AIGC学习笔记(8)——AI大模型开发工程师
LangChain于8月1日0.254版本更新,声称采用新的语法来创建带有组合功能的Chain,同时提供一个新的接口,支持批处理、异步和流处理,将这种语法称为LangChain Expression Language(LCEL)
·
文章目录
AI大模型开发工程师
007 LangChain之Model IO模块
1 Model IO核心概念
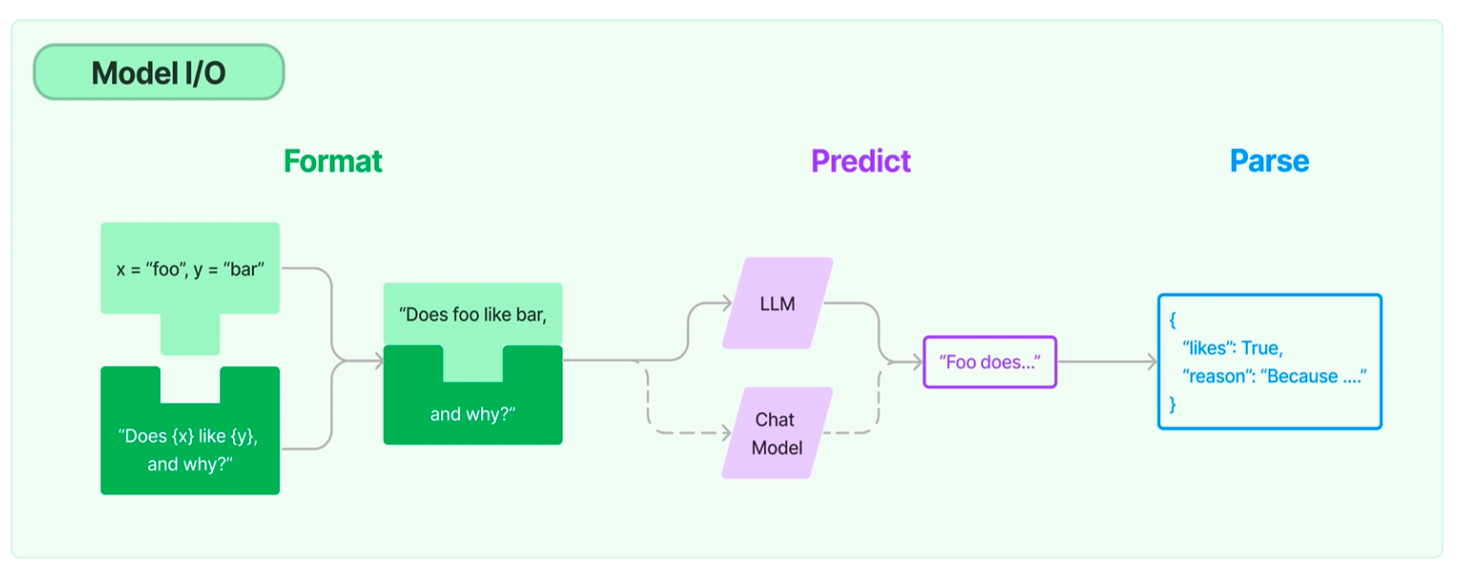
- Prompts:提示词
- Language models:大语言模型
- Output parsers:输出解析
2 Model IO代码实战
## 导入依赖库
!pip install langchain
什么是LCEL?
- LangChain于8月1日0.254版本更新,声称采用新的语法来创建带有组合功能的Chain,同时提供一个新的接口,支持批处理、异步和流处理,将这种语法称为LangChain Expression Language(LCEL)
Model
Model的分类
- LLMs:LangChain 的核心组件。LangChain并不提供自己的LLMs,而是为与许多不同的LLMs(OpenAI、Cohere、Hugging Face等)进行交互提供了一个标准 接口。(类似于Completion)
- Chat Models:语言模型的一种变体。虽然聊天模型在内部使用了语言模型,但它们提供的接口略有不同。与其暴露一个“输入文本,输出文本”的API不同, 它们提供了一个以“聊天消息”作为输入和输出的接口。(类似于Chat Completion)
LLMs
- 文档地址:https://python.langchain.com/docs/how_to/#llms
from langchain.llms import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo")
llm.invoke("什么是机器学习?")
llm("什么是大模型")
注意:在新版API中,这种方式已过时
ChatModel
- 文档地址:https://python.langchain.com/docs/how_to/#chat-models
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-3.5-turbo")
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
messages = [SystemMessage(content="你是一个智能助手"),
HumanMessage(content="第二十一届世界杯在哪儿举行的?"),
AIMessage(content="在俄罗斯"),
HumanMessage(content="冠军是哪个球队")]

Prompt
一个语言模型的提示是用户提供的一组指令或输入,用于引导模型的响应,帮助它理解上下文并生成相关和连贯的基于语言的输出,例如回答问题、完成句子或进行对话。
- 提示模板(Prompt Templates):参数化的模型输入
- 示例选择器(Example Selectors):动态选择要包含在提示中的示例
Prompt templates
use PromptTemplate
## 可以动态传入参数
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
## 也可以不传参数
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke")
prompt_template.format()
chat_model.invoke(prompt_template.format()).content
use ChatPromptTemplate
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
chat_model.invoke(messages)

Few-shot prompt templates
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "穆罕默德·阿里(Muhammad Ali)和艾伦·图灵(Alan Turing)中哪个活得更长?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:穆罕默德·阿里去世时多少岁?
中间答案:穆罕默德·阿里去世时74岁。
后续问题:艾伦·图灵去世时多少岁?
中间答案:艾伦·图灵去世时41岁。
因此最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是何时出生的?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:craigslist的创始人是谁?
中间答案:craigslist的创始人是Craig Newmark。
后续问题:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
因此最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿(George Washington)的母亲的母亲父亲是谁?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿(Mary Ball Washington)。
后续问题:玛丽·鲍尔·华盛顿的父亲是谁?
中间答案:玛丽·鲍尔·华盛顿的父亲是约瑟夫·鲍尔(Joseph Ball)。
因此最终答案是:约瑟夫·鲍尔
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是史蒂文·斯皮尔伯格(Steven Spielberg)。
后续问题:史蒂文·斯皮尔伯格来自哪里?
中间答案:美国。
后续问题:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是马丁·坎贝尔(Martin Campbell)。
后续问题:马丁·坎贝尔来自哪里?
中间答案:新西兰。
因此最终答案是:不是
"""
}
]
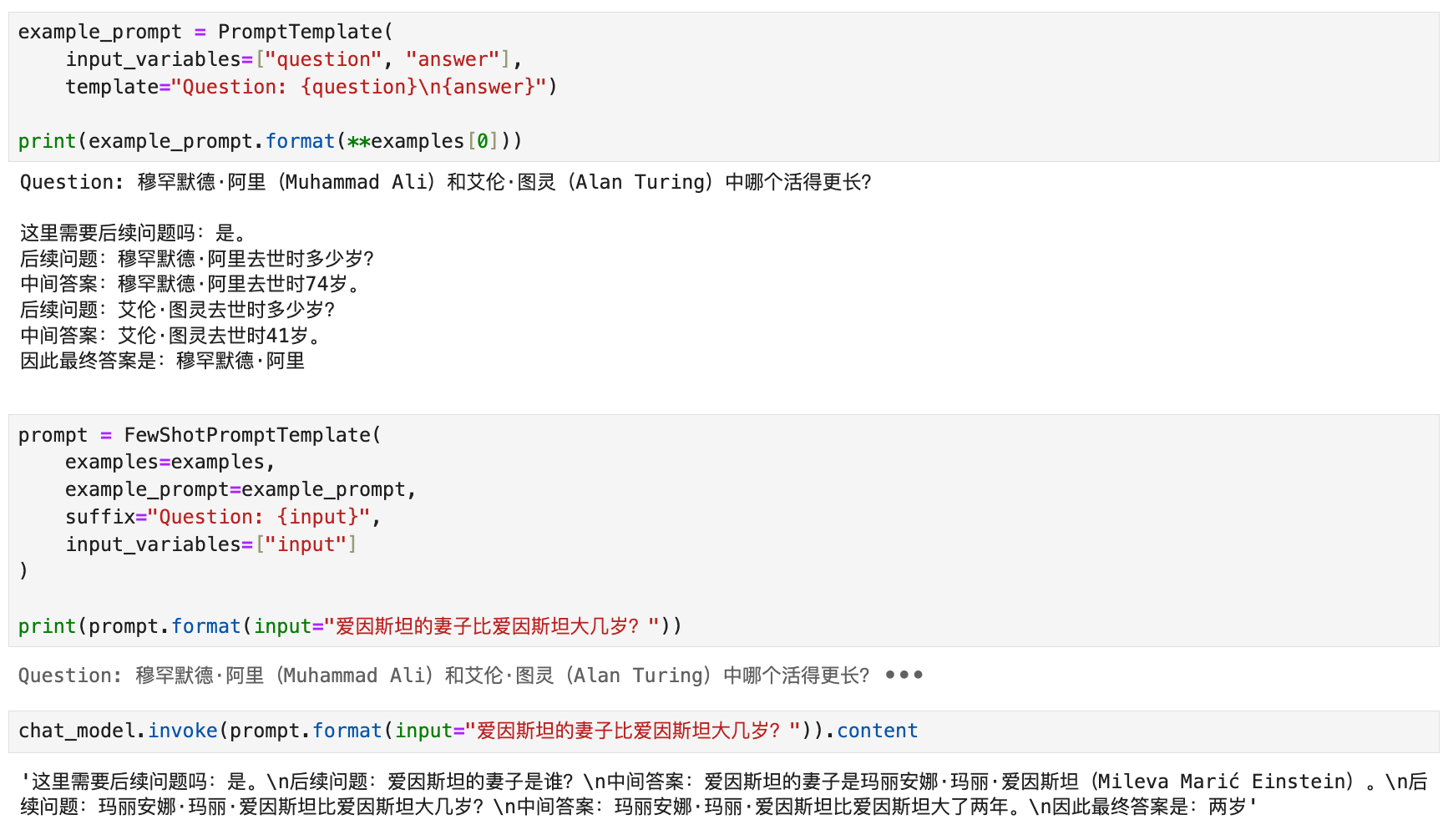
Example selectors
长度选择器
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
example_prompt=example_prompt,
# The maximum length that the formatted examples should be.
# Length is measured by the get_text_length function below.
max_length=25,
# The function used to get the length of a string, which is used
# to determine which examples to include. It is commented out because
# it is provided as a default value if none is specified.
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
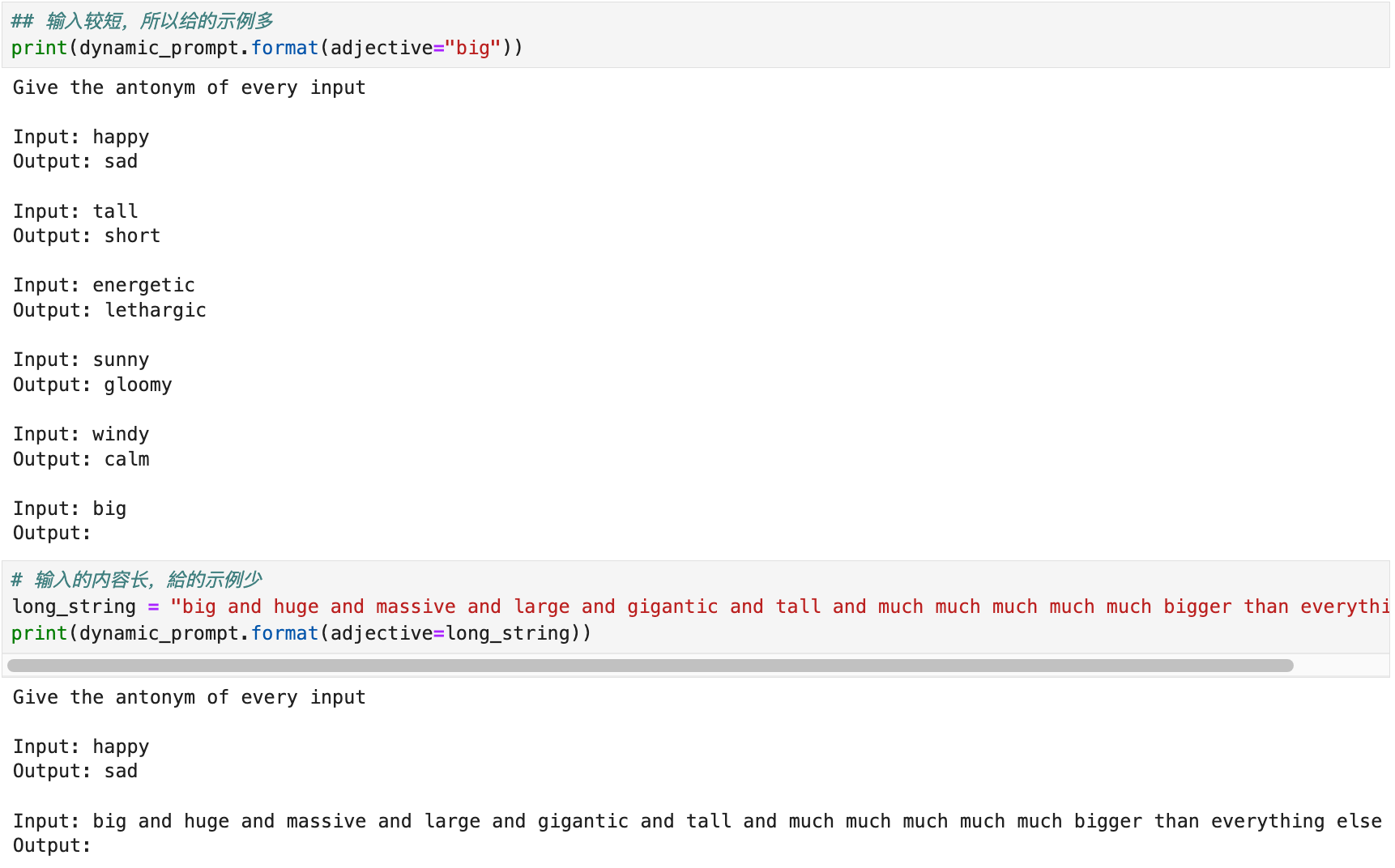
- 官方文档:https://python.langchain.com/docs/how_to/#example-selectors
Output parsers
- 语言模型输出文本。但是很多时候,你可能希望获得比纯文本更结构化的信息。这就是输出解析器的用处。
- 输出解析器是帮助结构化语言模型响应的类。一个输出解析器必须实现两个主要方法:
- 获取格式指令:返回一个包含语言模型输出应如何格式化的字符串的方法。
- 解析:接受一个字符串(假设是语言模型的响应)并将其解析为某种结构的方法。
- 然后还有一个可选的方法:
- 带提示解析:接受一个字符串(假设是语言模型的响应)和一个提示(假设是生成此响应的提示),并将其解析为某种结构。提示主要是在 OutputParser 希望以某种方式重试或修复输出时提供的,它需要来自提示的信息来执行这些操作。
List parser:返回以逗号分隔的列表
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
model = OpenAI(model_name="gpt-3.5-turbo")
parser = CommaSeparatedListOutputParser()
format_instructions = parser.get_format_instructions()
## LCEL
chain = prompt | model | parser
chain.invoke({"subject": "ice cream flavors"})

- 官方文档:https://python.langchain.com/docs/how_to/#output-parsers

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)