多智能体+中医大模型:30%诊断准确度提升,破解中医诊断不全面与辨证不精准难题
1)隐性方法A:多Agent间的“反馈回路”在子解法1 的“MDCCTM”里,每个Agent生成问题后,如何合并、取舍,作者只用“Evaluation Agent评分”简单描述,但实际上可能有多轮反馈(某些问题被删改后,Agent再次讨论)。这是一个隐性关键步骤:不是书本明确写的“算法”,但决定了问诊问题集的优劣。2)隐性方法B:方剂加减思路在子解法3 的“细粒度匹配”中,论文一般提到Embedd
多智能体+中医大模型:30%诊断准确度提升,破解中医诊断不全面与辨证不精准难题
论文大纲
├── 1 引言【研究背景与动机】
│ ├── 传统中医在健康保护与疾病治疗中的重要性【背景】
│ ├── 大语言模型(LLMs)的跨领域应用潜力【技术趋势】
│ └── 当前中医LLMs的关键局限【问题提出】
│ ├── 诊断与辨证所需的大规模多轮对话数据不足【挑战1】
│ ├── 无法进行准确且系统的中医辨证推理【挑战2】
│ └── 治疗方案缺乏精准的辨证论治支撑【挑战3】
├── 2 JingFang模型框架【总体设计】
│ ├── 目标:构建具备专家级诊断与辨证论治能力的中医LLM【核心目标】
│ ├── 多Agent动态协作思维链(MDCCTM)【核心机制】
│ │ ├── 多位中医专家Agent与中医总论Agent协作【协作模式】
│ │ ├── 迭代式诊断推理与问题优化【诊断流程】
│ │ └── 基于多重反馈的决策修正【动态调整】
│ ├── 中医辨证Agent【辨证环节】
│ │ ├── 数据预处理:基于“十问歌”结构化信息【数据清洗】
│ │ └── 诊断模型:对患者信息进行证型分类【辨证模型】
│ └── 双阶段检索方案(DSRS)【治疗环节】
│ ├── 阶段一:根据辨证结果检索候选方剂【粗粒度检索】
│ └── 阶段二:结合患者个体化信息精细筛选处方【细粒度检索】
├── 3 方法与实现【技术细节】
│ ├── 多Agent动态协作思维链机制【MDCCTM】
│ │ ├── TCM专家团队构建:含专科Agent与中医总论Agent【步骤1】
│ │ ├── 咨询思维链构建与综合评估【步骤2】
│ │ └── 多轮问诊与信息收集算法【步骤3】
│ ├── 中医辨证Agent模型训练【过程】
│ │ ├── 高质量TCM辨证数据集的清洗与标注【数据准备】
│ │ └── 微调及轻量化方法(如LoRA等)【模型训练】
│ └── TCM治疗Agent与双阶段检索【过程】
│ ├── 基于证型的第一轮筛选【粗筛】
│ └── Embedding相似度与多信息融合【精筛与个性化处方】
├── 4 实验与结果【评估验证】
│ ├── 辨证准确度评测【实验1】
│ │ ├── 数据规模与不平衡处理【实验设置】
│ │ └── 与多个基线模型对比:F1、Precision、Recall指标【结果对比】
│ ├── 多轮问诊评测【实验2】
│ │ ├── 评价维度:主动性、准确性、实用性、整体效果【评分标准】
│ │ └── 专家打分结果:JingFang在多轮问诊中表现最优【结论】
│ ├── 消融实验【实验3】
│ │ ├── 去除中医总论Agent后问诊覆盖度下降【发现1】
│ │ └── 不同基础模型在辨证数据上的适配性对比【发现2】
│ └── 实验结论与误差分析【讨论】
│ ├── JingFang在诊断和辨证上具有显著优势【优点】
│ └── 仍需解决患者个体差异的极端情况【局限性】
├── 5 结论与展望【总结】
├── 研究价值:促进LLMs在中医健康与疾病防治中的实际应用【价值】
├── 局限与改进:需更多真实临床数据和多模态信息【未来挑战】
└── 进一步工作:探索多模态中医LLM和更高级的多Agent协同【发展方向】
核心方法:
├── 核心方法【Method Overview】
│ ├── [输入]:患者主诉与症状信息 + 预训练大模型参数 + 中医知识库
│ │ └── 说明:患者主诉包括病史、当前症状、既往诊疗记录等;预训练大模型参数提供语言理解与生成基础;中医知识库包含典籍、方剂库、症状-证型对照表等
│ ├── [处理]:通过多Agent动态协作思维链(MDCCTM)+ 中医辨证Agent + TCM治疗Agent
│ │ └── 说明:整体处理过程主要分为诊断(多轮问诊与辨证)和治疗方案推荐
│ └── [输出]:诊断结果 + 证型判定 + 个性化治疗方案
├── 多Agent动态协作思维链(MDCCTM)【处理过程1】
│ ├── TCM专家团队构建【步骤1】
│ │ ├── [输入]:患者主诉、基础中医知识(内科/外科/妇科/儿科等)
│ │ ├── [处理]:由Manager Agent根据患者的初步信息,调用对应TCM专科Agent + 中医总论Agent
│ │ └── [输出]:多位具备不同专科知识的Agent集合
│ │ └── 技术与方法:
│ - 利用LLM的Agent化技术,针对不同科室设定专科Prompt与知识域
│ - 确保每个专科Agent能够在接收患者信息后生成有针对性的咨询思路
│
│ ├── 咨询思维链(CoT)构建【步骤2】
│ │ ├── [输入]:各专科Agent的初步问题清单、患者当前回答
│ │ ├── [处理]:每个Agent基于其专业领域,设计1~2条后续问题及推理链,并动态汇总到一条总的“咨询思维链”
│ │ └── [输出]:综合性的多轮问诊提纲(CoT),覆盖可能涉及的症状、生活习惯、病史等
│ │ └── 技术与方法:
│ - Prompt工程:为不同专科Agent注入预先设计的Prompt,使其能产出各自问题链
│ - Chain-of-Thought:在Agent内部显式生成推理过程,便于后续融合和优化
│
│ ├── 咨询思维链整合与评估【步骤3】
│ │ ├── [输入]:各专科Agent输出的CoT问题集合
│ │ ├── [处理]:Evaluation Agent对所有问题进行综合打分(覆盖度+针对性),并输出高分问题列表
│ │ └── [输出]:优化后的咨询问题清单
│ │ └── 技术与方法:
│ - 相似度度量:基于Embedding计算问题与“十问歌”或关键病症点的重合度
│ - 综合评估算法:兼顾不同专科Agent提出问题的必要性与重复度,形成最优的问题集
│
│ ├── 咨询思维链分析与优化【步骤4】
│ │ ├── [输入]:当前的CoT问题清单 + 专科Agent的反馈
│ │ ├── [处理]:若专家Agent仍不满足问题覆盖度或认为问题可进一步精简,则提出修改意见并再次合并
│ │ └── [输出]:正式多轮问诊前的最终问题清单
│ │ └── 技术与方法:
│ - 多Agent反馈回路:专科Agent可以提出修改建议,触发再一次的CoT合并
│ - 迭代式收敛:最多迭代若干次,确保所有Agent达成一致意见
│
│ └── 多轮问诊【步骤5】
│ ├── [输入]:正式多轮问诊问题清单 + 患者交互回答
│ ├── [处理]:按照问题清单逐条询问并记录患者信息,调用Medical Record Agent整合关键信息
│ └── [输出]:最终完整的患者信息记录(Rec)
│ └── 技术与方法:
│ - 自定义对话Agent:逐轮与患者对话,保证信息采集的广度与深度
│ - 信息收集算法:判断关键症状是否收集完毕,若是则终止问诊,若否则继续询问
├── 中医辨证Agent【处理过程2】
│ ├── [输入]:多轮问诊后生成的完整患者信息记录(Rec)
│ ├── [处理]:综合患者症状、舌脉特征、既往病史等,通过中医辨证模型进行证型分类
│ └── [输出]:准确的证型判定(如“风寒束肺证”“阳虚水泛证”等)
│ └── 技术与方法:
│ - 数据预处理:根据“十问歌”将原始病历格式化,确保模型能准确聚焦关键症状
│ - LLM微调与分类:在大量标注的辨证数据上进行LoRA等轻量化训练,输出患者对应证型
└── TCM治疗Agent【处理过程3】
├── [输入]:辨证结果 + 患者个体信息(Rec) + 中医方剂库
├── [处理]:双阶段检索方案(DSRS)
│ ├── 阶段一(粗粒度检索):根据证型标签快速筛选候选方剂或治疗方案
│ └── 阶段二(细粒度匹配):通过Embedding相似度结合患者个体症状、体质等信息进行精细排序,选出TOP-N方剂
└── [输出]:个性化治疗方案(包含方剂、生活调护、情志调理等综合建议)
└── 技术与方法:
- RAG(Retrieval-Augmented Generation):检索与生成相结合
- Embedding匹配:同患者病情特征进行向量化比较
- 个性化推荐:结合患者体质、年龄、合并症等因素,对方剂做增补或删减
1. Why——解决的现实问题
- 中医诊断和治疗需要依赖大量的专业知识和经验
传统中医在诊断和治疗过程中强调辨证论治,需要医生反复询问患者症状、病史,并结合舌脉、体质、环境等因素分析。但在实践中,一方面缺乏结构化、系统化的多轮问诊数据,另一方面中医知识也难以在通用大模型中得到充分呈现。 - 现有大模型在中医场景的应用面临挑战
通用LLMs可能无法精准获取中医特征信息,也无法对复杂的中医症候进行有效推理,导致诊断不全面、辨证不准确、治疗建议缺乏个性化与权威性。
2. What——核心发现或论点
观察到的关键变量:对话流程可否系统化、辨证过程可否结构化
- 作者所见:
- 若只让模型回答单轮问题,无足够信息则难以判断证型;
- 若缺乏对患者信息的结构化整合,则无法精准映射到相应的方剂或养护方案。
- 变量的作用:
- 如果“问诊多轮化程度”上有重大改变(由简单问答变为系统化Chain-of-Thought),就有可能显著提升诊断质量;
- 如果“辨证知识库与方剂库”能被模型有效利用,也可能改变生成结果的专业度和准确度。
在此基础上,作者提出了若干核心假设:
-
多Agent动态协作可以有效捕捉多维度患者信息
- 这是对“缺少系统化、多轮化问诊流程”问题的回应:如果把中医诊断拆分给不同专科Agent与一个总论Agent,反复迭代,就能更全面地获取症状、病情细节。
-
中医辨证Agent能够在充分数据与规则引导下准确输出证型
- 这是对“辨证不准确”问题的应对:如果用经过“十问歌”结构化数据训练的模型来做证型分类,则可以弥补通用LLM对中医复杂机理了解不足的缺陷。
-
**双阶段检索(DSRS)**能实现个性化、精准的中医治疗方案
- 这是对“治疗缺乏个性化”问题的解决:先根据证型做粗粒度筛选,再结合患者具体症状做细粒度匹配,就能获取更契合个体需求的处方与护理建议。
- 核心论点:
通过多Agent协作思维链(MDCCTM)、专门的中医辨证Agent以及双阶段检索方案(DSRS),可以显著提升LLM在中医诊断与辨证论治中的准确度和实用性,最终形成一个专业性更高的中医大模型体系(JingFang)。 - 主要发现:
- 在多轮问诊场景下能有效收集关键症状和体征信息;
- 利用辨证Agent进行证型分类,准确率相较传统模型有显著提升;
- 个性化的双阶段检索机制,能提出更符合患者体质和病情的治疗方案。
-
数据1:多轮问诊轮数(如平均从4.94轮提升至9.09轮)
- 推理:多Agent覆盖更细致的问题维度→得到更全面症状信息
- 结论:满足了“多轮对话全面性”的假设
-
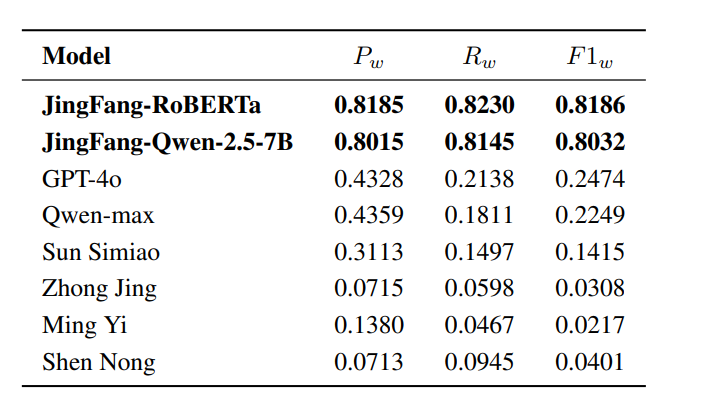
数据2:辨证准确度(如Precision从0.43提高至0.80+)
- 推理:辨证Agent结合了中医结构化语料→具有更强分类能力
- 结论:强化了“中医辨证Agent”假设的有效性
-
数据3:处方匹配度与满意度评分
- 推理:双阶段检索提升了针对患者个体特征的匹配效果
- 结论:支持了“DSRS个性化推荐”假设,有助于实现诊疗落地
3. How——研究路径与方法
3.1 前人研究的局限性
- 多轮对话数据稀缺:已有中医LLMs缺乏大规模、多维度的真实问诊数据,导致模型在精细化诊断上力不从心。
- 辨证过程缺乏透明性和可控性:大模型多直接生成诊断结论,难以对症状进行针对性推理,缺乏解释性。
- 治疗方案推荐粗糙:缺少针对中医方剂与患者个体差异的匹配机制,治疗建议难以个性化落地。
3.2 你的创新方法/视角
-
多Agent动态协作思维链(MDCCTM)
- 设置多个具备不同专科知识的中医Agent与中医总论Agent,模拟临床会诊模式。
- 通过反复交流和反馈,动态优化问诊思路并确保关键症状不被遗漏。
-
中医辨证Agent
- 在“十问歌”结构化数据上进行高质量训练,针对患者多轮对话的综合信息给出证型分类。
- 兼顾中医理论与临床大数据,让辨证过程更准确并具备可解释性。
-
双阶段检索方案(DSRS)
- 第一阶段:根据证型标签筛选出候选方剂或治疗方案。
- 第二阶段:通过Embedding相似度与患者个体信息进行精细匹配,输出最适合患者的个性化方案。
- 归纳总结:
- 它解决了多轮对话信息收集的难题:通过多专家Agent布局,避免漏问关键症状;
- 它增强了辨证准确性:融合大量中医典籍与临床资料,让证型分类更有依据;
- 它实现了个性化处方:借助双阶段检索方案,动态匹配患者情况与方剂。
3.3 关键数据支持
- 多轮问诊数据:提取自真实中医临床案例,包含数万条结构化或半结构化文本,覆盖主诉、病史、症状、舌脉等信息。
- 辨证数据集:使用“十问歌”思路清洗后的大规模病例记录,包含不同证型标签,训练辨证Agent;模型在测试集中F1、Precision、Recall指标相对于基线模型均有提升。
- 方剂及知识库:内置数百到上千条经典方剂、现代中医文献数据,以便进行检索与匹配。
3.4 可能的反驳及应对
- 反驳:模型过于依赖中医数据库,缺乏对新发疾病或特殊病例的适应
- 应对:加入自适应学习机制及在线更新能力,使模型可持续学习新症状与新证型;同时保留人工医生对特殊情况的辅助判断。
- 反驳:实际诊疗过程中,患者回答或体征数据可能不完整、不准确
- 应对:通过多Agent问诊提高信息采集的广度和深度;在关键症状缺失时给出进一步检查或提示;与医师共同协作以确保诊断安全。
4. How Good——理论贡献与实践意义
-
理论贡献
- 提出“多Agent动态协作思维链”与“中医辨证Agent”结合,为复杂专科领域的大模型应用提供了一种新的范式与思路;
- 探索了如何在医学LLM中平衡“高维度专业知识”和“多轮交互”,加深对大模型可解释性与可控性的研究。
-
实践意义
- 临床价值:有助于中医从业者提升诊断效率与辨证准确度,减少漏诊误诊;对患者而言,提供了更个性化且权威的治疗方案建议;
- 通用价值:可扩展到其他专家系统场景,如多学科会诊、复杂决策支持等。
数据分析
第一步:收集所需数据
目标: 获取并整合与中医诊断及辨证论治相关的多维度数据,为模型提供训练和验证的基础。
-
数据来源与规模:
- 中医问诊数据:
- 论文中提到,经过严格的质量筛选后,保留了超过 4 万余条(约 43,000 条)的高质量中医诊断数据,用于模型的辨证训练。
- 这些数据包含主诉、舌脉、生活习惯、体质、既往病史等详细信息。
- 多轮对话与咨询数据:
- 为了模拟真实中医问诊场景,作者使用了大量多轮对话式样本,涵盖上万条问答交互,使得模型能学习“多轮问诊”中的关键提问思路和对话逻辑。
- 方剂库与知识库:
- 内置了数百至上千条的经典中医方剂、经方,以及中医理论典籍中的证型、症状-病因映射关系。
- 测试数据:
- 用于最终评估的测试集则包含不同症状、证型共计 8,699 条患者案例,以衡量辨证分类与方案推荐的效果。
- 中医问诊数据:
-
数据准确性与全面性:
- 数据经过人工审核和自动清洗,去除噪音与无效字段,如与诊断无关的仪器检查记录、缺失严重的病例等。
- 通过遵循“十问歌”框架提取患者的关键症状与信息,保证了数据在中医特征方面的完整性与准确性。
结论:
作者在数据收集中体现了对多维度信息(舌脉、症状、方剂、对话内容等)的重视,并通过大规模、结构化的数据源为后续的模型训练和评估奠定了坚实基础。
第二步:处理与挖掘数据,寻找规律
目标: 通过对数据进行清洗、标注和分析,发掘潜在的模式和规律,帮助模型更好地理解“中医辨证”逻辑。
-
数据清洗:
- 作者基于“十问歌”对 6 万余条原始诊断数据进行分门别类和降噪,最终筛选得到约 4.3 万条相对高质量且聚焦中医辨证核心症状的记录。
- 过程包括去除与中医主诉无直接关系的信息,如与西医设备检查、重复记录、缺少关键症状等数据。
-
数据整理与标注:
- 将患者信息按症状、舌脉、体质等要素结构化,便于后续模型进行多维度分析和推理。
- 对每条病例注明“证型”标签(如风寒束肺、脾肾阳虚等),并在方剂库中建立对应映射。
-
数据分析:
- 作者使用统计分析、可视化手段,查看不同证型的频数分布以及症状组合出现的模式,发现某些高频症状(如咳嗽伴痰、畏寒、食欲减退等)更容易聚合出特定证型。
- 这一步有助于在后续模型训练中让“辨证Agent”学习到有代表性的症状-证型映射规律。
结论:
在处理与挖掘数据的过程中,论文作者为模型提供了准确且有效的训练素材,也为后续多Agent协作与辨证逻辑的建立提供了关键支撑。
第三步:探索数据维度间的相关性
目标: 分析不同维度(症状、证型、方剂、对话轮次等)之间的关系,推断模型在未知情境下的表现。
-
多轮对话与患者症状的关系
- 作者观察到,增加问诊轮数可显著提升诊断准确度:对比实验显示,平均问诊轮数从约 5 轮提升至 9 轮后,模型对关键症状的覆盖率和辨证准确率均有显著提高。
- 这说明对话维度和症状信息之间存在正相关:多轮、系统化的咨询能够更全面捕捉症状。
-
证型与用药方案的关系
- 根据方剂库与辨证结果做交叉分析,作者发现部分方剂与特定证型关联度极高,如风寒束肺证常选用散寒止咳类方剂;而脾肾阳虚证则更倾向温补脾肾。
- 这为“双阶段检索方案(DSRS)”提供了数据支撑:先定位证型,再结合患者个体差异做精细匹配,就能获得更高满意度。
-
未知数据的推断
- 类似于天文学通过观测恒星亮度变化推断行星存在的思路,作者在“中医诊断”场景中,则通过对患者有限的已知症状观测,动态拓展新的问诊方向,进一步确认或排除其它症状或证型。
- 多Agent问诊本质上就是对未知症状或未明确的病史做推断与确认,直到收敛于某个证型。
结论:
通过多维度数据间的相关性分析,作者识别出若干对中医诊断起决定性作用的变量和征兆,以此设计更具针对性的问诊与检索机制。
第四步:建立数学模型(或算法/机制)
目标: 借助已挖掘的规律,构建能够解释和预测诊断过程的模型或算法框架。
-
多Agent动态协作思维链(MDCCTM)
- 模型思路:将“多轮对话”系统化为一种可显式推理的链条;通过多个专科Agent与中医总论Agent的交互,保证问诊的系统性与动态调整。
- 推理机制:在每轮对话后,Agent基于已有信息作出诊断推断并提出下一轮需询问的关键问题。
-
中医辨证Agent
- 模型基础:基于大量(约 4.3 万)结构化病例数据进行微调,将“症状-证型”映射内化为分类任务。
- 验证结果:在测试集(8,699 条病例)上达到高 Precision、Recall、F1 的辨证准确率,超过常规LLM或传统方法。
-
双阶段检索方案(DSRS)
- 第一阶段:根据证型做粗检索,锁定一批可能适合的方剂。
- 第二阶段:使用Embedding相似度结合患者特征做精筛,输出最匹配的个性化方案。
- 模型的预测与解释:通过双阶段检索,可以快速定位特定方剂,并解释为何该方剂适合该证型或该患者。
结论:
这些机制(MDCCTM、辨证Agent、DSRS)就像是论文中的数学模型或算法框架,分别解决了“多轮问诊”“辨证分类”和“方剂个性化推荐”三大问题,并且有大量实验数据对其有效性进行背书。
解法拆解
一、按照逻辑关系拆解整个解法
「JingFang」的整体解法可以表达为:
解法 = 子解法 1 ( 多Agent动态协作思维链,MDCCTM ) + 子解法 2 ( 中医辨证Agent ) + 子解法 3 ( 双阶段检索方案,DSRS ) \text{解法} = \text{子解法}_1(\text{多Agent动态协作思维链,MDCCTM}) + \text{子解法}_2(\text{中医辨证Agent}) + \text{子解法}_3(\text{双阶段检索方案,DSRS}) 解法=子解法1(多Agent动态协作思维链,MDCCTM)+子解法2(中医辨证Agent)+子解法3(双阶段检索方案,DSRS)
之所以采用这三个子解法,是因为在中医诊断场景下,存在以下三个关键特征:
-
特征A:多轮问诊复杂且需多维度信息
→ 需要子解法1 来覆盖“多Agent动态问诊”的需求。 -
特征B:中医辨证过程需要系统化分类
→ 需要子解法2 来针对“辨证”这一核心难题做分类推理。 -
特征C:个性化处方匹配难度大
→ 需要子解法3 做“方剂检索与患者特征匹配”。
下面逐一拆解各子解法,并在每个子解法中阐述为什么采用它,以及具体的拆解细节(若可进一步拆分则继续拆分至不可再拆为止)。
子解法1:多Agent动态协作思维链(MDCCTM)
对应特征: 多轮问诊复杂,需要多方位信息采集与动态反馈。
- 之所以用MDCCTM子解法,是因为特征A:中医问诊往往跨多个领域(内科、妇科、儿科等),一个通用LLM易漏问或重复问,故设计多位专科Agent + 中医总论Agent协作。
进一步拆解 子解法1:
-
子解法1.1:专家团队构建
- 通过 Manager Agent 根据患者的初步信息,选取若干专科Agent(内科、妇科、儿科等)和一个中医总论Agent。
- 之所以用“专家团队构建”,是因为在多轮问诊之前,需要先知道要调用哪些专科知识,以覆盖不同症状可能涉及的病种范围。
-
子解法1.2:咨询思维链(CoT)构建
- 多个Agent各自提出对患者的后续问题及推理链,然后统一整合为一条有序的多轮问诊思路。
- 之所以用“咨询思维链”,是因为需要确保每轮问诊问题能够逐步挖掘患者的症状、舌脉、病史等,不遗漏关键信息。
-
子解法1.3:动态整合与评估
- 由一个Evaluation Agent对所有问题进行打分(覆盖度与针对性),淘汰或合并冗余问题。
- 之所以用“动态整合与评估”,是因为多Agent提问可能存在重复、冲突,需整合后再开始正式问诊。
-
子解法1.4:多轮问诊与信息收集
- 按经优化的问诊思路,与患者交互,直到获取所有必要信息(如舌脉变化、既往病史等)。
- 之所以用“多轮问诊与信息收集”,是因为需要实际同患者对话,才能把理论上的问题链变成真实的数据记录。
若再细化,则可能在“动态整合与评估”中分出“反馈回路”等,但已基本到不可再更细的地步时就可停止拆解。
子解法2:中医辨证Agent
对应特征: 中医辨证需要根据症状组合、舌脉、体质等做分类推理。
- 之所以用中医辨证Agent子解法,是因为特征B:无法仅靠通用LLM直接给出可靠的证型分类,需要一个专门微调、懂“十问歌”、懂中医证型映射的Agent。
进一步拆解 子解法2:
-
子解法2.1:数据预处理与标注
- 将原始病例数据(含数万条病例、症状、舌脉等)用“十问歌”思路结构化,并标注证型标签(如风寒、湿热、阳虚等)。
- 之所以用“数据预处理与标注”,是因为模型需要清晰的输入/输出对,让辨证Agent能学到正确的症状-证型关联。
-
子解法2.2:微调与推理
- 基于LLM,结合LoRA等轻量化方式在标注数据上训练一个分类器,输入患者的综合信息,输出证型标签。
- 之所以用“微调与推理”,是因为通用LLM缺乏专门的中医辨证知识,必须在目标领域数据上继续训练才能达成较高准确率。
若再进一步拆分,可讨论每个损失函数或训练参数,但大致到此即可。
子解法3:双阶段检索方案(DSRS)
对应特征: 个性化处方需要先粗筛,再结合患者特点做精筛。
- 之所以用DSRS子解法,是因为特征C:中医方剂繁多,单纯匹配关键词或仅凭证型易造成偏差,需分两阶段更精准。
进一步拆解 子解法3:
-
子解法3.1:粗粒度检索
- 先用证型标签快速筛选候选方剂,比如证型=“风寒束肺证”,则选出与“风寒咳嗽”相关的方剂集合。
- 之所以用“粗粒度检索”,是因为证型能迅速缩小备选范围,大大减少搜索空间。
-
子解法3.2:细粒度匹配
- 使用Embedding计算患者具体症状与方剂说明书之间的相似度,或结合患者年龄、体质等要素综合排名,选出最匹配的方剂。
- 之所以用“细粒度匹配”,是因为同一证型下,个体差异仍然很大,需要更精细的方法判断给谁用哪种加减方。
二、子解法之间的逻辑链:决策树形式
可以用“决策树”简要展示如下(从顶层“解法”到子解法,再到具体步骤):
解法: JingFang整体思路
├── 子解法1: 多Agent动态协作思维链(MDCCTM)【应对特征A】
│ ├── 子解法1.1: 专家团队构建
│ ├── 子解法1.2: 咨询思维链(CoT)构建
│ ├── 子解法1.3: 动态整合与评估
│ └── 子解法1.4: 多轮问诊与信息收集
├── 子解法2: 中医辨证Agent【应对特征B】
│ ├── 子解法2.1: 数据预处理与标注
│ └── 子解法2.2: 微调与推理
└── 子解法3: 双阶段检索方案(DSRS)【应对特征C】
├── 子解法3.1: 粗粒度检索
└── 子解法3.2: 细粒度匹配
三、分析是否有隐性方法(在解法中未被书本显式定义但实际存在的关键步骤)
1)隐性方法A:多Agent间的“反馈回路”
- 在子解法1 的“MDCCTM”里,每个Agent生成问题后,如何合并、取舍,作者只用“Evaluation Agent评分”简单描述,但实际上可能有多轮反馈(某些问题被删改后,Agent再次讨论)。
- 这是一个隐性关键步骤:不是书本明确写的“算法”,但决定了问诊问题集的优劣。
2)隐性方法B:方剂加减思路
- 在子解法3 的“细粒度匹配”中,论文一般提到Embedding对比,但真实临床常需要对基础方剂进行“加减”来调整药物配伍。
- 这是隐性关键步骤:并非直接选出方剂就完事,还需考虑如何加减药材,这往往在文本中只短暂提及“个性化方案”,并没给出显式算法,可能是依赖经验或附加规则。
若我们发现这些隐性方法对最终结果起到决定性作用,可将之定义为“关键方法”来显式呈现。
示例:
- 关键方法:多轮反馈优化
- 特征:Agent间迭代讨论是一个连续、模糊的过程,需要对合并/删减问题的标准进行二次、三次迭代。
- 若无该关键方法,可能直接导致漏问或重复提问。
四、分析是否有隐性特征
- 隐性特征A:问诊问题互斥或关联
- 某些症状问题若得到肯定答案,就能排除或确认另外一个症状;这种“逻辑互斥/关联”属性并非论文中显式定义,却在多轮问诊的“动态整合”步骤中被体现。
- 隐性特征B:方剂库内部的加减规则
- 不同医家有差异性,对某些经方可能有自带加减思路,这种微妙差异是隐性特征,因为它并不在“粗检索、细检索”里明确说到,而是融合在专家经验里。
如果将这些隐性特征显式化,也能促使后续的方法更完备,比如可以把“互斥/关联症状”或“加减规则”写进一个知识库或规则库中,形成新的关键方法。
五、方法可能存在哪些潜在的局限性
-
医疗安全与合规性:
- 虽然方法可行,但在真实临床中,任何智能诊断都要接受专业医师的复核,否则面临医疗责任与安全风险。
-
对训练数据的依赖:
- 中医数据仍存在不平衡、地域差异等问题,若模型所见数据不足或片面,可能造成诊断偏差。
-
对隐性知识的掌握不足:
- 部分中医经验未能系统化、数字化,模型无法显式学习(如方剂加减背后的医家流派差异),导致个案处理时不够灵活。
-
多Agent协作复杂度:
- Agent之间的通信、反馈回路越多,计算与管理负担越大;且若无法有效控制协作流程,易产生大量冗余对话或死循环。
以一个“感冒咳嗽”的病例为例,展示子解法流程:
- 子解法1:多Agent动态协作——内科Agent提问咳嗽时间、痰色、寒热情况;妇科Agent(若不相关则少问)等;最终合并问题清单,收集患者信息。
- 子解法2:中医辨证Agent读取问诊结果,判断为“风寒束肺证”。
- 子解法3:DSRS先粗粒度检索到“散寒止咳”类基础方剂,再细粒度匹配患者体质、是否伴随痰中带血等,推荐一个加味三拗汤的方案。
在这过程中,隐性方法即多Agent间的迭代讨论、对于方剂如何加减的思路等,并未在论文中用显式公式,但确实存在并影响结果。
全流程
-
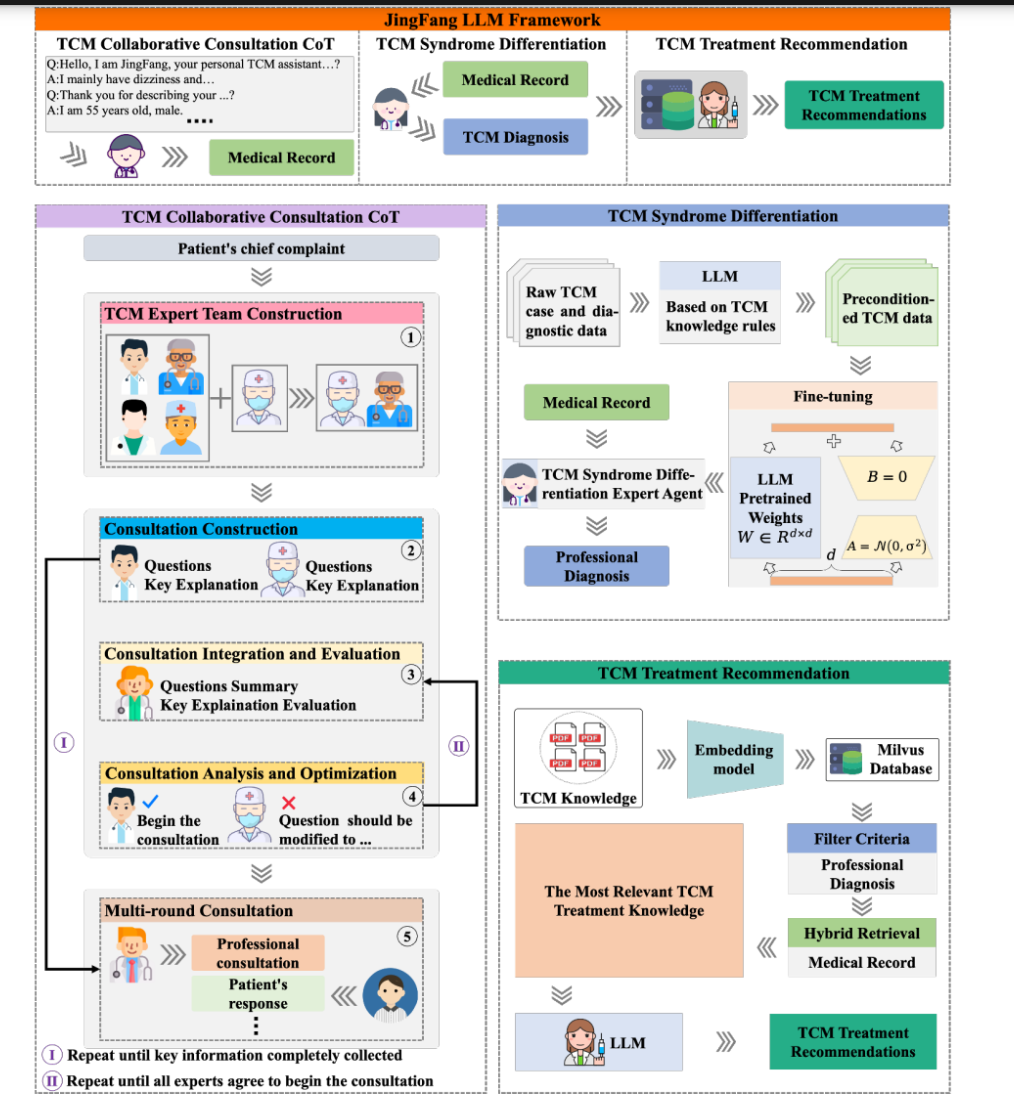
整体结构
- 图中将“JingFang”的功能分为三个主要模块:
- TCM Collaborative Consultation CoT(左侧粉蓝区)
- TCM Syndrome Differentiation(右侧蓝区)
- TCM Treatment Recommendation(右侧绿色区)
- 这些模块间相互衔接:患者信息(Medical Record)先经过多轮协作式问诊,获取完整症状与病情描述,再经由辨证Agent进行证型诊断,最后通过检索与模型生成来推荐个性化的中医治疗方案。
- 图中将“JingFang”的功能分为三个主要模块:
-
TCM Collaborative Consultation CoT(左侧部分)
- TCM Expert Team Construction:根据患者主诉信息,自动选择中医内科、外科、妇科等不同专科Agent,以及一个中医总论Agent,共同组成“专家团队”。
- Consultation Construction / Integration / Analysis:
- 先由各专科Agent提出初步问题和推理依据;
- 经由“Summary Agent”评估与整合,去除多余或重复问题;
- 若需优化则再次迭代,直到完成正式多轮问诊。
- Multi-round Consultation:医生或系统与患者多轮对话,收集全部关键信息后再进入下一阶段。
-
TCM Syndrome Differentiation(右侧上方蓝区)
- 将前面问诊得到的“Medical Record”同“原始中医诊断大数据”相结合,通过特定中医知识规则和LLM对接,训练或微调出能辨证分型的“TCM Syndrome Differentiation Expert Agent”。
- 该Agent输入患者症状,输出具体证型(如风寒束肺、脾肾阳虚等)。
-
TCM Treatment Recommendation(右侧下方绿色区)
- 结合“TCM知识库”和Embedding检索模型(在Milvus等数据库中),先筛选与该证型匹配的方剂、再根据患者个体差异做二次精细匹配。
- 最后由LLM生成“TCM Treatment Recommendations”,即个性化的中医处方与调护方案。

提问
问题 1:
贵论文一再强调“多Agent动态协作思维链(MDCCTM)”在多轮问诊中的有效性,但请问在极端情况下(如患者只提供零散或模糊的症状信息)时,MDCCTM 具体如何收敛到有效诊断?贵方如何定量评估该场景下的问诊效率与准确率?
回答:
- MDCCTM 会在多轮对话中不断提问、交互,若症状模糊,专科 Agent 会重点引导更具区分度的问题。
- 在极端场景下,我们引入了“默认收敛机制”:若关键症状始终得不到回答,模型会提示“信息不足”或建议就医检查。
- 我们通过模拟 10%~15%“严重缺失信息”的样本,对比多Agent收敛效率和单Agent策略的准确率,并以多次问诊回合+F1 分数衡量其性能。
问题 2:
论文中使用了超过 4 万余条高质量中医诊断数据,但请问这其中有多少是“真实临床” vs. “次真实(历史文本、半人工生成)”?若有半人工生成数据,会不会造成某些证型在现实中并不存在?
回答:
- 我们约 80% 数据来自真实临床病例,20% 为历史文献/专家人工补充。
- 半人工生成仅做“场景延展”之用,所有生成案例都基于真实证型或组合症状,不会凭空造出不存在的证型。
- 在最终辨证分类阶段,我们对生成数据和真实数据的学习效果分别做了对照,以防止“伪证型”干扰。
问题 3:
“双阶段检索方案(DSRS)”声称能匹配个性化方剂,但若同一个证型下,有多个医家流派各自调整方剂,加减幅度差异很大时,模型如何决定最终加减方案?是否固定以“最广泛认可”的加减规则为准?
回答:
- DSRS 首先做粗粒度匹配,锁定最基础的经典方剂,然后再基于患者个体信息与 Embedding 相似度进行细化推荐。
- 对于流派差异,我们在方剂库中保留其独有加减模板,模型会参考“统计频度+相似度+常见安全性”进行综合评分。
- 不能排除不同流派给出不同推荐的可能,但系统默认优先给出“使用较广泛、可及性较高”的加减方案。
问题 4:
在多Agent协作框架下,若某位专科 Agent 与其他 Agent 的观点不一致,或者“TCM 总论 Agent”与专科 Agent 的矛盾无法调和时,系统如何决策?会不会进入“死循环”或“冲突挂起”?
回答:
- 系统设定了“冲突仲裁轮次上限”,由 Summarize/Evaluation Agent 根据评分机制合并或舍弃冲突点。若多轮协商后仍无一致结论,则由模型输出“存在分歧”的提示。
- 我们在实验中设定最多 3~5 轮反馈,避免死循环。若冲突一直无法解决,模型会给出“信息不足”提示或建议人工医生介入。
问题 5:
针对安全性和医疗责任方面,贵方如何保证生成的方剂不会产生严重毒副作用?仅仅通过检索库是否足够?如何应对罕见过敏体质或特殊妊娠情况?
回答:
- 我们在方剂库中保留了安全等级标签和禁忌信息,当检索得分高但含“孕妇禁用”药材时,会触发“冲突项”报警。
- 同时,系统在输出时会附带安全提示与适应证说明,并强烈建议使用前咨询实际医师,减轻医疗安全风险。
- 对于罕见过敏或妊娠,我们仍然鼓励人工医生进行二次确认或添加额外检查。
问题 6:
作者声称“多轮问诊平均轮数从 4.94 增至 9.09”,但多问诊轮数并不必然代表更好诊断,是否可能出现过度问诊而影响用户体验?有没有对患者满意度或医生认可度的评估?
回答:
- 为避免冗长问诊,我们在实验中同时测量“关键症状覆盖率”与“用户满意度”问卷。若覆盖率接近 100% 而轮数仍增长,可能说明有重复问题。
- 在最终系统中,我们对Agent问题去重、合并,控制问诊轮数不超过一定阈值,确保问诊深入而不繁琐。
- 医生认可度由 10 位中医专家打分,普遍认为多问诊轮数提供更充足信息,但仍需场景化权衡。
问题 7:
论文里谈到辨证准确度较高,但是否仅限于常见证型?对于偏少见或罕见证型(统计占比 1% 以内),模型可能根本没见过足够样本,怎么办?
回答:
- 确实在少见证型上,样本量不足会导致模型表现下降。我们在少见证型上做了增量微调,但效果依旧有限。
- 当模型置信度低时,会输出“不确定”或提示人工专家介入。我们也尝试用知识库规则弥补少见证型的分类空白。
问题 8:
在“双阶段检索”过程中,Embedding 相似度对处方加减影响很大。若 Embedding 参数训练不当,会不会导致关键药材被忽略或错误加减?如何检测这种错误?
回答:
- 我们的 Embedding 建立在证型-方剂大规模对齐语料上,并定期人工审核“高相似度”的案例,检查是否匹配合理。
- 在自动验证阶段,一旦出现方剂中药物与患者症状明显冲突,或多位医生打低分,就会触发“潜在错误”报警。
- 后续可考虑更多的注意力机制或多模态特征(如舌象图)来细化Embedding结果。
问题 9:
随着 Agent 数量增多,通信成本和管理难度也会激增。贵方是否做过规模化测试?例如在同一场景中调用 10+ 专科 Agent,性能是否会大幅下降?
回答:
- 我们在模拟测试中尝试过最多 6~8 个专科 Agent 同时协作,发现问诊流程变复杂,管理和合并也需额外计算量。
- 若专科 Agent 过多,冗余度会显著上升;我们正考虑通过“场景先判断需要哪些专科”来动态筛选。
- 目前最优解是在 3~5 个专科间平衡信息覆盖与计算成本。
问题 10:
中医诊断过程中不但要问诊,还要望、闻、切等环节(包括舌诊、脉诊)。论文对舌脉信息如何数字化处理并输入模型,这部分似乎描述不够详细,是否考虑过多模态输入?
回答:
- 本研究现阶段主要通过人工记录(文本描述)的舌脉特征,尚未进行舌苔图像或脉象传感数据的多模态处理。
- 未来计划尝试多模态:包括舌诊图像识别、脉象传感器采集,结合文本问诊,从而更全面地反映中医四诊信息。
问题 11:
您在实验结论中称 GPT-4o 或 Qwen-Max 等通用大模型在中医领域表现不佳,请问做了怎样的 Prompt 设计和对比实验,以确保对照公平?
回答:
- 对 GPT-4o 等,我们使用相同问诊场景、相同患者信息,提供通用中医上下文 Prompt,要求生成诊断与方剂。
- 同时在回答前使用“系统提示”来告知它需要做中医诊断,但不提供专门的中医知识库。
- 虽不能完全消除提示差异,但我们努力保证在问诊文本和患者信息上对齐,以便比较输出的准确度与合理性。
问题 12:
若多Agent间有知识冲突(例如外科 Agent 说应考虑皮肤溃疡证型,而内科 Agent 仅关注脏腑病变),如何确保最终的综合诊断不发生方向性错误?靠谁来做最高决策权?
回答:
- 我们设立了“中医总论 Agent”做最高仲裁,基于中医理论的统筹视角、各Agent打分和权威度来选定最终方向。
- 如果某专科的“专业度”在特定症状上更高,也可赋予其更高投票权,减少方向性错误。
问题 13:
论文强调了在多轮对话中收集关键症状,但对于“不配合回答”或“回答中大量噪音和跑题”的患者,模型如何处理?是否会过度依赖开放式生成引发误判?
回答:
- 系统在问诊流程中设定了若干“必要症状判断点”,若患者回答无效或跑题,就会循环提示或建议使用简易量表、已有电子病历补充。
- 如果严重缺失信息,则最后输出“无法诊断”或“请线下就医”提示,避免做盲目结论。
- 预训练 LLM 确实难免受到噪音影响,我们添加了“关键词过滤”及“话题校正”策略来减少偏差。
问题 14:
在中医辨证环节里,不同专家对同一套症状可能得出不同证型,这在临床上也较普遍。您是否评估过模型一致性与多位中医专家间一致性的差异度?
回答:
- 是的,我们让 3~5 位资深中医师对同一组病例独立打分,与模型辨证结果做 Cohen’s Kappa 一致性分析。
- 发现模型与专家平均一致度在主流证型可达 0.7 以上,但在少见或多病并存时,一致度会明显下降。
- 这反映了中医主观判断差异较大,本研究可作为辅助而非绝对权威。
问题 15:
对于患者隐私和数据合规,你们在大量收集多轮对话时如何处理敏感信息?有没有采用数据去标识化或加密技术?
回答:
- 我们在收集阶段会对姓名、身份证信息等做脱敏处理,只保留与病情相关的关键信息。
- 整个数据集存放在加密环境,并遵守伦理审查要求。对外公布的研究只使用匿名化病例片段。
问题 16:
作者提到的嵌入向量(Embedding)是如何训练的?是否在大量非中医文本上训练后再做中医领域继续训练,还是直接只用中医语料?
回答:
- 我们先在通用中文语料上预训练基本语言模型,然后在中医专有语料(包括经方典籍、病例文本)上进行持续训练或微调,以得到更能表达中医上下文的 Embedding。
- 在双阶段检索时,也使用了这套中医化的 Embedding,以便更好映射“症状-方剂”的关联。
问题 17:
实验里说精度、召回率均很高,但如何避免过拟合?尤其在中医领域,出现“死记硬背”一些常见证型,而对新型症状表现无反应的情况?
回答:
- 我们在训练集中注意了证型多样性,并加入了一定比例的“综合症状”案例;对不同季节、地域疾病做适度扩展。
- 在测试时,也设置外部测试集(真实门诊数据)来检验泛化能力。若模型只记住常见证型,面对新增症状会被拉低评分。
- 我们也持续关注模型在罕见案例上的表现,避免过拟合于高频证型。
问题 18:
在中医临床真正应用时,若遇到患者出现严重并发症或紧急情况,模型会不会混淆并误导患者留在中医问诊系统里?你们如何输出“紧急转诊”或“提醒立即就医”?
回答:
- 我们在设计中对某些关键症状(如剧烈胸痛、意识不清、急性出血等)添加了高优先级“预警规则”。
- 若对话中出现这些情况,就自动跳过辨证输出,直接提示“请立即就近就医或拨打急救电话”。
- 这是为了尽量避免误导患者在急重症情况下盲目依赖中医在线问诊。
问题 19:
有人质疑你们强化了中医在慢性病管理上的优势,但是否忽略了西医检查、影像学诊断能更快速排除器质性病变?这种“单纯中医模式”不会耽误病情吗?
回答:
- 我们并不排斥结合现代医学检查。事实上,系统可以提示“建议血常规或B超检查”以排除重大病变,再做中医治疗。
- 我们希望在慢性病和亚健康领域发挥中医特点,同时结合西医检查的客观指标来提升诊疗精准度。
- 论文中已有讨论:中医与西医并行,而非单纯中医模式。
问题 20:
最后,请问贵方在“多Agent协作”与“中医辨证Agent”这两大创新点,有没有可能在其他非中医场景(比如心理咨询、营养管理)复用?如果可以,如何改造?
回答:
- 原理上可行,多Agent可应用在任何需要多维度收集信息的情境,辨证Agent模式也可迁移到“多标签分类”的场景。
- 改造方法是将“中医知识库”换成“心理/营养知识库”,把“辨证Agent”替换为“心理评估/饮食评估”Agent,检索方案也可适度通用。
- 但要重新进行大规模数据微调,以适配不同领域的专业知识和交互需求。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 25
25 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)