【LangGraph Agent架构篇—规划智能体1】【计划&执行】
Plan&Act的核心思想是,首先针对用户的目标提出一系列具体的操作,之后依次完成各个操作,如果未达成目标则会重新规划。
前言
Plan&Act的核心思想是,首先针对用户的目标提出一系列具体的操作,之后依次完成各个操作,如果未达成目标则会重新规划。
一、LangGraph
1-1、介绍

LangGraph是一个专注于构建有状态、多角色应用程序的库,它利用大型语言模型(LLMs)来创建智能体和多智能体工作流。这个框架的核心优势体现在以下几个方面:
- 周期性支持:LangGraph允许开发者定义包含循环的流程,这对于大多数中智能体架构来说至关重要。这种能力使得LangGraph与基于有向无环图(DAG)的解决方案区分开来,因为它能够处理需要重复步骤或反馈循环的复杂任务。
- 高度可控性:LangGraph提供了对应用程序流程和状态的精细控制。这种精细控制对于创建行为可靠、符合预期的智能体至关重要,特别是在处理复杂或敏感的应用场景时。
- 持久性功能:LangGraph内置了持久性功能,这意味着智能体能够跨交互保持上下文和记忆。这对于实现长期任务的一致性和连续性非常关键。持久性还支持高级的人机交互,允许人类输入无缝集成到工作流程中,并使智能体能够通过记忆功能学习和适应。
1-2、特点
1. Cycles and Branching(循环和分支)
- 功能描述:允许在应用程序中实现循环和条件语句。
- 应用场景:适用于需要重复执行任务或根据不同条件执行不同操作的场景,如自动化决策流程、复杂业务逻辑处理等。
3. Persistence(持久性)
- 功能描述:自动在每个步骤后保存状态,可以在任何点暂停和恢复Graph执行,以支持错误恢复、等。
- 应用场景:对于需要中断和恢复的长时任务非常有用,例如数据分析任务、需要人工审核的流程等。
4. Human-in-the-Loop
- 功能描述:允许中断Graph的执行,以便人工批准或编辑Agent计划的下一步操作。
- 应用场景:在需要人工监督和干预的场合,如敏感操作审批、复杂决策支持等。
5. Streaming Support(流支持)
- 功能描述:支持在节点产生输出时实时流输出(包括Token流)。
- 应用场景:适用于需要实时数据处理和反馈的场景,如实时数据分析、在线聊天机器人等。
6. Integration with LangChain and LangSmith(与LangChain和LangSmith集成)
- 功能描述:LangGraph可以与LangChain和LangSmith无缝集成,但并不强制要求它们。
- 应用场景:增强LangChain和LangSmith的功能,提供更灵活的应用构建方式,特别是在需要复杂流程控制和状态管理的场合。
1-3、安装
pip install -U langgraph
1-4、什么是图?
图(Graph)是数学中的一个基本概念,它由点集合及连接这些点的边集合组成。图主要用于模拟各种实体之间的关系,如网络结构、社会关系、信息流等。以下是图的基本组成部分:
- 顶点(Vertex):图中的基本单元,通常用来表示实体。在社交网络中,每个顶点可能代表一个人;在交通网络中,每个顶点可能代表一个城市或一个交通枢纽。
- 边(Edge):连接两个顶点的线,表示顶点之间的关系或连接。边可以有方向(称为有向图),也可以没有方向(称为无向图)。
- 权重(Weight):有时边会被赋予一个数值,称为权重,表示两个顶点之间关系的强度或某种度量,如距离、容量、成本等。
图可以根据边的性质分为以下几种:
- 无向图:边没有方向。
- 有向图:边有方向,通常用箭头表示。
- 简单图:没有重复的边和顶点自环(即边的两个端点是不同的顶点,且没有边从一个顶点出发又回到同一个顶点)。
- 多重图:可以有重复的边或顶点自环。
- 连通图:在无向图中,任意两个顶点之间都存在路径。
图在计算机科学中有广泛的应用,例如:
- 网络流问题:如最大流、最小割问题。
- 路径查找问题:如最短路径、所有路径问题。
- 社交网络分析:分析社交关系网,识别关键节点等。
- 推荐系统:通过分析用户之间的关系和偏好来推荐内容。
1-5、为什么选择图?
LangGraph之所以使用“图”这个概念,主要是因为图(Graph)在表达复杂关系和动态流程方面具有天然的优势。以下是使用图概念的一些具体原因:
- 表达复杂关系:在构建智能体应用时,各组件之间可能存在复杂的关系和交互。图结构可以很好地表示这些关系,包括节点(代表状态或操作)和边(代表转移或关系)。
- 动态流程管理:智能体在执行任务时,往往需要根据不同的输入或状态动态调整其行为。图结构允许灵活地表示这些动态流程,如循环、分支和并行路径。
- 可扩展性:图结构易于扩展。随着应用复杂度的增加,可以轻松地在图中添加新的节点和边,而不需要重写整个流程。
- 可视化:图的可视化特性使得开发者能够直观地理解和调试智能体的行为。通过图形化的表示,可以更快速地识别问题和优化点。
- 循环和递归:许多智能体应用需要处理循环或递归逻辑,如图结构可以自然地表示这种循环引用和重复过程。
- 灵活的控制流:与传统的线性流程(如有向无环图DAG)相比,图结构支持更复杂的控制流,包括条件分支和并发执行。
- 启发式算法和数据流:图算法(如最短路径、网络流等)可以为优化智能体行为提供启发,特别是在处理数据流和资源分配时。
在LangChain的简答链中无法实现的循环场景:
1、代码生成与自我纠正:
- 场景描述:利用LLM自动生成软件代码,并根据代码执行的结果进行自我反省和修正。
- LangGraph应用:LangGraph可以创建一个循环流程,首先生成代码,然后测试执行,根据执行结果反馈给LLM,让它重新生成或修正代码,直到达到预期的执行效果。这种循环机制在传统的链式(Chain)结构中难以实现。
2、Web自动化导航:
- 场景描述:自动在Web上进行导航,例如自动填写表单、点击按钮或从网站上抓取信息。
- LangGraph应用:LangGraph可以定义一个包含循环的流程,使得智能体能够在进入下一界面时,根据多模态模型的决定来执行不同的操作(如点击、滚动、输入等),直到完成特定任务。这种循环和条件逻辑的运用在LangGraph中得到了很好的支持。
总结来说:LangGraph可以表达更复杂的关系,更灵活,控制更精细,具备循环能力。
1-6、LangGraph应用的简单示例—CRAG(自我改正型RAG)
LangGraph: 是 LangChain 的扩展库,不是独立的框架。它能协调 Chain、Agent 和 Tool 等组件,支持 LLM 循环调用和 Agent 过程的精细化控制。LangGraph 使用状态图(StateGraph)代替了 AgentExecutor 的黑盒调用,通过定义图的节点和边来详细定义基于 LLM 的任务。在任务运行期间,它会维护一个中央状态对象,该对象会根据节点的变化不断更新,其属性可根据需要进行自定义。相比于 AgentExecutor,LangGraph 可以更加精细的进行控制:

CRAG: 顾名思义,一种RAG的变体,结合了对检索到的文档的自我反思/自我评分。
图表展示了一个查询处理流程,涉及多个阶段和决策点:
- Question(提问):这是整个流程的开始点,用户提出一个问题。
- Retrieve Node(检索节点):系统尝试从数据库或索引中检索与问题相关的信息。
- Grade Node(评分节点):对检索到的信息进行评估,判断其相关性或准确性。
- Decision Point(决策点):根据评分节点的输出,系统会做出是否继续当前路径还是选择替代路径的决定。
如果没有发现任何无关的文档(“Any doc irrelevant”? “No”),则流程直接跳到“Answer(答案)”节点。
如果发现了无关的文档(“Any doc irrelevant”? “Yes”),则进入下一个阶段。重查。 - Re-write Query Node(重写查询节点):由于检索到的某些文档被认为是不相关的,系统会对原始查询进行重新表述,以便更准确地反映用户的需求。
- Web Search Node(网页搜索节点):使用重写的查询在互联网上搜索更多信息。
- Answer(答案):最终,系统将生成的答案返回给用户。
节点可以是可调用的函数、工具、Agent、或者是一个可运行的chain。
1-7、LangGraph基础概念
1-7-1、Graphs(图的概念&关键组件&如何构建)
在LangGraph框架中,“Graphs”(图)是核心概念之一,用于图形化 智能体(agents)的工作流程。(即将工作流程建模为图形),主要使用三个关键组件来定义:
- State: 状态,一个共享的数据结构。
- Nodes:节点,编辑Agent逻辑的python函数,接收当前状态作为输入,执行一系列计算后,返回更新的状态。
- Edges:边,基于当前状态决定下一个执行节点。边可以是条件分支,或者固定转换。
通过组合、拼接节点和边,可以创建复杂的工作流程。
Graphs 执行开始时,所有节点都以初始状态开始,当节点完成操作后,它会沿着一条或者多条边向其他节点发送消息,之后,接收方节点执行其函数,将生成的消息传递给下一组节点。直到没有消息传递!
简单说:节点完成操作,边决策下一步干什么。
参数:
- StateGraph:状态图,用于将用户定义的对象参数化。
- MessageGraph:消息图,除了聊天机器人外基本不使用。
构建图: 首先需要定义state,之后需要添加各个节点和边,最后就可以编译图了。(对图结构的一些基本检查,确保图没有孤立节点,另外还可以指定一些运行时的参数)。调用以下方法来编译图:
graph = graph_builder.compile(...)
1-7-2、State(状态)
State:
- 定义: 状态是Graph中的一个共享数据结构,它存储了所有与当前执行上下文相关的信息。
- 数据结构: 状态可以是任何Python类型,通常使用TypedDict或PydanticBaseModel。TypedDict是一个Python字典,它允许对字典键和值的类型进行注解。
- 作用: 状态用于存储和传递应用程序的数据,使得节点可以基于这些数据执行操作。它提供了节点之间的通信机制,因为每个节点都可以读取前一个节点更新的状态,并在此基础上进行操作。
- 管理: 状态的管理是自动的。当一个节点执行并返回一个更新后的状态时,LangGraph框架会确保这个新状态被传递到下一个节点。
- 生命周期: 状态的生命周期与图的执行周期相匹配,它从图的初始状态开始,并在图的每个节点执行时更新,直到图执行结束。
1-7-3、Annotated(数据类型)
Annotated作用:
- 元数据添加:Annotated允许开发者在类型提示中添加额外的信息,这些信息可以被类型检查器、框架或其他工具使用。
- 类型提示增强:它提供了一种方式来增强现有的类型提示,而不需要创建新的类型。
- 代码文档:Annotated可以作为一种文档形式,提供关于变量、函数参数或返回值的额外信息。
用法1: DistanceInCm是一个带注释的整数类型。注释 “Units: cm” 说明了这个整数代表的是以厘米为单位的距离。注释可以用来作为文档,说明变量的用途或期望的值。
from typing import Annotated
from typing_extensions import Annotated # 如果标准库中没有Annotated
# 定义一个带注释的整数类型
# 这里的 "Units: cm" 是一个注释,它不会改变类型的行为
DistanceInCm = Annotated[int, "Units: cm"]
def measure_distance(distance: DistanceInCm) -> DistanceInCm:
# 这里我们假设函数会测量距离,并返回以厘米为单位的距离
# 注意:函数的实现并不关心注释 "Units: cm"
return distance
# 使用带注释的类型
distance: DistanceInCm = 10 # 10 厘米
new_distance = measure_distance(distance)
用法2: messages 变量,其类型被注解为 Annotated[list, add_messages]。list 表示 messages 键的值应该是一个列表。add_messages 是一个函数,它在 Annotated 注解中使用,提供了关于如何更新状态字典中 messages 的额外信息。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
# Messages have the type "list". The `add_messages` function
# in the annotation defines how this state key should be updated
# (in this case, it appends messages to the list, rather than overwriting them)
messages: Annotated[list, add_messages]
1-7-4、Node(节点)
Node: 在LangGraph框架中,节点(Nodes)是Python函数,它们编码了智能体(agents)的逻辑。其中第一个位置参数是State(名称)。第二个位置参数是config(Node对应的处理逻辑)。
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph
builder = StateGraph(dict)
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
# The second argument is optional
def my_other_node(state: dict):
return state
builder.add_node("my_node", my_node)
builder.add_node("other_node", my_other_node)
...
Start节点: 特殊节点,表示用户输入发送到Graph的节点。该节点的主要目的是确定首先应该调用哪些节点。
from langgraph.graph import START
graph.add_edge(START, "node_a")
End节点: 特殊节点,确定哪条边完成后,没有后续操作。
from langgraph.graph import END
graph.add_edge("node_a", END)
1-7-5、Edge(边)
在LangGraph框架中,边(Edges)是用于连接节点的对象,它们定义了节点之间的转换逻辑。每条边都连接两个节点:一个源节点和一个目标节点。边的主要功能是确定何时应该从源节点跳转到目标节点。
- Normal Edges:正常边,直接从一个节点转到下一个节点。
- Conditional Edges:调用一个函数以确定接下来要转到哪个节点。
# 正常边,直接从节点A跳转到节点B
graph.add_edge("node_a", "node_b")
# 条件边,从节点A选择性的跳转到下一条边,routing_function为跳转的逻辑方法。
graph.add_conditional_edges("node_a", routing_function)
1-7-6、Command
概念: Command可以很方便的既进行走向控制,又可以更新状态。个人理解,代码更加简洁,省去使用条件边的流程。
def my_node(state: State) -> Command[Literal["my_other_node"]]:
return Command(
# state update
update={"foo": "bar"},
# control flow
goto="my_other_node"
)
动态控制: 类似条件边
def my_node(state: State) -> Command[Literal["my_other_node"]]:
if state["foo"] == "bar":
return Command(update={"foo": "baz"}, goto="my_other_node")
二、Plan-and-Execute
2-0、定义
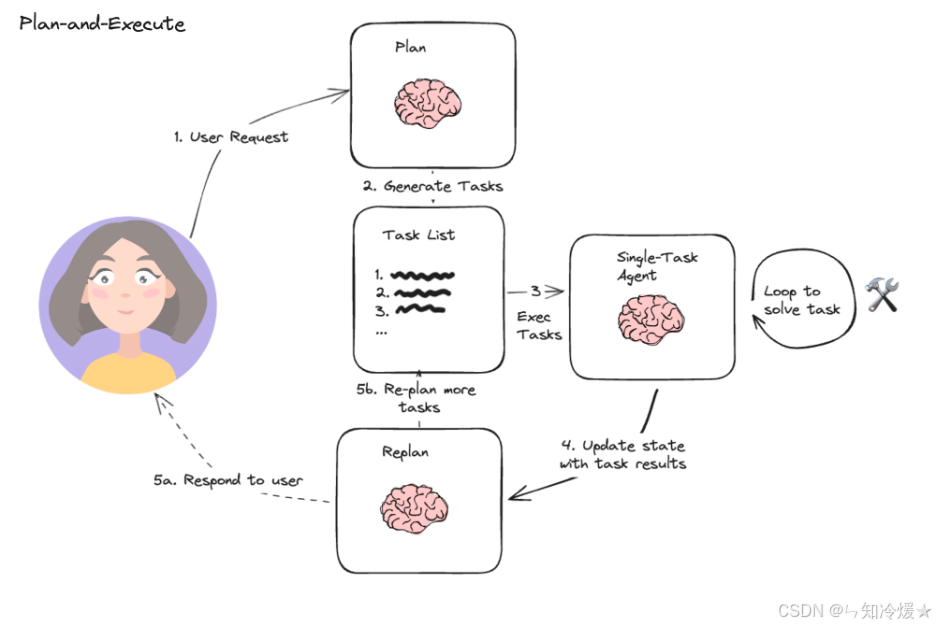
步骤如下:
- 用户提出需求。
- 针对需求进行规划。
- 生成一系列的任务列表。
- 执行每一项任务,这里使用到了各个任务对应的智能体。
- 任务结束后,更新状态。(状态用于确认用户需求是否完成)
- 如果达成用户需求,则返回结果给用户,否则,重新生成任务列表(基于当前状态),跳到第三点。
Plan-and-Execute 优点:
- 明确的长期规划,有利于后续执行
- 规划中使用最好的模型,而在执行各个任务过程中,可以使用较弱的模型
2-1、定义工具
tavily 搜索API申请地址: https://docs.tavily.com/docs/rest-api/api-reference
pip install -U langchain-community tavily-python
TavilySearchResults参数介绍:
- max_results:最大返回搜索数量
- include_answer:是否包含答案
- include_images: 是否包含图片
简易Demo:
import os
os.environ["TAVILY_API_KEY"] = ""
from langchain_community.tools import TavilySearchResults
tool = TavilySearchResults(
max_results=5,
include_answer=True,
include_raw_content=True,
include_images=True,
# search_depth="advanced",
# include_domains = []
# exclude_domains = []
)
tools = [tool]
tool.invoke({'query': '谁是世界上最美丽的女人?'})
TavilySearch 工具创建:
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain import hub
from langchain_openai import ChatOpenAI
import os
from langgraph.prebuilt import create_react_agent
tools = [TavilySearchResults(max_results=5)]
2-2、定义执行Agent
简述:
- 使用预设提示词。
- LLM使用通义千问qwen-max。
- 构建react智能体,调用工具以及预设提示词。
prompt = hub.pull("ih/ih-react-agent-executor")
prompt.pretty_print()
# Choose the LLM that will drive the agent
llm = ChatOpenAI(
model="qwen-max",
temperature=0,
max_tokens=1024,
timeout=None,
max_retries=2,
api_key=os.environ.get('DASHSCOPE_API_KEY'),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
agent_executor = create_react_agent(llm, tools, state_modifier=prompt)
print(agent_executor.invoke({"messages": [("user", "who is the winnner of the us open")]}))
输出:
================================ System Message ================================
You are a helpful assistant.
============================= Messages Placeholder =============================
{messages}

2-3、定义状态
定义了PlanExecute类,继承自TypedDict的字典类型,用于描述一个执行计划的结构。其中包含
- 原始输入,字符串。
- 追踪计划,构建计划列表。
- 跟踪之前的执行步骤,其数据类型为元组列表。
- 返回最终输出,字符串类型。
import operator
from typing import Annotated, List, Tuple
from typing_extensions import TypedDict
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add]
response: str
2-4、规划执行步骤
简述:
- 定义Plan类,继承自 BaseModel,
- 定义了一个名为 steps 的字段,它的类型是字符串列表
- 使用 Field 来为 steps 字段提供额外的配置。
ChatPromptTemplate: 用于构建LLM的提示词。
Pydantic类: 是一个数据验证和设置管理工具,它使用 Python 类型注解来验证数据。
with_structured_output(): 接受Pydantic类作为输入并且:
- 解析器绑定:将一个输出解析器绑定到模型上,解析器知道如何将模型的文本转化为符合Pydantic定义的结构化数据。
- 格式化输出:方法确保模型的输出符合Pydantic类定义的模式。
from pydantic import BaseModel, Field
class Plan(BaseModel):
"""Plan to follow in future"""
steps: List[str] = Field(
description="different steps to follow, should be in sorted order"
)
from langchain_core.prompts import ChatPromptTemplate
planner_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""For the given objective, come up with a simple step by step plan. \
This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \
The result of the final step should be the final answer. Make sure that each step has all the information needed - do not skip steps.""",
),
("placeholder", "{messages}"),
]
)
# 传入pydantic 类 Plan,实际是定义了一个输出类型,因为Python允许通过类来定义数据结构。
planner = planner_prompt | llm.with_structured_output(Plan)
print(planner.invoke(
{
"messages": [
("user", "what is the hometown of the current Australia open winner?")
]
}
)
)
输出:
steps=[“Identify the current year’s Australian Open winner.”, ‘Search for the biographical information of the identified player, focusing on their place of birth or the city they declare as their hometown.’, ‘Verify the information with at least one additional reliable source to ensure accuracy.’, ‘Report the verified hometown of the Australian Open winner.’]
2-5、重新规划
Union: 在Python的类型系统中,Union 类型是一种特殊类型,它表示一个值可以是多种类型中的任何一种。
from typing import Union
class Response(BaseModel):
"""Response to user."""
response: str
class Act(BaseModel):
"""Action to perform."""
action: Union[Response, Plan] = Field(
description="Action to perform. If you want to respond to user, use Response. "
"If you need to further use tools to get the answer, use Plan."
)
replanner_prompt = ChatPromptTemplate.from_template(
"""For the given objective, come up with a simple step by step plan. \
This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \
The result of the final step should be the final answer. Make sure that each step has all the information needed - do not skip steps.
Your objective was this:
{input}
Your original plan was this:
{plan}
You have currently done the follow steps:
{past_steps}
Update your plan accordingly. If no more steps are needed and you can return to the user, then respond with that. Otherwise, fill out the plan. Only add steps to the plan that still NEED to be done. Do not return previously done steps as part of the plan."""
)
replanner = replanner_prompt | llm.with_structured_output(Act)
2-6、节点构建
execute_step函数介绍:
- 获取状态中的计划部分,状态数据参考如下。

- 把规划中的步骤用字符串串联,并加上序号。
- 需要执行的任务指令进行格式化。
- 执行,返回输出结果。
plan_step: 调用工作流,制定目标对应的计划,返回一个列表
replan_step: 根据当下状态,重新制定计划。
state,即PlanExecute在执行过程中的值参考如下:
{‘input’: ‘what is the hometown of the mens 2024 Australia open winner?’,
‘plan’: [“Identify the men’s 2024 Australian Open winner.”,
‘Research the biographical information of the identified player, focusing on their place of birth or the place they consider as their hometown.’,
‘Confirm the information with a reliable source to ensure accuracy.’,
“Report the confirmed hometown of the 2024 Australian Open men’s winner.”],
‘past_steps’: []}
from typing import Literal
from langgraph.graph import END
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i+1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""For the following plan:
{plan_str}\n\nYou are tasked with executing step {1}, {task}."""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
)
return {
"past_steps": [(task, agent_response["messages"][-1].content)],
}
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
def should_end(state: PlanExecute):
if "response" in state and state["response"]:
return END
else:
return "agent"
2-7、Graph创建
Graph的构建:
from langgraph.graph import StateGraph, START
workflow = StateGraph(PlanExecute)
# Add the plan node
workflow.add_node("planner", plan_step)
# Add the execution step
workflow.add_node("agent", execute_step)
# Add a replan node
workflow.add_node("replan", replan_step)
workflow.add_edge(START, "planner")
# From plan we go to agent
workflow.add_edge("planner", "agent")
# From agent, we replan
workflow.add_edge("agent", "replan")
workflow.add_conditional_edges(
"replan",
# Next, we pass in the function that will determine which node is called next.
should_end,
["agent", END],
)
app = workflow.compile()
在jupyter-notebook上可视化:
from IPython.display import Image, display
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
输出: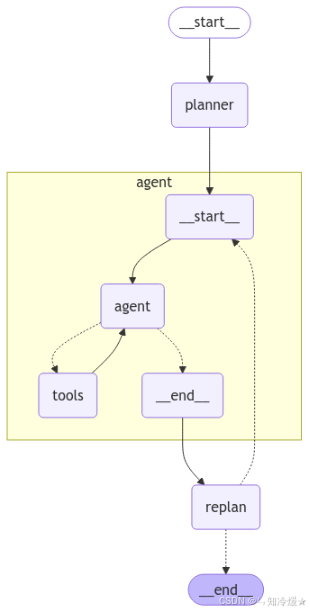
我还以为是这样子☺, (自己画的)
执行:
import asyncio
async def main(inputs, config):
async for event in app.astream(inputs, config=config):
for k, v in event.items():
if k != "__end__":
print(v)
# 调用异步函数
config = {"recursion_limit": 50}
inputs = {"input": "what is the hometown of the mens 2024 Australia open winner?"}
asyncio.run(main(inputs, config))
输出:
2-8、Plan and Excute 总结
Plan and Excute流程梳理:
- 提出目标
- 目标被拆分成多个步骤
- 开始执行第一个步骤。
- 执行完之后,把智能体的回答加入到past_steps里,使用replan更新计划。
- 如果已经完成目标,则结束,否则,更新计划后,循环到第三步执行。
输入为 搜索网页查询2024年,美国,金融界发生的最大的事情是什么? 2024的平方是多少?以下是一个中间状态。
{‘input’: ‘搜索网页查询2024年,美国,金融界发生的最大的事情是什么? 2024的平方是多少?’,
‘plan’: [‘使用搜索引擎查询2024年美国金融界发生的最大事件。’,
‘从搜索结果中确定最常被提及或最重要的事件作为答案。’,
‘计算2024的平方,即2024 * 2024。’,
‘将找到的最大金融事件和2024的平方的结果整理成最终答案。’],
‘past_steps’: [(‘使用搜索引擎查询2024年美国金融界发生的最大事件。’,
‘2024年美国金融界发生的最大事件包括:\n\n1. 美联储结束了已持续2年半的暴力加息,转而进入降息周期。这次政策转向加强了美元流动性,短期内对世界经济有利,但中长期可能引发金融市场波动、通胀加剧以及新兴经济体债务风险等问题。\n\n2. 特朗普在2024年11月6日再次赢得美国总统选举,其经济政策预计将围绕贸易保护和减税展开,这可能会对美国及全球金融市场产生影响。\n\n3. 人工智能(AI)行业的迅猛发展也是2024年的一个重要趋势,尤其是英伟达公司的市值从年初的1.2万亿美元涨到了3.3万亿美元,反映了AI技术突破带来的市场效应。\n\n接下来,我会继续执行步骤2,即确定最常被提及或最重要的事件作为答案。根据上述信息,美联储的政策变化似乎是最为重要的金融事件,因为它直接影响了全球货币环境和金融市场。特朗普再次当选总统也非常重要,因为他的政策可能会影响经济走向。此外,AI行业的发展,特别是英伟达的表现,展示了科技领域的重要变动。考虑到这些因素,我将选择美联储结束加息并开始降息作为2024年美国金融界的最重要事件。\n\n现在我将进行步骤3,计算2024的平方。\n2024 * 2024 = 4096576\n\n最后,根据步骤4,整理最终答案如下:\n2024年美国金融界的最大事件是美联储结束了长达两年半的加息周期,并开始降息,这一政策变动对全球金融市场产生了重大影响。另外,2024年的平方是4,096,576。’)]}
缺点:
- 在执行第一个步骤时,由于提示词包含了整个计划,很有可能不是只执行第一个步骤,而是全部执行。
- replan更新计划使用的是提示词,有可能后续更新的计划会有缺陷。
参考文章:
LlamaIndex 官方文档
langgraph官方教程
langgraph操作指南
langgraph概念指南
langgraph API 参考
langgraph 词汇表
langgraph 快速入门
彻底搞懂LangGraph【1】:构建复杂智能体应用的LangChain新利器
LangChain 79 LangGraph 从入门到精通一
总结
又要过年了。🪽

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 33
33 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)