4.5 联机搜索(online-dfs-agent) --- 实现代码附详细注释
蛮简单的算法,但因为对python不太熟悉,实现过程不是一般的痛苦…联机dfs传统dfs的区别只是要维护一个回溯序列和一个解序列启发式函数使用的是与目标的曼哈顿距离,在一些极限条件下,因为每次只能感知一步,所以效果并不好,但总体情况下还是具有一定优化能力整体流程见书中描述:Python代码:import mathdirections4 = {'W': (-1, 0), 'N': (0, 1), '
·
蛮简单的算法,但因为对python不太熟悉,实现过程不是一般的痛苦…
联机dfs传统dfs的区别只是要维护一个回溯序列和一个解序列
启发式函数使用的是与目标的曼哈顿距离,在一些极限条件下,因为每次只能感知一步,所以效果并不好,但总体情况下还是具有一定优化能力
整体流程见书中描述:
Python代码:
import math
directions4 = {'W': (-1, 0), 'N': (0, 1), 'E': (1, 0), 'S': (0, -1)}
directions8 = dict(directions4)
directions8.update({'NW': (-1, 1), 'NE': (1, 1), 'SE': (1, -1), 'SW': (-1, -1)})
mp = [[0, 0, 0, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0], [0, 0, 0, 0, 0]]
def compare(a, b):
if a.x == b.x and a.y == b.y:
return True
else:
return False
class Problem:
def __init__(self, goal, init):
self.goal = goal
self.init = init
def goal_test(self, state):
if self.goal == state:
return True
else:
return False
def actions(self, state):
return (directions4['W'], directions4['N'], directions4['E'], directions4['S'])
class State:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, other):
if self.x == other.x and self.y == other.y:
return True
else:
return False
def Hash(self):
return self.x * 100 + self.y
class OnlineDFSAgent:
def __init__(self, problem):
self.problem = problem
# the previous state, initially null
self.s = None
# the action, initially null
self.a = None
# a table that list, for each state, the actions not yet tried
self.untried = dict()
# a table that list, for each state, the backtracks not yet tried
self.unbacktracked = dict()
# a table indexed by state and action, initially empty
self.result = {}
def __call__(self, percept):
s1 = self.update_state(percept)
print("(", s1.x, ",", s1.y, ")")
# 如果已经到达目标状态,行动为空
if self.problem.goal_test(s1):
print("(", self.problem.init.x, ",", self.problem.init.y, ")", end='')
for k in self.result:
print(" ->", "(", self.result[k].x, ",", self.result[k].y, ")", end='')
return True
else:
if s1.Hash() not in self.untried.keys():
self.untried[s1.Hash()] = [directions4['E'], directions4['N'], directions4['S'], directions4['W']]
# 如果s1不是初始节点
if self.s is not None:
if (self.s.Hash(), self.a) not in self.result or s1 != self.result[(self.s.Hash(), self.a)]:
self.result[(self.s.Hash(), self.a)] = s1
if s1.Hash() not in self.unbacktracked:
self.unbacktracked[s1.Hash()] = []
self.unbacktracked[s1.Hash()].insert(0, self.s)
# 维护untried列表
if len(self.untried[s1.Hash()]) == 0:
if len(self.unbacktracked[s1.Hash()]) == 0:
self.a = None
else:
# else a <- an action b such that result[s', b] = POP(unbacktracked[s'])
unbacktracked_pop = self.unbacktracked.pop(s1.Hash())
for (s, b) in self.result.keys():
if self.result[(s, b)] == unbacktracked_pop:
self.a = b
break
self.s = s1
return False
def update_state(self, percept):
if self.s is None:
return problem.init
s2 = self.s
h = 999999
at = None
for i in range(len(self.untried[self.s.Hash()]) - 1, -1, -1):
a1 = self.untried[self.s.Hash()][i]
st = State(a1[0] + self.s.x, a1[1] + self.s.y)
if st.x >= 0 and st.x <= 3 and st.y >= 0 and st.y <= 4:
if mp[st.x][st.y] != 1:
# 计算启发值
ht = abs(st.x - problem.goal.x) + abs(st.y - problem.goal.y)
if ht < h:
h = ht
s2 = st
at = a1
else:
self.untried[self.s.Hash()].pop(i)
else:
self.untried[self.s.Hash()].pop(i)
self.untried[self.s.Hash()].remove(at)
self.a = at
return s2
if __name__ == '__main__':
init_state = State(3, 0)
goal_state = State(0, 4)
problem = Problem(goal_state, init_state)
agent = OnlineDFSAgent(problem)
judge = False
while judge is False:
judge = agent(judge)
可以看到算法回溯了两次,最后到达了终点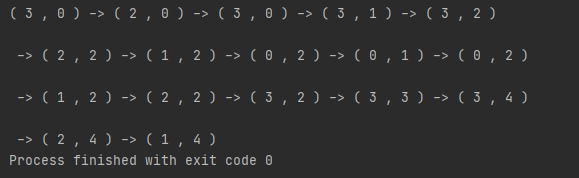

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)