【论文阅读笔记】Social-SSL: 基于Transformer的自监督交叉序列表示学习用于多智能体轨迹预测
【ECCV 2022】Social-SSL: Self-supervised Cross-Sequence Representation Learning Based on Transformers for Multi-agent Trajectory Prediction

前言:最近实验室给了许多行人轨迹预测方面的论文,这是阅读的第一篇,尝试记录论文内容,加深自己的理解~坚持就是胜利!
一、背景与动机
多智能体轨迹预测是理解和预测多个智能体在复杂环境中行为的重要任务。随着智能交通系统和自动驾驶技术的发展,预测行人和车辆的运动轨迹变得尤为重要。
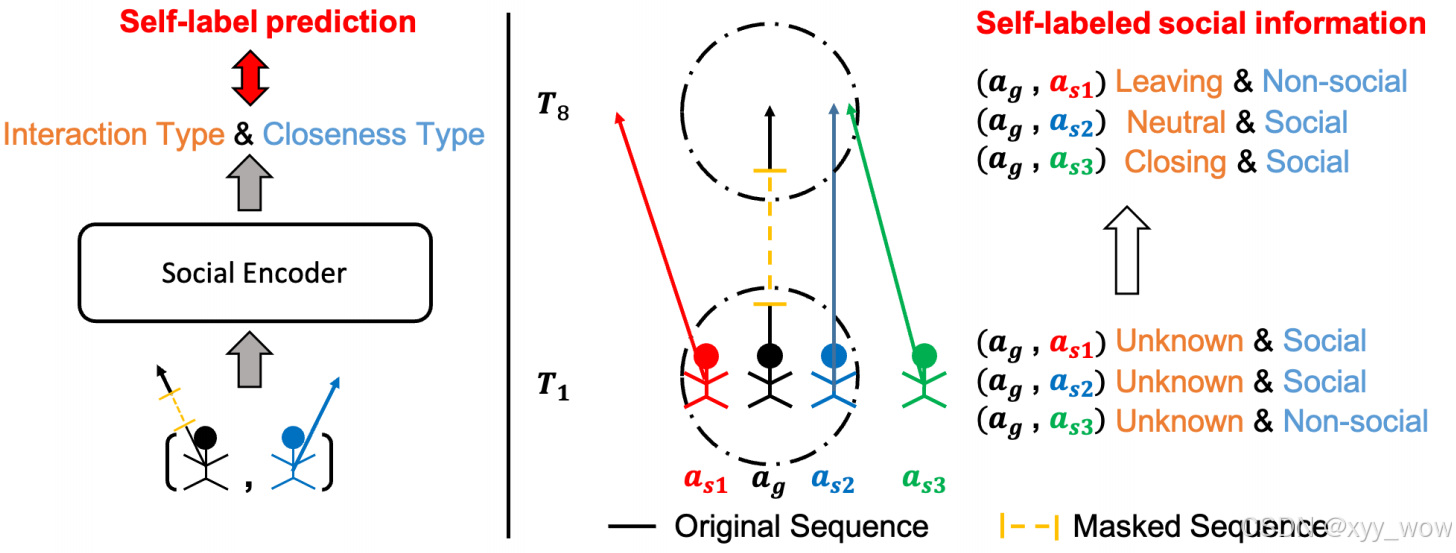
早期的轨迹预测方法侧重于利用循环网络捕获行人之间的序列结构,已知这种方法在捕获长序列结构方面存在一些局限性。为了解决这个限制,最近的一些工作提出了基于transformer的架构,它是用注意力机制构建的。然而,这些基于transformer的网络是端到端的训练,而没有利用预训练的价值。作者提出了通过自监督预训练捕获交叉序列轨迹结构的Social-SSL,这在提高Transformer网络的数据效率和轨迹预测的可泛化性方面起着至关重要的作用。具体来说,Social-SSL通过三个代理任务来建模交互和运动模式:交互类型预测、亲密度预测和掩蔽交叉序列到序列的预训练。
本篇论文的主要贡献如下:
-
跨序列相互关系学习的两个社会相关代理任务:交互类型预测和亲密度预测,学习场景中每一对智能体之间的社会交互模式。
-
跨序列关系内学习的动作相关代理任务:掩蔽交叉序列到序列的预训练,从目标智能体自身序列的非屏蔽部分学习目标智能体的运动,并通过交叉序列结构发现其与周围社会智能体的相互关系。
-
通过利用自监督表示学习的优势,即使在少量轨迹数据上进行训练,Social-SSL也能在轨迹预测任务上取得最先进的结果。此外,还可以提高轨道预测任务的泛化能力。
二、相关工作
(简略别的方法,着重看本论文的~)
基于数据的重要性。Social - LSTM是一项开创性的工作;SocialGAN修改了池化模块;SoPhie提出了社会关注的概念;最近引入了新的思想,如Graph Attention Networks,用于模拟行人之间的社会互动。
利用Transformer来解决轨迹预测问题越来越受欢迎。Transformer TF首次引入了Transformer用于单智能体轨迹预测;STAR引入了一个Graph Transformer Network;AgentFormer设计了具有更好的多模态特性的时空转换器。
三、Social-SSL
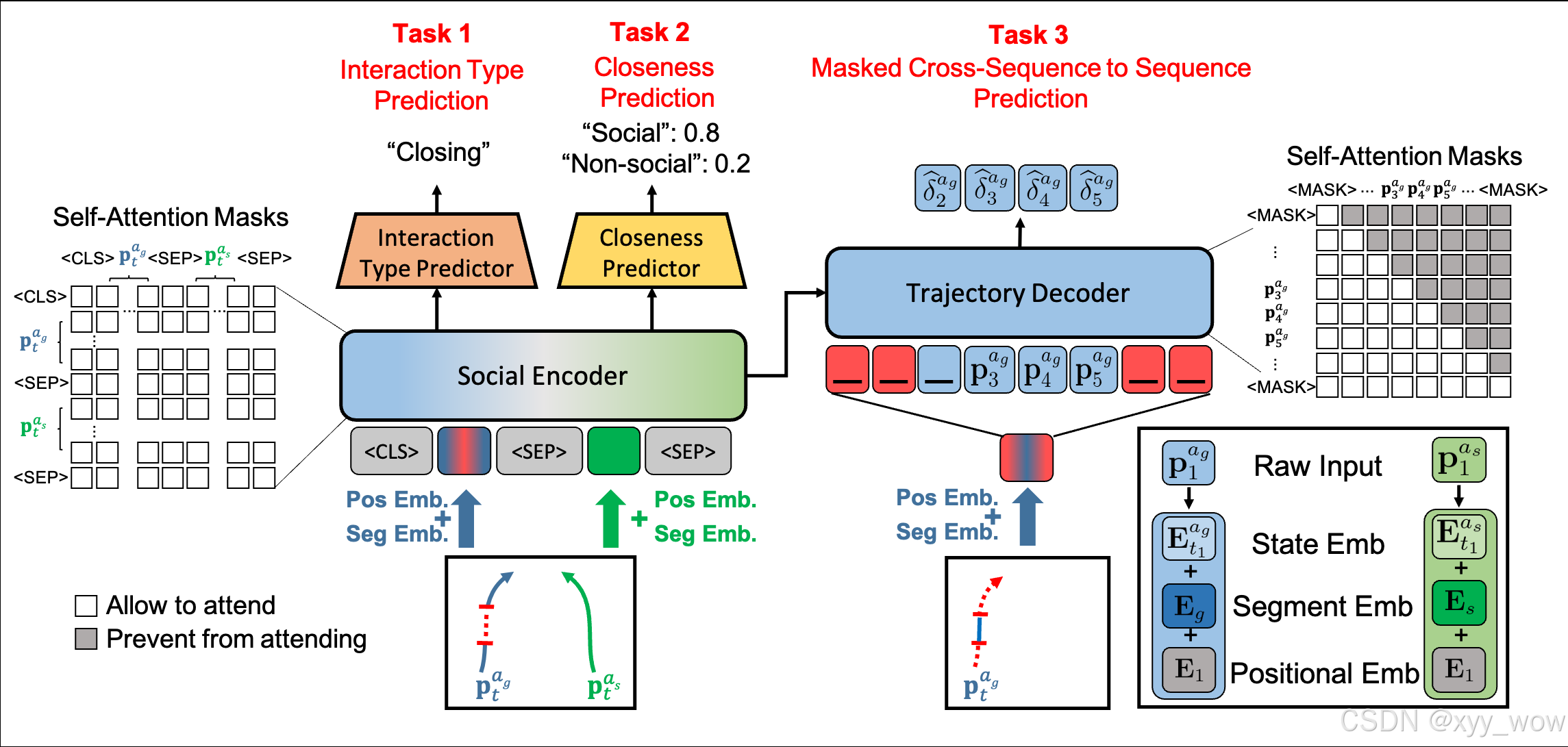
下图为Social-SSL预训练架构。
在Social-SSL中,将社会编码器和轨迹解码器设置为简单的Transformer编码器和解码器,这对于预训练任务来说简单而有效。由于这三个代理任务是同时训练的,并且共享相同的社会编码器参数,因此与掩蔽的交叉序列到序列任务一起,轨迹解码器被迫分别考虑通过目标智能体的运动和来自社会编码器的影响社会信息的智能体之间的内部和相互关系。经过这些代理任务的训练后,Social-SSL可以将所有观察到的交叉序列建模为时空嵌入,并在预测未来时间戳的未知序列时隐含地提供有用的社会信息。
3.1、问题定义
已知智能体的观测位置被重新缩放到[0,1],可以表示为
,其中
表示智能体
在时刻 t 时的重新缩放位置。由于该模型应侧重于预测相对坐标而不是绝对位置,因此作者将绝对坐标转换为相对坐标。设
表示智能体
在 t 时刻的相对坐标,计算式为
。
3.2、三个代理任务
3.2.1 Interaction Type Prediction
先来举个例子,你准备挑选一部电影来看,点开豆瓣评论区,发现有300条好评和50条差评,此时我们可能会觉得这部电影是好看的。类似的,作者将两个智能体靠近的频率和它们离开的频率相加,创建“closing” 和 “leaving”两类,第三个类“neutral”用于表示不确定两个智能体是否亲密或离开的情况。
设为在时间 t 时目标和社会智能体的距离变化,则有:
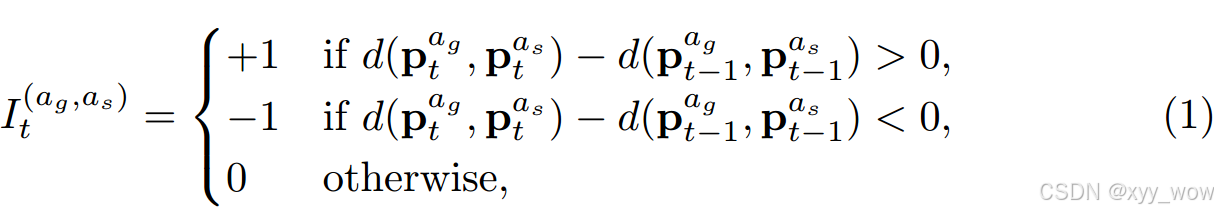
其中,是欧氏距离函数。为了跟踪社会关系的趋势,作者总结了一个时期 r 内的所有指标,并确定了两个智能体之间的交互类型如下:
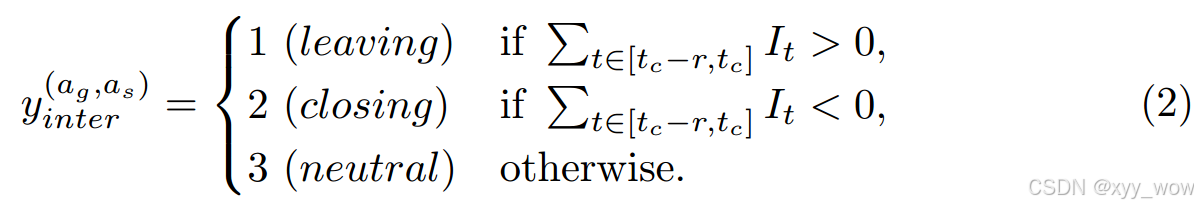
以交叉熵为损失函数:
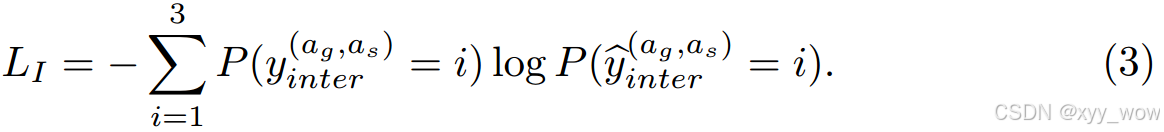
3.2.2 Closeness Prediction
已知靠近目标的智能体比远离目标的智能体对轨迹的影响更大,亲密度预测是用来捕捉这种社会特征的。作者将亲密度预测分为稀疏预测和密集预测以适应不同的场景。
稀疏预测:任何时候,目标智能体与社会智能体之间的距离小于设定的阈值,就将它们的亲密度标签赋值为1。
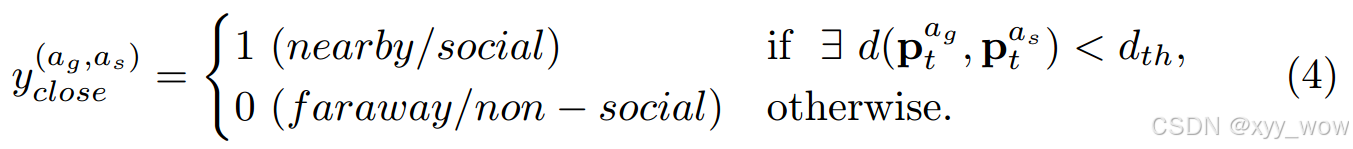
以二值交叉熵函数为目标函数进行稀疏预测:
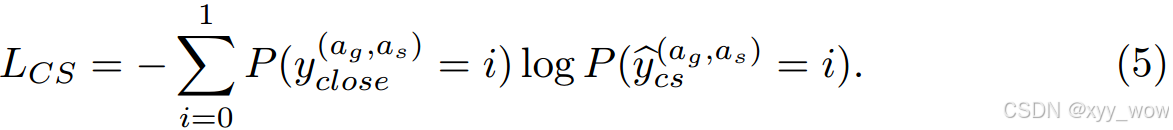
密集预测:要考虑目标智能体和社会智能体之间的精确距离。以均方误差为目标函数进行密集预测,如下图:
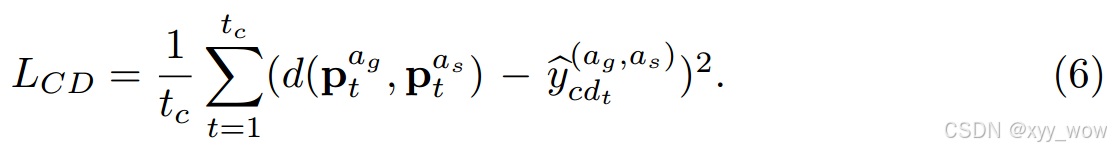
最后,亲密度预测任务的总损失表示为
与
之和。
下图为稀疏预测与密集预测的细节图:
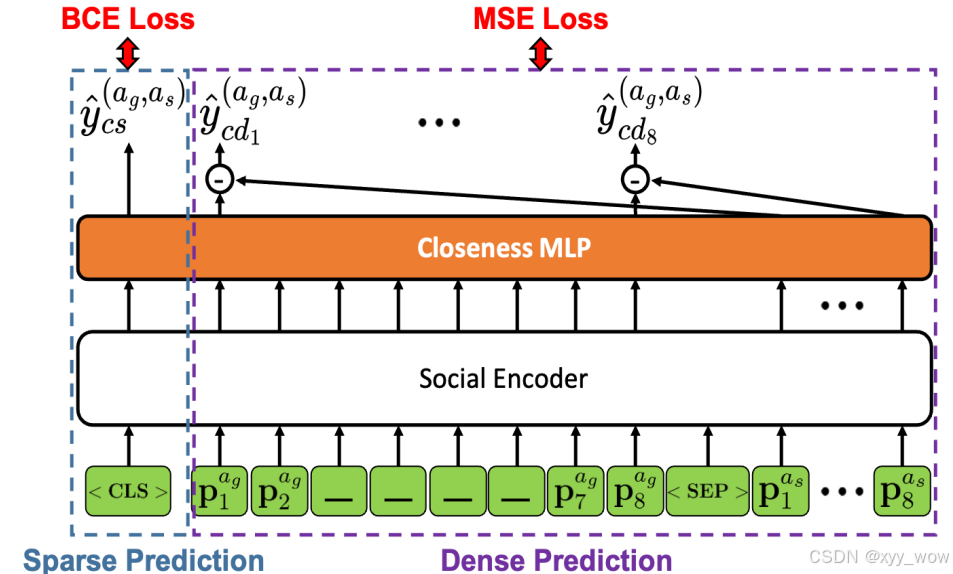
3.2.3 Masked Cross-Sequence to Sequence Prediction
第三个代理任务通过随机屏蔽目标智能体的子序列来创建,模型应该学会从交叉序列输入中重构被屏蔽的子序列。由于掩膜子序列的ground truth在被掩膜之前是已知的,因此模型可以以自监督学习的方式进行训练。
设和
分别表示随机掩码子序列时间戳的起始点和结束点,解码器上采用自回归结构来预测微调期间的轨迹,其输出表示为
,它表示目标序列在掩码时间戳上的重建。以均方误差作为掩模交叉序列到序列预训练的目标函数:
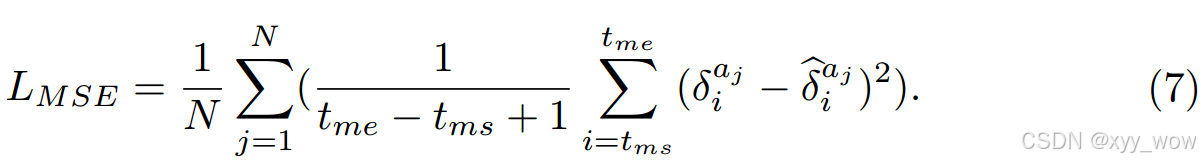
预训练阶段的总体目标函数可表示为下图,其中、
为超参数:
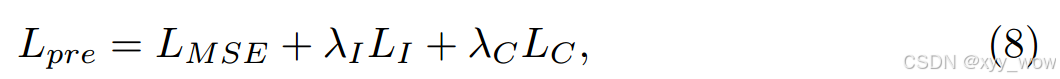
四、实验
数据集
使用了研究行人轨迹预测问题广泛使用的公共行人数据集ETH、UCY、SDD。
设置
在ETH和UCY数据集上使用留一法训练,在SDD上采用标准的train-test分割。在对轨迹预测任务进行微调时,训练集的可观察周期作为输入信息,未来周期作为ground truth计算MSE损失,指导轨迹预测。实验设置的观测周期为8帧,预测周期为12帧。在预训练阶段只使用训练集的可观察周期,以避免数据泄漏。
指标
使用平均位移误差(ADE)和最终位移误差(FDE)来评估结果。ADE反映了对突变的反应,FDE更多地反映了长期目标。
(具体实验细节不赘述,可以看原文)
实验结果
定量结果
表1显示了不同基线在ETH和UCY数据集上的定量结果。结果表明,Social-SSL在ADE和FDE方面比最先进的方法至少高出12%。
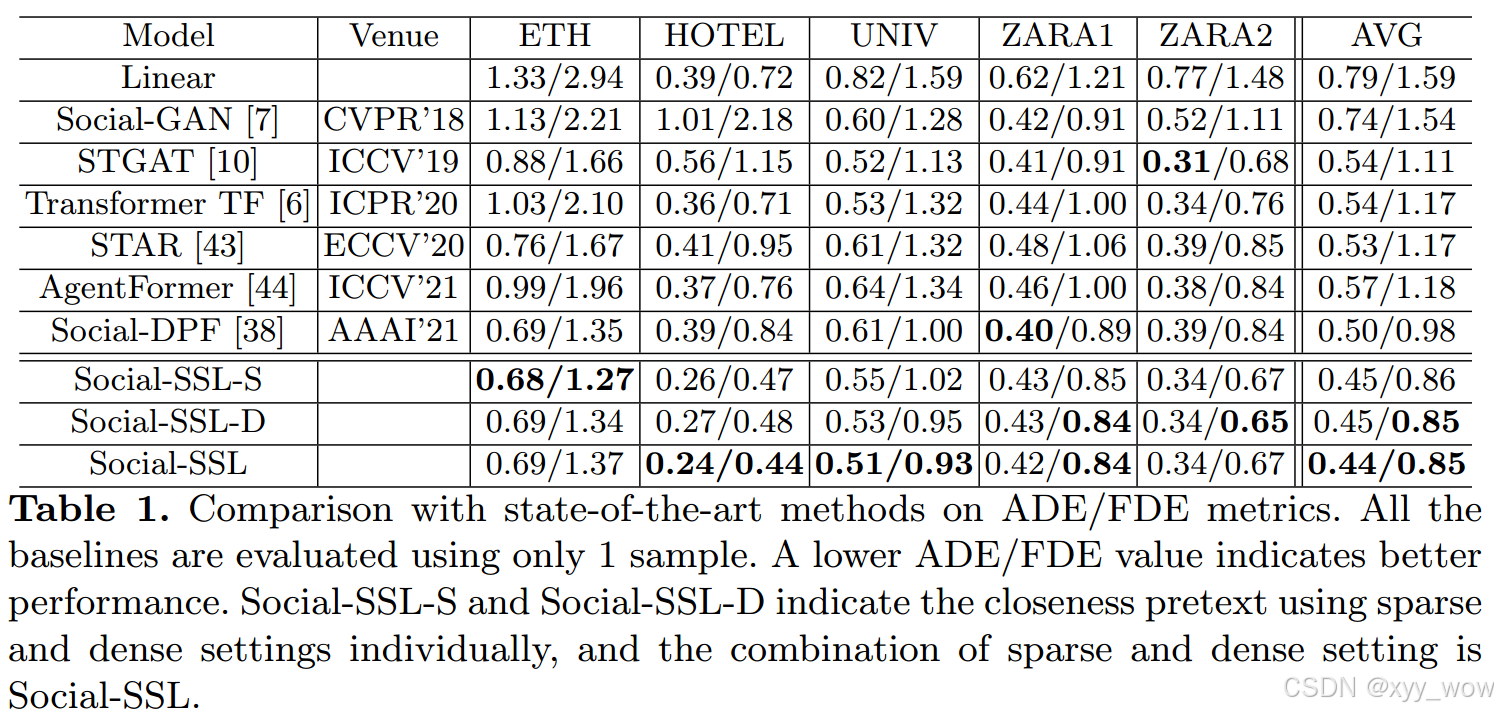
表2显示了就SDD数据集上的ADE和FDE而言,Social-SSL比最先进的方法至少高出23%和20%。我们知道SDD是一个更具挑战性的大规模数据集,它包含了不同主体之间复杂的相互作用,说明本论文的预训练策略不仅能够捕获行人之间的交互,还能够从大型数据集中捕获不同类型智能体之间的社会交互,从而获得更好的性能,这说明了预训练的优势。
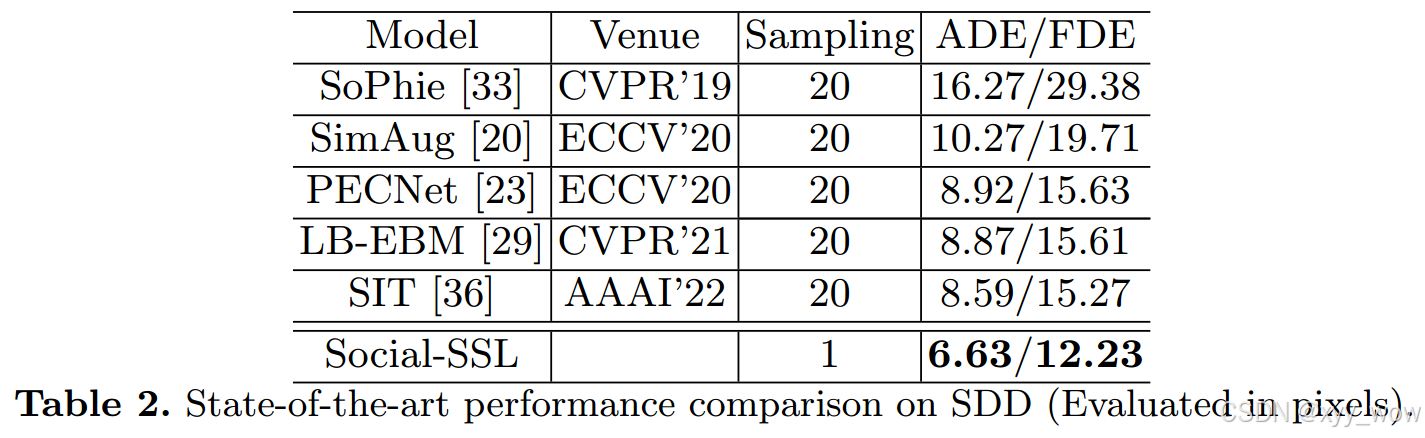
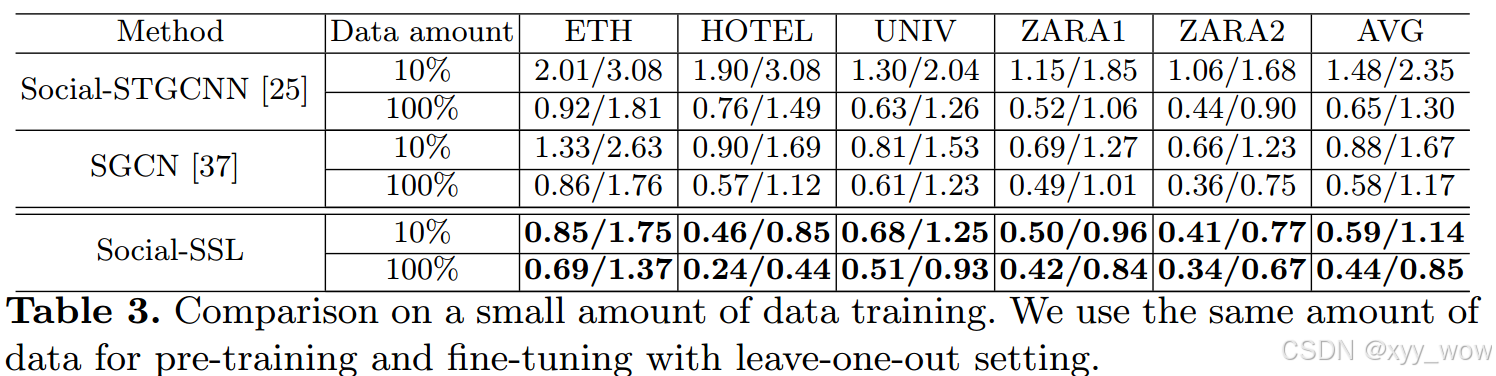
表3比较了5个数据集的10%和100%数据上训练的不同方法的性能。
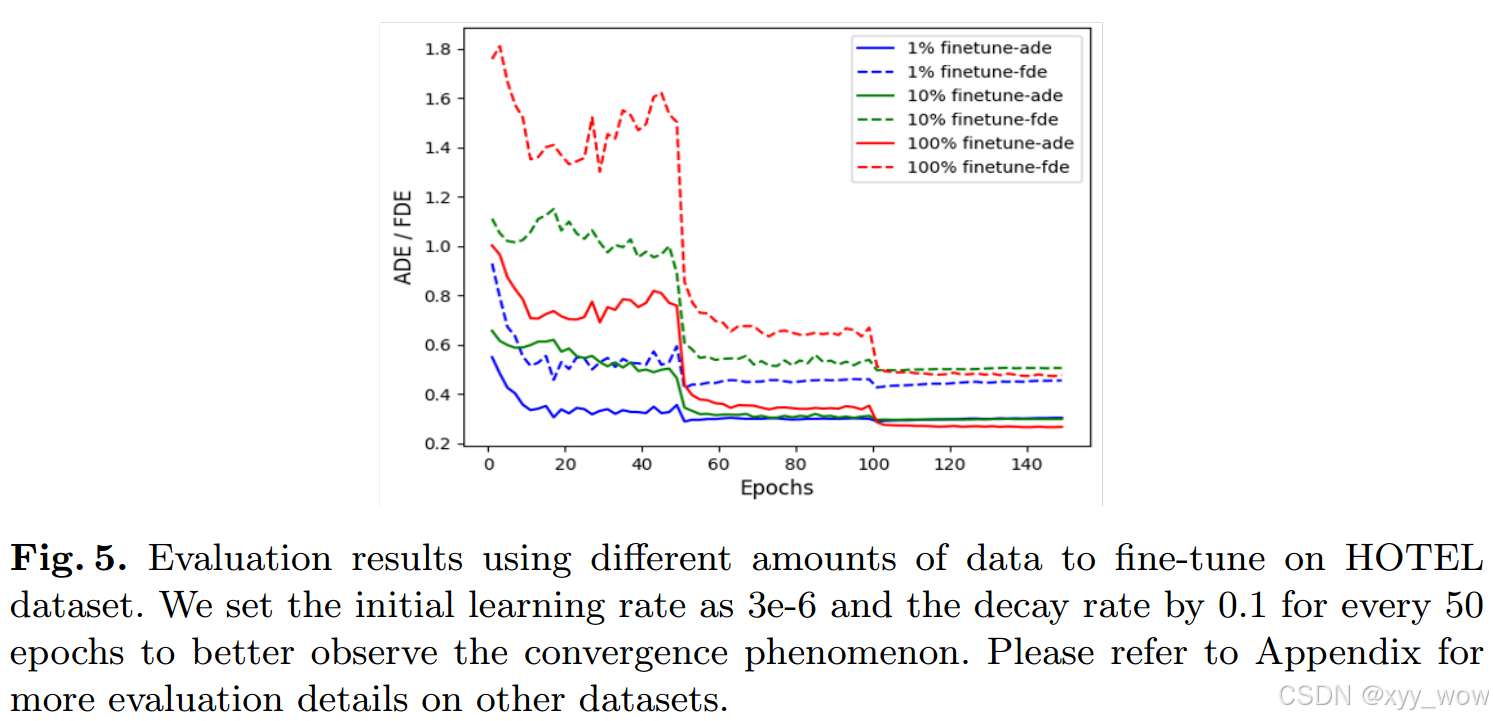
定性结果
图5展示了预训练策略的优势,仅使用1%的数据进行微调,训练可以很容易地收敛并在几个epoch内达到足够好的性能。这可以归因于掩蔽交叉序列到序列预训练任务的有效性。
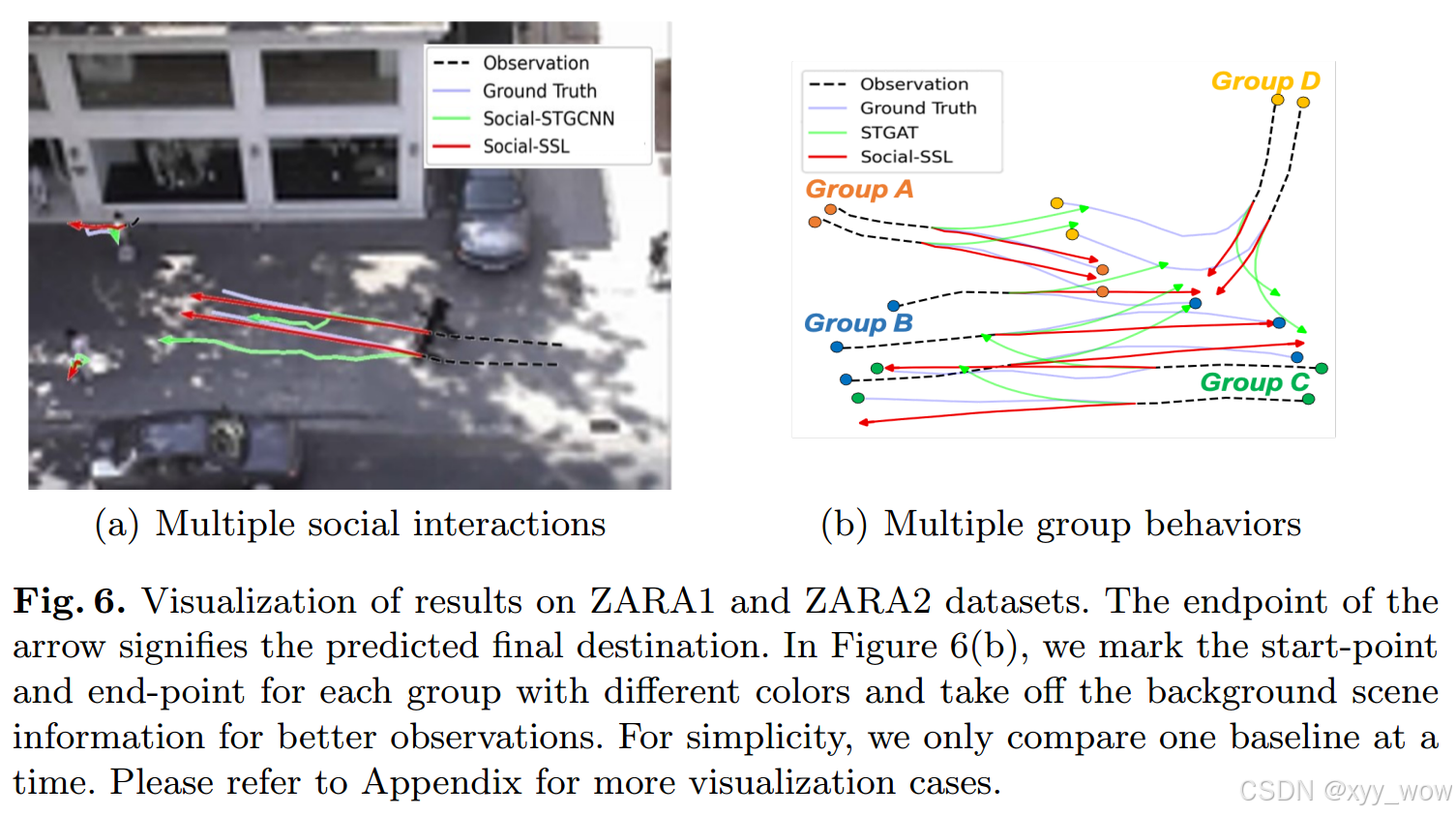
如下图6(a),Social-STGCNN预测一个智能体比另一个移动得快。相比之下,Social-SSL能够通过嵌入“中立”交互类型和跨序列到序列表示来保持内部和相互关系,从而保持两个智能体之间更好的速度和距离。对于左上角的agent, Social-STGCNN预测agent会朝中间两个智能体的方向移动。相比之下,Social-SSL基于过去的轨迹,精确地预测了离开行为。类似的,图6(b)比较了STGAT和Social-SSL在多组情况下的性能。
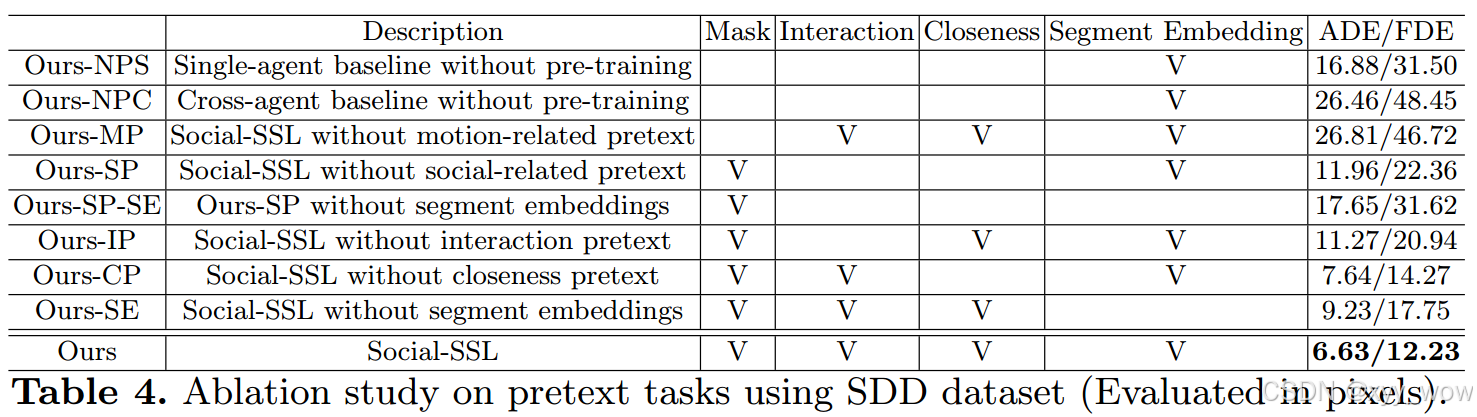
消融实验结果
为了进一步评估每个代理任务的贡献,表4比较了在不同代理任务组合上训练的Social-SSL的性能。
五、总结
这项工作提出了基于transformer的自监督交叉序列学习的Social-SSL,以学习执行下游多智能体轨迹预测任务的更好表示。Social-SSL的预训练任务增强了交叉序列表示的内部关系和内部关系。Social-SSL通过设计交互类型预测和亲密度预测的代理任务以及掩码交叉序列对序列的预训练,可以处理目标序列中缺失值的问题,同时从交叉序列中捕获有信息量的社会信息。
定量和定性实验表明,Social-SSL在基准数据集上的表现优于最先进的方法。
~~~~完结撒花~~~~

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 49
49 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)