【人工智能agent】--dify通过mcp协议调用工具
现在如果自己写了一个爬虫工具,需要调用到dify工作流或者智能体中如何实现呢直接运行:成功搭建。2.dify调用"url": "http://本机ip:9000/sse",},# }# 设置Edge浏览器选项# try:# print("Edge浏览器启动失败,请检查驱动是否正确安装!")# print(e)"综合": "GANGCAIZONGHE","长材": "CHANGCAI","扁平":
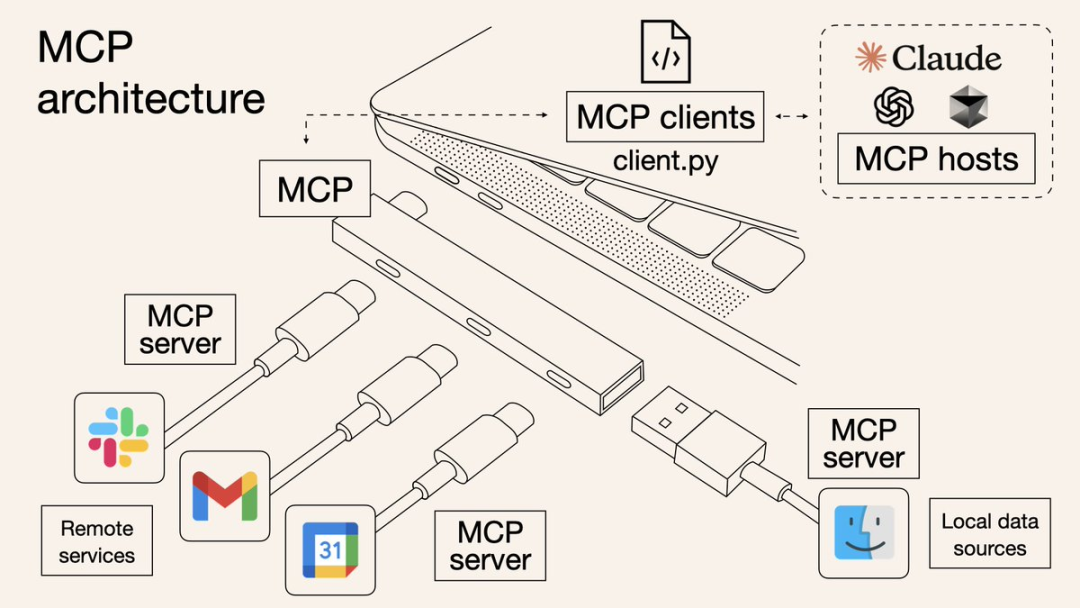
MCP Client
发起工具调用的实体,也就是 Dify 工作流或 Agent。它通过 Dify 平台提供的标准化接口(工具节点)来请求服务。
MCP Server / Host
提供实际服务的端点。在这个例子中,就是模拟 API 服务器 上的各个API (/api/pump/status, /api/cmms/pump/history 等)。这个服务器理解工具调用背后转换成的 HTTP 请求并返回数据。
Dify 平台
扮演着协议转换器、编排器和代理的角色。它接收来自 Client (工作流节点) 的标准化工具调用请求,根据工具的 Schema 定义,将其转换为具体的 HTTP 请求发送给 Server/Host (你的 API),接收响应,再将其作为工具节点的输出返回给工作流。
目录
1.MCP-Server通信服务
以下是MCP(Microcontroller Protocol)中SSE(Server-Sent Events)与STDIO(Standard Input/Output)通信模式的对比
| 特性 | STDIO(标准输入/输出) | SSE(服务器推送事件) |
|---|---|---|
| 通信方向 | 双向(客户端↔服务器) | 单向(服务器→客户端) |
| 传输方式 | 本地进程间通信(通过 stdin/stdout/stderr) |
基于 HTTP 长连接(text/event-stream) |
| 延迟 | 极低(无网络开销) | 依赖网络延迟(需 TCP/IP 握手) |
| 多客户端支持 | 仅单会话(1客户端:1服务器) | 支持多客户端(1服务器:N客户端) |
| 部署复杂度 | 无需网络配置(本地进程直接调用) | 需 HTTP 服务端(如 Nginx、云服务) |
| 安全性 | 高(仅限本地进程) | 需 HTTPS/TLS 加密防中间人攻击 |
| 适用场景 |
|
|
| 扩展性 | 差(依赖本地资源) | 强(支持负载均衡和横向扩展) |
2.Dify调用MCP协议
mcp协议github官网:python-sdk/examples/clients/simple-chatbot/.python-version at main · modelcontextprotocol/python-sdk · GitHub
直接在市场搜索安装插件:
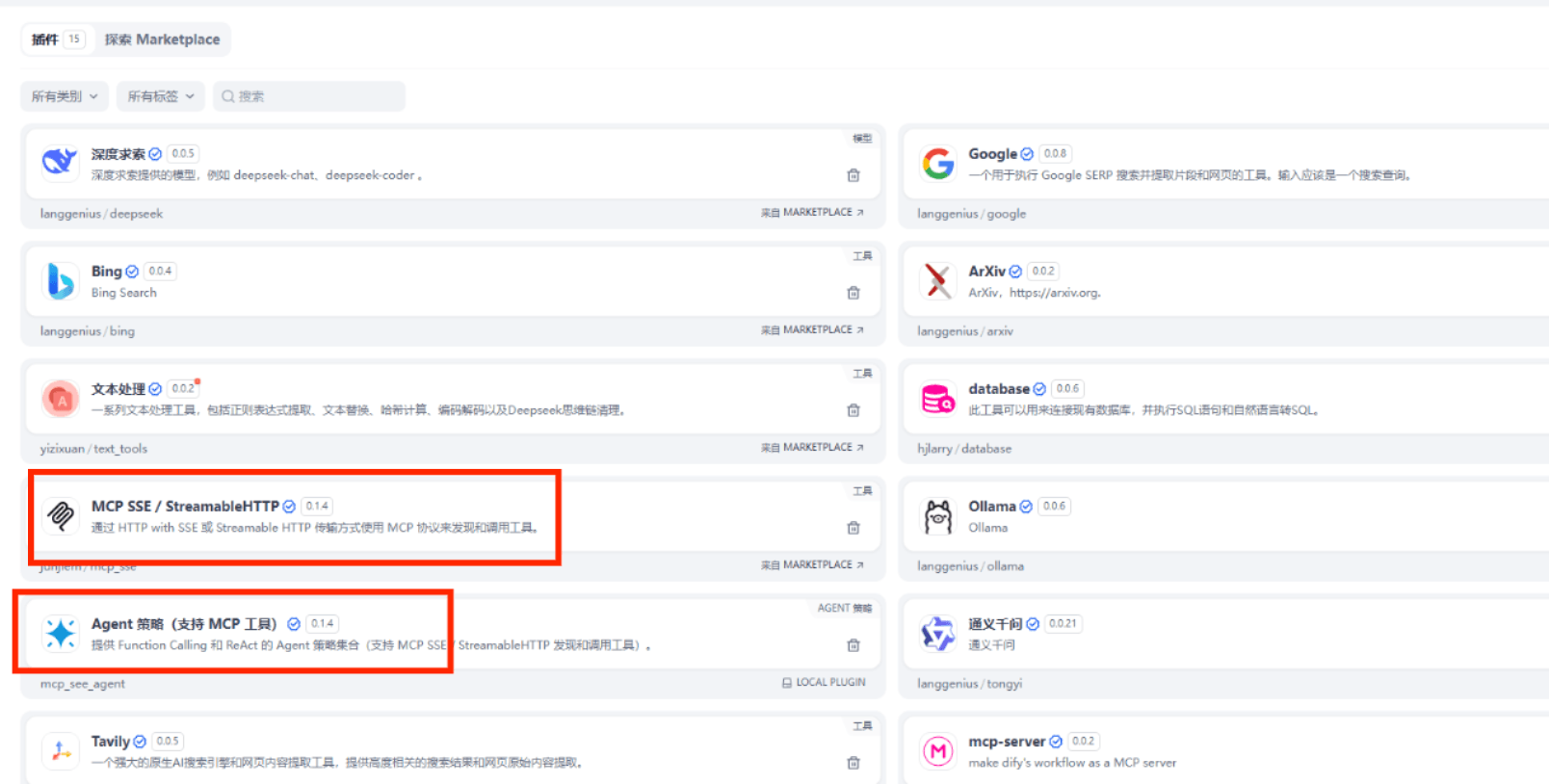
MCP SSE提供两个功能:
- mcp_sse_list_tools:获取工具列表
- mcp_sse_list_tools:调用工具
sse连接工具格式:
{
"server_name1": {
"url": "http://127.0.0.1:8000/sse",
"headers": {},
"timeout": 60,
"sse_read_timeout": 300
},
"server_name2": {
"url": "http://127.0.0.1:8001/sse"
}
}3.案例
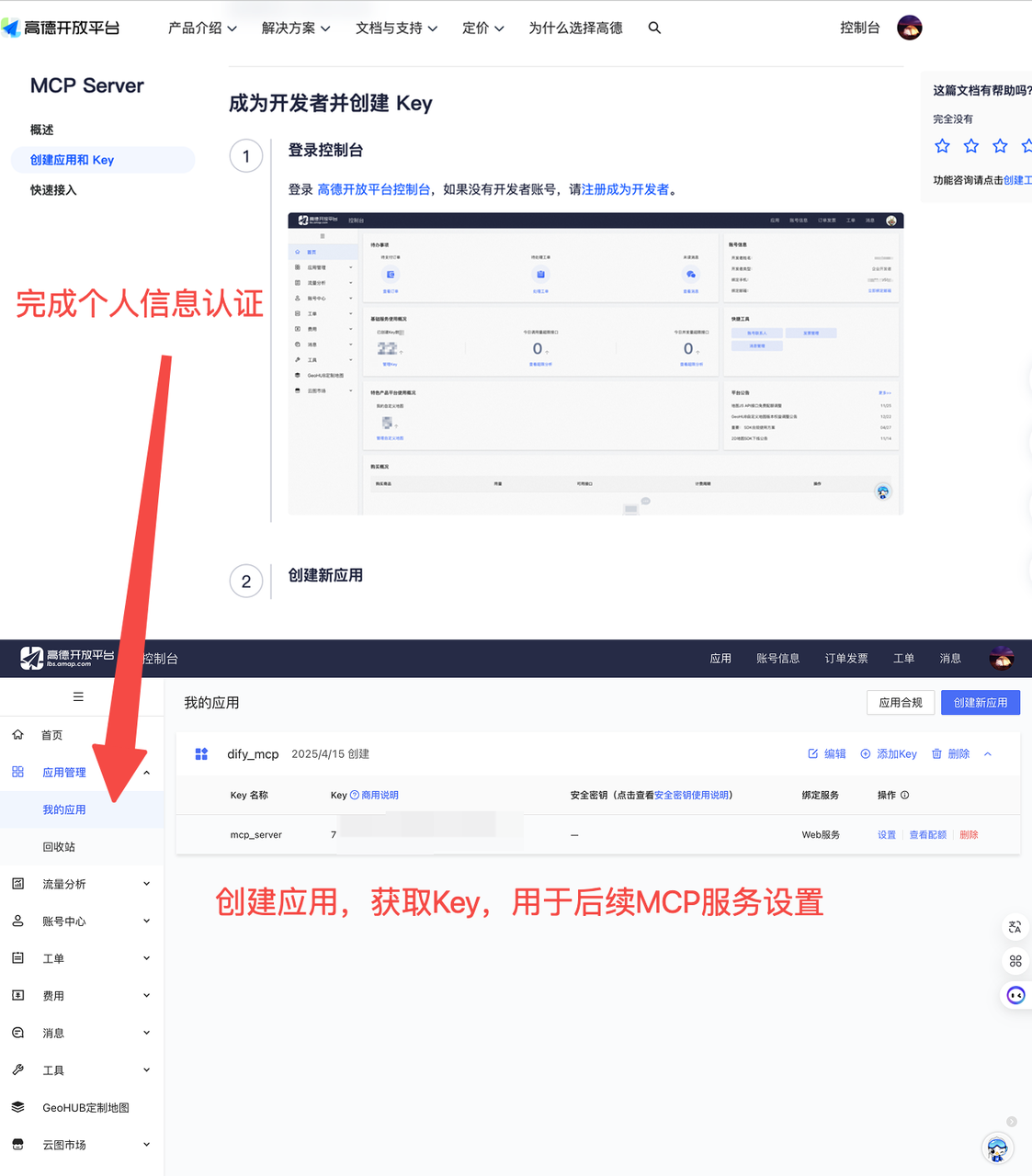
3.1.高德地图MCP服务
进入高德地图开发者后台:注册应用,完成实名认证,获取MCP服务器密钥,用于地图和天气数据调用。
使用教程:快速接入-MCP Server | 高德地图API
dify使用高德地图mcp-server:
{
"server_name1":
{ "url": "https://mcp.amap.com/sse?key=****",
"headers": {},
"timeout": 60,
"sse_read_timeout": 300 }}3.2.Zapier MCP服务
Zapier MCP 是 Zapier 用于支持其自动化工作流(Zaps)的底层微服务通信平台,旨在高效连接不同应用(如 Slack、Google Sheets 等)的 API,实现跨系统的数据流转与自动化触发。其核心目标是降低集成复杂度,提升可扩展性。
可以获取集成7000+应用的MCP Server URL,支持邮件、搜索、CRM等多种操作,极大丰富助手功能。
官网:Get Started - Zapier AI Actions
完成注册之后:
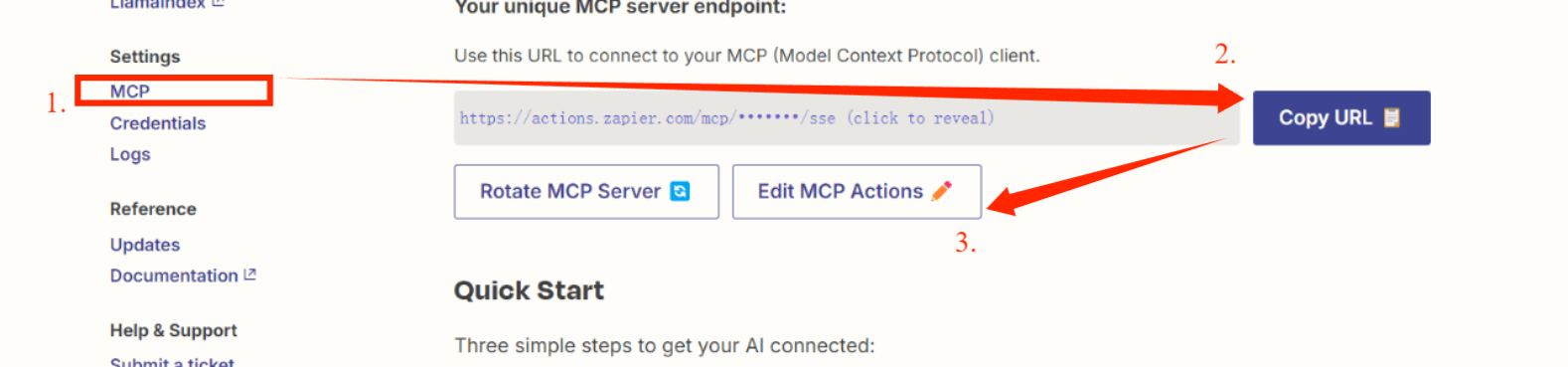
2.复制链接地址后面使用
3.添加mcp工具
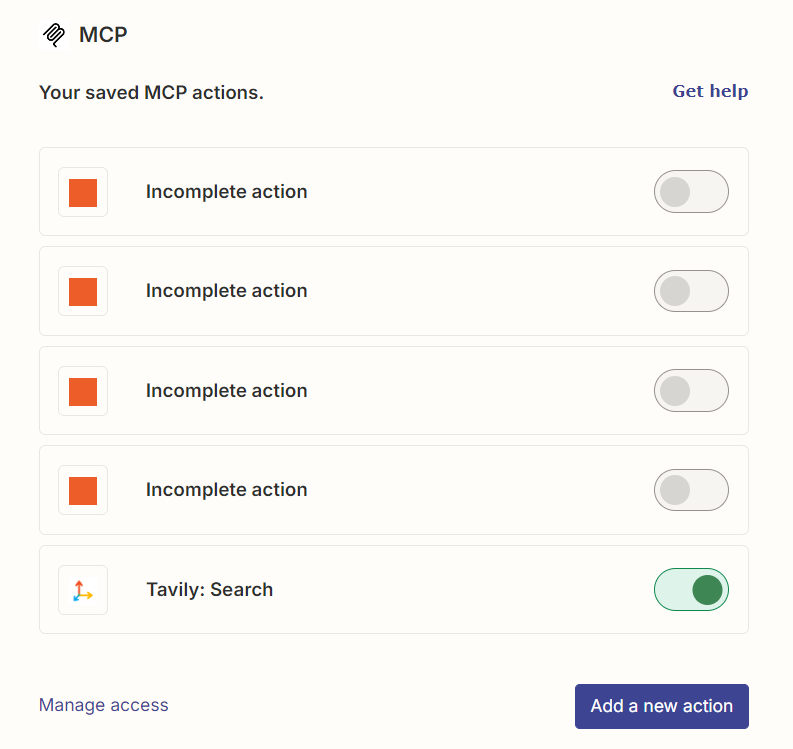
我这里添加注册了一个搜索引擎:Tavily
{
"server_name1":
{ "url": "https://mcp.amap.com/sse?key=***",
"headers": {},
"timeout": 60,
"sse_read_timeout": 300 },
"server_name2":
{ "url": "刚才的链接"}}添加到mcp服务配置中:
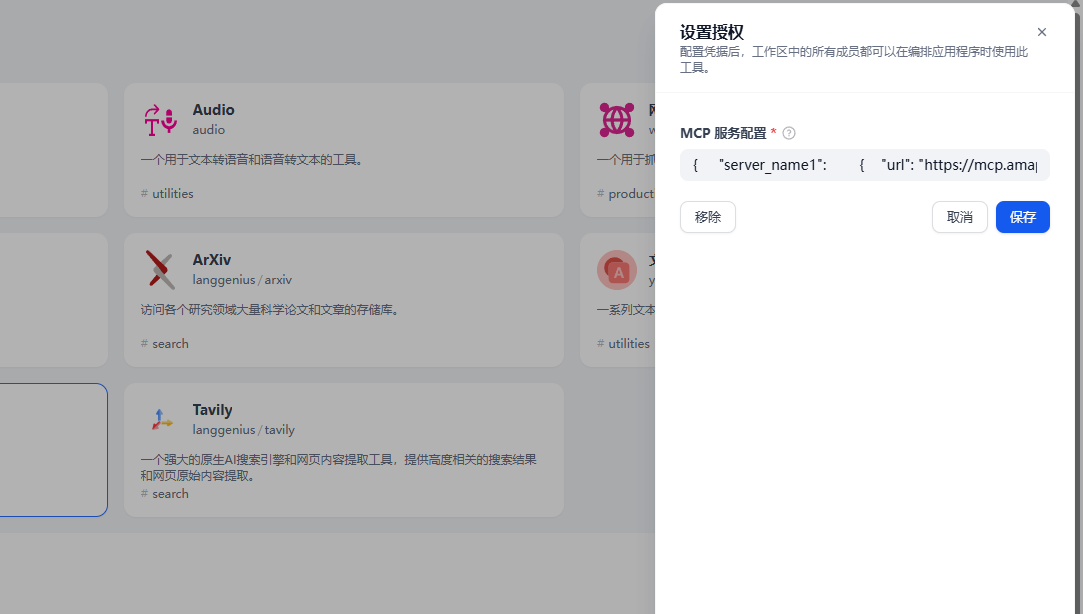
创建智能体:
你是一个智能助手,可根据用户输入的指令,进行推理并调用工具,完成任务后返回给用户结果。其中
server_name1为地图和天气服务,其中server_name2为搜索服务。
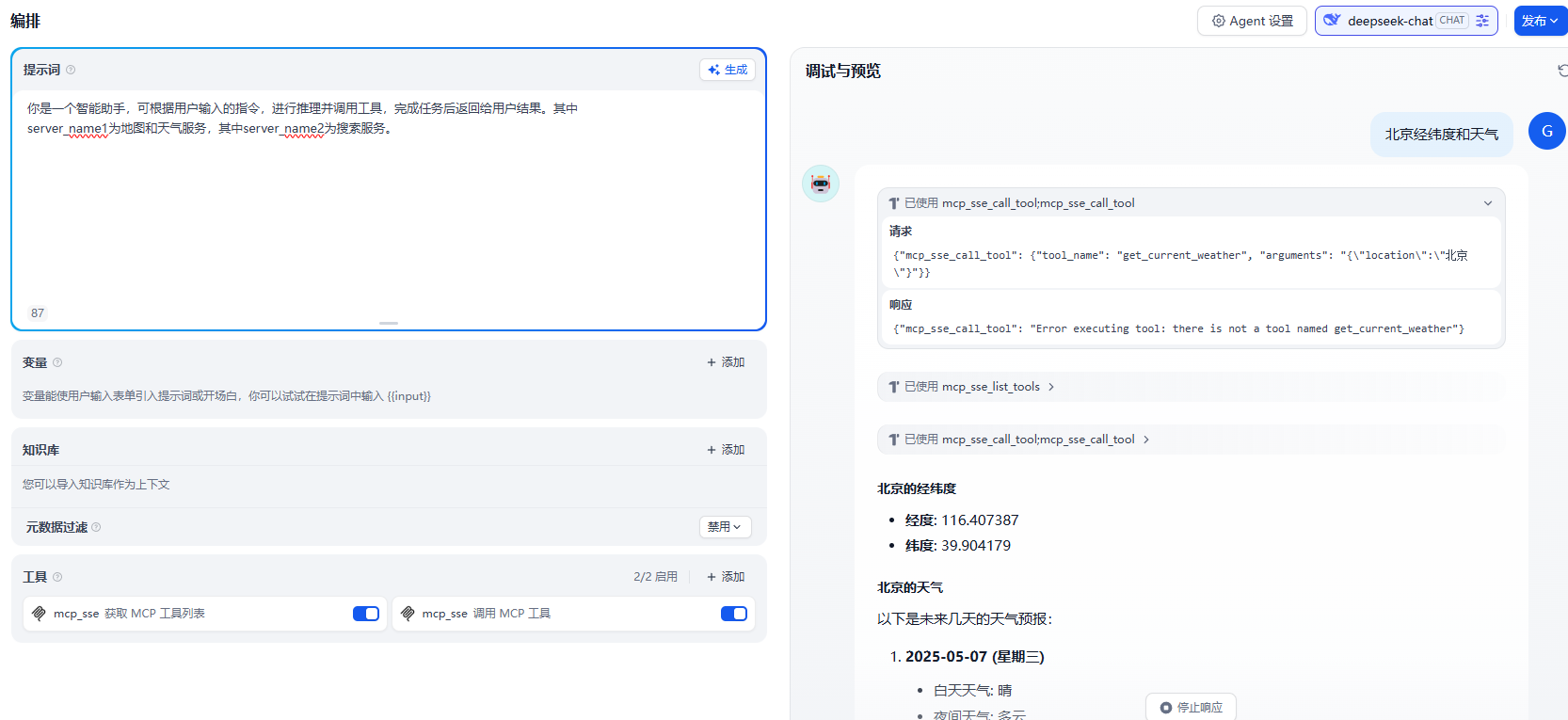
3.3.如何自定义MCP工具
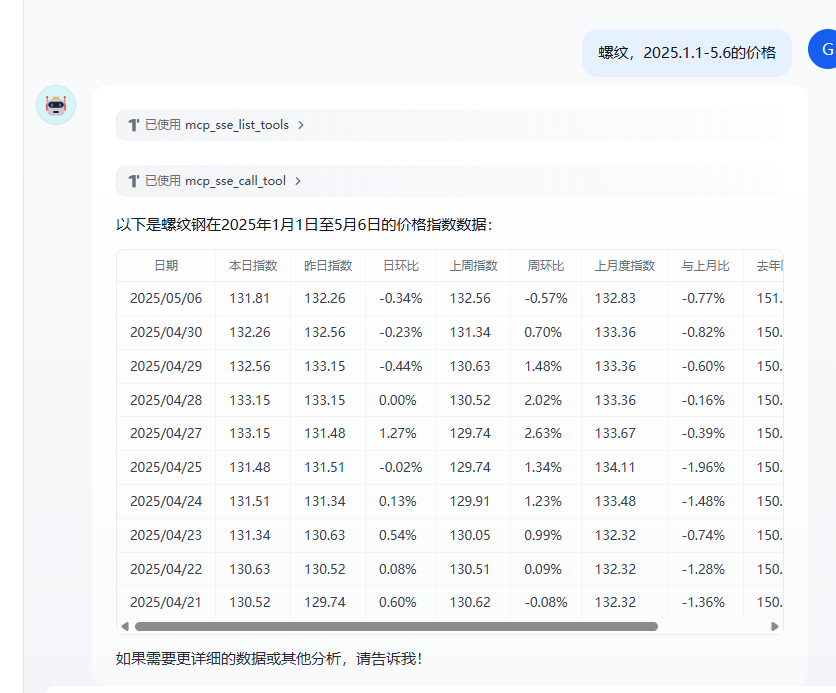
现在如果自己写了一个爬虫工具,需要调用到dify工作流或者智能体中如何实现呢
1.搭建MCP-server,选择sse通信协议,举例子:
from fastmcp import FastMCP
mcp = FastMCP("Demo 🚀",port=9000)
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run(transport='sse')
直接运行:
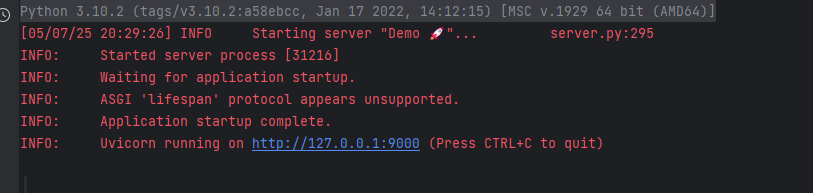
 成功搭建。
成功搭建。
2.dify调用
{
"mcp_server": {
"url": "http://本机ip:9000/sse",
"headers": {
},
"timeout": 5,
"sse_read_timeout": 300
}
}完整示例:
import anyio
import click
import httpx
import mcp.types as types
from mcp.server.lowlevel import Server
import pandas as pd
import time
# async def fetch_website(
# url: str,
# ) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
# headers = {
# "User-Agent": "MCP Test Server (github.com/modelcontextprotocol/python-sdk)"
# }
# async with httpx.AsyncClient(follow_redirects=True, headers=headers) as client:
# response = await client.get(url)
# response.raise_for_status()
# return [types.TextContent(type="text", text=response.text)]
async def fetch_website(
data_type: str,
Start_Time: str,
End_Time: str,
)-> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
# 设置Edge浏览器选项
# try:
# except Exception as e:
# print("Edge浏览器启动失败,请检查驱动是否正确安装!")
# print(e)
all_data_dist = {
"综合": "GANGCAIZONGHE",
"长材": "CHANGCAI",
"扁平": "BIANPING",
"一次材": "YICICAI",
"华东": "HUADONG",
"华南": "HUANAN",
"华北": "HUABEI",
"中南": "ZHONGNAN",
"东北": "DONGBEI",
"西南": "XINAN",
"西北": "XIBEI",
"螺纹": "LUOWEN",
"线材": "XIANCAI",
"型材": "XINCAI",
"中厚": "ZHONGHOU",
"锅炉容器板": "GUOLURONGQIBAN",
"造船板": "ZAOCHUANBAN",
"热卷": "REJUAN",
"窄带": "ZAIDAI",
"冷板": "LENGBAN",
"镀锌板卷": "DUXIN",
"无缝管": "WUFENGGUAN",
"聊城无缝钢管": "WUFENG_LIAOCHENG",
"焊管": "HANGUAN",
"盘扣式钢管脚手架": "PKSJSJ"
}
print("开始爬取数据")
print("普钢的所有数据类型:" + str(all_data_dist.keys()))
# Start_Time = input("请输入开始日期(格式:2024-01-01):") or "2024-04-01"
Start_Time_year = Start_Time.split("-")[0]
Start_Time_month = Start_Time.split("-")[1]
Start_Time_day = Start_Time.split("-")[2]
# day格式转换02需要去掉前导0
Start_Time_day = str(int(Start_Time_day))
print(f"开始日期:{Start_Time_year}-{Start_Time_month}-{Start_Time_day}")
# End_Time = input("请输入结束日期(格式:2025-04-01):") or "2025-04-01"
End_Time_year = End_Time.split("-")[0]
End_Time_month = End_Time.split("-")[1]
End_Time_day = End_Time.split("-")[2]
# day格式转换02需要去掉前导0
End_Time_day = str(int(End_Time_day))
print(f"结束日期:{End_Time_year}-{End_Time_month}-{End_Time_day}")
# data_type = input(
# "请输入需要爬取的数据类型:普钢['综合', '长材', '扁平', '一次材', '华东', '华南', '华北', '中南', '东北', '西南', '西北', '螺纹', '线材', '型材', '中厚', '锅炉容器板', '造船板', '热卷', '窄带', '冷板', '镀锌板卷', '无缝管', '聊城无缝钢管', '焊管', '盘扣式钢管脚手架']")
data_type1 = all_data_dist[data_type]
# 等待页面加载3s
# time.sleep(3)
# # element = driver.find_element(By.CLASS_NAME, "mRightBox")
# # 等待页面加载3s-
# time.sleep(3)
edge_options = Options()
edge_options.add_argument("--headless") # 无头模式,不显示浏览器窗口
edge_options.add_argument("--disable-gpu")
edge_options.add_argument("--window-size=1920,1080")
edge_service = Service('D:\桌面文件\edgedriver_win64\msedgedriver.exe') # 替换为你的Edge驱动路径
driver = webdriver.Edge(service=edge_service, options=edge_options)
print("开始打开浏览器")
url = "https://index.mysteel.com/xpic/detail.html?tabName=pugang"
driver.get(url)
time.sleep(3)
driver.find_element(By.CSS_SELECTOR, "img.addBtn[src*='icon.png']").click() # 点击展开
print("点击展开")
time.sleep(3)
# print(element.text)
try:
# 点击类型
key1 = driver.find_element(By.ID, data_type1)
key1.click()
# 等待页面加载3s
time.sleep(3)
# //*[@id="searchTimeLiDiv"]/ul/li[1]/a按日查询
key2 = driver.find_element(By.XPATH, '//*[@id="searchTimeLiDiv"]/ul/li[1]/a')
key2.click()
time.sleep(1)
# 起始日期//*[@id="startDay"]
start_date = driver.find_element(By.XPATH, '//*[@id="startDay"]')
# start_date.clear()
start_date.click()
time.sleep(1)
driver.maximize_window()
# # 解析年月日
# target_date = "2021-09-01"
# year, month, day = target_date.split('-')
# # 等待日历面板加载
# WebDriverWait(driver, 10).until(
# EC.presence_of_element_located((By.CSS_SELECTOR, ".daterangepicker.dropdown-menu"))
# )
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 选择年份(如果页面有年份下拉框)
year_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[2]")
year_dropdown.click()
time.sleep(1)
print("选择年份下拉框")
# 选择年份<option value="1975">1975</option>
# year_dropdown.find_element(By.XPATH, f"//option[@value='{year}']").click()
# print(f"选择年份:{year}")
select = Select(year_dropdown)
select.select_by_visible_text(Start_Time_year) # 根据文本选择
print(f"选择年份:{Start_Time_year}")
# 输出
# 选择月份 /html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]
month_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]")
month_dropdown.click()
time.sleep(1)
print("选择月份下拉框")
select1 = Select(month_dropdown)
select1.select_by_visible_text(Start_Time_month) # 根据文本选择
print(f"选择月份:{Start_Time_month}")
# 选择日期
date_cell = driver.find_element(
By.XPATH, f"//td[contains(@class, 'available') and text()='{Start_Time_day}']"
)
date_cell.click()
time.sleep(1)
print(f"选择日期:{Start_Time_day}")
except Exception as e:
print(f"执行出错: {str(e)}")
driver.save_screenshot('error.png')
try:
# //*[@id="searchTimeLiDiv"]/ul/li[1]/a按日查询
key2 = driver.find_element(By.XPATH, '//*[@id="searchTimeLiDiv"]/ul/li[1]/a')
key2.click()
time.sleep(1)
# 终止日期//*[@id="endDay"]
end_date = driver.find_element(By.XPATH, '//*[@id="endDay"]')
# start_date.clear()
end_date.click()
time.sleep(1)
driver.maximize_window()
# 解析年月日
target_date = "2021-09-01"
year, month, day = target_date.split('-')
# # 等待日历面板加载
# WebDriverWait(driver, 10).until(
# EC.presence_of_element_located((By.CSS_SELECTOR, ".daterangepicker.dropdown-menu"))
# )
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 选择年份(如果页面有年份下拉框)
year_end_dropdown = driver.find_element(By.XPATH,
"/html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[2]")
year_end_dropdown.click()
print("选择年份下拉框")
# 选择年份<option value="1975">1975</option>
# year_dropdown.find_element(By.XPATH, f"//option[@value='{year}']").click()
# print(f"选择年份:{year}")
select_year_end = Select(year_end_dropdown)
select_year_end.select_by_visible_text(End_Time_year) # 根据文本选择
print(f"选择年份:{End_Time_year}")
# 输出
# 选择月份 /html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[1]
month_end_dropdown = driver.find_element(By.XPATH,
"/html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[1]")
month_end_dropdown.click()
print("选择月份下拉框")
select_month_end = Select(month_end_dropdown)
select1_month_end = select_month_end.select_by_visible_text(End_Time_month) # 根据文本选择
print(f"选择月份:{End_Time_month}")
# /html/body/div[4]/div[2]
# 找到右侧日历
left_calendar = driver.find_element(
By.XPATH,
'/html/body/div[4]/div[2]'
)
# 选择日期
# left_calendar = driver.find_element(By.CLASS_SELECTOR, "calendar single left")
# driver.find_element(By.XPATH, "//td[contains(@class, 'available') and text()='2']")
date_end_cell = left_calendar.find_element(
By.XPATH,
f'.//td[text()={End_Time_day}]'
)
date_end_cell.click()
driver.save_screenshot('C:\pythonProject\python爬虫\我的钢铁网\end_date.png')
print(f"选择日期:{End_Time_day}")
except Exception as e:
print(f"执行出错: {str(e)}")
driver.save_screenshot('error.png')
# 点击搜索按钮
search_btn = driver.find_element(By.XPATH, '//*[@id="dome1"]/table/tbody/tr/td[5]/img')
search_btn.click()
# driver.save_screenshot('C:\pythonProject\python爬虫\我的钢铁网\搜索之后.png')
element = driver.find_element(By.CLASS_NAME, "mRightBox")
# 等待页面加载3s-
time.sleep(3)
#保存截图
driver.save_screenshot('C:\pythonProject\python爬虫\我的钢铁网\搜索之后.png')
print(element.text)
# data_str = element.text
# driver.quit()
return [types.TextContent(type="text", text=element.text)]
# return data_str
@click.command()
@click.option("--port", default=8000, help="Port to listen on for SSE")
@click.option(
"--transport",
type=click.Choice(["stdio", "sse"]),
default="stdio",
help="Transport type",
)
def main(port: int, transport: str) -> int:
app = Server("mcp-website-fetcher")
@app.call_tool()
async def fetch_tool(
name: str, arguments: dict
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name != "fetch":
raise ValueError(f"Unknown tool: {name}")
# if "url" not in arguments:
# raise ValueError("Missing required argument 'url'")
return await fetch_website(arguments["data_type"],arguments["Start_Time"],arguments["End_Time"])
@app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="fetch",
description="抓取网页数据,需要输入抓取钢材的类型,开始时间,结束时间三个参数",
inputSchema={
"type": "object",
"required": ["data_type", "Start_Time", "End_Time"],
"properties":
{
"data_type": {"type": "string", "description": "钢材种类(如HRB400)"},
"Start_Time": {"type": "string", "format": "date", "description": "开始时间(YYYY-MM-DD)"},
"End_Time": {"type": "string", "format": "date", "description": "结束时间(YYYY-MM-DD)"},
},
},
)
]
if transport == "sse":
from mcp.server.sse import SseServerTransport
from starlette.applications import Starlette
from starlette.responses import Response
from starlette.routing import Mount, Route
sse = SseServerTransport("/messages/")
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request._send
) as streams:
await app.run(
streams[0], streams[1], app.create_initialization_options()
)
return Response()
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse, methods=["GET"]),
Mount("/messages/", app=sse.handle_post_message),
],
)
import uvicorn
uvicorn.run(starlette_app, host="0.0.0.0", port=port)
else:
from mcp.server.stdio import stdio_server
async def arun():
async with stdio_server() as streams:
await app.run(
streams[0], streams[1], app.create_initialization_options()
)
anyio.run(arun)
return 0运行:
uv run mcp_simple_tool --transport sse --port 8000
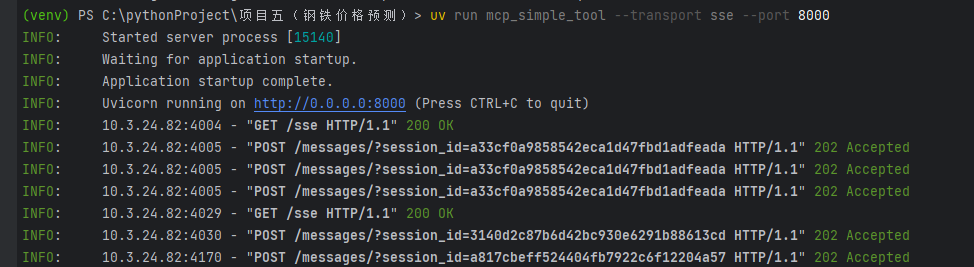
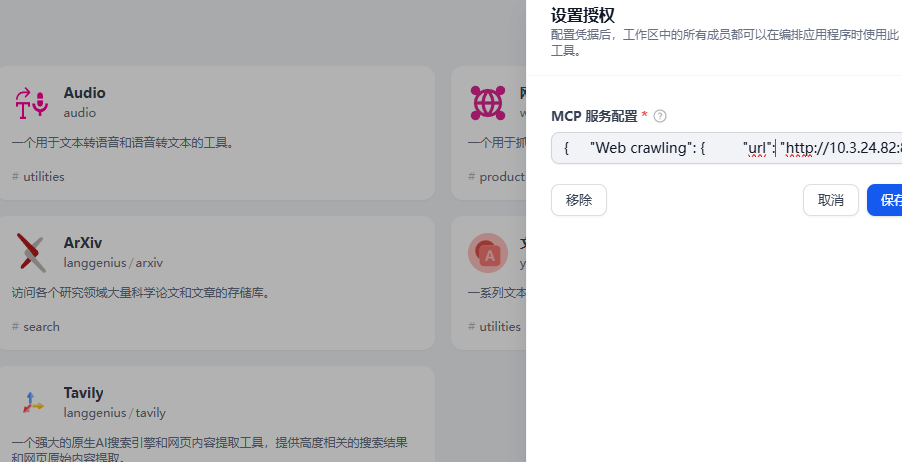
{
"Web crawling": {
"url": "http://10.***:8000/sse",
"headers": {
},
"timeout": 5,
"sse_read_timeout": 300
}
}

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)