开源的本地大语言模型运行框架Ollama
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
Ollama 提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
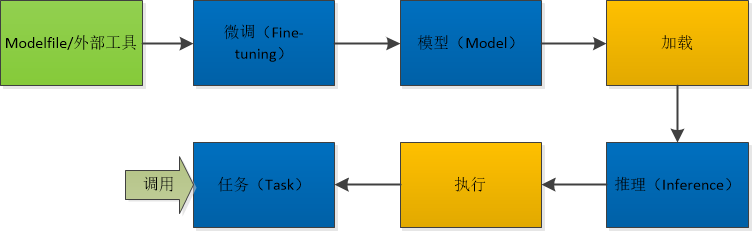
01 基本概念
-
模型(Model)
模型是AI核心组成部分,它们是经过预训练的机器学习模型,能够执行不同的任务,例如文本生成、文本摘要、情感分析、对话生成等。
Ollama 中的模型指已封装好的大语言模型文件(如 Llama 3、Mistral、Gemma 等),包含预训练的权重、架构和推理逻辑。
ollama pull llama3 # 下载模型ollama list # 查看本地模型列表ollama rm mistral # 删除模型
支持的模型可以通过链接查看https://ollama.com/search
-
任务(Task)
任务指用户要求模型执行的具体操作。Ollama 通过 API 或命令行接收任务请求并返回结果。主要包括以下几种常见任务类型:
-
对话生成(Chat Generation):通过与用户交互生成自然的对话回复。
-
文本生成(Text Generation):根据给定的提示生成自然语言文本,例如写文章、生成故事等。
-
情感分析(Sentiment Analysis):分析给定文本的情感倾向(如正面、负面、中立)。
-
文本摘要(Text Summarization):将长文本压缩为简洁的摘要。
-
翻译(Translation):将文本从一种语言翻译成另一种语言
例如可以通过如下对ollama 发起一个任务
curl http://localhost:11434/api/generate -d '{"model": "llama3","prompt": "写一首关于夏天的诗","stream": false}'
-
推理(Inference)
推理是模型根据输入数据(如提示词)生成输出的计算过程,Ollama 在本地完成推理,无需依赖云端。ollama 命令行工具或 API,使用户可以快速向模型提供输入并获取结果。
import ollamaresponse = ollama.generate(model="llama3",prompt="解释神经网络",stream=False)print(response["response"])
过程一般包括:输入->模型处理->输出
-
微调(Fine-tuning)
在 Ollama 中,微调指基于现有模型进一步训练,使其适应特定领域或任务(如医疗问答、法律文本生成)。
Ollama 支持微调功能,用户可以使用自己的数据集对预训练模型进行微调,来定制模型。微调过程一般包括下面几个步骤:
-
数据准备:
数据格式可以是:文本文件(.txt);JSON 文件和CSV文件
去除噪声、标准化格式。
按比例拆分训练集/验证集(如 80%/20%)
-
模型选择
选择一个适合微调的预训练模型,例如通用任务:llama3、mistral;对话任务:llama3-chat、zephyr
下载预训练模型(如 Llama3)ollama pull llama3;验证模型是否加载成功ollama list
-
训练配置
使用 Modelfile(轻量微调)
使用 LoRA/PEFT(深度微调)
通过ollama create my-doctor -f Modelfile 类似命令构建自定义模型。
-
部署应用
构建完成后通过ollama list可以查看自定义模型
# 启动 Ollama 服务ollama serve# 调用微调后的模型curl http://localhost:11434/api/generate -d '{"model": "my-doctor","prompt": "头痛怎么办?"}'
-
其他概念
-
API 服务
提供 RESTful 接口(默认端口 11434),兼容 OpenAI 格式,方便集成到应用。
支持 /generate、/chat、/embeddings 等端点。
-
模型库(Library)
官方托管常用模型(如 library/llama3),支持一键下载。
社区可共享自定义模型(需注册推送)。
-
量化(Quantization)
通过降低模型精度(如 4-bit)减少资源占用,平衡性能与效率。
示例:ollama pull llama3:8b-q4_0
02 Ollama安装
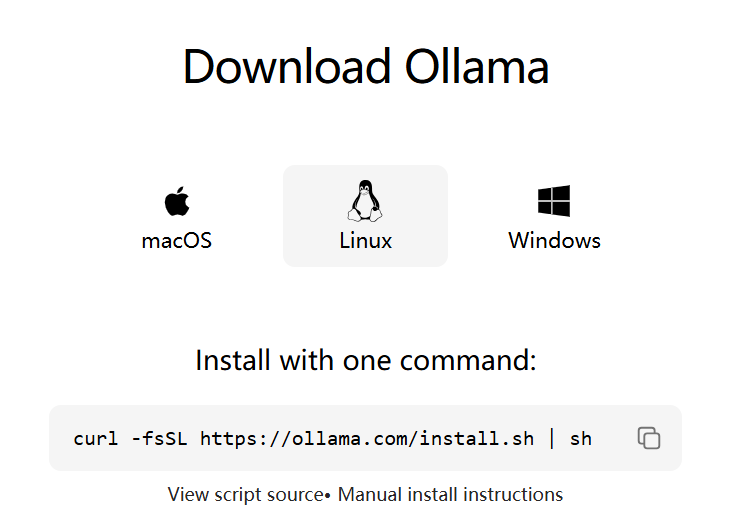
Ollama的安装非常简单,打开官网链接https://ollama.com/download
-
mac和windows分别下载安装包安装
-
linux上执行下面命令安装
curl -fsSL https://ollama.com/install.sh | sh
安装完成后执行如下命令,如果显示版本号,说明安装成功:
ollama --version
官方 Docker 镜像 ollama/ollama 可在 Docker Hub 上获取
https://hub.docker.com/r/ollama/ollama
拉取 Docker 镜像:
docker pull ollama/ollama
运行容器:
docker run -p 11434:11434 ollama/ollama
运行完后访问http://localhost:11434即可使用Ollama
03 Ollama运行和使用
Ollama是一个开源LLM工具,只有在其上部署和运行模型才能使其发挥作用,
Ollama安装完成后,是通过命令来管理和加载模型的,主要的命令如下:
|
命令 |
功能 |
示例 |
|
ollama run <模型名> |
运行指定模型(若本地不存在,自动下载) |
ollama run llama3 |
|
ollama pull <模型名> |
下载模型但不运行 |
ollama pull mistral |
|
ollama list |
列出已安装的模型 |
ollama list |
|
ollama rm <模型名> |
删除本地模型 |
ollama rm llama2 |
|
ollama serve |
启动本地 API 服务(默认端口 11434) |
ollama serve |
|
ollama create <自定义模型名> |
通过 Modelfile 创建自定义模型 |
ollama create my-model -f ./Modelfile |
|
ollama show <模型名> |
显示模型详细信息(参数、模板等) |
ollama show llama3 |
|
ollama copy <源模型> <目标模型> |
复制模型(用于创建副本或重命名) |
ollama copy llama3 my-llama3 |
|
ollama help |
查看帮助文档 |
ollama help |
ollama run 命令
ollama run llama3.2(假设本地没有 llama3.2 模型),Ollama 会先自动从官方仓库下载模型,下载完成后立即启动交互对话。效果等同于先执行 ollama pull llama3.2,再执行 ollama run llama3.2。
使用方式一般有下面几种
-
命令行交互
# 运行模型(自动下载若不存在)ollama run llama3# 直接输入问题交互>>> 你好,你是谁?
echo "你是谁?" | ollama run deepseek-coderollama run deepseek-coder "Python 的 hello world 代码?"-
API调用
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-coder","prompt": "你好,你能帮我写一段代码吗?","stream": false}'
stream代表的是是否流式响应。
-
Python调用
首选需要安装pip install ollama,然后还要保证服务器上 Ollama 本地服务已经启动,如果没有启动需要通过ollama serve命令启动。下面是两个调用的例子:
from ollama import chatstream = chat(model='llama3.2',messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],stream=True,)for chunk in stream:print(chunk['message']['content'], end='', flush=True)
from ollama import Clientclient = Client(host='http://localhost:11434',headers={'x-some-header': 'some-value'})response = client.chat(model='llama3.2', messages=[{'role': 'user','content': 'Why is the sky blue?',},])
更多细节可参考:https://github.com/ollama/ollama-python
-
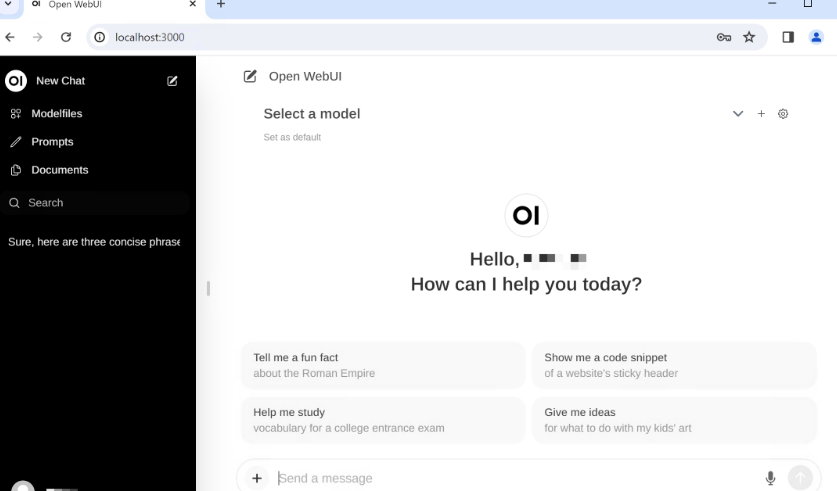
Open WebUI
Ollama Open WebUI 是一个基于网页的用户界面,用于与本地运行的 Ollama 大语言模型(如 Llama 3、Mistral 等)交互。它提供了类似 ChatGPT 的聊天界面,支持多模型切换、对话历史管理、Markdown 渲染等功能,适合不熟悉命令行的用户直观操作。
安装方式有docker, python,脚本等多种安装方式,例如docker安装如下:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main如果webui和ollama没在一台服务上,使用如下命令,其中OLLAMA_BASE_URL 更改为ollama服务器的 URL。
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main安装完成后可以通过 http://localhost:3000访问,注册登录。
https://docs.openwebui.com/
https://github.com/open-webui/open-webui

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)