2026 年从 0 开发 AI Agent:你必须掌握的 10 个核心技能(附代码与架构图)
引言:为什么 2026 年开发 AI Agent 依然充满挑战?
2026 年,AI Agent 的开发已从“概念验证”阶段迈入“工程化落地”阶段。单纯调用 API 已无法构建出稳定、可靠、能解决实际问题的智能体。从零开始开发一个 AI Agent,意味着你需要成为一个“全栈 AI 工程师”,横跨算法、工程、产品与运维。本文将为你拆解 2026 年必备的 10 大核心技能,并辅以代码示例和架构图,助你构建属于自己的智能体。
1. 大语言模型 (LLM) 的深度理解与提示工程
技能描述:超越简单的 system 和 user 对话,掌握思维链 (CoT)、少样本学习 (Few-shot)、函数调用 (Function Calling) 以及最新的推理框架(如 OpenAI o1)。
核心要点:
- 提示模板化:将提示词模块化,支持变量注入和条件逻辑。
- 输出结构化:强制模型返回 JSON、YAML 等可解析格式。
- 上下文管理:精准控制上下文窗口,避免信息过载。
代码示例:构建一个可复用的提示模板引擎
from typing import Dict, Any
from dataclasses import dataclass
import json
@dataclass
class PromptTemplate:
system: str
few_shot_examples: list[Dict[str, str]]
output_format: Dict[str, Any]
def render(self, user_input: str, **kwargs) -> list[Dict[str, str]]:
"""渲染完整的对话消息列表"""
messages = []
# 1. 系统指令(支持变量注入)
system_msg = self.system.format(**kwargs)
messages.append({"role": "system", "content": system_msg})
# 2. 少样本示例
for ex in self.few_shot_examples:
messages.append({"role": "user", "content": ex["user"]})
messages.append({"role": "assistant", "content": ex["assistant"]})
# 3. 当前用户输入
final_input = user_input
if self.output_format:
final_input += f"\n\n请严格按照以下 JSON 格式回复:\n{json.dumps(self.output_format, indent=2, ensure_ascii=False)}"
messages.append({"role": "user", "content": final_input})
return messages
# 使用示例:创建一个天气查询 Agent 的提示模板
weather_template = PromptTemplate(
system="你是一个专业的天气助手。请根据用户提供的城市名,查询天气信息。",
few_shot_examples=[
{
"user": "北京天气怎么样?",
"assistant": '{"city": "北京", "weather": "晴", "temperature": 22, "unit": "摄氏度"}'
}
],
output_format={
"city": "string",
"weather": "string",
"temperature": "number",
"unit": "string"
}
)
# 渲染提示词
messages = weather_template.render("上海今天天气如何?")
print(json.dumps(messages, indent=2, ensure_ascii=False))
可视化建议:此处可插入一张图,展示“从用户问题到结构化 JSON 输出”的提示工程处理流水线。
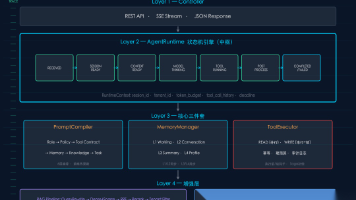
2. 智能体框架的熟练运用(LangChain, LlamaIndex, CrewAI)
技能描述:选择一个主流框架作为开发底座,理解其核心抽象(Agent、Tool、Memory、Chain),并能进行定制化扩展。
核心要点:
- 工具封装:将任何 API、函数或数据库查询封装成 Agent 可调用的工具。
- 记忆设计:实现短期对话记忆和长期知识存储。
- 流程编排:用 Chain 或 Crew 编排多个 Agent 的协作流程。
代码示例:使用 LangChain 构建一个具备工具调用能力的简易 Agent
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain.tools import Tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
import requests
# 1. 定义自定义工具:获取当前时间
def get_current_time(timezone: str = "Asia/Shanghai") -> str:
"""获取指定时区的当前时间。"""
# 这里模拟一个 API 调用
import datetime
now = datetime.datetime.now()
return now.strftime(f"%Y-%m-%d %H:%M:%S ({timezone})")
time_tool = Tool(
name="get_current_time",
func=get_current_time,
description="获取指定时区的当前时间。输入参数 timezone 是时区字符串,例如 'Asia/Shanghai'。"
)
# 2. 定义另一个工具:计算器
def calculator(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
# 警告:实际生产环境应使用更安全的评估方法
result = eval(expression)
return str(result)
except Exception as e:
return f"计算错误:{e}"
calc_tool = Tool(
name="calculator",
func=calculator,
description="计算一个数学表达式。输入是一个字符串,例如 '3 + 5 * 2'。"
)
# 3. 构建 Agent
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
tools = [time_tool, calc_tool]
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有帮助的助手,可以回答问题和使用工具。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 4. 运行 Agent
result = agent_executor.invoke({
"input": "现在上海是什么时间?然后计算一下 (15 + 27) / 3 等于多少?",
"chat_history": [] # 初始为空
})
print(result["output"])
可视化建议:此处可插入一张 LangChain Agent 执行循环的流程图,展示 LLM -> 思考 -> 选择工具 -> 执行 -> 观察 -> 再思考 的过程。
3. 向量数据库与语义检索
技能描述:让 Agent 拥有“长期记忆”和“知识库”,能够从海量文档中精准检索相关信息。
核心要点:
- 嵌入模型选择:根据文本类型(代码、长文档、短查询)选择合适的嵌入模型。
- 检索策略:掌握相似性搜索、最大边际相关性 (MMR) 重排序、混合搜索(关键词+向量)。
- 索引优化:理解分块、元数据过滤、多向量索引等高级概念。
代码示例:使用 ChromaDB 为 Agent 构建一个本地知识库
import chromadb
from chromadb.config import Settings
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
# 1. 初始化客户端和嵌入函数
chroma_client = chromadb.PersistentClient(path="./my_agent_knowledge_base")
embedding_function = OpenAIEmbeddings(model="text-embedding-3-small")
# 2. 准备文档并分块
loader = TextLoader("./project_requirements.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", "、", " "]
)
chunks = text_splitter.split_documents(documents)
# 3. 创建集合(相当于数据库表)并添加文档
collection = chroma_client.get_or_create_collection(
name="project_docs",
embedding_function=embedding_function.embed_documents # 适配 Chroma 的调用方式
)
# 添加文档块,包含文本和元数据
for i, chunk in enumerate(chunks):
collection.add(
documents=[chunk.page_content],
metadatas=[{"source": "requirements.txt", "chunk_id": i}],
ids=[f"chunk_{i}"]
)
# 4. 检索:为 Agent 的当前问题寻找相关上下文
def retrieve_context_for_agent(query: str, n_results: int = 3):
"""检索与查询最相关的文档块"""
# 将查询转换为向量
query_embedding = embedding_function.embed_query(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=n_results,
include=["documents", "metadatas", "distances"]
)
context = ""
for doc, meta in zip(results['documents'][0], results['metadatas'][0]):
context += f"[来源:{meta['source']}]\n{doc}\n\n"
return context.strip()
# 模拟 Agent 在回答前先检索知识库
user_question = "我们项目的登录模块有哪些安全要求?"
relevant_context = retrieve_context_for_agent(user_question)
print("检索到的相关上下文:")
print(relevant_context)
print("\n--- Agent 可以将上述上下文注入提示词中,再生成回答 ---")
可视化建议:此处可插入一张 RAG (检索增强生成) 架构图,展示“用户问题 -> 向量化 -> 向量数据库检索 -> 上下文注入 -> LLM 生成答案”的完整流程。
4. 函数/工具调用与工作流编排
技能描述:将外部能力(API、数据库、本地函数)安全、可靠地暴露给 Agent,并设计复杂的工作流。
核心要点:
- 工具描述:编写清晰、准确的工具描述,让 LLM 能正确理解和使用。
- 错误处理:设计工具调用的重试、降级和超时机制。
- 流程编排:使用状态机或工作流引擎(如 Prefect、Airflow)管理多步骤任务。
代码示例:定义一个包含多种工具的工具箱,并实现自动重试
import tenacity
from typing import Any, Dict, List
from pydantic import BaseModel, Field
import httpx
class Toolbox:
"""Agent 的工具箱,封装了所有可用的外部能力"""
@tenacity.retry(
stop=tenacity.stop_after_attempt(3),
wait=tenacity.wait_exponential(multiplier=1, min=4, max=10),
retry=tenacity.retry_if_exception_type((httpx.RequestError,))
)
def search_web(self, query: str) -> str:
"""使用搜索引擎搜索网络信息(模拟)"""
print(f"[工具调用] 正在搜索:{query}")
# 模拟网络请求和响应
return f"关于 '{query}' 的搜索结果摘要:...(此处为模拟数据)"
def send_email(self, to: str, subject: str, body: str) -> str:
"""发送电子邮件"""
print(f"[工具调用] 发送邮件给 {to},主题:{subject}")
# 模拟发送逻辑
return f"邮件已成功发送至 {to}"
def query_database(self, sql: str) -> List[Dict[str, Any]]:
"""执行 SQL 查询"""
print(f"[工具调用] 执行 SQL: {sql}")
# 模拟数据库查询结果
return [{"id": 1, "name": "示例数据"}]
def get_tool_descriptions(self) -> List[Dict]:
"""生成供 LLM 使用的工具描述列表"""
return [
{
"type": "function",
"function": {
"name": "search_web",
"description": "使用搜索引擎搜索最新的网络信息。",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "send_email",
"description": "发送一封电子邮件。",
"parameters": {
"type": "object",
"properties": {
"to": {"type": "string", "description": "收件人邮箱地址"},
"subject": {"type": "string", "description": "邮件主题"},
"body": {"type": "string", "description": "邮件正文"}
},
"required": ["to", "subject", "body"]
}
}
}
# ... 其他工具描述
]
# 使用示例
toolbox = Toolbox()
# 这些描述可以被注入到 LLM 的 system prompt 中,或用于自动生成 OpenAI 的 tools 参数
print("可用工具描述:")
print(toolbox.get_tool_descriptions())
可视化建议:此处可插入一张“工具调用决策与执行”的序列图,展示 Agent 分析问题、选择工具、执行、处理结果的完整交互。
5. 记忆与状态管理
技能描述:设计 Agent 的“大脑”,使其能记住对话历史、用户偏好和任务状态。
核心要点:
- 短期记忆:管理对话上下文,避免 token 超限。
- 长期记忆:将重要信息向量化后存入知识库,供未来检索。
- 状态持久化:将会话状态保存到数据库,支持断点续跑。
代码示例:实现一个基于向量数据库的长期记忆系统
from typing import List, Dict
import json
from datetime import datetime
class LongTermMemory:
"""基于向量数据库的长期记忆系统"""
def __init__(self, collection_name: str = "agent_memory"):
self.chroma_client = chromadb.PersistentClient(path="./agent_memory_db")
self.embedding_function = OpenAIEmbeddings(model="text-embedding-3-small")
self.collection = self.chroma_client.get_or_create_collection(
name=collection_name,
embedding_function=self.embedding_function.embed_documents
)
def store_memory(self, content: str, memory_type: str = "fact", metadata: Dict = None):
"""存储一段记忆"""
if metadata is None:
metadata = {}
memory_id = f"memory_{datetime.now().timestamp()}_{hash(content) % 10000}"
metadata.update({
"type": memory_type,
"timestamp": datetime.now().isoformat(),
"content_preview": content[:100]
})
self.collection.add(
documents=[content],
metadatas=[metadata],
ids=[memory_id]
)
print(f"[长期记忆] 已存储:{content[:50]}...")
return memory_id
def recall_memories(self, query: str, n_results: int = 5, memory_type: str = None) -> List[Dict]:
"""回忆与查询相关的记忆"""
query_embedding = self.embedding_function.embed_query(query)
where_clause = None
if memory_type:
where_clause = {"type": memory_type}
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=n_results,
where=where_clause,
include=["documents", "metadatas", "distances"]
)
memories = []
for doc, meta, dist in zip(results['documents'][0], results['metadatas'][0], results['distances'][0]):
memories.append({
"content": doc,
"metadata": meta,
"relevance_score": 1 - dist # 简单转换,距离越小越相关
})
# 按相关性排序
memories.sort(key=lambda x: x['relevance_score'], reverse=True)
return memories
def summarize_conversation(self, conversation_history: List[Dict]) -> str:
"""总结一段对话,并存储为长期记忆"""
# 简单实现:将最后几轮对话拼接
summary = "对话摘要:\n"
for msg in conversation_history[-5:]: # 取最后5条
role = msg.get("role", "unknown")
content = msg.get("content", "")[:100]
summary += f"{role}: {content}\n"
self.store_memory(
content=summary,
memory_type="conversation_summary",
metadata={"source": "auto_summary"}
)
return summary
# 使用示例
memory = LongTermMemory()
# 存储一些事实
memory.store_memory("用户张三喜欢喝美式咖啡,不加糖。", memory_type="user_preference", metadata={"user": "zhangsan"})
memory.store_memory("项目的 API 密钥是 sk-...(已脱敏)", memory_type="project_config", metadata={"sensitivity": "high"})
# 回忆
print("回忆与‘咖啡’相关的记忆:")
related_memories = memory.recall_memories("咖啡", memory_type="user_preference")
for mem in related_memories:
print(f"- {mem['content']} (相关性:{mem['relevance_score']:.2f})")
可视化建议:此处可插入一张“Agent 记忆系统架构图”,区分短期记忆(对话上下文)、长期记忆(向量存储)和外部知识库。
6. 评估、测试与监控
技能描述:建立科学的评估体系,确保 Agent 的行为符合预期,并在生产环境中保持稳定。
核心要点:
- 单元测试:对工具、提示词、链进行独立测试。
- 端到端评估:设计测试用例,评估 Agent 的

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)