RAG和transformers的关系
这样的预训练生成模型。RAG 不同于传统的生成模型(如 GPT 系列),它通过检索外部信息来增强生成的内容,因此模型的生成过程不仅依赖于模型本身的知识,还依赖于从外部数据库或文档库中检索到的相关信息。:RAG 使用了 Transformer 作为生成模块的核心架构,同时结合检索器来提供外部知识,从而增强 Transformer 在面对需要领域知识的任务时的表现。:传统的 Transformer 模
RAG(Retrieval-Augmented Generation)和 Transformers 是两个紧密相关但不同的概念,它们在自然语言处理(NLP)中通常会协同工作,以提升生成模型的性能,特别是在处理需要外部知识的任务时。下面,我将详细解释它们之间的关系。
1. Transformers:基础架构
Transformer 是一种深度学习模型架构,首次由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它在 NLP 中取得了巨大成功,并成为了现代语言模型(如 GPT、BERT、T5、BLOOM 等)的基础架构。
核心组件:Transformers 使用了 自注意力机制(Self-Attention),它能够有效捕捉文本中不同位置的依赖关系,无论这些位置之间的距离有多远。这使得 Transformer 模型特别适合处理长距离依赖的语言任务。
Transformer 的优势:由于自注意力机制,Transformer 不像 RNN 或 LSTM 那样需要按顺序处理输入,可以并行化处理,因此在训练效率和处理长文本方面具有优势。
Transformers 的核心特点:
- Encoder-Decoder 结构:原始的 Transformer 模型包括编码器(Encoder)和解码器(Decoder)两部分,编码器处理输入的文本,解码器生成输出。
- 自注意力机制:每个词的表示都可以通过注意力机制与其他词的信息进行交互,增强了上下文理解能力。

2. RAG(Retrieval-Augmented Generation)模型
RAG(检索增强生成)是一种结合了 信息检索 和 生成模型 的架构。其核心思想是在生成任务中加入外部知识,以补充语言模型的知识库,从而使生成的结果更加准确和丰富。
RAG 模型的主要流程是:
- 检索阶段:模型首先从一个外部知识库中检索相关的文档或信息片段。
- 生成阶段:模型将检索到的相关信息与输入的文本一起,作为生成模型的上下文输入,生成最终的输出。
RAG 模型使用了 Transformer 架构的生成部分,通常是基于类似 BART 或 T5 的结构,结合了 检索(retrieval)部分来增强生成能力。
RAG 的工作流程:
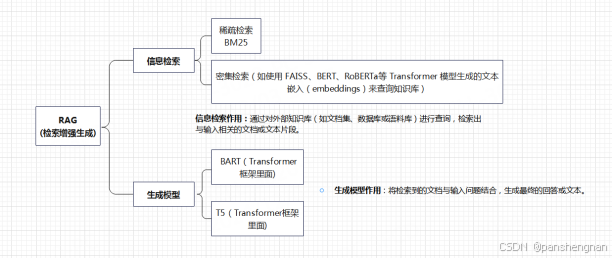
- 检索模块:通过对外部知识库(如文档集、数据库或语料库)进行查询,检索出与输入相关的文档或文本片段。常用的检索方法包括基于 BM25 或 Dense Retrieval(如使用 FAISS)等方法。
- 生成模块:使用 Transformer 模型(如 BART 或 T5)将检索到的文档与输入问题结合,生成最终的回答或文本。
3. RAG 与 Transformer 的关系
Transformer 是基础:RAG 的生成部分通常依赖于 Transformer 架构,特别是 BART 或 T5 这样的预训练生成模型。这些模型使用 Transformer 的编码器-解码器结构进行文本生成。RAG 不同于传统的生成模型(如 GPT 系列),它通过检索外部信息来增强生成的内容,因此模型的生成过程不仅依赖于模型本身的知识,还依赖于从外部数据库或文档库中检索到的相关信息。
融合检索与生成:传统的 Transformer 模型(如 GPT 或 BERT)是单纯的生成或表示模型,它们的知识有限,仅限于模型训练时的数据。而 RAG 在 Transformer 的基础上,加入了 信息检索 机制,这样在进行文本生成时,模型能够动态地从外部获取相关知识。这种方式显著提高了模型在需要领域知识或上下文信息的任务中的表现。
信息检索 +Transformer的生成==》RAG
模型架构:RAG 的架构通常包括两部分:
- 检索器(Retriever):负责从外部文档或知识库中检索相关的信息。常用的检索方法有 BM25 或 密集检索(dense retrieval),后者通常会使用基于 Transformer 的嵌入模型(例如,使用 BERT 来生成文本嵌入)。
- 生成器(Generator):负责使用检索到的信息与原始输入一起,生成最终的输出。这一部分通常使用基于 Transformer 的生成模型,如 BART 或 T5。
4. RAG 与 Transformer 的优势结合
RAG 模型通过引入 检索增强,使得 Transformer 模型能够在处理 开放域问题(如问答系统)时获得更好的性能。传统的 Transformer 模型(如 GPT 或 BERT)虽然在理解和生成文本方面表现优异,但它们在一些需要 最新信息 或 领域知识 的任务中可能表现不佳。通过结合检索,RAG 使得模型能够在 外部知识库 中进行检索,解决了知识过时或有限的问题。
灵活性和精确度:RAG 允许模型根据实际需要检索相关信息,这种方式使得模型在面对动态和不断变化的知识时能更加灵活,提供更加精准的答案。
多模态和跨领域应用:通过结合多种信息源(文本、数据库、API 等),RAG 在多模态任务和跨领域问题中表现出色。例如,图像问答、医学文献问答等领域,都可以通过检索增强生成来提升模型的效果。
总结
Transformer 是一种基础架构,广泛应用于 NLP 中的各种任务(如生成、分类、翻译等),通过自注意力机制捕捉文本中的长距离依赖。
RAG 是一个将 信息检索 和 生成 结合的模型,在生成过程中引入了 检索模块,使得模型能够从外部知识库中获取动态信息,增强生成的准确性和丰富度。
关系:RAG 使用了 Transformer 作为生成模块的核心架构,同时结合检索器来提供外部知识,从而增强 Transformer 在面对需要领域知识的任务时的表现。
简而言之,RAG 是基于 Transformer 的生成模型,通过在生成过程中加入检索机制,增强了模型在复杂任务中的表现。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)