Camel Multi-Agent框架学习-第二章 Hello CAMEL!
第二章主要是学习CAMEL框架中的一些基础智能体对象的使用,以及结合RAG和知识图谱进行智能检索。
本文根据DataWhale 2025年2月的学习项目 Camel Multi-Agent 做的笔记。
参考教程:Docs
操作系统版本:MacOS 11.6
1. RolePlaying
按照教程里提供的代码跑通调试,没有太大的问题。step方法是一个单轮对话的实现,每次只处理一轮assistant和user之间的交互,返回的是当前轮次的对话结果。在roleplaying里可以加入 critic agent来做择优,参考:Critic Agents and Tree Search — CAMEL 0.2.22 documentation
2. Workforce
Camel的Workforce采用方法链,将多智能体进行组织。按照创建 Workforce、添加工作节点、启动并处理任务的3个步骤,即可让workforce完成你指定的某个具体任务。如果是完成简单任务,只需要传入一段描述prompt给workforce即可,如果你需要更复杂的定制,则可以在初始化时配置工作节点列表、协调器Agent(Coordinator Agent)或任务规划Agent(Task Planner Agent)等高级参数。
但运行教程示例代码的时候,遇到了一个问题,提示duckduckgo_search模块缺失,导致规划助手最后无法输出结果。
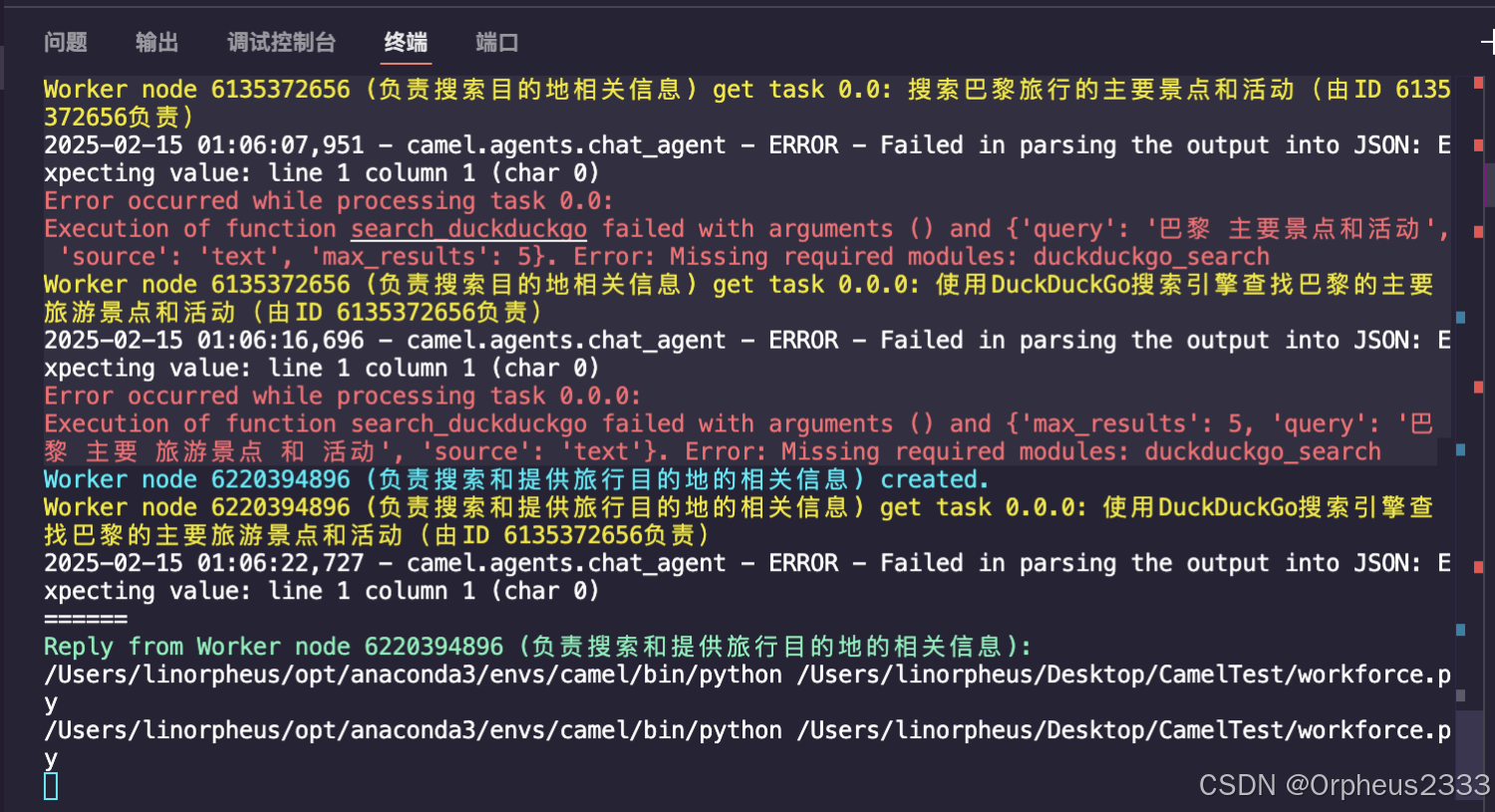
解决方法:pip install duckduckgo-search,重新安装duckduckgo库就可以解决。
以下图中展示分别展示代码运行后,负责搜索、制定计划、模拟游客给出反馈的AGENT的输出。
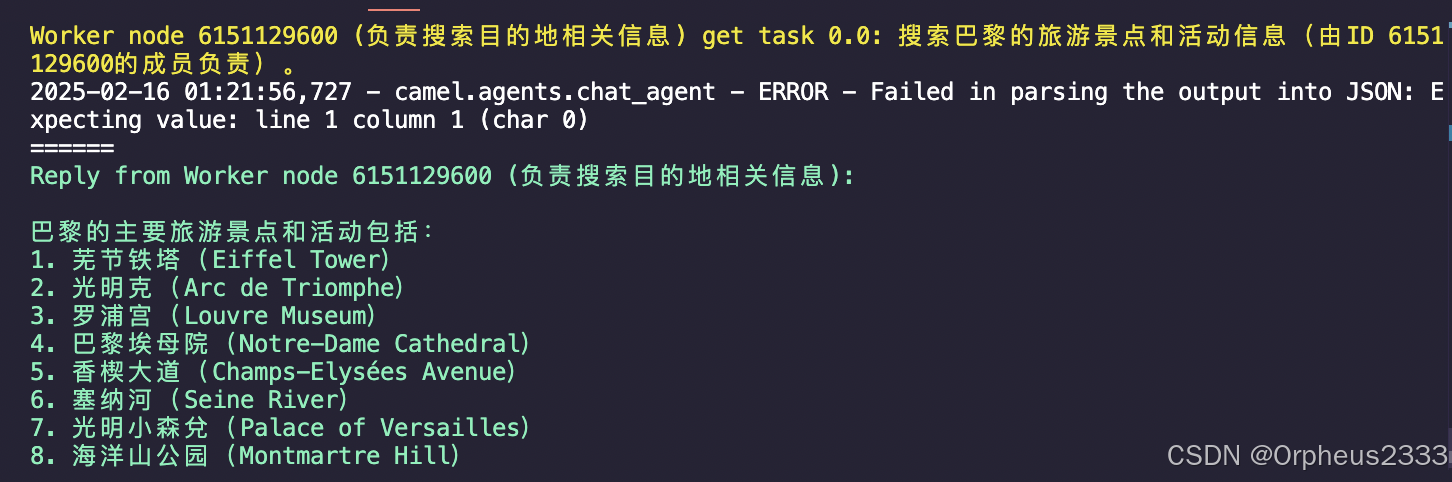


3. RAG
这一部分实现了一个基于PDF文档知识库进行RAG的AGENT。基于教程中给出的代码,调试修改如下:
import os
import requests
from config import API_SETTINGS
os.makedirs('local_data', exist_ok=True)
url = API_SETTINGS['modelscope']['paper_url']
response = requests.get(url)
with open('local_data/camel_paper.pdf', 'wb') as file:
file.write(response.content)
from camel.retrievers import VectorRetriever
from camel.types import StorageType
from camel.embeddings import SentenceTransformerEncoder
# embedding_model=SentenceTransformerEncoder(model_name='intfloat/e5-large-v2')
# 国内无法运行上述代码,可以注释掉使用以下方案
# 下载方案2:打开这个链接https://hf-mirror.com/intfloat/e5-large-v2/tree/main,下载除了model.safetensors的以外部分,保存到当前代码同级目录的embedding_model文件夹下。
# 也可以从百度云盘直接下载embedding_model文件夹放到当前代码同级目录下。
# https://pan.baidu.com/s/1xt0Tg_Wmr8iJuyGiPfgJrw 提取码: 7pzr
embedding_model=SentenceTransformerEncoder(model_name='./embedding_model/')
# 初始化VectorRetriever实例并使用本地模型作为嵌入模型
vr = VectorRetriever(embedding_model= embedding_model)
# 创建并初始化一个向量数据库 (以QdrantStorage为例)
from camel.storages.vectordb_storages import QdrantStorage
vector_storage = QdrantStorage(
url="http://localhost:6333", # 使用 HTTP 服务器
vector_dim=embedding_model.get_output_dim(),
collection="demo_collection",
path="storage_customized_run",
collection_name="论文"
)
# 将文件读取、切块、嵌入并储存在向量数据库中
vr.process(
content="local_data/camel_paper.pdf",
storage=vector_storage
)
# 设定一个查询语句
query = "CAMEL是什么"
# 执行查询并获取结果
results = vr.query(query=query, top_k=1)
print(results)然而运行后出现以下报错,提示pikepdf依赖库安装失败(这个问题在第一章安装camel完整库时也遇到过)。
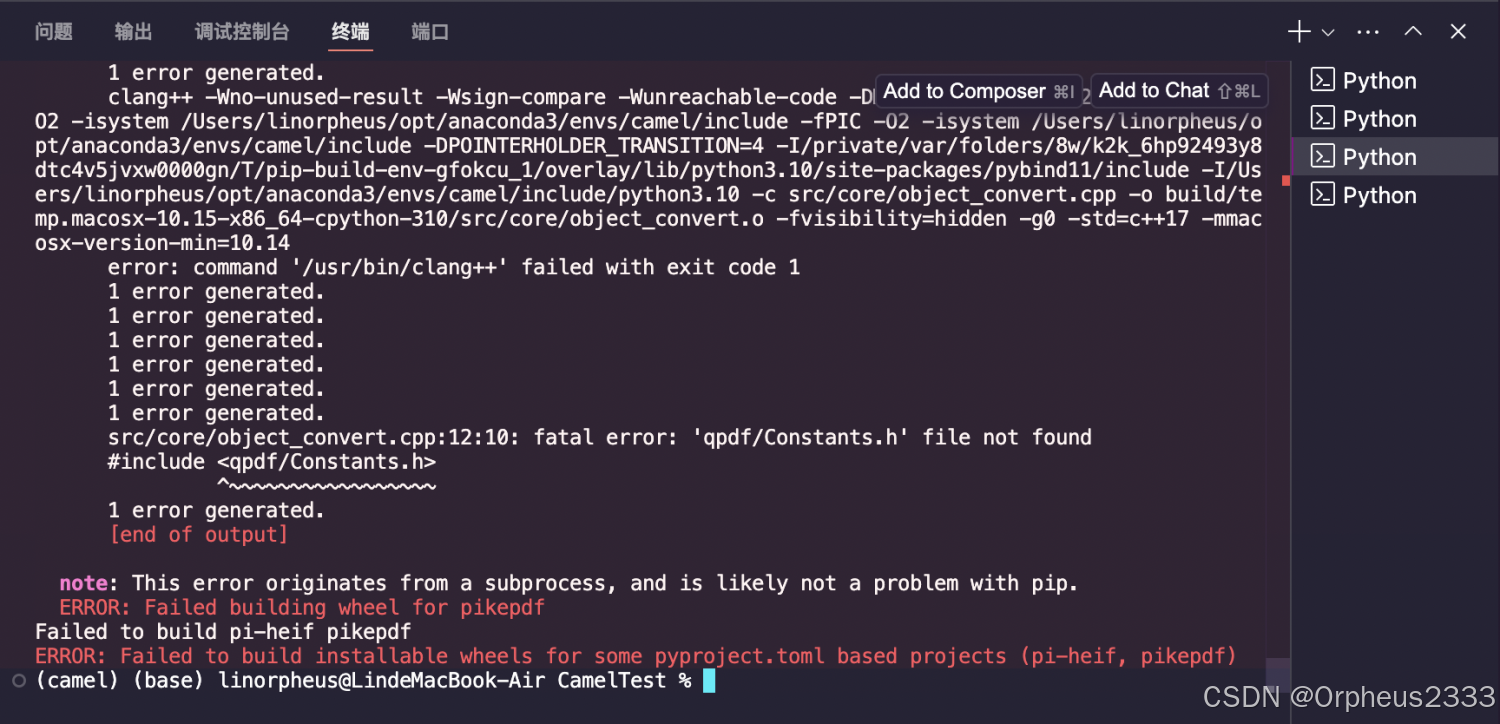
查询资料后,发现需要重新安装qpdf库,于是采用以下命令
brew install qpdf但是两次安装,都遇到了不同的错误提示。
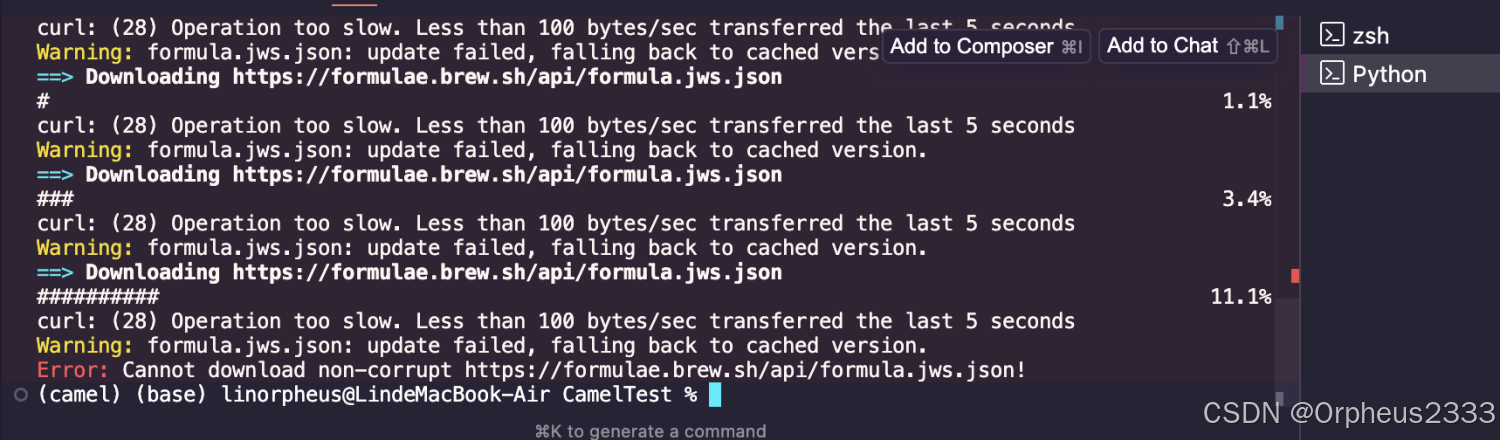
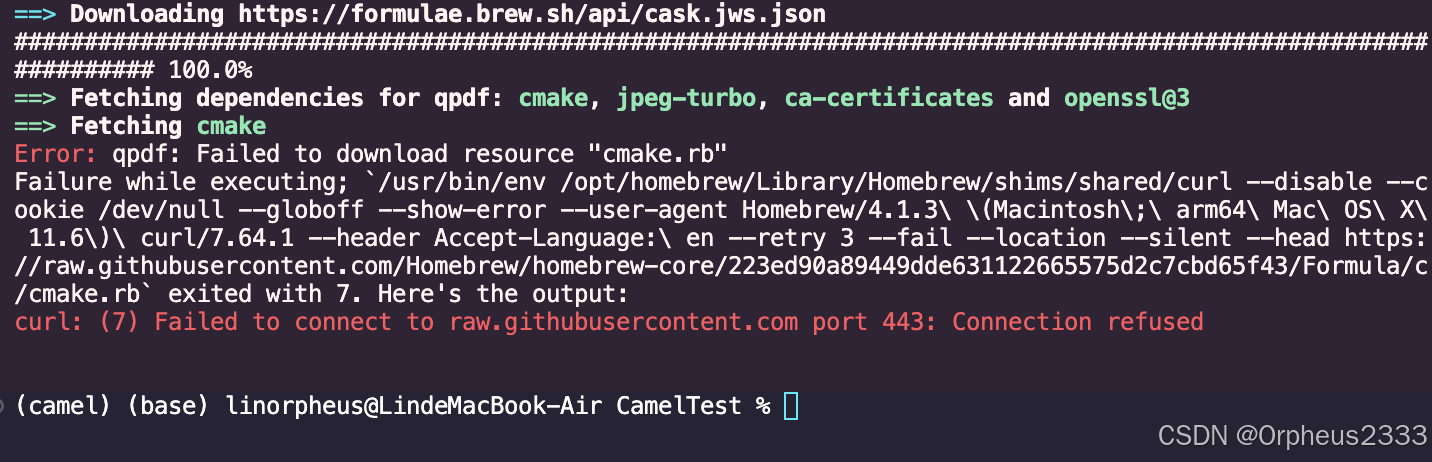
再次运行代码,也出现了不同的报错提示。
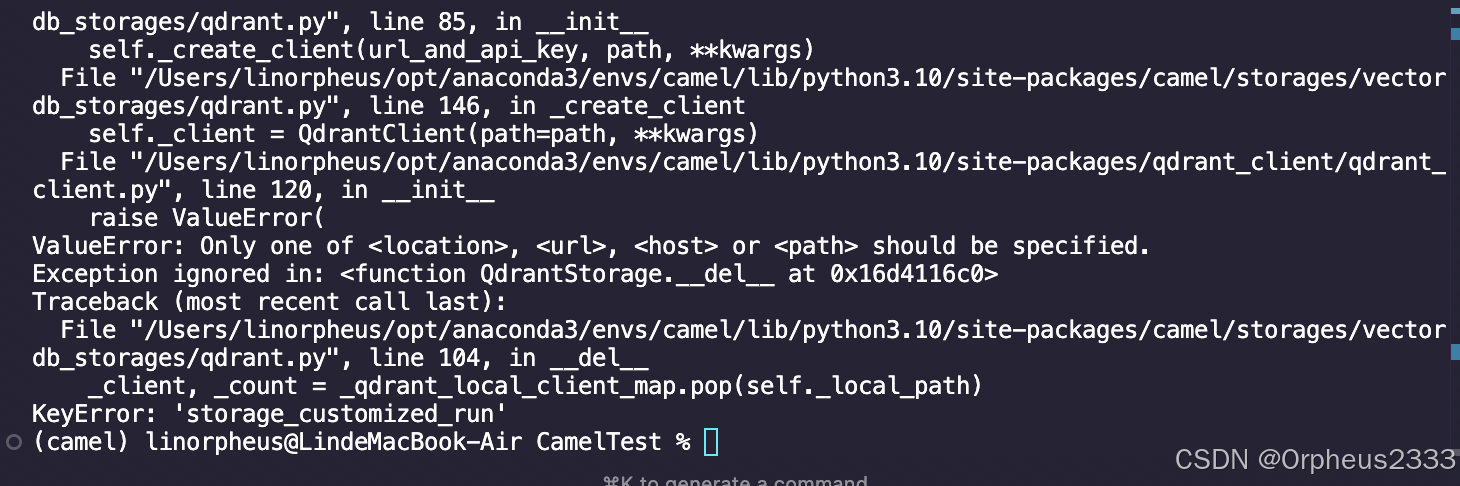
这个问题目前也没有解决,这个示例无法复现。
4. GraphRAG
Graph RAG 是将知识图谱(Knowledge Graph)引入检索增强生成(RAG)框架的一种扩展形式。它利用结构化的知识显式表示实体及其关系,从而显著提升系统的推理能力和回答准确性。在这一部分中,我尝试复现构建三元组,并上传到Neo4j图数据库并进行可视化呈现。
准备工作需要到Neo4j网站上注册账号,并创建实例,下载配置文件,里面有实例的url、username和password,在代码中使用。
基于教程中给出的代码,调试修改如下:
from camel.models import ModelFactory
from camel.types import ModelPlatformType
from camel.loaders import UnstructuredIO
from camel.agents import ChatAgent
from camel.storages import Neo4jGraph
from camel.agents import KnowledgeGraphAgent
from config import API_SETTINGS
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url=API_SETTINGS['modelscope']['api_url'],
api_key=API_SETTINGS['modelscope']['api_key']
)
sys_msg = """
你是一个图数据库专家,你的任务是从给定的内容中提取实体和关系,构建知识图谱。
知识图谱的基本组成:
1. 节点(Node):表示实体,包含id和type属性
2. 关系(Relationship):表示实体之间的联系
3. 属性(Property):节点或关系的附加信息
示例输入:
"小明,2008年9月13日出生,男。五行属水,性格开朗。"
期望输出:
Nodes:
Node(id="小明", type="人")
Node(id="水", type="五行")
Node(id="开朗", type="性格")
Node(id="2008年9月13日", type="时间")
Relationships:
Relationship(subj=Node(id="小明", type="人"), obj=Node(id="水", type="五行"), type="五行属性")
Relationship(subj=Node(id="小明", type="人"), obj=Node(id="开朗", type="性格"), type="性格特征")
Relationship(subj=Node(id="小明", type="人"), obj=Node(id="2008年9月13日", type="时间"), type="出生日期")
请从以下内容中提取实体和关系:
"""
graphprocessor = ChatAgent(
system_message=sys_msg,
model=model,
)
text_example = """
CAMEL和DATAWHALE是两个活跃的AI开源社区。
CAMEL致力于推动人工智能技术的发展,帮助开发者更好地进行AI研究和应用。
DateWhale通过开源项目和社区活动,促进知识分享和技术交流。这两个社区都为AI领域的创新和进步做出了重要贡献。
"""
# 自己实现prompt
# response = graphprocessor.step(input_message= text_example)
# print (response.msgs[0].content)
# 调用Camel的KnowledgeGraphAgent
uio = UnstructuredIO()
kg_agent = KnowledgeGraphAgent(model=model)
# 从给定文本创建一个元素
element_example = uio.create_element_from_text(
text=text_example, element_id="0"
)
# 让知识图谱Agent提取节点和关系信息
ans_element = kg_agent.run(element_example, parse_graph_elements=False)
print(ans_element)
# 在创建 Neo4jGraph 之前,先测试连接
from neo4j import GraphDatabase
import logging
# 设置日志级别
logging.basicConfig(level=logging.DEBUG)
url=API_SETTINGS['n4jscope']['NEO4J_URI']
# 测试连接
try:
driver = GraphDatabase.driver(
url,
auth=(
API_SETTINGS['n4jscope']['NEO4J_USERNAME'],
API_SETTINGS['n4jscope']['NEO4J_PASSWORD']
)
)
driver.verify_connectivity()
print("连接测试成功!")
except Exception as e:
print(f"连接测试失败:{str(e)}")
finally:
if 'driver' in locals():
driver.close()
# 上传n4j图数据库
n4j = Neo4jGraph(
url,
username=API_SETTINGS['n4jscope']['NEO4J_USERNAME'],
password=API_SETTINGS['n4jscope']['NEO4J_PASSWORD'],
)
# 检查实体信息
graph_elements = kg_agent.run(element_example, parse_graph_elements=True)
print(graph_elements)
# 上传知识图谱
n4j.add_graph_elements(graph_elements=[graph_elements])运行后,发现知识图谱Agent可以提取节点和关系信息并输出。
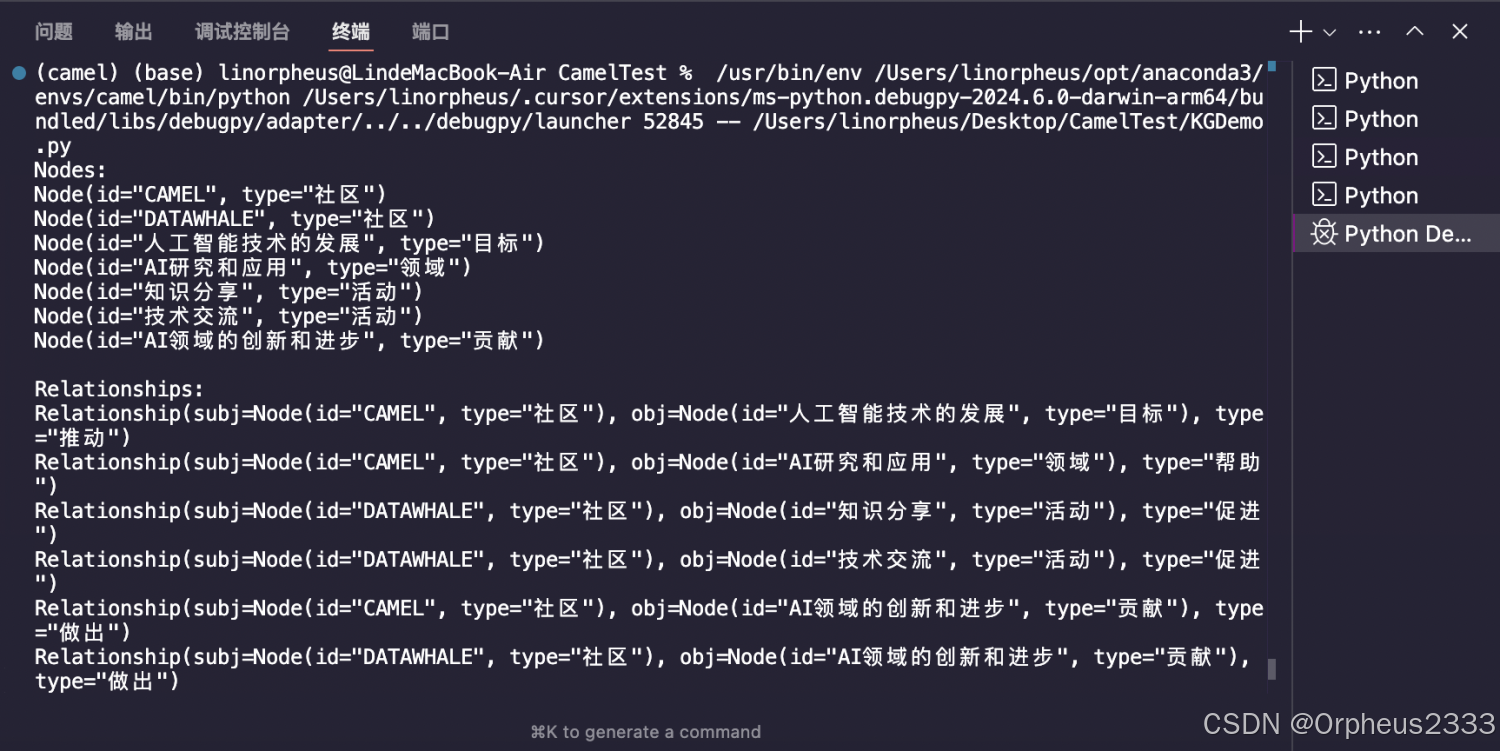
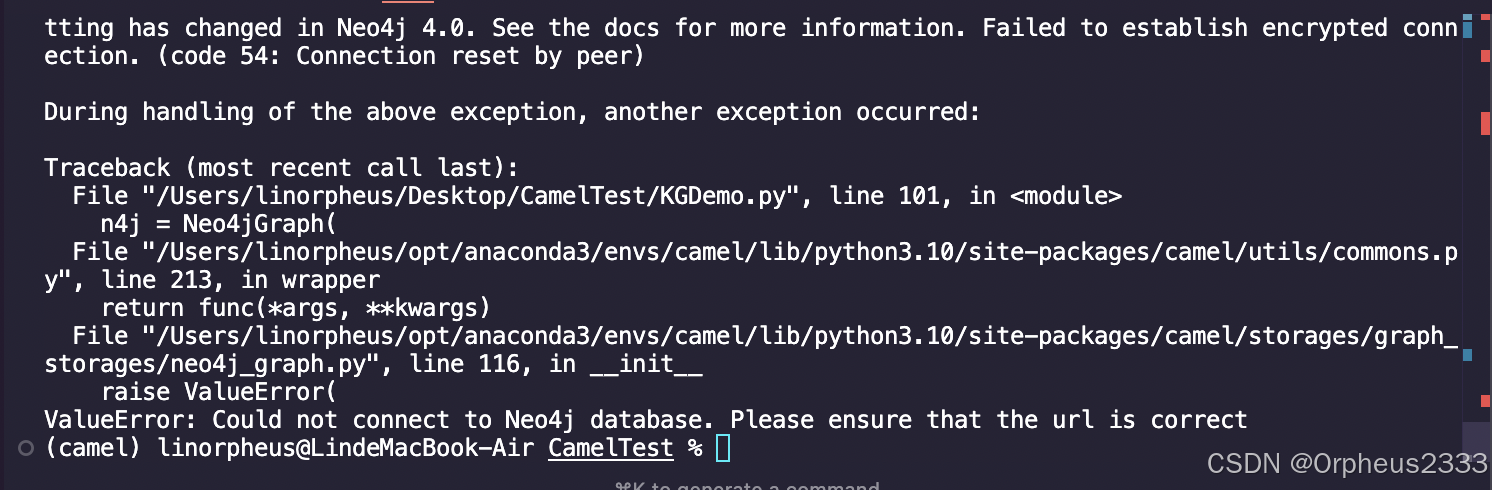
但是连接Neo4j数据库并上传时出现报错,一直无法连接数据库,但网站上实例确实在运行。尝试了各种方法后均无法解决。这个示例无法复现。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)