
- Dify = 做 AI 应用
- RAGFlow = 做文档知识库
模型格式
- GGUF = llama.cpp / ollama
- Safetensors / Bin = vLLM / 训练
llama.cpp 部署 Qwen2.5-VL-3B 完整教程
(含:模型下载、命令行聊天/看图、网页访问、Python API 调用)
一、模型说明(必须下载 2 个文件)
模型:Qwen2.5-VL-3B-Instruct-GGUF(最小可用视觉大模型)
下载地址(ModelScope 中文网页):
https://www.modelscope.cn/models/qwen/Qwen2.5-VL-3B-Instruct-GGUF/files
需下载文件:
qwen2.5-vl-3b-instruct-q4_k_m.gguf(主模型)mmproj-qwen2.5-vl-3b-instruct-f16.gguf(视觉编码器)
放置路径:
llama.cpp/models/
├── qwen2.5-vl-3b-instruct-q4_k_m.gguf
└── mmproj-qwen2.5-vl-3b-instruct-f16.gguf
二、启动方式(3 种任选)
进入目录:
cd /home/dh/llama.cpp
1. 网页界面(最易用,支持上传图片)
./build/bin/llama-server \
-m models/qwen2.5-vl-3b-instruct-q4_k_m.gguf \
--mmproj models/mmproj-qwen2.5-vl-3b-instruct-f16.gguf \
-c 4096 \
-ngl 99 \
--port 8080
访问:http://localhost:8080
2. 命令行聊天 + 看图(无界面)
./build/bin/llama-cli \
-m models/qwen2.5-vl-3b-instruct-q4_k_m.gguf \
--mmproj models/mmproj-qwen2.5-vl-3b-instruct-f16.gguf \
-c 4096 \
-ngl 99 \
-i
看图提问格式:
/home/dh/test.jpg 图片里有什么?
3. 仅命令行纯文本聊天(不带视觉)
./build/bin/llama-cli \
-m models/qwen2.5-vl-3b-instruct-q4_k_m.gguf \
-c 4096 \
-ngl 99 \
-i
三、Python 代码调用(API 形式)
先启动 llama-server,再运行 Python:
import base64
from openai import OpenAI
# 本地图片路径
IMAGE_PATH = "/home/dh/2.jpg"
# 读取图片并转 base64
with open(IMAGE_PATH, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
client = OpenAI(
api_key="dummy",
base_url="http://localhost:8080/v1"
)
# 发送请求(正确格式!)
resp = client.chat.completions.create(
model="vl",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图片"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{base64_image}" # ✅ 必须是 base64
}}
]
}
]
)
print("图片识别结果:")
print(resp.choices[0].message.content)
四、常见说明
- 没有 main 文件:新版 llama.cpp 用
llama-cli替代 main - -ngl 99:全部层加载到 GPU(你的 4070Ti 可直接用)
- 视觉模型必须带 --mmproj,否则无法看图
- 网页和 API 不能同时用,需单独启动对应服务

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)