AI agent求职党必看:48小时笔试题多Agent怎么破
苦猿技术分享 · 多 Agent 协作的 GitHub 体检工具——48 小时笔试题深度拆解
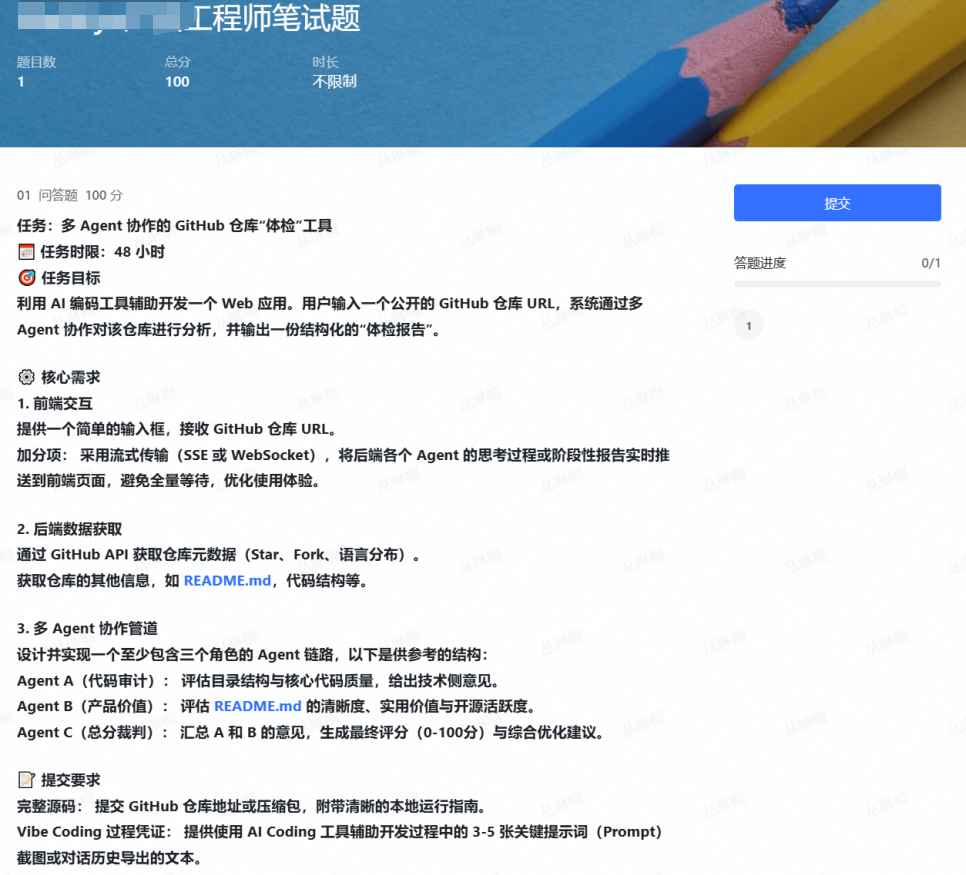
▲ 学员发来的笔试题
前言:深夜 11 点,学员甩过来一张截图
上周三晚上 11 点,我正在改一份 PPT。
微信"叮"地响了一下,我辅导的一个学员发了张截图过来——某家公司的工程师笔试题。
48 小时内交卷。
题目就一句话:用 AI 编程工具做一个 Web 应用,输入一个 GitHub 仓库 URL,多 Agent 协作产出一份结构化的"体检报告"。
我盯着这张图看了两分钟,第一反应不是"这题难不难",而是——
这题出得太狠了。
它表面上是"做个小工具",实际上把现在 AI 工程岗最看重的几样东西全考了一遍:
- 多 Agent 编排(LangGraph / LangChain / AutoGen)
- 异步实时通信(SSE / WebSocket)
- Prompt 工程(结构化输出、角色分工、交叉评估)
- 工程交付能力(README、运行指南、commit 历史)
- Vibe Coding 认证(让你交 3-5 条关键 Prompt)
任何一项糊弄,都会被有经验的面试官一眼看穿。
学员问我:"猿哥,这题 48 小时能搞定吗?"
我说,能。但不是从零开始搞。
接下来这一篇,我把这道题的踩分点、坑位、和我陪学员最终交付的 DeepEye 项目(截图你们看到了),一次性拆给你看。
不管你是正在求职的应届生、转行人,还是正在做 AI 应用开发的同行——这篇都值得你啃完。

▲ DeepEye 项目主界面:三 Agent 协作 + 时间轴
PART 01:先拆题——考官到底想看你交什么
很多人一拿到这种开放题,第一反应是"赶紧动手写代码"。
这是最大的错误。
48 小时的笔试,前 2 小时必须是拆题——把"考官想要什么"翻译成"我要交付什么"。
我把这道题的得分点拆成三层:
基础分(不交就出局)
- 输入界面:能接收 GitHub 仓库 URL
- 后端拉数据:通过 GitHub API 拿 Star / Fork / 语言分布
- 拿仓库内容:README.md、源代码结构
- 至少三个 Agent 协作:
- Agent A(代码分析):评估代码复杂度、可维护性
- Agent B(产品分析):评估 README 质量、亮点
- Agent C(综合评分):汇总 A、B,给出 0-100 分 + 优化建议
这层你做不到,后面都白搭。
加分项(拉开差距的关键)
题面里有一句很不起眼的话:
加分项:采用异步式传输(SSE 或 WebSockets),将后台每个 Agent 的参考过程或阶段性报告实时发送到前端界面,避免全量等待。
90% 的候选人会跳过这一项。
为什么?因为做 SSE/WebSocket 意味着你要解决前后端的实时通信、Agent 状态管理、事件分发——工作量直接翻倍。
但这一项恰恰是面试官用来筛人的钩子。
交了,说明你不仅能写代码,还懂用户体验、懂工程权衡。
隐藏 KPI(决定能不能拿 offer)
题面最后还有两行小字:
Vibe Coding 过程认证:提供使用 AI Coding 工具编程过程中的 3-5 条关键提示词(Prompt)。
提交历史提交的文本。
这两条是真正考你"工程师素养"的地方。
- 你有没有清晰的 commit 历史?还是一坨"update"?
- 你交的 Prompt 是"帮我写代码"这种废话,还是带角色、目标、约束、验收标准的结构化 Prompt?
- 你的 README 能不能让人 5 分钟内本地跑起来?
一句话——
考官不是看你能不能写出来,是看你像不像一个能独立交付的工程师。
代码只是载体,交付方式才是评分项。
PART 02:架构怎么搭——LangGraph 三 Agent 流水线
拆完题,下一步是定架构。
多 Agent 编排市面上有三个主流选择:
- LangChain Agent:上手快,但流程不透明,调试地狱
- AutoGen:对话式编排,适合多轮讨论,不适合"流水线"场景
- LangGraph:状态机模型,节点之间共享 state,可观测、可重放
这道题是典型的流水线场景(A、B 并行 → C 汇总),闭眼选 LangGraph。
流水线设计
我给学员画的架构图是这样的:
URL 输入
↓
[URL 解析] → 识别 owner/repo
↓
[GitHub 拉取] → API 元数据 + 文件树
↓
[静态分析] → radon 圈复杂度 + cloc 注释率
↓
┌─────────── 并行 ───────────┐
│ │
[Agent A · 代码审计] [Agent B · 产品价值]
分数 0-100 分数 0-100
└────────────┬─────────────┘
↓
[Agent C · 综合裁判]
汇总 + 强制交叉评估
↓
结构化体检报告核心代码长这样:
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
class RepoState(TypedDict):
url: str
owner: str
repo: str
files: list
metrics: dict # radon / cloc 静态指标
agent_a_report: dict # 代码审计结果
agent_b_report: dict # 产品价值结果
final_report: dict # Agent C 汇总
graph = StateGraph(RepoState)
graph.add_node("parse_url", parse_url)
graph.add_node("fetch_repo", fetch_repo)
graph.add_node("static_analysis", static_analysis)
graph.add_node("agent_a", agent_a_code_audit)
graph.add_node("agent_b", agent_b_product_value)
graph.add_node("agent_c", agent_c_judge)
graph.add_edge("parse_url", "fetch_repo")
graph.add_edge("fetch_repo", "static_analysis")
# 静态分析后,A、B 并行
graph.add_edge("static_analysis", "agent_a")
graph.add_edge("static_analysis", "agent_b")
# A、B 都完成后,再跑 C
graph.add_edge(["agent_a", "agent_b"], "agent_c")
app = graph.compile()一个关键设计点:Agent C 必须换模型
这是我反复跟学员强调的一条——
Agent C 用的模型,必须跟 A、B 不同 family。
为什么?
如果 A、B、C 都用 GPT-4o,它们会有同源盲区——同一类问题它都看不见。
比如 GPT-4o 容易高估"目录结构清晰度",那 A、B、C 三个都会高估,最终分数虚高。
我们最终的配置是:
- Agent A、B:GPT-4o / Claude Sonnet(快、便宜、上下文够用)
- Agent C:换成不同 family 的模型(比如 DeepSeek、Qwen)
这叫交叉评估。同一份报告,让两个不同训练数据的模型各自打分,分歧才会暴露。
这一招在面试讲架构时一拿出来,面试官眼睛会亮。
PART 03:踩坑实录——SSE 实时推送与 Agent 状态可视化
加分项要拿,但 SSE 这条路是真不好走。
学员在跑通"输入 URL → 出报告"的同步版本后,花了整整一天才把 SSE 串起来。
我把踩过的三个坑都记下来。
坑 1:LangGraph 同步 invoke 会阻塞事件循环
最直觉的写法是这样:
# 错误写法:会阻塞
@app.get("/api/analyze")
async def analyze(url: str):
async for event in app.astream_events(input, version="v2"):
yield format_event(event)
return result # ❌ 这里 return 早了问题在于 LangGraph 的 astream_events 是事件流,但 FastAPI 的 @app.get 不能直接返回 generator。
正确写法是用 StreamingResponse:
from fastapi.responses import StreamingResponse
@app.get("/api/analyze")
async def analyze(url: str):
async def event_stream():
async for event in graph_app.astream_events(
{"url": url}, version="v2"
):
kind = event["event"]
if kind == "on_chain_start":
yield f"event: stage\ndata: {json.dumps({'node': event['name']})}\n\n"
elif kind == "on_chain_end":
yield f"event: report\ndata: {json.dumps(event['data'])}\n\n"
return StreamingResponse(event_stream(), media_type="text/event-stream")前端用原生 EventSource 监听,按 event: 字段分发就行。
坑 2:Agent 并发与状态合并
A、B 并行跑,C 必须等齐。
这个 LangGraph 的 add_edge([a, b], c) 语法已经帮你处理了——它会等 a、b 都 done 才触发 c。
但报错处理得自己写。Agent B 报错了怎么办?
我们的降级策略:
- 给 B 一个默认分(50 分)
- 在最终报告里标记"产品价值评估降级"
- 不阻塞整体流程
工程化的核心就是——LLM 会失败,但你的服务不能挂。
坑 3:评分稳定性
这是最坑的一个。
同样的仓库,跑两次,分数差 ±15 分。
为什么?LLM 评分天生漂移。
解法有三:
- 结构化输出:用 JSON schema 约束输出格式,分数必须是数字、维度必须齐
- few-shot 锚点:在 prompt 里给 2-3 个"已知答案"的样本,让模型对齐刻度
- 温度调到 0.2:牺牲一点创造性,换稳定性
跑完这三步,分数波动能压到 ±3 分以内。
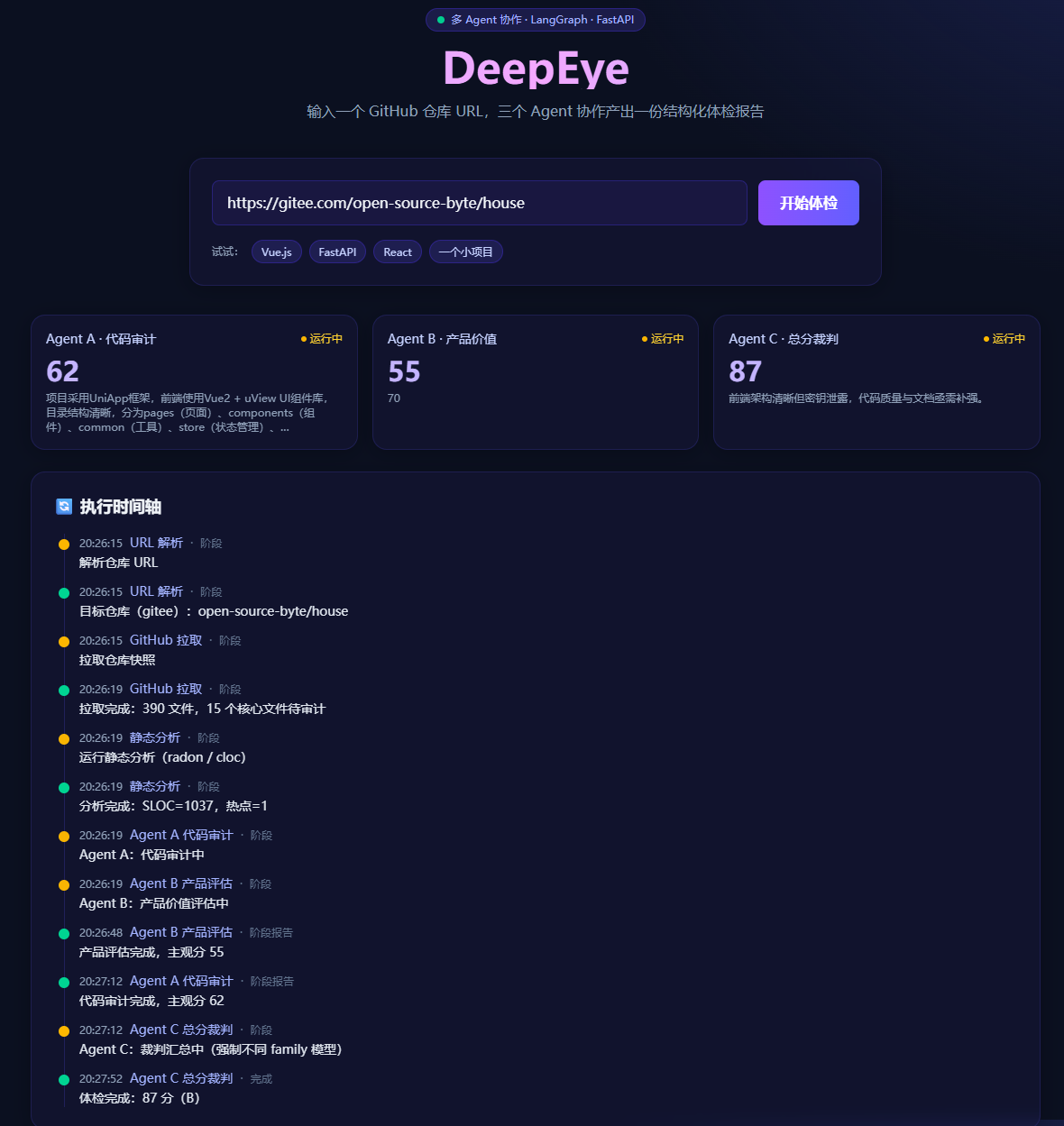
▲ 执行时间轴:每个 Agent 的状态实时回传
PART 04:交付物的"卖相"——让考官挑不出毛病的体检报告
代码跑通只完成了一半。报告长什么样,决定了你能不能拿满分。
评分维度不能拍脑袋
很多人让 LLM 直接输出一个 0-100 分,这是大忌——
面试官看到"87 分",第一反应是"凭什么 87?标准在哪?"
正确的做法是把评分维度拆开,每个维度带权重:
| 维度 | 权重 | 说明 |
|---|---|---|
| architecture(架构) | 25% | 目录结构、模块化、技术栈合理性 |
| quality(代码质量) | 25% | 复杂度、注释率、可读性 |
| documentation(文档) | 20% | README 完整度、注释覆盖率 |
| activity(活跃度) | 15% | commit 频率、最近维护情况 |
| security(安全) | 15% | 密钥泄露、依赖漏洞 |
权重写在 prompt 里,让 LLM 按这个表打分,输出的分数就有了依据。
报告必须有的几个块
最终交付的体检报告(参考截图 3)应该包含:
- 总分 + 评级(A/B/C/D)
- 5 维评分表(维度 / 分数 / 权重 / 说明)
- 亮点(绿色,3-5 条)
- 风险(黄色/红色,3-5 条)
- 改进建议(每条对应一个风险)
- 优先改进清单 P0/P1/P2
最后这个 P0/P1/P2 优先级清单是杀手锏。
它把 LLM 输出的"散装建议"工程化成了"按优先级排好的行动项"——
- P0:必须立刻处理(密钥泄露这种)
- P1:本周内处理(重构并发逻辑、补文档)
- P2:长期改进(加测试、补注释)
面试官看到这个清单的瞬间,他知道你不只是"调了个 API",你是真懂工程交付。
Vibe Coding 认证:Prompt 怎么交
题面要求交 3-5 条关键 Prompt。
别交这种:
帮我写一个分析 GitHub 仓库的 Agent
这种 Prompt 一交,直接暴露你不会用 AI。
要交这种(角色 + 目标 + 约束 + 验收标准):
你是 Agent A · 代码审计专家。
## 目标
对给定的 GitHub 仓库进行代码层面的健康度评估。
## 输入
- 仓库 owner / repo
- 核心文件列表(15 个)
- 静态分析指标(radon 圈复杂度、cloc 注释率)
## 输出格式(严格 JSON)
{
"score": 0-100 的整数,
"highlights": ["亮点 1", "亮点 2"],
"risks": ["风险 1", "风险 2"],
"suggestions": ["建议 1", "建议 2"]
}
## 评分锚点
- 90+:架构清晰、测试覆盖 > 70%、注释率 > 30%
- 70-89:架构合理但有瑕疵
- 50-69:明显技术债
- <50:严重不可维护这种 Prompt 一交出去,面试官就知道——
这人不是在用 AI,是在驾驭 AI。

▲ 最终交付的体检报告:5 维评分 + 优先改进清单
结尾:笔试题考的从来不是答案
回到这道 48 小时的笔试题。
我陪学员交完卷的那一刻,他问我:"猿哥,你觉得能过吗?"
我说,你已经赢了。
不是因为你做出了 DeepEye 这个项目,而是因为你完整经历了一次从需求拆解到工程交付的全流程——
拆题、架构、SSE、多 Agent、结构化输出、降级策略、报告工程化、Prompt 认证……
这些才是面试官真正想看的东西。
笔试题考的从来不是答案,是你交付答案的方式。
多 Agent 不是把 LLM 调三次,而是把"分工"这件事写进代码。
代码会过时,框架会迭代,但像工程师一样思考问题的能力,永远不过时。
互动时间:你遇到过最"狠"的笔试题是什么?是这种开放题还是纯算法题?评论区聊聊,我挑两条下次专门拆。
关注我,下一期拆 多 Agent 落地的 5 种编排模式——什么场景该用 Pipeline,什么场景该用 Supervisor,什么场景必须上 Swarm。
— END —
苦猿 · 帮普通人把 AI 学进简历

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)