如何构建高效智能体:一文读懂Anthropic的《Building effective agents》
在这篇文章中,我们分享了从与客户合作以及自己构建智能体(Agents)中学到的东西,并为开发人员提供了构建高效智能体(Agents)的实用建议。
Building effective agents
https://www.anthropic.com/research/building-effective-agents
在过去的一年里,我们与数十个跨行业的团队合作,构建大型语言模型(LLM)智能体(Agents)。我们发现,最成功的应用案例并非依赖于复杂的框架或专门的库,而是使用简单、可组合的模式进行构建的。
在这篇文章中,我们分享了从与客户合作以及自己构建智能体(Agents)中学到的东西,并为开发人员提供了构建高效智能体(Agents)的实用建议。
- What is Agent?
“Agent”的定义多种多样。一些客户将Agent定义为完全自主的系统,能够在较长时间内独立运行,利用各种工具来完成复杂的任务。另一些客户则用这个术语来描述更具规范性的实现,即遵循预定义的工作流程。在 Anthropic,我们将所有这些变体都归类为“Agentic Systems”,但对工作流(Workflows)和智能体(Agents)进行了重要的架构区分。
工作流(Workflows)是一种通过预定义的代码路径对大语言模型(LLM)和工具(Tools)进行编排的系统。
智能体(Agents)则是一种大型语言模型(LLM)动态指导自身流程和工具使用的系统,自己掌控着完成任务的方式。
下面,我们将详细探讨这两种类型的智能体系统。在附录 1(“Agents in practice”)中,我们将描述客户发现使用这类系统特别有价值的两个领域。
在使用大语言模型构建应用程序时,我们建议找到尽可能简单的解决方案,仅在必要时才增加其复杂性,这可能意味着根本不需要构建具有智能体系统。智能体系统通常会以延迟和成本为代价来换取更好的任务性能,你应该考虑这种权衡何时具有意义。
当需要更高的复杂性时,工作流可为明确定义的任务提供可预测性和一致性,而当大规模需要灵活性和模型驱动的决策时,智能体是更好的选择。然而,对于许多应用程序来说,通过检索和上下文示例优化单个大型语言模型调用通常就足够了。
在本节中,我们将探讨在生产环境中智能体系统常见的构建模式。我们将从基础构建模块——增强型大语言模型开始,并逐步增加复杂性,从简单的组合工作流到自主的智能体。
智能体系统的基本构建模块是一个通过检索、工具和记忆等增强功能进行强化的大型语言模型。我们当前的模型可以主动地调用这些能力——生成自己的搜索查询、选择合适的工具,并决定要保留哪些信息。

我们建议在实现时重点关注两个方面:根据您特定的使用场景调整这些能力,并确保它们为您的大型语言模型提供一个简单且文档完善的接口。虽然有很多方法可以实现这些增强功能,但一种方法是通过我们最近发布的
Model Context Protocol
https://www.anthropic.com/news/model-context-protocol
它允许开发人员通过实现一个简单的客户端,就能与不断增长的第三方工具生态系统集成。
在本文的其余部分,我们将假设每次调用大型语言模型都可以访问这些增强功能。
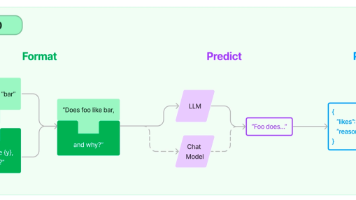
Prompt chaining将一个任务分解为一系列步骤,其中每个 LLM 都会处理前一步的输出。你可以在任何中间步骤添加程序化的检查(见下图中的“Gate”),以确保整个流程仍在正确的轨道上。

**何时使用这种工作流:**这种工作流适用于可以轻松、清晰地分解为固定子任务的情况。主要目标是通过使每个 LLM 调用成为更简单的任务,以延迟为代价换取更高的准确性。
Prompt chaining的实用场景:
- 生成营销文案,然后将其翻译成另一种语言。
- 撰写文档大纲,检查大纲是否符合特定标准,然后根据大纲撰写文档。
Routing对输入进行分类并将其引导至专门的后续任务。这种工作流程允许关注点分离,并构建更专门的提示。如果没有这种工作流程,针对一种输入进行优化可能会损害对其他输入的性能。

**何时使用这种工作流:**对于复杂任务,路由很有效,在这些任务中,存在不同的类别,最好分别处理,并且可以通过 LLM 或更传统的分类模型/算法准确地进行分类。
Routing的实用场景:
- 将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导到不同的下游流程、提示和工具中。
- 将简单/常见问题路由到较小的模型,如Claude 3.5 Haiku模型,将困难/不寻常的问题路由到更强大的模型,如Claude 3.5 Sonnet模型,以优化成本和速度。
大型语言模型有时可以同时处理一项任务,并通过编程方式聚合它们的输出。这种工作流程,即并行化,表现为两种关键的变体:
- 分段:将一个任务分成独立的子任务并行运行。
\- 投票:多次运行相同的任务以获得不同的输出。

**何时使用这种工作流:**当划分的子任务可以并行化以提高速度时,或者当需要从多个角度或进行多次尝试以获得更高置信度的结果时,并行化是有效的。对于具有多个考虑因素的复杂任务,通常在每个考虑因素由单独的 LLM 调用处理时,大型语言模型表现得更好,从而可以专注于每个特定方面。
Parallelization的实用场景:
分段(Sectioning):
- 实施防护栏,其中一个模型实例处理用户查询,而另一个模型实例对其进行筛选,以查找不适当的内容或请求。这往往比让同一个大语言模型调用同时处理防护栏和核心响应表现更好。
- 自动化评估以评估大语言模型的性能,其中每个大语言模型调用会评估模型在给定提示下性能的不同方面。
投票(Voting):
- 审查一段代码是否存在漏洞,其中几个不同的提示会在发现问题时审查并标记代码。
- 评估给定内容是否不适当,有多个提示评估不同方面,或者需要不同的投票阈值来平衡误报和漏报。
在Orchestrator-workers工作流中,一个中央大型语言模型动态地分解任务,将它们委派给工作者大型语言模型,并综合它们的结果。

**何时使用这种工作流:**此工作流非常适合复杂的任务,在这些任务中,你无法预测所需的子任务(例如,在编码中,需要更改的文件数量以及每个文件中的更改性质可能取决于任务)。虽然它在拓扑上相似,但与并行化的关键区别在于其灵活性——子任务不是预先定义的,而是由协调器根据特定输入确定的。
Orchestrator-workers的实用场景:
- 对多个文件每次进行复杂更改的编码产品。
- 搜索涉及从多个来源收集和分析信息以查找可能相关信息的任务。
在Evaluator-optimizer工作流中,一个语言模型调用生成一个响应,而另一个在循环中提供评估和反馈。

**何时使用这种工作流:**当我们有明确的评估标准,并且迭代改进能提供可衡量的价值时,此工作流特别有效。良好适配的两个标志是,首先,当人类明确表达他们的反馈时,大型语言模型的响应可以明显得到改善;其次,大型语言模型可以提供这样的反馈。这类似于人类作家在制作精良文档时可能经历的迭代写作过程。
Evaluator-optimizer的实用场景:
- 文学翻译中存在一些细微差别,翻译语言模型可能最初无法捕捉到这些差别,但评估语言模型可以提供有用的批评。
- 复杂的搜索任务需要多轮搜索和分析以收集全面的信息,由评估人员决定是否需要进一步搜索。
随着大型语言模型在关键能力上的成熟——理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复,智能体正在生产中崭露头角。Agents的工作始于人类用户的命令或与之进行的交互式讨论。一旦任务明确,智能体就会独立进行规划和操作,并可能返回向人类寻求更多信息或判断。在执行过程中,智能体在每一步都从环境中获取“真实情况”(例如工具调用结果或代码执行情况)以评估其进展至关重要。然后,智能体可以在检查点或遇到阻碍时暂停以获取人类反馈。任务通常在完成时终止,但通常也会包括停止条件(例如最大迭代次数)以保持控制。
Agents可以处理复杂的任务,但它们的实现通常很直接。它们通常只是基于环境反馈在循环中使用工具的大型语言模型。因此,清晰而周到地设计工具集及其文档至关重要。我们在附录 2(“提示工程你的工具”)中详细阐述了工具开发的最佳实践。

**何时使用Agents:**Agents可用于难以或无法预测所需步骤数量的开放式问题,以及无法硬编码固定路径的情况。大语言模型可能会运行很多轮,并且你必须在一定程度上信任其决策。智能体的自主性使其非常适合在受信任的环境中扩展任务。
Agents的自主性意味着更高的成本和潜在的错误叠加。我们建议在沙箱环境中进行广泛的测试,并设置适当的防护措施。
Agents的实用场景:
\- 一个编码智能体来解决SWE-bench任务,这些任务涉及根据任务描述对许多文件进行编辑。
\- 我们的“computer use”参考实现,其中 Claude 使用计算机来完成任务。

这些构建模块并非规定性的。它们是常见的模式,开发人员可以塑造并组合它们以适应不同的用例。与任何大型语言模型功能一样,成功的关键在于衡量性能并对实现进行迭代。重复一遍:只有当它明显改善结果时,你才应该考虑增加复杂性。
在大语言模型领域取得成功并不在于构建最复杂的系统。而在于为你的需求构建合适的系统。从简单的提示开始,通过全面评估对其进行优化,只有在较简单的解决方案不足时才添加多步骤的智能体系统。
在实现智能体时,我们尝试遵循三个核心原则:
-
Maintain simplicity in your agent’s design.
在你的智能体设计中保持简单性。
-
Prioritize transparency by explicitly showing the agent’s planning steps.
优先考虑透明度,明确展示智能体的规划步骤。
-
Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing.
仔细设计你的智能体-计算机接口(ACI),方法是通过全面的工具文档记录和测试。
框架可以帮助你快速上手,但在转向生产环境时,不要犹豫减少抽象层并使用基本组件进行构建。遵循这些原则,你可以创建不仅强大而且可靠、可维护并受用户信任的智能体。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)