如何用LangGraph构建多Agent系统架构,收藏这一篇就够了!!
Agent是一个使用大语言模型决定应用程序控制流的系统。随着这些系统的开发,它们随时间推移变得复杂,使管理和扩展更困难。如你可能会遇到:Agent拥有太多的工具可供使用,对接下来应该调用哪个工具做出糟糕决策上下文过于复杂,以至于单个Agent无法跟踪系统中需要多个专业领域(例如规划者、研究员、数学专家等)。
前言
Agent是一个使用大语言模型决定应用程序控制流的系统。随着这些系统的开发,它们随时间推移变得复杂,使管理和扩展更困难。如你可能会遇到:
- Agent拥有太多的工具可供使用,对接下来应该调用哪个工具做出糟糕决策
- 上下文过于复杂,以至于单个Agent无法跟踪
- 系统中需要多个专业领域(例如规划者、研究员、数学专家等)。
为解决这些问题,你可能考虑将应用程序拆分成多个更小、独立的代理,并将它们组合成一个多Agent系统。这些独立的Agent可以简单到一个提示和一个LLM调用,或者复杂到像一个ReActAgent(甚至更多!)。
1 多Agent系统的好处
- 模块化:独立的Agent使得开发、测试和维护Agent系统更加容易。
- 专业化:你可以创建专注于特定领域的专家Agent,这有助于提高整个系统的性能。
- 控制:你可以明确控制Agent之间的通信(而不是依赖于函数调用)。
2 多Agent架构
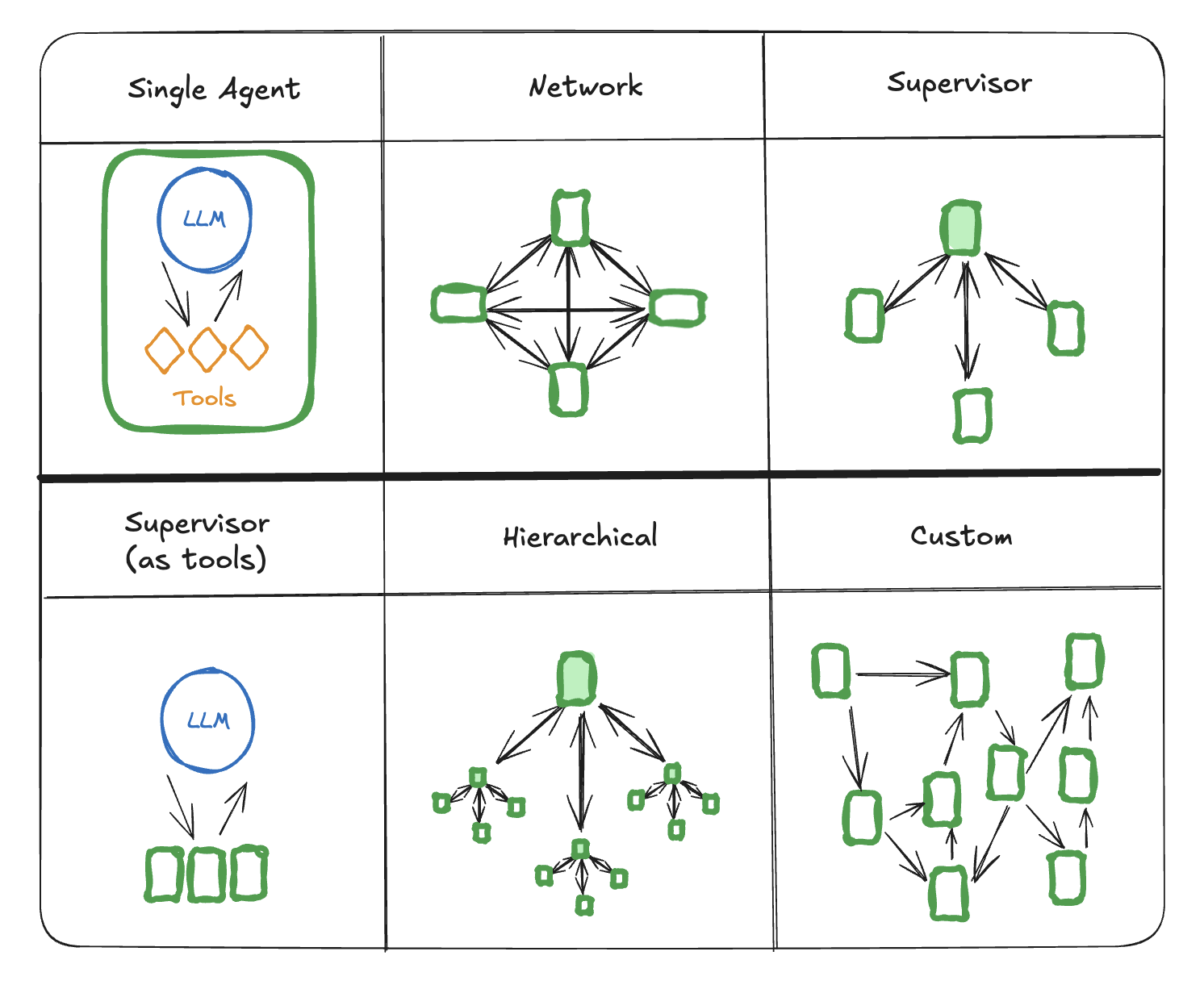
多Agent系统中有几种方式连接Agent:
- 网络:每个Agent都可与其他Agent通信。任何Agent都可以决定接下来调用哪个其他Agent
- 监督者:每个Agent与一个监督者Agent通信。监督者Agent决定接下来应该调用哪个Agent。
- 监督者(工具调用):这是监督者架构的一个特殊情况。个别Agent可以被表示为工具。在这种情况下,监督者Agent使用一个工具调用LLM来决定调用哪个Agent工具,以及传递哪些参数给这些Agent。
- 层次结构:你可以定义一个有监督者的多Agent系统。这是监督者架构的概括,并允许更复杂的控制流。
- 自定义多Agent工作流:每个Agent只与Agent子集中的其他Agent通信。流程的部分是确定性的,只有一些Agent可以决定接下来调用哪个其他Agent。
网络
这种架构中,Agent被定义为图节点。每个Agent都可以与每个其他Agent通信(多对多连接),并且可以决定接下来调用哪个Agent。虽然非常灵活,但随着Agent数量的增加,这种架构扩展性并不好:
- 很难强制执行接下来应该调用哪个Agent
- 很难确定应该在Agent之间传递多少信息
建议生产避免使用这架构,而是使用以下架构之一。
监督者
这种架构中,定义Agent为节点,并添加一个监督者节点(LLM),它决定接下来应该调用哪个Agent节点。使用条件边根据监督者的决策将执行路由到适当的Agent节点。这种架构也适用于并行运行多个Agent或使用map-reduce模式。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START
model = ChatOpenAI()
class AgentState(MessagesState):
next: Literal["agent_1", "agent_2"]
def supervisor(state: AgentState):
response = model.invoke(...)
return {"next": response["next_agent"]}
def agent_1(state: AgentState):
response = model.invoke(...)
return {"messages": [response]}
def agent_2(state: AgentState):
response = model.invoke(...)
return {"messages": [response]}
builder = StateGraph(AgentState)
builder.add_node(supervisor)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_edge(START, "supervisor")
# 根据监督者的决策路由到Agent之一或退出
builder.add_conditional_edges("supervisor", lambda state: state["next"])
builder.add_edge("agent_1", "supervisor")
builder.add_edge("agent_2", "supervisor")
supervisor = builder.compile()
教程以获取有关监督者多Agent架构的示例。
监督者(工具调用)
在这种监督者架构的变体中,我们定义个别Agent为工具,并在监督者节点中使用一个工具调用LLM。这可以作为一个ReAct风格的Agent实现,有两个节点——一个LLM节点(监督者)和一个执行工具(在这种情况下是Agent)的工具调用节点。
from typing import Annotated
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import InjectedState, create_react_agent
model = ChatOpenAI()
def agent_1(state: Annotated[dict, InjectedState]):
tool_message = ...
return {"messages": [tool_message]}
def agent_2(state: Annotated[dict, InjectedState]):
tool_message = ...
return {"messages": [tool_message]}
tools = [agent_1, agent_2]
supervisor = create_react_agent(model, tools)
自定义多Agent工作流
在这种架构中,我们添加个别Agent作为图节点,并提前定义Agent被调用的顺序,以自定义工作流。在LangGraph中,工作流可以以两种方式定义:
- 显式控制流(普通边):LangGraph允许你通过普通图边显式定义应用程序的控制流(即Agent通信的顺序)。这是上述架构中最确定性的变体——我们总是提前知道接下来将调用哪个Agent。
- 动态控制流(条件边):在LangGraph中,你可以允许LLM决定应用程序控制流的部分。这可以通过使用条件边实现。一个特殊情况是监督者工具调用架构。在这种情况下,驱动监督者Agent的工具调用LLM将决定工具(Agent)被调用的顺序。
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START
model = ChatOpenAI()
def agent_1(state: MessagesState):
response = model.invoke(...)
return {"messages": [response]}
def agent_2(state: MessagesState):
response = model.invoke(...)
return {"messages": [response]}
builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
# 明确定义流程
builder.add_edge(START, "agent_1")
builder.add_edge("agent_1", "agent_2")
3 Agent之间通信
构建多Agent系统时最重要的事情是弄清楚Agent如何通信。有几个不同的考虑因素:
3.1 图状态与工具调用
Agent之间传递的“有效载荷”是什么?在上述讨论的大多数架构中,Agent通过图状态进行通信。在监督者带工具调用的情况下,有效载荷是工具调用参数。
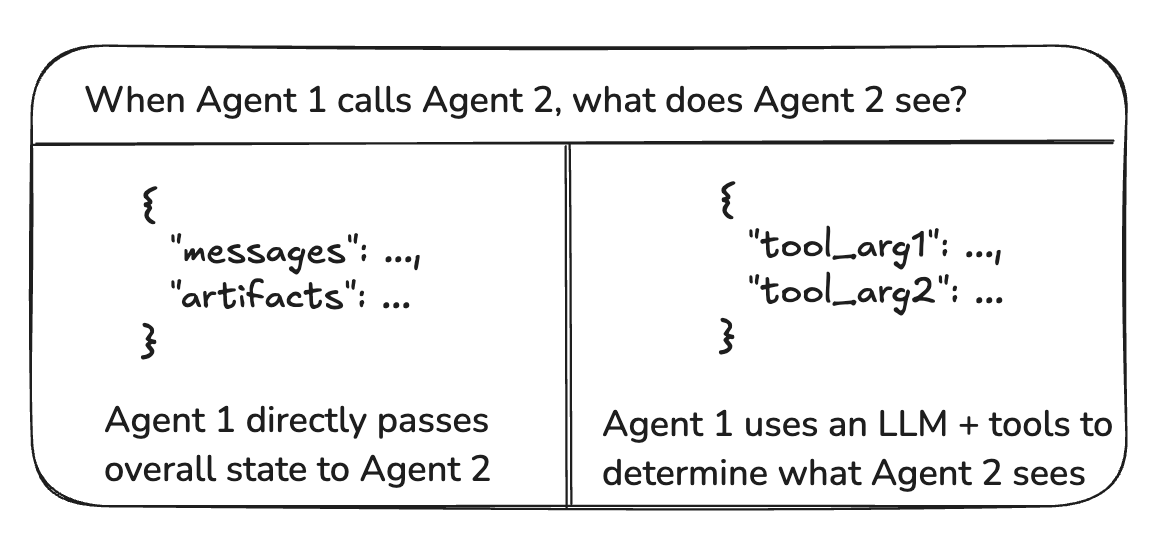
图状态
要通过图状态进行通信,各个Agent需要被定义为图节点。这些可以作为函数或整个子图添加。在图执行的每一步中,Agent节点接收当前的图状态,执行Agent代码,然后将更新的状态传递给下一个节点。
通常,Agent节点共享一个单一的状态模式。然而,你可能想要设计具有不同状态模式的Agent节点。
3.2 不同的状态模式
一个Agent可能需要与其余Agent有不同的状态模式。例如,搜索Agent可能只需要跟踪查询和检索到的文档。在LangGraph中有两种方法可以实现这一点:
- 定义具有单独状态模式的子图Agent。如果子图和父图之间没有共享状态键(通道),则需要添加输入/输出转换,以便父图知道如何与子图通信。
- 定义具有私有输入状态模式的Agent节点函数,该模式与整个图的状态模式不同。这允许传递仅需要用于执行该特定Agent的信息。
3.3 共享消息列表
Agent之间通信的最常见方式是通过共享状态通道,通常是消息列表。这假设状态中至少有一个通道(键)由Agent共享。当通过共享消息列表通信时,还有一个额外的考虑因素:Agent是共享完整的历史记录还是仅共享最终结果?
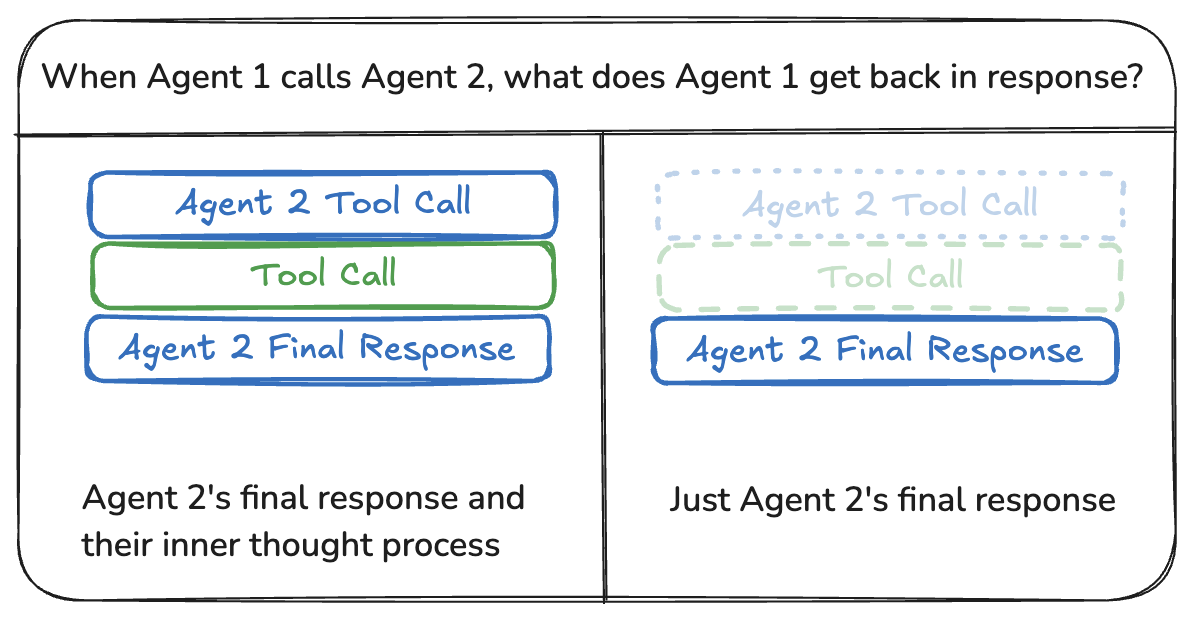
共享完整历史记录
Agent可以共享他们的思维过程的完整历史记录(即“草稿垫”)与其他所有Agent。这种“草稿垫”通常看起来像一个消息列表。共享完整思维过程的好处是,它可能有助于其他Agent做出更好的决策,提高整个系统的整体推理能力。缺点是,随着Agent数量和复杂性的增长,“草稿垫”将迅速增长,可能需要额外的策略进行内存管理。
共享最终结果
Agent可以拥有自己的私有“草稿垫”,并且只与其余Agent共享最终结果。这种方法可能更适合拥有许多Agent或更复杂的Agent的系统。在这种情况下,你需要定义具有不同状态模式的Agent。
对于作为工具调用的Agent,监督者根据工具模式确定输入。此外,LangGraph允许在运行时传递状态给单个工具,以便从属Agent在需要时可以访问父状态。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 18
18 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)