

metagpt学习-OSS订阅智能体 每日早上八点爬取b站前三十个视频并使用WxPusher发送至微信
个人学习的笔记,带大家更深入的认识智能体,metagpt框架,以及与爬虫结合的智能体,爬取b站排行榜并发送至微信。
前言
个人学习的笔记,带大家更深入的认识智能体,metagpt框架,以及与爬虫结合的智能体,爬取b站排行榜并发送至微信
正文
OSS订阅智能体实现
- 实现一个 OSSWatcher 的 Role:OSS 即 Open source software,我们对OSS 智能体定位是,帮我们关注并分析热门的开源项目,当有相关信息时将信息推送给我们,这里需要确定让 OSS 从哪个网页获取信息
- 结果Callback:处理OSSWatcher角色运行生成的信息,我们可以将数据发送到微信或者discord
- 触发Trigger:指这个OSSWatcher角色运行的触发条件,可以是定时触发或者是某个网站有更新时触发
实现一个 OSSWatcher 的 Role
要实现这样一个智能体,我们需要从两个方面进行考虑,第一个是用爬虫爬取b站的排行榜,第二个就是写一个可以实现使用gpt整理成我们需要的格式的智能体
爬取b站排行榜的部分
这里可以看我写的部分
在这其中,我们需要填写自己的User-Agent和Cookie,方法就是打开你的b站主页,点击f12打开控制台,选择网络,点击刷新后,打开一个调用接口的信息,一个没找到就再换一个,总会有的

我们把里面的Cookie的值和User-Agent的值复制出来,然后分别填上
爬虫部分不多解释,网上的教程比我说的详细多了
import requests
from bs4 import BeautifulSoup
import json
def main():
head = {
"User-Agent": "***", # 自己补上,我的不能给你们看
"Referer": "https://www.bilibili.com/v/popular/rank/all/",
"Cookie": "***" # 自己补上,我的不能给你们看
}
url="https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=108c53ba3d5d692a90b85aa32c7a513b&wts=1706973855"
html = requests.get(url, headers=head)
content: str = ''
data = html.json()
list_data = data['data']['list']
for index, data in enumerate(list_data[:30]):
name = data['owner']
name1 = name['name']
content += f"第{index + 1}个视频\n视频封面:{data['pic']}\n视频标题:{data['title']}\n视频作者:{name1}\n视频链接:{data['short_link_v2']}\n"
print(content)
if __name__ == "__main__":
main()
实现gpt整理的智能体
不多说,直接代码管上,如果熟悉了metagpt框架,这一部分不需要讲的详细
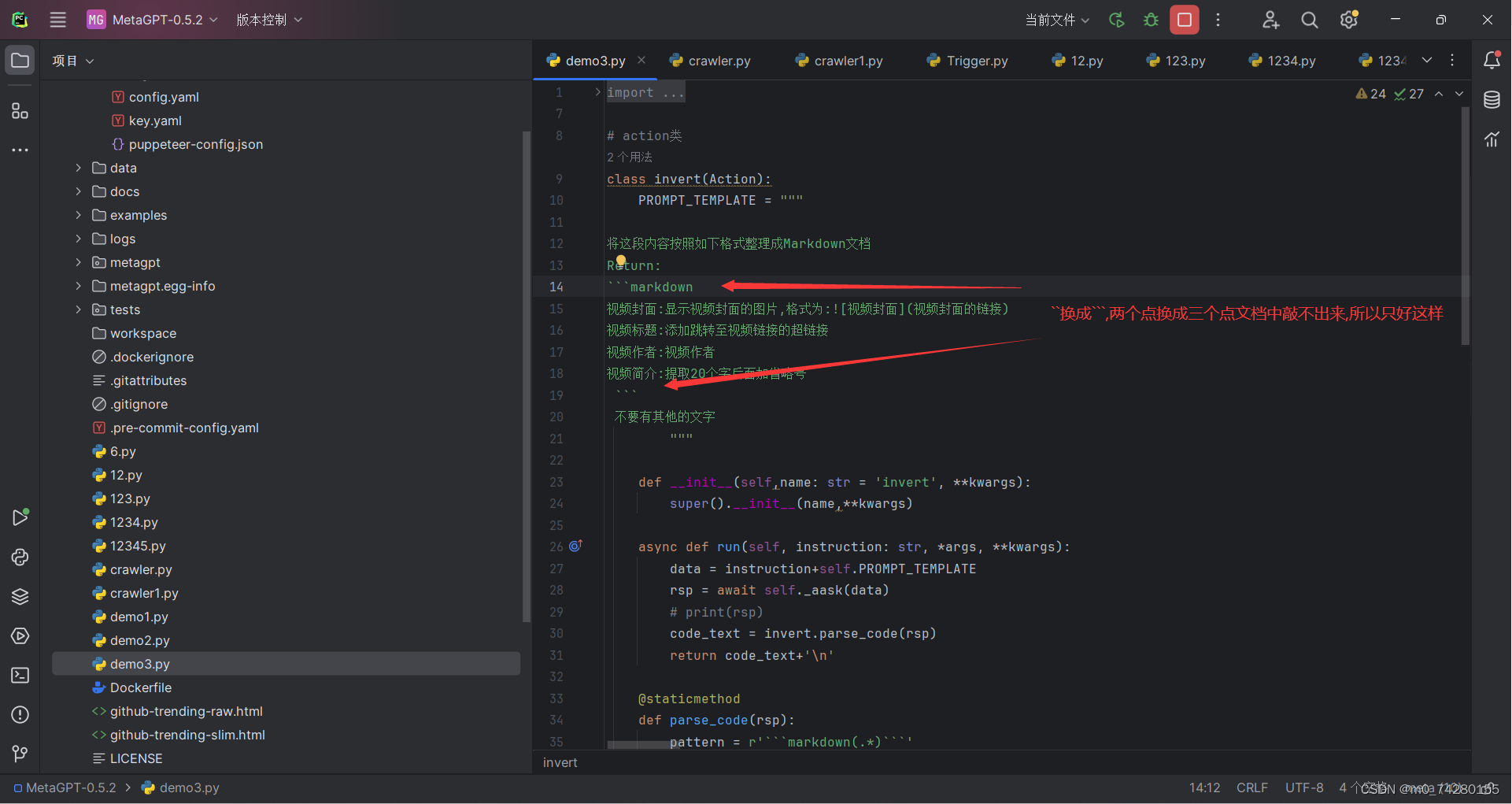
如果运行效果不理想,就把 PROMPT_TEMPLATE 中内容修改成这样,这里敲不出来,所以只好发截图了,下方的完整代码也是同理
代码如下
import asyncio
from metagpt.schema import Message
from metagpt.roles.role import Role
from metagpt.actions import Action
import requests
import re
# action类
class invert(Action):
PROMPT_TEMPLATE = """
将这段内容按照如下格式整理成Markdown文档
Return:
``markdown
视频封面:显示视频封面的图片,格式为:
视频标题:添加跳转至视频链接的超链接
视频作者:视频作者
视频简介:提取20个字后面加省略号
``
不要有其他的文字
"""
def __init__(self,name: str = 'invert', **kwargs):
super().__init__(name,**kwargs)
async def run(self, instruction: str, *args, **kwargs):
data = instruction+self.PROMPT_TEMPLATE
rsp = await self._aask(data)
# print(rsp)
code_text = invert.parse_code(rsp)
return code_text+'\n'
# 正则表达式,获取我们需要的位置的enrichment
@staticmethod
def parse_code(rsp):
pattern = r'```markdown(.*)```'
match = re.search(pattern, rsp, re.DOTALL)
code_text = match.group(1) if match else rsp
return code_text
# role类
class Crawling(Role):
Markdown: str = ""
def __init__(
self,
name:str='xiaopacai',
profile:str='Crawling',
**kwargs):
super().__init__(name,profile,**kwargs)
self._init_actions([invert])
async def _act(self) -> Message:
todo = self._rc.todo
# 爬虫爬取b站排行榜
head = {
"User-Agent": "***", # 自己补上,我的不能给你们看
"Referer": "https://www.bilibili.com/v/popular/rank/all/",
"Cookie": "***" # 自己补上,我的不能给你们看
}
url = "https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=108c53ba3d5d692a90b85aa32c7a513b&wts=1706973855"
html = requests.get(url, headers=head)
content: str = ''
data = html.json()
list_data = data['data']['list']
for index, data in enumerate(list_data[:30]): # 未必只能整三十个,在这里可以修改能获取数量,最多不超过100
name = data['owner']
name1 = name['name']
content = f"第{index + 1}个视频\n视频封面:{data['pic']}\n视频标题:{data['title']}\n视频简介:{data['desc']}\n视频作者:{name1}\n视频链接:{data['short_link_v2']}\n"
code = await todo.run(instruction=content)
self.Markdown += code + '\n\n'
msg = Message(content=self.Markdown)
return msg
async def main():
msg = "爬取b站"
role = Crawling()
return_text= await role.run(msg)
print(return_text.content)
if __name__ == '__main__':
asyncio.run(main())
结果Callback(使用WxPusher发送至微信)
在《MetaGPT智能体开发入门》教程中有相应部分的代码,可是这个代码太复杂了,对于我们这种没有实力的小趴菜来说理解起来有点难度,所以我这里使用简单的方法给大家解释
咱们使用的是WxPusher平台,这个平台不需要梯子,操作起来也很简单(按照《MetaGPT智能体开发入门》教程中并不简单,所以我给简化成一个像我们这种小趴菜都能理解的样子)
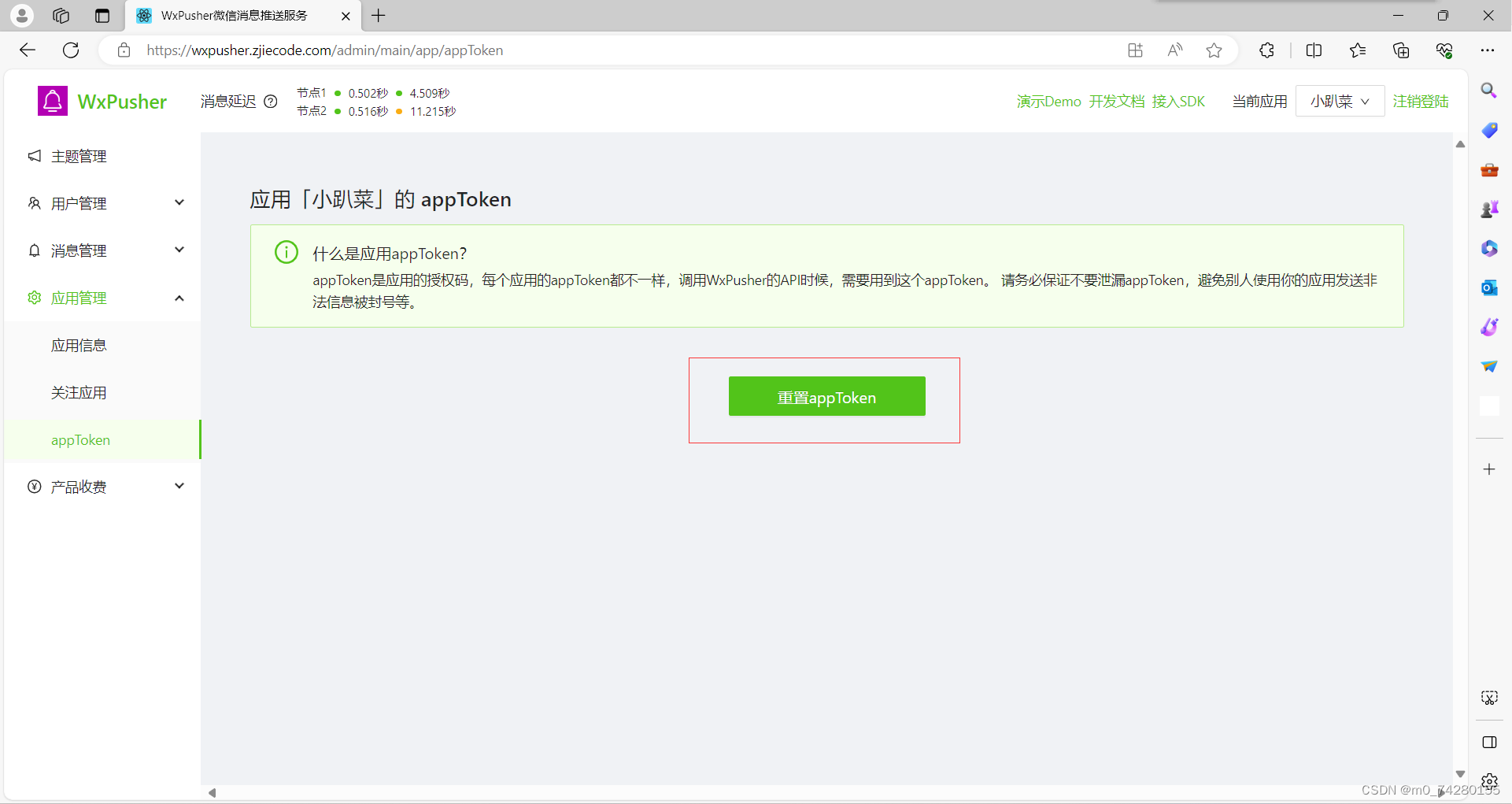
这里的app_token 在平台的这里可以进行复制粘贴
这里的uid_myself 是在有人关注之后,在这里查看

更多关于WxPusher详细教程
import requests
app_token = 'AT_***' # 本处改成自己的应用 APP_TOKEN
uid_myself = 'UID_***' # 本处改成自己的 UID
# 发送消息的方法
def wxpusher_send_by_webapi(msg):
"""利用 wxpusher 的 web api 发送 json 数据包,实现微信信息的发送"""
webapi = 'http://wxpusher.zjiecode.com/api/send/message'
data = {
"appToken":app_token,
"content":msg,
"summary":msg[:99], # 该参数可选,默认为 msg 的前10个字符
"contentType":3,# 内容类型 1表示文字 2表示html(只发送body标签内部的数据即可,不包括body标签) 3表示markdown
"uids":[ uid_myself, ],
}
result = requests.post(url=webapi,json=data) # 将消息推送至微信
return result.text
def main(msg):
result1 = wxpusher_send_by_webapi(msg)
print(result1)
if __name__ == '__main__':
main('hello, world!')
触发Trigger
最后就是我们的触发器Trigger了,这个是我们每天进行设定时间来运行我们的代码,给我们每日推送b站排行榜的一个用处
我们设定时间是在
cron_trigger = bilibiliTrendingCronTrigger(spec="0 8 * * *", tz=None)
中进行修改的,第一个数字代表的是这个小时的第几分钟,第二个数字代表的是每天的第几个小时,文中的"0 8 * * *"代表的是每天早上八点
import time
import asyncio
from aiocron import crontab
from typing import Optional
from pytz import BaseTzInfo
from pydantic import BaseModel, Field
from metagpt.schema import Message
class OssInfo(BaseModel):
url: str
timestamp: float = Field(default_factory=time.time)
class bilibiliTrendingCronTrigger():
# spec:用于指定定时任务的时间规范 tz:用于指定时区 url:链接
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=108c53ba3d5d692a90b85aa32c7a513b&wts=1706973855") -> None:
self.crontab = crontab(spec, tz=tz)
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message(content=self.url, instruct_content=OssInfo(url=self.url))
async def main():
# 创建一个bilibiliTrendingCronTrigger实例
cron_trigger = bilibiliTrendingCronTrigger(spec="0 8 * * *", tz=None)
# 异步迭代cron触发器
async for _ in cron_trigger:
print("1") # 运行的部分
await asyncio.sleep(1)
# 运行main函数
if __name__ == '__main__':
asyncio.run(main())
完整代码
如果运行的结果不满意,可以看一下上方的 实现gpt整理的智能体部分内容,因为格式,我打不出来 ```这个符号
import time
import asyncio
import fire
from aiocron import crontab
from typing import Optional
from pytz import BaseTzInfo, timezone
from pydantic import BaseModel, Field
from metagpt.schema import Message
import asyncio
from metagpt.schema import Message
from metagpt.roles.role import Role
from metagpt.actions import Action
import requests
import re
app_token = 'AT_***' # 本处改成自己的应用 APP_TOKEN
uid_myself = 'UID_***' # 本处改成自己的 UID
# ===========================================智能体部分=======================================
# action类
class invert(Action):
PROMPT_TEMPLATE = """
将这段内容按照如下格式整理成Markdown文档
Return:
``markdown
视频封面:显示视频封面的图片,格式为:
视频标题:添加跳转至视频链接的超链接
视频作者:视频作者
视频简介:提取20个字后面加省略号
``
不要有其他的文字
"""
def __init__(self, name: str = 'invert', **kwargs):
super().__init__(name, **kwargs)
async def run(self, instruction: str, *args, **kwargs):
data = instruction + self.PROMPT_TEMPLATE
rsp = await self._aask(data)
# print(rsp)
code_text = invert.parse_code(rsp)
return code_text + '\n'
@staticmethod
def parse_code(rsp):
pattern = r'``markdown(.*)``'
match = re.search(pattern, rsp, re.DOTALL)
code_text = match.group(1) if match else rsp
return code_text
# role类
class Crawling(Role):
Markdown: str = ""
def __init__(
self,
name: str = 'xiaopacai',
profile: str = 'Crawling',
**kwargs):
super().__init__(name, profile, **kwargs)
self._init_actions([invert])
async def _act(self) -> Message:
todo = self._rc.todo
# 爬虫爬取b站排行榜
head = {
"User-Agent": "***", # 自己补上,我的不能给你们看
"Referer": "https://www.bilibili.com/v/popular/rank/all/",
"Cookie": "***" # 自己补上,我的不能给你们看
}
url = "https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=108c53ba3d5d692a90b85aa32c7a513b&wts=1706973855"
html = requests.get(url, headers=head)
content: str = ''
data = html.json()
list_data = data['data']['list']
for index, data in enumerate(list_data[:2]):
name = data['owner']
name1 = name['name']
content = f"第{index + 1}个视频\n视频封面:{data['pic']}\n视频标题:{data['title']}\n视频简介:{data['desc']}\n视频作者:{name1}\n视频链接:{data['short_link_v2']}\n"
code = await todo.run(instruction=content)
self.Markdown += code + '\n\n'
msg = Message(content=self.Markdown)
return msg
# ===========================================发送WxPusher消息部分=======================================
def wxpusher_send_by_webapi(msg):
"""利用 wxpusher 的 web api 发送 json 数据包,实现微信信息的发送"""
webapi = 'http://wxpusher.zjiecode.com/api/send/message'
data = {
"appToken":app_token,
"content":msg,
"summary":msg[:99], # 该参数可选,默认为 msg 的前10个字符
"contentType":3,
"uids":[ uid_myself, ],
}
result = requests.post(url=webapi,json=data)
return result.text
# ===========================================定时部分=======================================
class OssInfo(BaseModel):
url: str
timestamp: float = Field(default_factory=time.time)
class bilibiliTrendingCronTrigger():
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=108c53ba3d5d692a90b85aa32c7a513b&wts=1706973855") -> None:
self.crontab = crontab(spec, tz=tz)
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message(content=self.url, instruct_content=OssInfo(url=self.url))
# ===========================================运行部分=======================================
async def crawler_main():
msg = "爬取b站"
role = Crawling()
return_text = await role.run(msg)
result1 = wxpusher_send_by_webapi(return_text.content)
print(result1)
async def main():
# 创建一个bilibiliTrendingCronTrigger实例
cron_trigger = bilibiliTrendingCronTrigger(spec="00 8 * * *", tz=None)
# 异步迭代cron触发器
async for _ in cron_trigger:
await crawler_main()
await asyncio.sleep(1)
if __name__ == '__main__':
asyncio.run(main())
最终的效果是这个样子

更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)