工具调用×大模型思考=超级智能体:ReAct 策略如何改变AI能力,看完这一篇你就懂了!!
想象一下,如果普通AI是一个只会机械执行指令的机器人,那么采用ReAct策略的智能体就像是一个会先思考后行动的侦探。在解决问题时,它不会匆忙跳入结论的深渊,而是沿着"观察-思考-行动-观察"的螺旋阶梯,一步步接近真相。这就是ReAct(Reasoning + Acting)策略的魅力所在。
前言
想象一下,如果普通AI是一个只会机械执行指令的机器人,那么采用ReAct策略的智能体就像是一个会先思考后行动的侦探。
在解决问题时,它不会匆忙跳入结论的深渊,而是沿着"观察-思考-行动-观察"的螺旋阶梯,一步步接近真相。这就是ReAct(Reasoning + Acting)策略的魅力所在。
ReAct策略:智能体的"内心独白"与"外在行动"
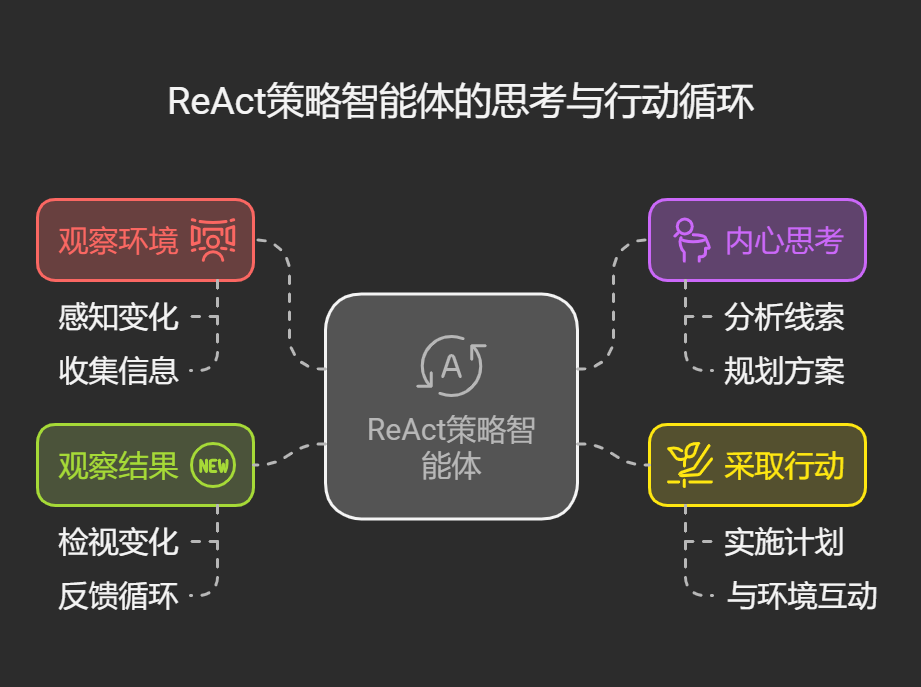
ReAct就像给AI装上了"内心独白"和"行动执行器"两个齿轮,让它们交替转动:
-
观察环境:智能体睁大眼睛,感知周围世界
-
内心思考:像侦探一样在脑海中分析线索,规划方案
-
采取行动:迈出实际步伐,与环境互动
-
观察结果:检视行动带来的变化,为下一轮思考提供新线索
这种策略让AI不再像无头苍蝇般乱撞,而是像国际象棋大师,每走一步棋都经过深思熟虑。
案例一:寻找名人出生年份
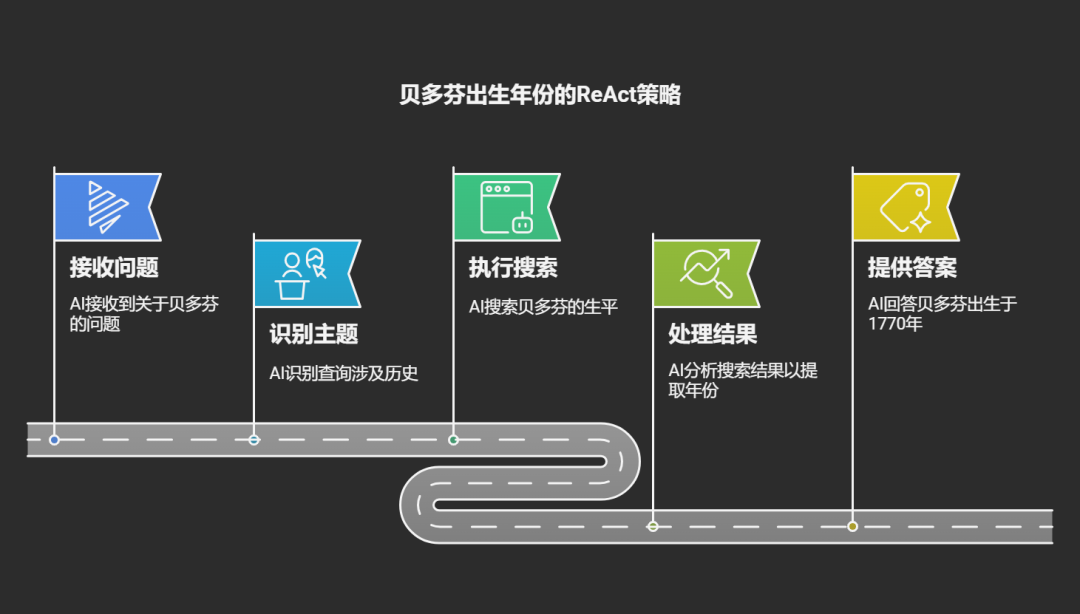
想象智能体面对这个问题:“贝多芬出生于哪一年?”
伪代码示例:
观察:收到问题"贝多芬出生于哪一年?"
思考:这是关于历史人物的问题,我需要查找贝多芬的生平信息。
行动:[搜索] 查询"贝多芬生平"
观察结果:搜索返回"路德维希·范·贝多芬(1770-1827),德国作曲家..."
思考:从结果中我可以看到贝多芬的出生年份是1770年。
行动:[回答] "贝多芬出生于1770年。"
这个过程就像一个学生在做历史作业,先理解问题,思考获取信息的方法,查阅资料,最后从资料中提取答案。
案例二:解决需要多步推理的复杂问题
现在来看一个更复杂的问题:“贝多芬和莫扎特谁的音乐生涯更长?”
伪代码示例:
观察:收到问题"贝多芬和莫扎特谁的音乐生涯更长?"
思考:要比较音乐生涯长度,我需要知道两人的出生年份、逝世年份以及开始创作音乐的时间。
行动:[搜索] 查询"贝多芬生平"
观察结果:得到"路德维希·范·贝多芬(1770-1827),8岁开始学习音乐..."
思考:贝多芬1770年出生,1827年逝世,8岁开始音乐生涯。下面我需要查询莫扎特的信息。
行动:[搜索] 查询"莫扎特生平"
观察结果:得到"沃尔夫冈·阿玛多伊斯·莫扎特(1756-1791),5岁开始作曲..."
思考:莫扎特1756年出生,1791年逝世,5岁开始音乐生涯。现在我需要计算各自的音乐生涯长度。
行动:[计算] 贝多芬音乐生涯 = 1827 - (1770 + 8) = 49年
莫扎特音乐生涯 = 1791 - (1756 + 5) = 30年
思考:经过计算,贝多芬的音乐生涯为49年,莫扎特为30年,所以贝多芬的音乐生涯更长。
行动:[回答] "贝多芬的音乐生涯更长,共49年。而莫扎特的音乐生涯为30年。虽然莫扎特更早开始(5岁),但贝多芬活得更久,因此创作时间更长。"
这个例子就像解谜游戏,需要收集多块拼图,通过逻辑推理将它们拼接起来,才能看到完整图景。
ReAct策略如何提升智能体能力
像导航仪一样校正路线
普通AI像一个按照固定路线前进的火车,而ReAct智能体则像一辆装有GPS的汽车,每行驶一段距离就会重新评估位置,随时调整路线。当遇到错误转弯时,它会立即察觉并纠正,而不会固执地走向错误目的地。
例如,在搜索"拿破仑的出生地"时,如果第一次查询返回不明确结果,ReAct会思考:“我需要更精确的查询”,然后尝试新的搜索词"拿破仑·波拿巴出生地详细信息"。
像拆解积木一样分解问题
面对"计算爱因斯坦发表相对论时的年龄"这样的复杂问题,ReAct会将其分解为:
-
查询爱因斯坦出生年份
-
查询相对论发表年份
-
计算两者之差
这就像厨师先准备所有食材,再一步步完成烹饪,而不是盲目地一股脑儿把所有东西倒入锅中。
生活中的ReAct应用场景
智能购物助手
想象一个帮你选购新笔记本电脑的ReAct智能体:
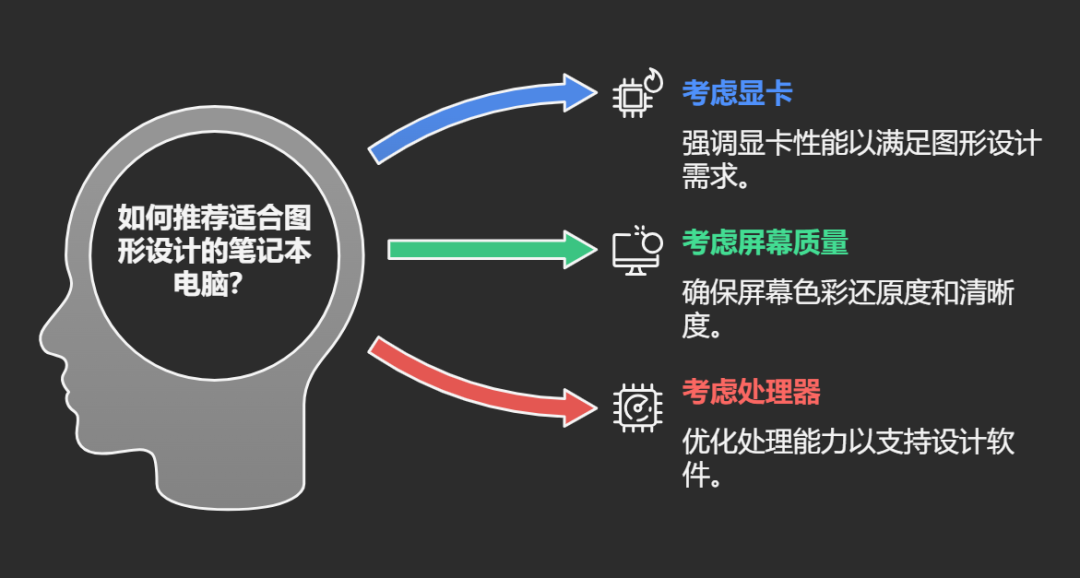
用户:帮我推荐一台适合图形设计的笔记本电脑。
思考:用户需要适合图形设计的笔记本,应该考虑显卡性能、屏幕色彩还原度和处理器性能。
行动:[检索] 查询"2025年图形设计推荐笔记本"
观察结果:得到多款高性能笔记本信息...
思考:需要了解用户预算和对轻薄度的要求。
行动:[询问] "您的预算大约是多少?对笔记本的轻薄度有要求吗?"
用户:预算8000元,希望便于携带。
思考:根据预算和轻薄需求,需要在性能和便携性间平衡...
...(持续思考-行动循环)
行动:[推荐] "根据您的需求,我推荐以下三款笔记本..."
这个过程就像一位经验丰富的导购,不断通过交流了解需求,思考可行方案,最终提供个性化建议。
健康顾问机器人
一个帮助用户制定健身计划的ReAct智能体:
思考:需要了解用户的身体状况、健身目标和时间安排。
行动:[询问] 收集用户基本信息...
思考:用户是健身新手,希望增肌,每周有3天时间锻炼,需要设计循序渐进的计划。
行动:[检索] 查询"初学者增肌训练计划"
思考:根据用户情况,建议先从基础动作开始,逐步增加强度...
行动:[生成] 制定个性化的三阶段健身计划...
就像一位私人教练,ReAct智能体不仅提供标准化建议,还会根据用户的特点和反馈不断调整计划。
思考:AI的思考之舞
ReAct策略为智能体带来了"思考与行动"的双重能力,如同赋予机器一种特殊的舞蹈节奏。在这场舞蹈中,思考是审慎的步伐,行动是舞者的跃动,两者交织形成优雅而高效的问题解决流程。
通过这种交替前进的方式,AI不再是简单的命令执行者,而成为了能够思考、规划、执行和调整的智能助手。在未来的AI发展中,ReAct策略无疑代表了从"机械反应"到"思考行动"的关键跨越,为构建更智能、更自然的人机交互铺平了道路。
正如侦探需要线索、推理和行动才能破案,配备ReAct策略的智能体也能够在复杂多变的世界中,以更加人性化的方式帮助我们解决各种难题。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 28
28 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)