企业知识决策平台:未来五年企业AI最大的新市场机遇
企业知识决策平台,可能是未来五年企业 AI 最大的新市场
过去几年,大模型的发展速度远远超过了很多人的预期。从最初的聊天机器人,到如今能够编写代码、分析文档、生成报告,越来越多的企业开始尝试将 AI 引入自己的业务流程。
然而,在真正落地企业场景之后,很多团队却发现了一个共同的问题。
企业并不缺 AI,也并不缺知识。
真正缺少的是能够把企业知识转换成企业决策能力的平台。
这也是我认为未来几年,一个全新软件市场正在形成的原因——Enterprise Knowledge Decision Platform(企业知识决策平台)。
为什么传统知识管理越来越难满足企业需求
过去二十多年,企业已经投入了大量资源建设自己的信息化平台。
包括 ERP、CRM、MES、PLM、SharePoint、Confluence、Wiki、Git、Jira、数据仓库以及各种文档管理系统。
如果只看数据量,大多数企业已经积累了几十万甚至上百万份文档。
问题并不是没有知识。
而是知识越来越难被利用。
例如,一个金融交易系统出现异常,开发人员真正需要知道的是:
-
为什么这笔交易没有完成清算?
-
为什么接口昨天还能调用,今天却失败了?
-
当前版本应该使用哪个 API?
-
数据库哪个字段决定了最终状态?
-
为什么升级之后配置失效?
这些答案通常不会出现在同一个地方。
它们可能分别存在于:
-
PDF 用户手册
-
API Guide
-
Release Note
-
Git 源代码
-
数据库 Schema
-
运维日志
-
Jira Issue
-
测试用例
-
Wiki
-
邮件
-
Teams 或 Slack 历史讨论
企业拥有所有这些信息,却很难快速形成正确决策。
因此,企业真正需要解决的问题已经不是"如何搜索文档",而是"如何利用全部知识完成一次正确决策"。
企业知识平台正在经历三次演进
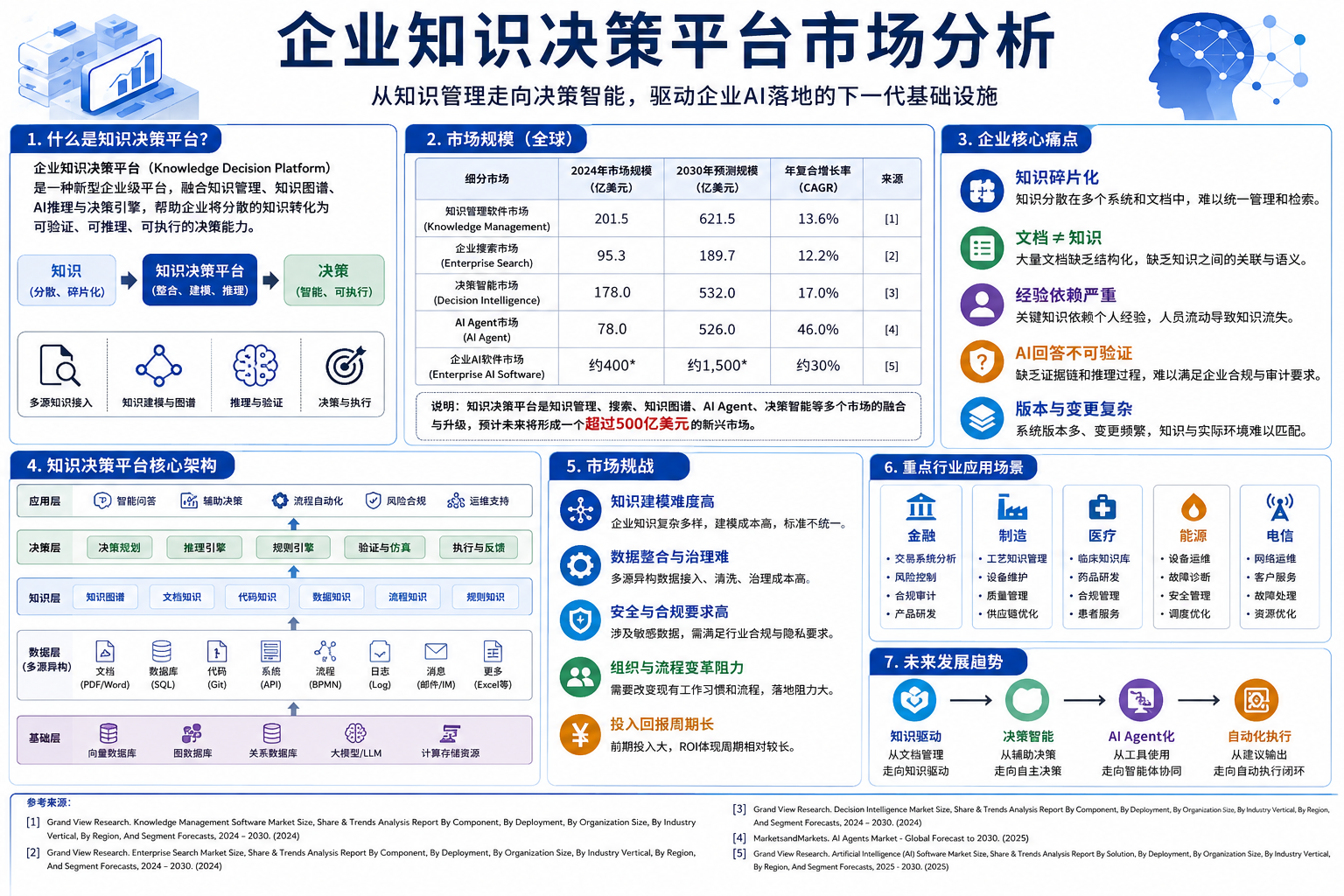
如果回顾企业知识平台的发展,可以大致分成三个阶段。
第一阶段是传统 Knowledge Management。
这一阶段解决的是文档如何存储、分类和共享的问题。SharePoint、Confluence 等产品基本代表了这一时代。
第二阶段开始进入 RAG(Retrieval-Augmented Generation)。
企业开始利用向量数据库和大语言模型回答文档中的问题。
相比传统搜索,这已经取得了巨大的进步。
但是,它仍然存在明显局限。
RAG 能回答"文档写了什么",却很难回答:
-
哪个版本适用?
-
哪些 API 必须先执行?
-
哪些权限必须提前具备?
-
为什么系统最终这样处理?
-
有没有违反企业内部规则?
因为这些内容,并不是某一篇文档能够回答的。
于是,第三阶段开始出现。
也就是我认为未来几年企业最重要的发展方向:
Knowledge Decision Platform。
它不仅学习知识。
更重要的是学习:
-
知识之间的关系;
-
系统之间的依赖;
-
规则之间的约束;
-
Workflow 的执行逻辑;
-
不同版本之间的演进;
-
决策背后的证据链。
最终形成企业真正能够依赖的决策能力。
为什么说这是一个新的市场
很多人会问:
市场真的存在吗?
事实上,目前还没有任何一家研究机构专门统计"Knowledge Decision Platform"。
但是,它实际上位于多个高速增长市场的交汇点。
根据 Grand View Research 的统计,全球 Knowledge Management Software 市场 2024 年约为 201.5 亿美元,预计到 2033 年增长至 621.5 亿美元,年复合增长率约 13.6%。
同样,Grand View Research 预计 Decision Intelligence 市场将在 2025 年达到约 178 亿美元,2033 年增长至 532 亿美元。
AI Agent 市场增长速度更快。MarketsandMarkets 预计该市场将从 2025 年约 78 亿美元增长至 2030 年约 526 亿美元,年复合增长率超过 46%。
与此同时,整个企业 AI 市场仍保持高速扩张。Grand View Research 预计全球 AI 市场规模将在未来几年保持约 30% 的年增长率。
如果把这些市场放在一起观察,会发现它们正在逐渐融合。
知识管理负责保存知识。
Enterprise Search 负责寻找知识。
Knowledge Graph 建立知识关系。
Decision Intelligence 负责辅助决策。
AI Agent 开始执行任务。
Knowledge Decision Platform 正好位于这些能力的交汇点。
因此,它并不是替代某一个市场,而是逐渐成为这些平台共同演化出来的新一代企业基础设施。
真正困难的地方,不是大模型
很多企业刚开始做 AI 时,都认为最大的难点是选择哪个模型。
事实上,大模型只是其中一层能力。
真正困难的是企业知识本身。
首先,是知识碎片化。
企业知识通常散落在几十甚至上百个系统中。
其次,是知识关系。
API 与 API 存在依赖。
数据库与代码存在依赖。
Workflow 与权限存在依赖。
版本之间还存在大量差异。
这些关系,大多数都没有写进任何一份 PDF。
再次,是版本管理。
同一家公司可能同时维护:
5.0
5.5
6.0
6.4
7.0
不同版本之间:
API 不同。
数据库不同。
配置不同。
部署方式不同。
如果 AI 无法识别当前版本,那么它生成的大部分答案都有可能错误。
最后,也是企业最关注的问题——证据。
企业不会接受一句"AI 认为"。
企业需要知道:
为什么这样回答?
依据哪份文档?
依据哪个版本?
依据哪条规则?
依据哪段代码?
能否追溯?
这就是企业 AI 与消费级 AI 最大的区别。
企业真正需要的是证据驱动的决策
未来企业 AI 的竞争,不会只是回答问题更快。
真正的竞争,将发生在"谁能够证明自己的答案是正确的"。
一个成熟的知识决策平台,不仅应该返回最终答案。
还应该同时返回:
-
推理过程;
-
使用的知识节点;
-
依赖关系;
-
Workflow;
-
规则验证结果;
-
文档来源;
-
版本信息;
-
风险提示。
最终形成完整的 Evidence Package(证据包)。
对于金融、医疗、能源、制造等行业来说,这一点甚至比回答速度更加重要。
结语
我认为,未来企业 AI 的演进路径将非常清晰。
第一阶段,是让 AI 学会阅读文档。
第二阶段,是让 AI 学会理解企业知识。
第三阶段,则是让 AI 能够参与企业决策,并且能够证明自己的决策为什么正确。
真正决定企业 AI 竞争力的,不会只是模型参数,也不会只是上下文长度,而是谁能够把分散的企业知识组织成可理解、可推理、可验证、可执行的决策能力。
这,也许正是未来几年企业软件最值得关注的新市场。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)