

论文阅读——MO-MIX:基于深度强化学习的多目标多智能体协作决策(IF=20.8)
为了提高最终解的一致性,对一个包含迄今为止找到的所有非支配解非支配集,在训练阶段,每一集采样一个ω,作为网络的输入。如果某一个子空间中的解比较稀疏,则其中偏好的采样概率会增加,这允许对性能较差的子空间中的权重进行更多次的采样和训练。MOMN将CAN的输出作为输入,首先基于目标对n个智能体的Q向量进行重组,组合对应于某个目标的所有Q值合并馈送到某个MOMN并行轨道中,然后将多个轨迹输出连接为整个网络
原文连接:
目录
贡献
1.提出了一种新的多目标多智能体协同决策方法MO-MIX,该方法能够根据输入偏好生成多种策略,并最终得到稠密且高质量的Pareto集近似。
2.提出了一种探索引导方法。在训练过程中引导算法的探索方向,改善了最终Pareto集逼近的一致性。
Pareto集
MO-MIX
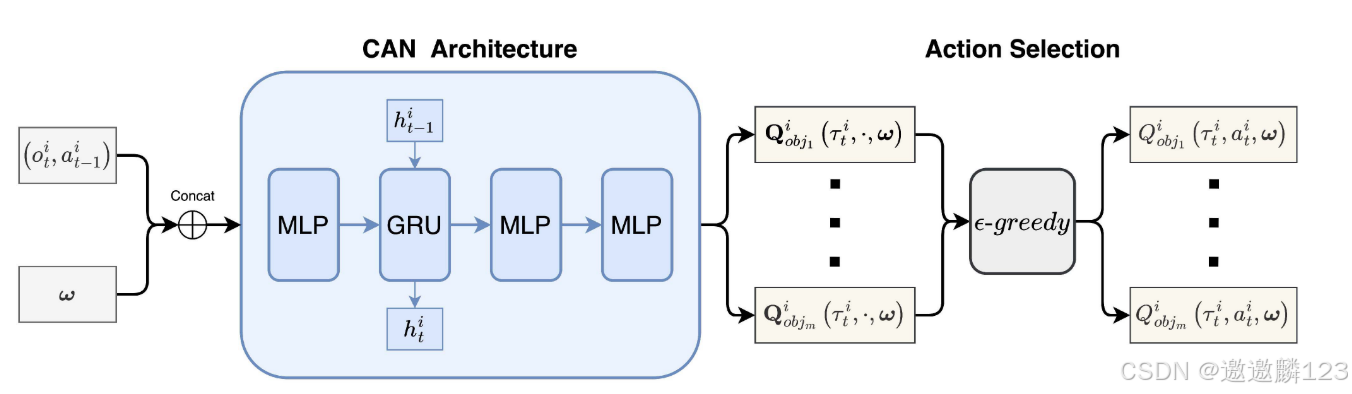
条件代理网络(CAN)
CAN是CTDE框架的分散执行部分。
目的:估计行动价值向量函数Q,其中包括所有目标的价值函数。
CAN由几个多层感知器(MLP)层和一个门递归单元(GRU)层组成。
GRU
参考
【深度学习 搞笑教程】30 门控神经单元GRU | 草履虫都能听懂 零基础入门 | 持续更新_哔哩哔哩_bilibili
GRU是一种能够更好地处理序列信息的递归神经网络。GRU的输出不仅与当前时间步的输入有关,而且与历史输入有关。因此,CAN可以利用Agent的整个观察和动作历史,从而弥补局部观察的不足。
MLP
参考
MLP是万能函数模拟器,考虑到动态权值的自适应性,在GRU之后连接两层MLP,以提高网络的表示能力。
需要使用不同的偏好来训练模型,从而增加非支配集的多样性,找到一个帕累托集合近似。
每个智能体使用其各自的CAN来估计部分多目标Q函数并选择动作。
网络的输入:智能体的观察和动作信息,以及表示偏好的偏好向量ω。输入偏好向量的目的是训练模型基于输入偏好产生适当的策略,使神经网络以特定的权重作为条件来估计向量Q函数。
由于观察和动作信息的维数明显大于偏好向量的维数,为了避免偏好信息被模型忽略,多次复制偏好向量ω。
GRU层用于利用部分观测历史。
CAN的输出是每个可选动作的多目标Q向量,每个向量包含m个目标的Q值。代理根据-greedy策略独立选择最佳动作。
多目标混合网络(MOMN)
MOMN为集中式训练部分。
目的:处理多智能体系统环境的非平稳性问题,使用基于全局观察的联合动作值函数来评估智能体的行为。
具有并行结构的混合网络,用于产生多个目标的值。
MOMN将CAN的输出作为输入,首先基于目标对n个智能体的Q向量进行重组,组合对应于某个目标的所有Q值合并馈送到某个MOMN并行轨道中,然后将多个轨迹输出连接为整个网络的输出,输出联合动作值向量。在时间步t的全局状态st被馈送到几个超网络,并用于生成混合网络的权重和偏置。
为满足单调性约束,使用多个超网络来产生混合网络的MLP层的权重和偏差,这与QMIX方法相同。
QMIX
参考
https://zhuanlan.zhihu.com/p/362683452


对于每个神经网络层,使用两个超网络来生成其参数。一个用于权重,另一个用于偏差。每个MOMN轨道有两个MLP层,因此一个轨道有四个超网络。
每个产生权重的超网络由一个线性层组成,并使用绝对值激活函数来确保输出是非负的,这保证了混合网络的输出满足单调性约束。
产生偏差的超网络不需要绝对值激活函数,因为偏差没有非负约束。
对于每个轨道的最后一层的偏差,使用两层超网络并使用ReLU激活函数。
所有的超网络都以全局状态s作为输入,保证混合网络可以利用全局观测信息。
探索引导方法
权值ω表示不同目标的优先级,它不仅决定了Agent动作的评价标准,也决定了算法的探索方向。但是,对于相互矛盾的多目标,对目标进行加权转化为单目标问题并不能保证最终策略与偏好相匹配。在MORL中,反映在最终非支配集的一致性上。
为了提高最终解的一致性,对一个包含迄今为止找到的所有非支配解非支配集,在训练阶段,每一集采样一个ω,作为网络的输入。在实际中,偏好向量是一个角度向量,其角度范围为0-90度,因此根据角度将偏好空间均匀地划分为四个部分。如果某一个子空间中的解比较稀疏,则其中偏好的采样概率会增加,这允许对性能较差的子空间中的权重进行更多次的采样和训练。非支配集被周期性地重置,以确保它反映当前的策略质量。
算法框架

评价方法
使用了四种评估度量来评估多目标算法生成的非支配集:
超体积度量(HV):由参考点和通过算法获得的非支配解所包围的目标空间中的区域的体积。HV值越大,算法的综合性能越好。如果一个解集P优于另一个解集Q,则解集P的超体积度量将大于解集Q的超体积度量。是一种Pareto相容的评价方法。
间隔度量:非支配集中连续点之间的欧几里德距离的标准偏差,间距值越小,解集越均匀。
稀疏性度量:非支配集中连续点之间的平均平方欧几里德距离,稀疏性度量越小,解集越密集。
多样性度量:最后的非支配解的数目。多样性度量越高,算法能找到的非支配解越多,效果越好。
实验结果
1.与baseline对比


2.不同偏好采样间隔

3.与无探测引导部分的MO-MIX对比

更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)