小白学习:ragas评估rag系统好坏
课程链接。
·
Ragas是什么
ragas是一个用于评估RAG系统的框架,它允许在不依赖人工注释的情况下,通过一套指标评估检索模块和生成模块评估RAG系统的性能和生成质量。
评估数据集:
Question
Answer(大语言模型生成答案)
Contexts(检索到的上下文)
Ground_Truths(标准答案)
评估指标:
Faithfulness(忠诚度)
Answer Relevance(答案相关性)
Context Precision(上下文精确度)
Context Recall(上下文召回率)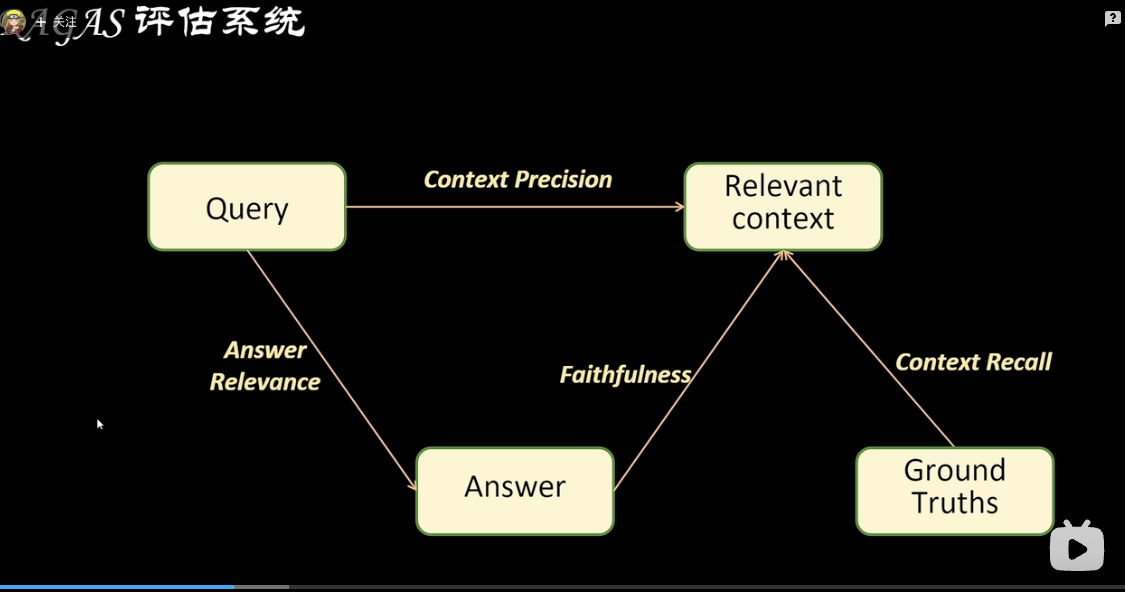
每个指标代表含义:
Faithfulness(忠诚度)
评估大模型生成answer和检索到的上下文之间的相关度,答案的评分在0-1之间,分数越高越好
计算逻辑:根据答案和检索到的上下文来计算。把生成答案分成n个陈述句,检索陈述句们是否都在检索到的相关上下文中,都在则为1,都不在,则为0。
例: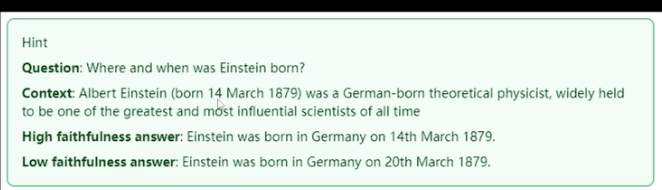
Answer Relevance(答案相关性)
评估生成答案与给定提示的相关程度
计算逻辑:根据问题和答案来计算。基于答案去生成n个问题,将生成的问题和原来的问题做余弦相似度平均,验证答案是否不完整或包含冗余信息。其值在0-1之间,得分越高,相关性越好
Context Precision(上下文精确度)
上下文精确度衡量上下文中所有相关的真实信息是否被排在了较高的位置。
计算逻辑:根据问题和上下文来计算。
Context Recall(上下文召回率)
检索到的上下文和被视为真实事实的标准答案的一直程度。
计算逻辑:根据事实真实和检索到的上下文来计算。真实答案的每个句子是否可以归因于检索到的上下文。
如何综合评判一个系统整体性能
检索器 — 通过升级embedding模型,提高指标
- Context Precision(上下文精确度):评估检索质量
- Context Recall(上下文召回率):衡量检索的完整性
生成器 — 通过升级llm模型,提高指标
- Faithfulness(忠诚度):衡量生成答案中的幻觉情况
- Answer Relevance(答案相关性):衡量答案对问题的直接性(紧扣问题的核心)

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)