机器学习基础一文速通:理清概念——实践代码任务
1. 绪论:人工智能与机器学习
1.1 人工智能、机器学习与深度学习
人工智能(AI) 是研究、开发用于模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的综合性交叉学科。它包含感知能力、决策能力与行动能力,涵盖机器学习、自动推理、知识表示、语音识别、视觉识别等方向。
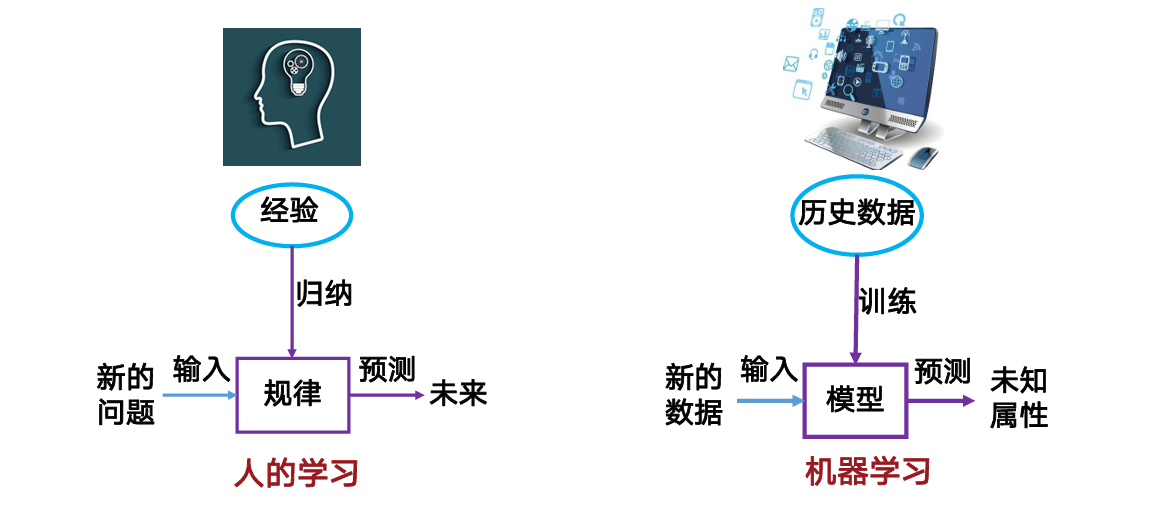
机器学习(ML) 是 AI 的子集。Tom Mitchell 给出经典定义:机器学习是一门研究算法的学科,这些算法能够——
- 在任务 T 上
- 通过经验 E(数据)
- 提升性能 P(指标)
即学习任务由三元组 <T, P, E> 定义。
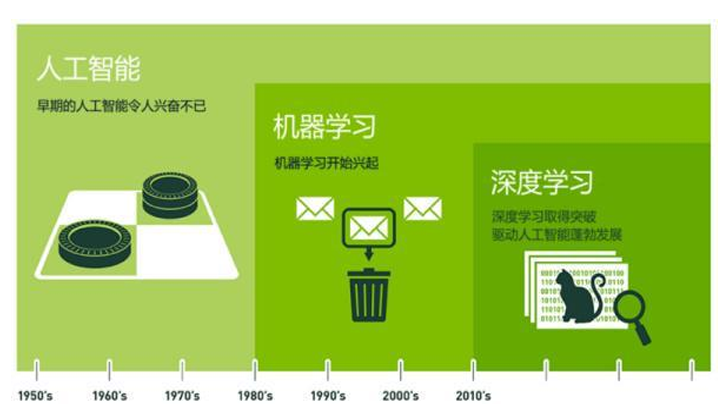
深度学习(DL) 是机器学习的子集,通过多层神经网络自动学习层次化特征表示。关系为:人工智能 ⊃ 机器学习 ⊃ 深度学习。
1.2 机器学习简单例子:西瓜分类
训练数据包含特征(色泽、根蒂、敲声)与标签(好瓜/坏瓜)。学习算法从训练数据归纳出模型,再对新样本 (浅白, 蜷缩, 浊响, ?) 预测标签。
1.3 基本术语
| 术语 | 含义 |
|---|---|
| 数据集 | 训练集、测试集 |
| 样本 (sample) | 一条观测记录 |
| 特征 (feature) / 属性 (attribute) | 描述样本的变量 |
| 标签 (label) | 监督学习中的目标值 |
| 特征向量 | 将各特征组成向量表示样本 |
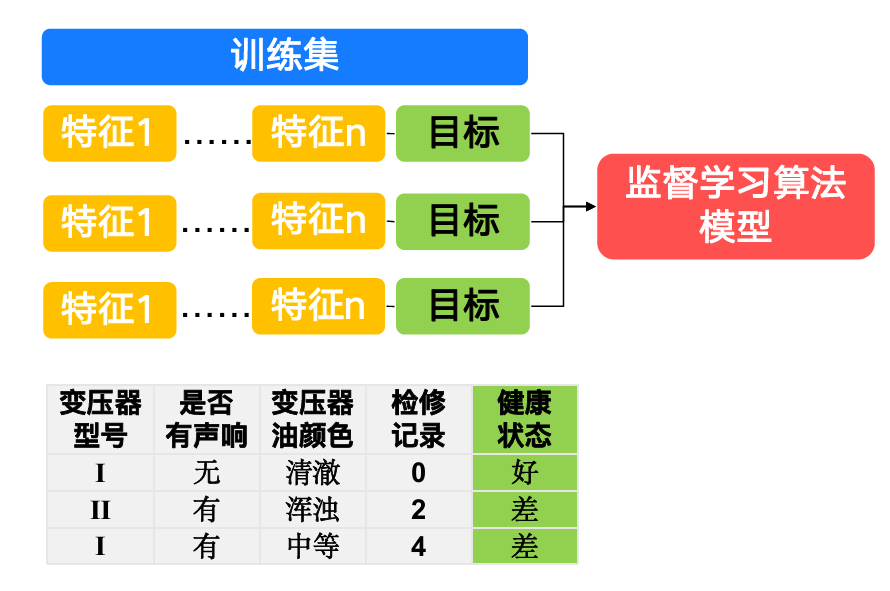
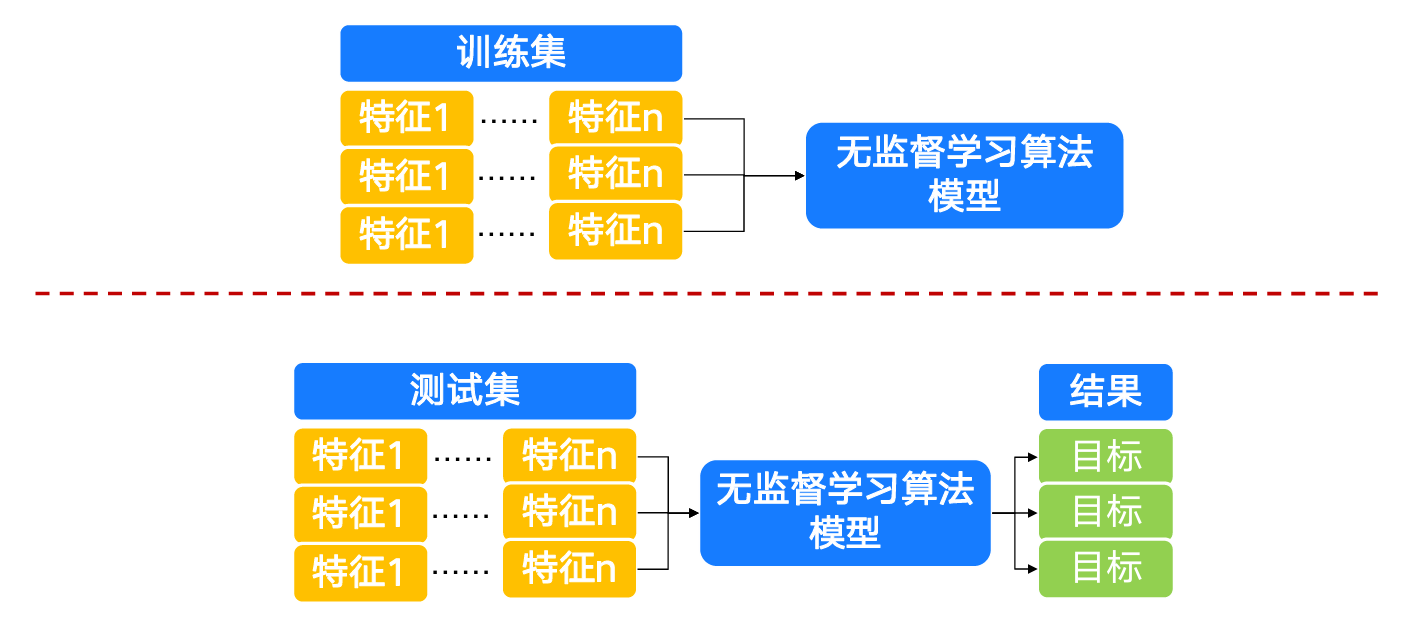
1.4 监督学习 vs 无监督学习
监督学习:训练数据同时有特征和标签,学习「特征→标签」的映射。包括:
- 分类:输出离散值(KNN、决策树、SVM、神经网络等)
- 回归:输出连续值
无监督学习:只有特征、无标签,发现数据内在结构。包括聚类(K-Means)、降维(PCA)、关联规则(Apriori)等。
1.5 损失函数、梯度下降与泛化
监督学习的数学形式:给定数据集 $D = {(x_i, y_i)}{i=1}^n$,学习映射 $f\theta(x) \approx y$。
常见损失函数(回归):平方误差
$$\mathcal{L}(y, f_\theta(x)) = \frac{1}{2}(y - f_\theta(x))^2$$
通过 梯度下降 最小化损失,更新参数 $\theta$。
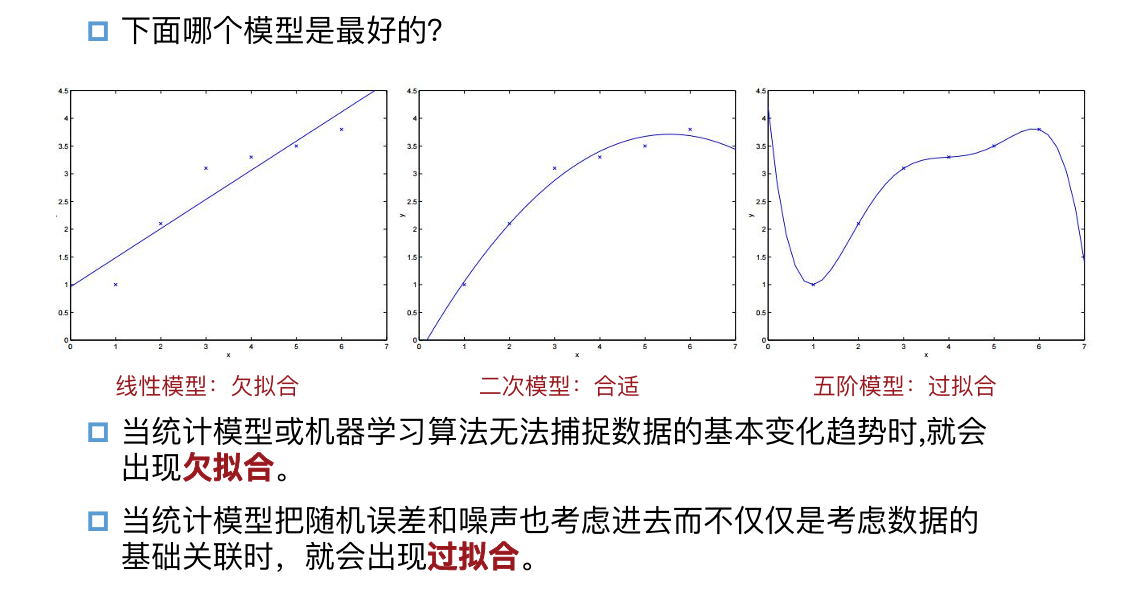
过拟合与欠拟合:
- 欠拟合:模型过于简单,无法捕捉数据趋势(如用直线拟合明显曲线)
- 过拟合:模型过于复杂,把噪声也学进去(如高阶多项式)
1.6 代码练习 0:理解训练/测试划分
"""练习 0:手动实现 train/test 划分,理解监督学习基本流程"""
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 模拟数据:y = 2x + 噪声
rng = np.random.default_rng(42)
X = rng.uniform(0, 10, size=(100, 1))
y = 2 * X.ravel() + rng.normal(0, 1, size=100)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f"测试集 MSE: {mean_squared_error(y_test, pred):.4f}")
print(f"学到的斜率≈2: {model.coef_[0]:.4f}")
2. Python 与 NumPy 基础
机器学习实践离不开 Python。本章要点:
- 数据结构:列表、字典、元组、集合
- NumPy:向量化运算、矩阵操作
- Matplotlib:数据可视化
2.1 NumPy 数组与矩阵运算






2.2 代码练习 1:NumPy 距离计算(KNN 预备)
第 3 章会用到多种距离度量,先用 NumPy 实现:
"""练习 1:实现欧氏距离、曼哈顿距离、闵可夫斯基距离"""
import numpy as np
def euclidean(a: np.ndarray, b: np.ndarray) -> float:
return np.sqrt(np.sum((a - b) ** 2))
def manhattan(a: np.ndarray, b: np.ndarray) -> float:
return np.sum(np.abs(a - b))
def minkowski(a: np.ndarray, b: np.ndarray, p: int = 3) -> float:
return np.sum(np.abs(a - b) ** p) ** (1 / p)
# 电影分类例子:接吻次数、打斗次数
train = np.array([
[104, 3], [100, 2], [81, 1], # 爱情
[10, 101], [5, 99], [2, 98], # 动作
])
labels = ["爱情", "爱情", "爱情", "动作", "动作", "动作"]
unknown = np.array([18, 90])
distances = [euclidean(unknown, x) for x in train]
k = 3
idx = np.argsort(distances)[:k]
votes = [labels[i] for i in idx]
from collections import Counter
print("K=3 预测:", Counter(votes).most_common(1)[0][0])
2.3 代码练习 2:数据归一化(0-1 标准化)
量纲大的特征会主导距离。使用 0-1 标准化:
"""练习 2:0-1 归一化(课件 datingTestSet 同款思路)"""
import numpy as np
def min_max_norm(data: np.ndarray) -> np.ndarray:
min_vals = data.min(axis=0)
max_vals = data.max(axis=0)
return (data - min_vals) / (max_vals - min_vals + 1e-8)
raw = np.array([[40920, 8.3, 0.95], [14488, 7.2, 1.67]])
print("归一化后:\n", min_max_norm(raw))
2.4 代码练习 3:Matplotlib 绘图基础
由于本博客强调机器学习,固对matplotlib不过多赘述,大家感兴趣可以自行了解
"""练习 3:绘制 K 值-准确率折线图模板"""
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei", "SimHei"]
plt.rcParams["axes.unicode_minus"] = False
ks = [1, 3, 5, 7, 9, 11]
acc = [0.92, 0.96, 0.97, 0.965, 0.96, 0.955]
plt.figure(figsize=(8, 5))
plt.plot(ks, acc, "o-", linewidth=2)
plt.xlabel("K(邻居数)")
plt.ylabel("测试准确率")
plt.title("K 值与分类准确率")
plt.grid(alpha=0.3)
plt.savefig("k_vs_accuracy_demo.png", dpi=150, bbox_inches="tight")
plt.close()
3. K 近邻(KNN)
3.1 分类基本思想
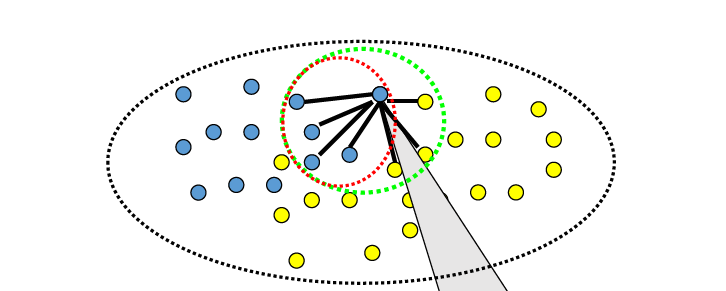
分类解决「这是什么」的问题。核心思想:相似的样本,标签也相似——用距离衡量相似度。
3.2 距离度量
| 距离 | 公式要点 | sklearn 参数 |
|---|---|---|
| 欧氏距离 | $\sqrt{\sum(x_i-y_i)^2}$ | metric='euclidean' |
| 曼哈顿距离 | $\sum|x_i-y_i|$ | metric='manhattan' |
| 闵可夫斯基 | $(\sum|x_i-y_i|p)$ | metric='minkowski', p=3 |
| 余弦距离 | 向量夹角 | metric='cosine' |





3.3 KNN 算法原理
- 计算测试样本与所有训练样本的距离
- 按距离升序,取前 K 个邻居
- 多数表决决定类别
最近邻(NN, K=1) 对噪声敏感;K 近邻 通过扩大投票范围提高鲁棒性。
3.4 KNN 优缺点
优点:简单直观、无需训练阶段(惰性学习)、适合多分类。
缺点:
- 预测时需与全部训练样本算距离,计算量大
- K 值难选:K 过小易过拟合,K 过大易欠拟合
- 对高维数据效果下降(维度灾难)
3.5 代码练习 4:手写数字 KNN识别
数据格式:32×32 文本文件,每行 32 个 0/1,文件名 标签_序号.txt。
精简练习代码:
"""练习 4:sklearn KNN 手写数字识别"""
from pathlib import Path
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
def load_digit_folder(folder: Path):
xs, ys = [], []
for path in sorted(folder.glob("*.txt")):
label = int(path.stem.split("_")[0])
rows = []
with path.open(encoding="utf-8") as f:
for line in f:
line = line.strip()
if line:
rows.append([int(ch) for ch in line])
xs.append(np.asarray(rows, dtype=float).reshape(-1))
ys.append(label)
return np.asarray(xs), np.asarray(ys)
# 修改为你的数据路径
root = Path("机器学习作业/机器学习作业1/数据集")
X_train, y_train = load_digit_folder(root / "trainingDigits")
X_test, y_test = load_digit_folder(root / "testDigits")
# Baseline:sklearn 默认 K=5, 欧氏距离
clf = KNeighborsClassifier()
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
print(f"Baseline 准确率: {accuracy_score(y_test, pred):.4f}")
print(classification_report(y_test, pred))
# 对比不同距离度量
for name, kw in [
("欧氏", {"metric": "euclidean"}),
("曼哈顿", {"metric": "manhattan"}),
("余弦", {"metric": "cosine"}),
]:
model = KNeighborsClassifier(n_neighbors=5, **kw)
model.fit(X_train, y_train)
acc = accuracy_score(y_test, model.predict(X_test))
print(f"{name}距离 K=5 准确率: {acc:.4f}")
3.6 代码练习 5:K 值与距离度量网格搜索
"""练习 5:K 值 × 距离度量对比(对应作业1 grid 实验)"""
import pandas as pd
rows = []
for metric_name, kw in [
("euclidean", {"metric": "euclidean"}),
("manhattan", {"metric": "manhattan"}),
]:
for k in range(1, 16, 2):
m = KNeighborsClassifier(n_neighbors=k, **kw)
m.fit(X_train, y_train)
acc = accuracy_score(y_test, m.predict(X_test))
rows.append({"metric": metric_name, "k": k, "accuracy": acc})
df = pd.DataFrame(rows)
best = df.loc[df["accuracy"].idxmax()]
print("最优组合:\n", best)
3.7 代码练习 6:PCA + KNN 降维实验
"""练习 6:PCA 降维 + KNN 管线"""
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
for n_comp in [10, 20, 50, 100, 200, 512]:
pipe = Pipeline([
("scaler", StandardScaler()),
("pca", PCA(n_components=n_comp, random_state=42)),
("knn", KNeighborsClassifier(n_neighbors=5, metric="euclidean")),
])
pipe.fit(X_train, y_train)
acc = accuracy_score(y_test, pipe.predict(X_test))
print(f"PCA n={n_comp:3d} → 准确率 {acc:.4f}")
4. 支持向量机(SVM)
4.1 核心思想:最大间隔
SVM 寻找能将两类分开的 超平面,使得 间隔(margin) 最大。距离分界最近的样本点称为 支持向量(Support Vector)。
优化目标(硬间隔):最小化 $|w|^2$,约束 $y_i(w^Tx_i+b) \geq 1$。
4.2 软间隔与核函数
软间隔:引入松弛变量,允许部分样本分错,惩罚系数 C 控制容忍度。C 越大越不容错,易过拟合;C 越小间隔越大,易欠拟合。
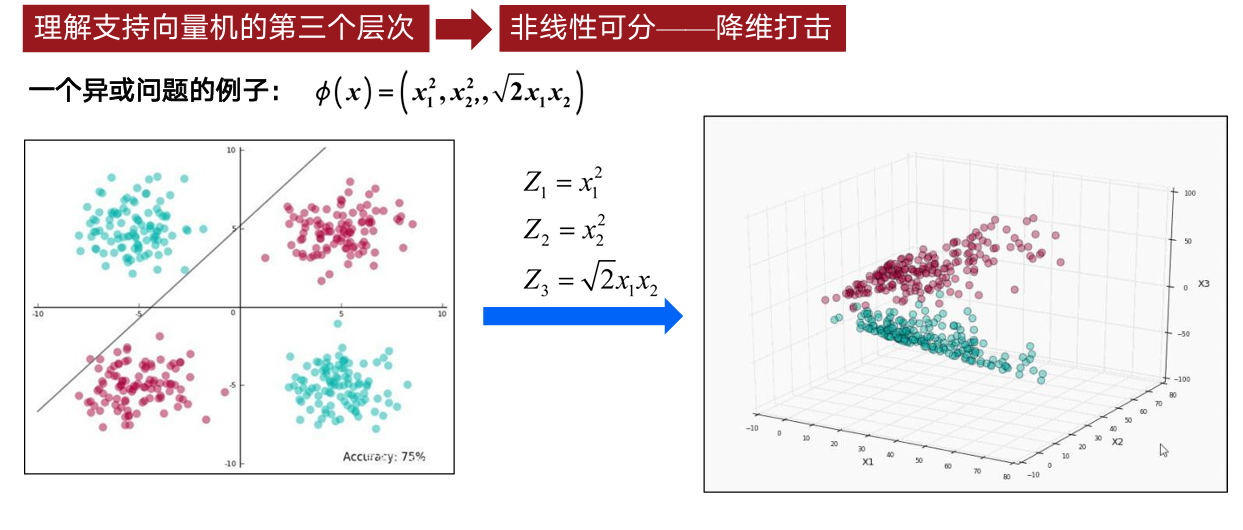
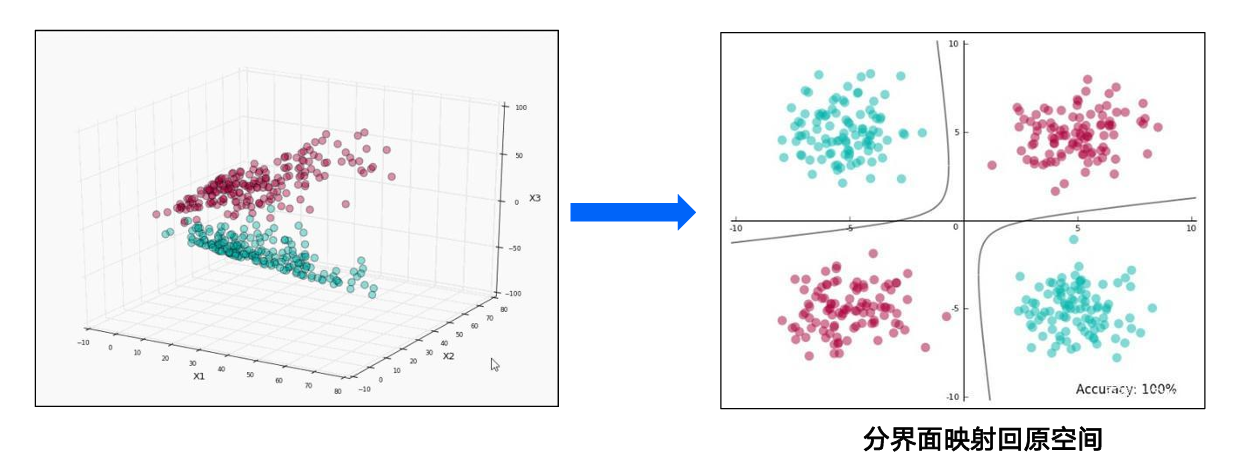
非线性可分:通过核函数 $K(x_i, x_j) = \phi(x_i)^T \phi(x_j)$ 隐式映射到高维空间,无需显式计算 $\phi(x)$。
常用核函数:
| 核函数 | sklearn 参数 | 特点 |
|---|---|---|
| 线性核 | kernel='linear' |
线性可分数据 |
| RBF 高斯核 | kernel='rbf' |
最常用,处理非线性 |
| 多项式核 | kernel='poly' |
多项式决策边界 |
| Sigmoid 核 | kernel='sigmoid' |
类神经网络 |

4.3 SVM vs KNN
SVM 训练后只需支持向量参与预测,预测复杂度低;KNN 预测需遍历全部训练样本。
4.4 代码练习 7:SVM 手写数字识别
"""练习 7:SVM 手写数字 Baseline + 网格搜索"""
from pathlib import Path
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
# 复用练习4的 load_digit_folder
root = Path("机器学习作业/机器学习作业2/手写数字数据集")
X_train, y_train = load_digit_folder(root / "trainingDigits")
X_test, y_test = load_digit_folder(root / "testDigits")
# Baseline SVM (RBF)
baseline = SVC(cache_size=100)
baseline.fit(X_train, y_train)
pred = baseline.predict(X_test)
print(f"Baseline SVM 准确率: {accuracy_score(y_test, pred):.4f}")
# 网格搜索 C × gamma
param_grid = {
"C": [0.1, 1, 10, 100],
"gamma": ["scale", 0.001, 0.01, 0.1],
"kernel": ["rbf"],
}
grid = GridSearchCV(SVC(cache_size=100), param_grid, cv=3, n_jobs=1)
grid.fit(X_train, y_train)
print("最优参数:", grid.best_params_)
print(f"最优测试准确率: {accuracy_score(y_test, grid.predict(X_test)):.4f}")
4.5 代码练习 8:双螺旋数据 KNN vs SVM
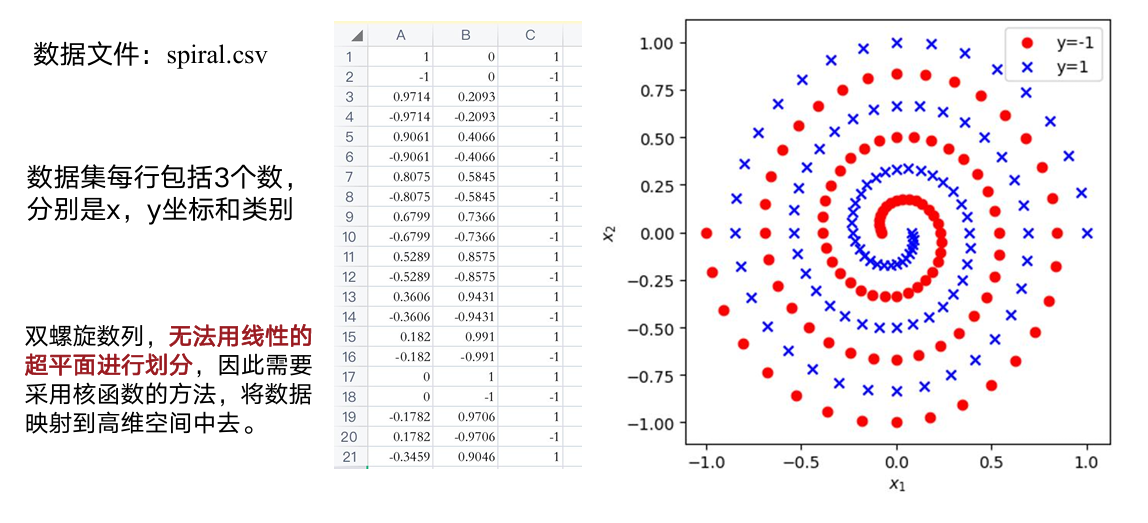
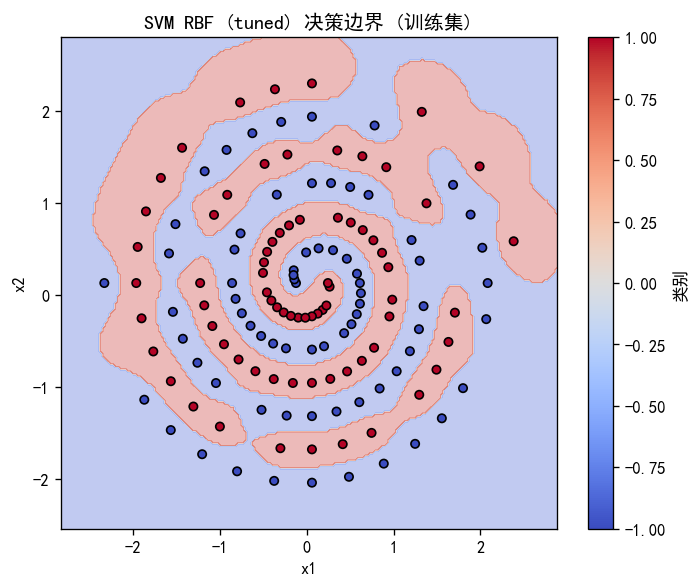
双螺旋 spiral.csv 是典型 非线性可分 数据,线性 SVM 无法胜任,RBF 核 SVM 可以。
"""练习 8:双螺旋数据集上的 KNN / SVM 决策边界"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
df = pd.read_csv("机器学习作业/机器学习作业2/双螺旋/spiral.csv")
X = df[["x", "y"]].values
y = df["label"].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_test_s = scaler.transform(X_test)
for name, clf in [
("KNN k=5", KNeighborsClassifier(n_neighbors=5)),
("SVM linear", SVC(kernel="linear")),
("SVM RBF", SVC(kernel="rbf", gamma="scale")),
]:
clf.fit(X_train_s, y_train)
acc = accuracy_score(y_test, clf.predict(X_test_s))
print(f"{name}: {acc:.4f}")
# 可视化决策边界(简化版)
xx, yy = np.meshgrid(
np.linspace(X_train_s[:, 0].min() - 0.5, X_train_s[:, 0].max() + 0.5, 200),
np.linspace(X_train_s[:, 1].min() - 0.5, X_train_s[:, 1].max() + 0.5, 200),
)
svm = SVC(kernel="rbf", gamma="scale")
svm.fit(X_train_s, y_train)
Z = svm.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap="coolwarm")
plt.scatter(X_train_s[:, 0], X_train_s[:, 1], c=y_train, cmap="coolwarm", edgecolors="k", s=20)
plt.title("双螺旋:RBF-SVM 决策边界")
plt.savefig("spiral_svm_boundary.png", dpi=150)
plt.close()
5. 决策树
5.1 决策树结构
决策树由 根节点、内部节点(属性测试)、叶节点(类别输出)组成。学习过程是 自上而下分而治之 的递归划分。
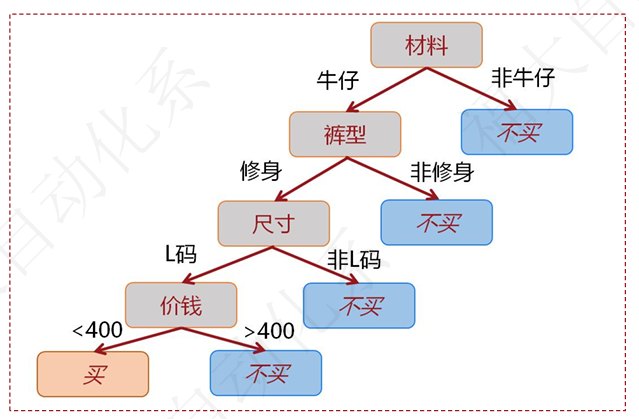
停止条件:
- 当前节点样本全属同一类
- 属性集为空或所有样本属性取值相同
- 样本集合为空
5.2 信息熵与信息增益(ID3)
信息熵 衡量纯度:
$$\text{Ent}(D) = -\sum_{k=1}^{K} p_k \log_2 p_k$$
信息增益:选择使划分后熵下降最大的属性。ID3 算法用信息增益选特征。
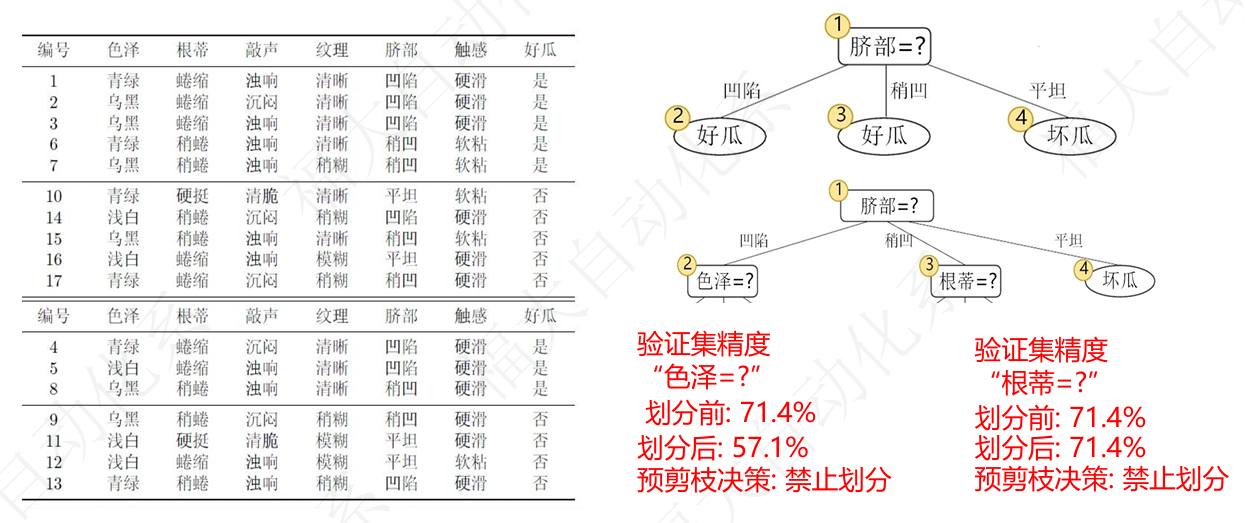
5.3 剪枝与缺失值
预剪枝 / 后剪枝:控制树深度,防止过拟合。sklearn 中 max_depth、min_samples_leaf 等参数实现预剪枝。
缺失值处理:对含缺失样本赋权,在划分时按无缺失子集计算信息增益(课件 6.2 节)。

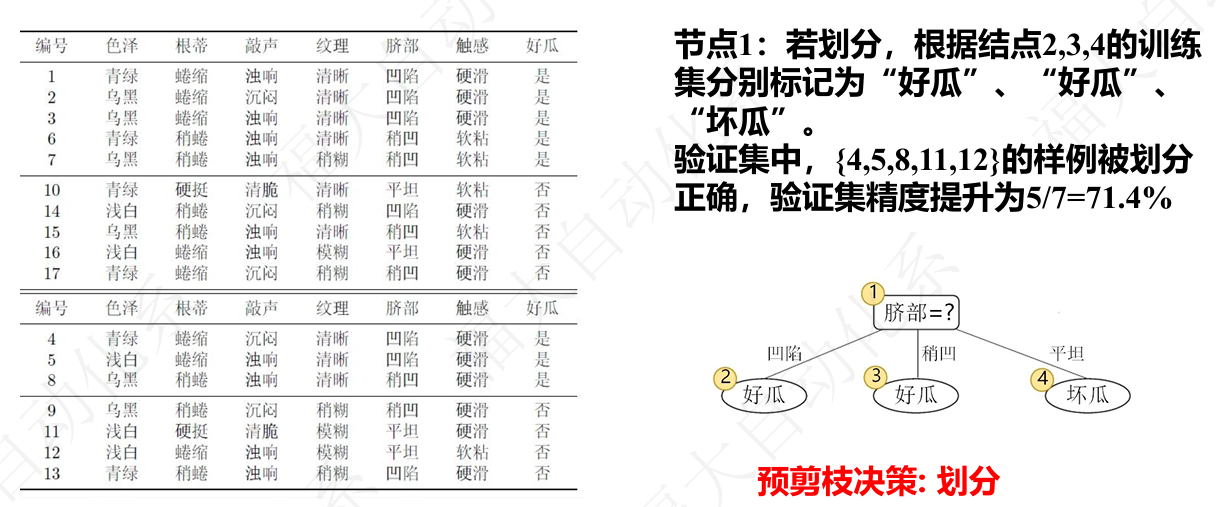

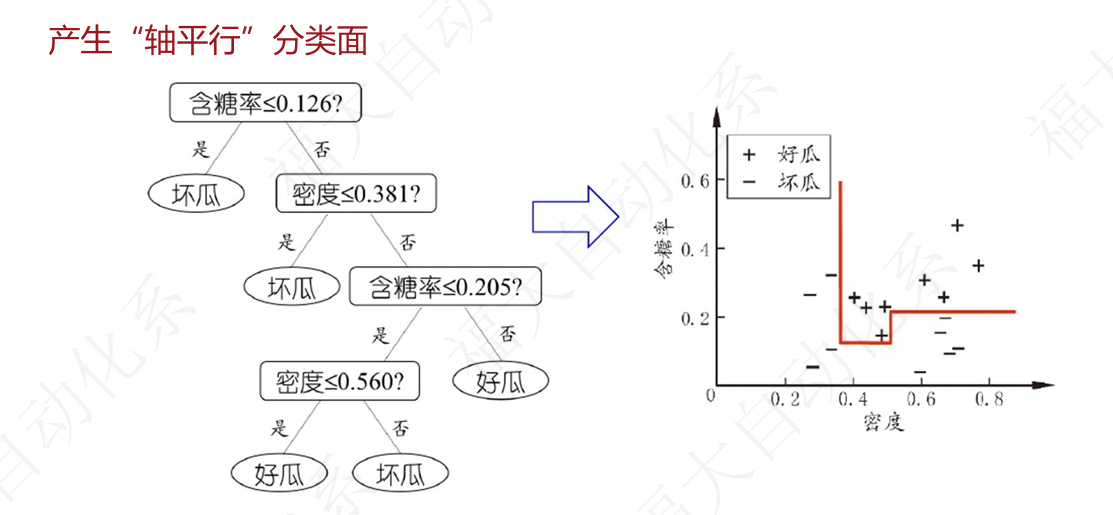
5.4 决策树本质
决策树产生 轴平行(axis-parallel) 分类边界——每个划分对应一个特征阈值。复杂边界需要很多段划分。
5.5 代码练习 9:泰坦尼克号 Age 缺失值填补
- 用 KNN / SVR 回归预测 Age,比较不同特征组合
- 用不同 Age 填补策略训练决策树,预测 Survived
"""练习 9:泰坦尼克 Age 缺失值 KNN 回归填补"""
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error
df = pd.read_csv("机器学习作业/机器学习作业3/泰坦尼克号/train.csv")
known = df[df["Age"].notna()].copy()
feature_cols = ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"]
X = known[feature_cols]
y = known["Age"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
pre = ColumnTransformer([
("num", Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]), ["Pclass", "SibSp", "Parch", "Fare"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
]), ["Sex", "Embarked"]),
])
pipe = Pipeline([
("pre", pre),
("model", KNeighborsRegressor(n_neighbors=5, weights="distance")),
])
pipe.fit(X_train, y_train)
pred = pipe.predict(X_test)
print(f"Age 预测 MAE: {mean_absolute_error(y_test, pred):.3f} 岁")
5.6 代码练习 10:决策树生存预测
"""练习 10:决策树预测泰坦尼克生存"""
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import cross_val_score
# 用 KNN 填补后的 Age
def impute_age_knn(df, feature_cols):
data = df.copy()
known = data[data["Age"].notna()]
missing = data[data["Age"].isna()]
if missing.empty:
return data["Age"]
pre = ColumnTransformer([
("num", Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]), [c for c in feature_cols if c not in ("Sex", "Embarked")]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
]), [c for c in feature_cols if c in ("Sex", "Embarked")]),
])
reg_pipe = Pipeline([("pre", pre), ("model", KNeighborsRegressor(n_neighbors=5))])
reg_pipe.fit(known[feature_cols], known["Age"])
data.loc[missing.index, "Age"] = reg_pipe.predict(missing[feature_cols])
return data["Age"]
features = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
df = pd.read_csv("机器学习作业/机器学习作业3/泰坦尼克号/train.csv")
df["Age"] = impute_age_knn(df, ["Pclass", "Sex", "SibSp", "Parch", "Fare", "Embarked"])
X = df[features]
y = df["Survived"]
dt_pipe = Pipeline([
("pre", ColumnTransformer([
("num", Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]), ["Pclass", "Age", "SibSp", "Parch", "Fare"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
]), ["Sex", "Embarked"]),
])),
("clf", DecisionTreeClassifier(max_depth=5, min_samples_leaf=5, random_state=42)),
])
cv = cross_val_score(dt_pipe, X, y, cv=5, scoring="accuracy")
print(f"5折CV准确率: {cv.mean():.4f} ± {cv.std():.4f}")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42, stratify=y)
dt_pipe.fit(X_train, y_train)
print(classification_report(y_test, dt_pipe.predict(X_test), target_names=["未生还", "生还"]))

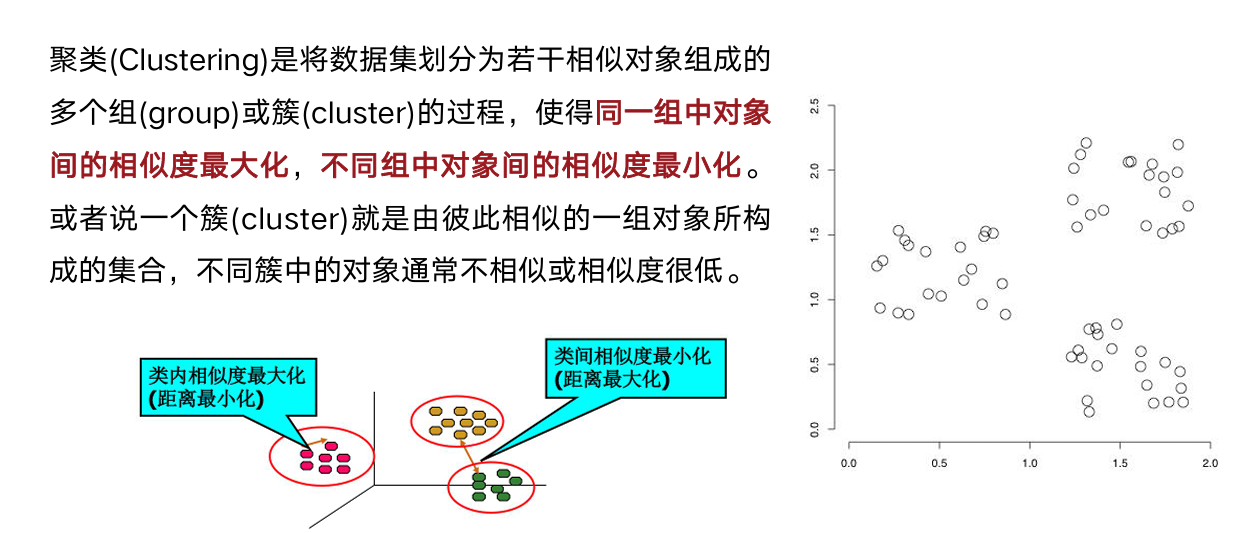
6. K-Means 聚类
6.1 聚类与无监督学习
聚类 将样本划分为若干簇,使簇内相似、簇间相异。与分类不同:类别不是事先给定的。
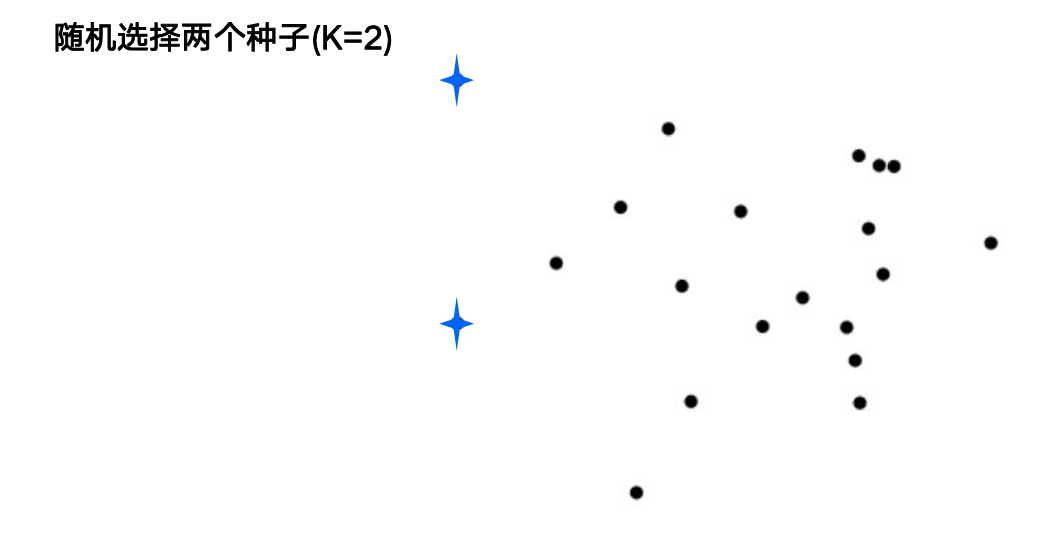
6.2 K-Means 算法
目标:最小化簇内平方和 SSE( inertia )
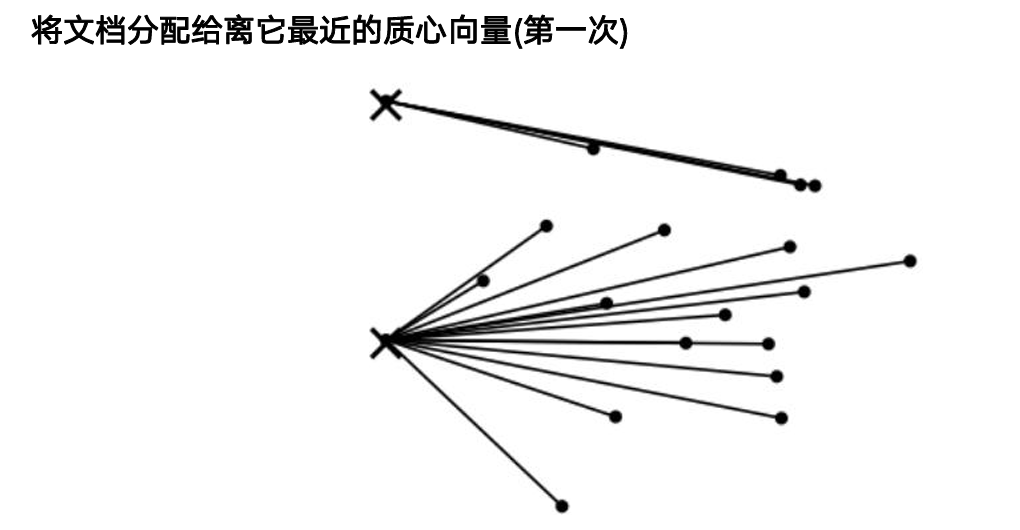
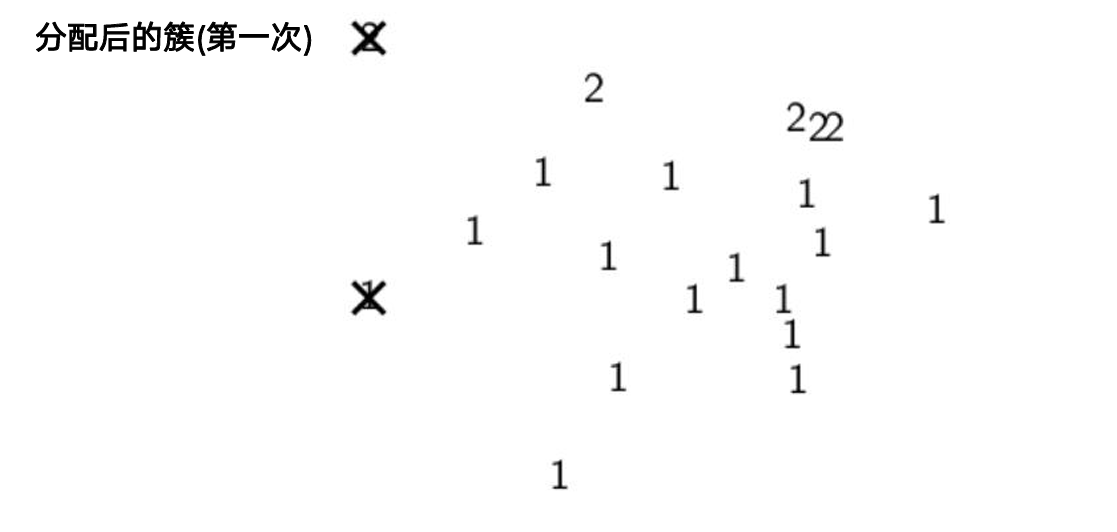
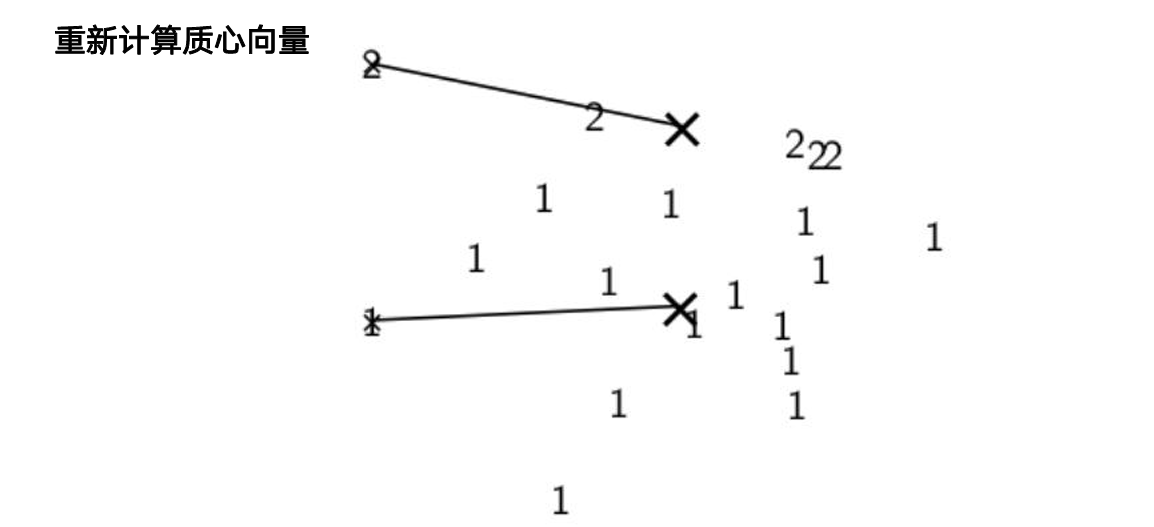
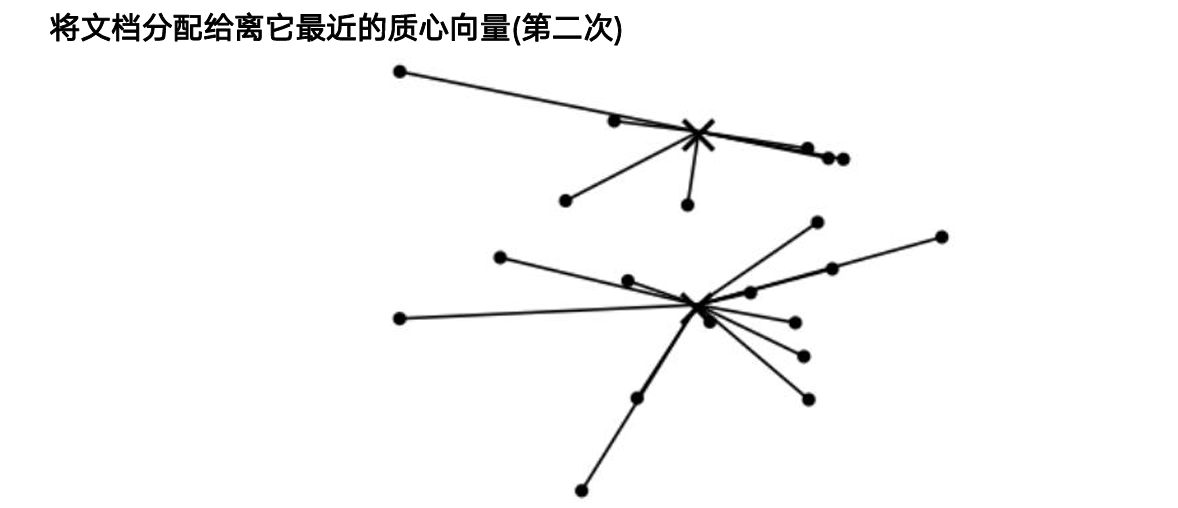
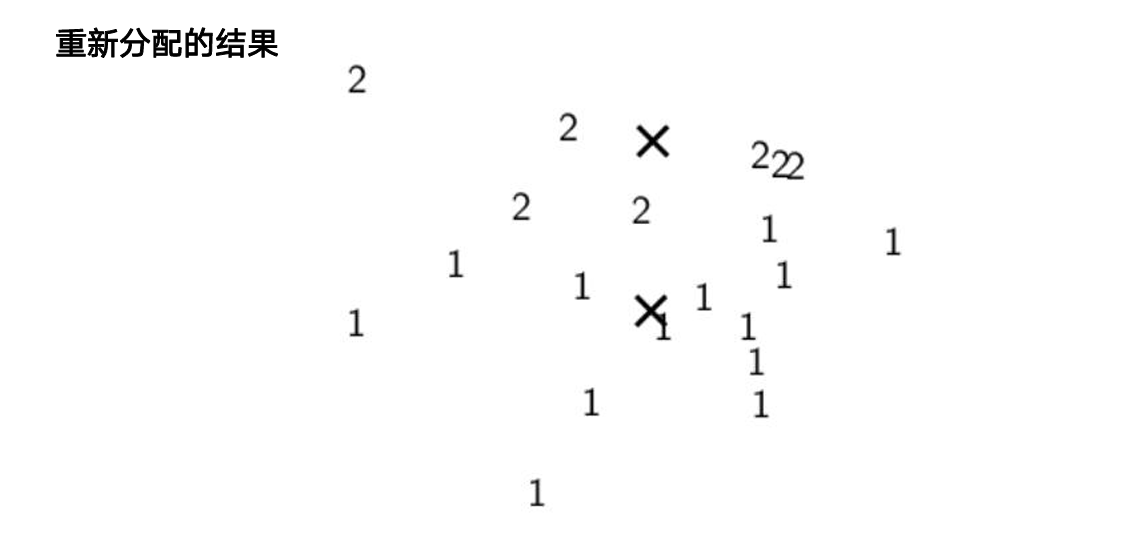
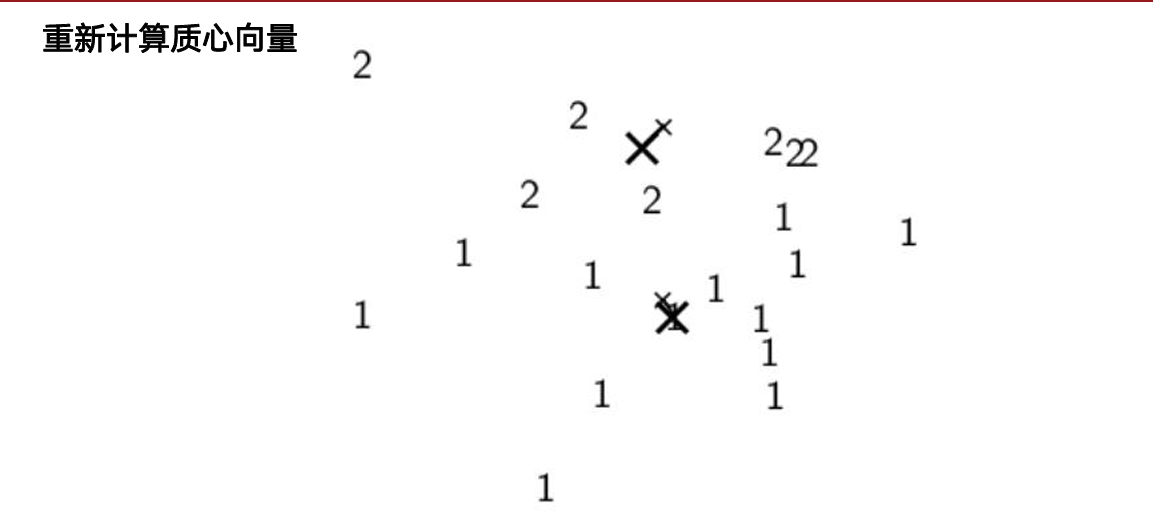
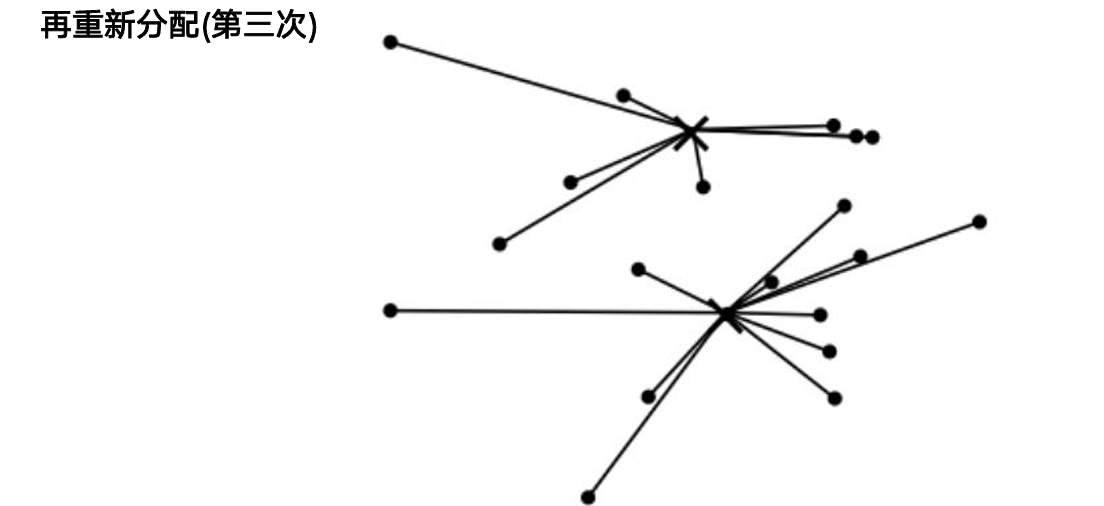
Lloyd 迭代:
- 初始化 K 个质心(推荐
k-means++) - 分配:每个样本归入最近质心
- 更新:重新计算各簇均值作为新质心
- 重复 2–3 直到收敛
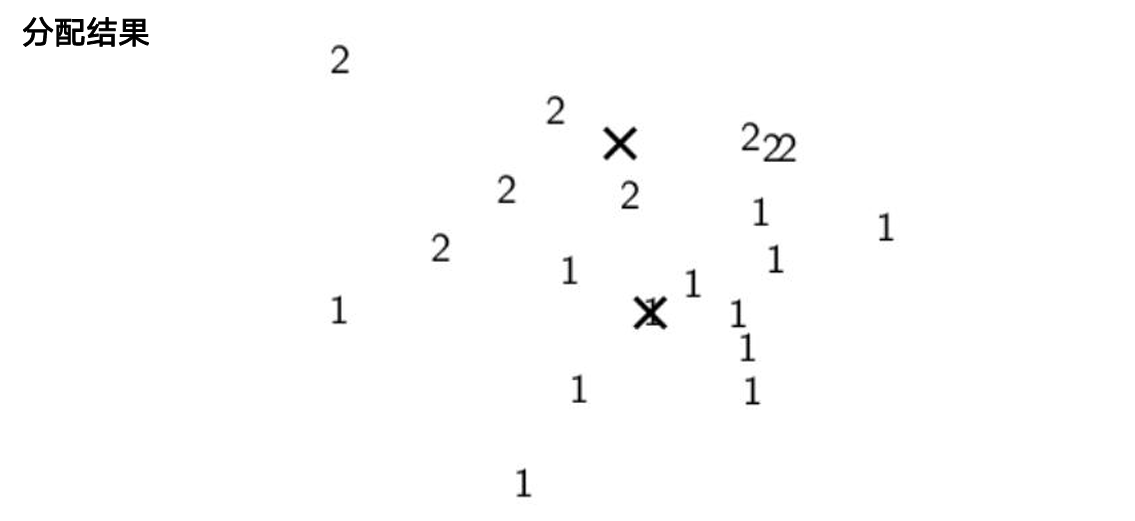
..........
6.3 K 值选择
| 方法 | 说明 |
|---|---|
| 肘部法 | SSE 随 K 增大而下降,选下降率突变(拐点)处 |
| 轮廓系数 | SC 越大越好,K 取 SC 最大值 |
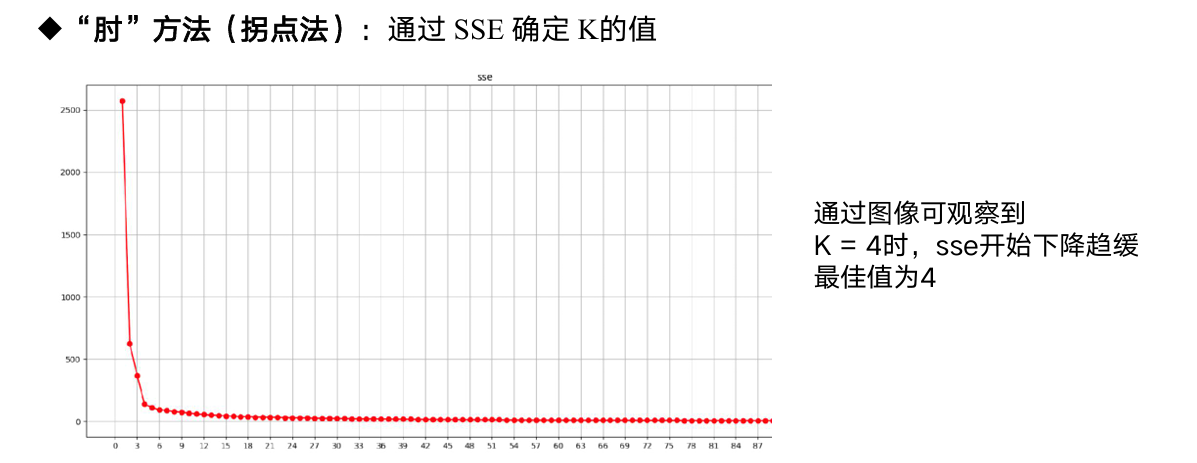
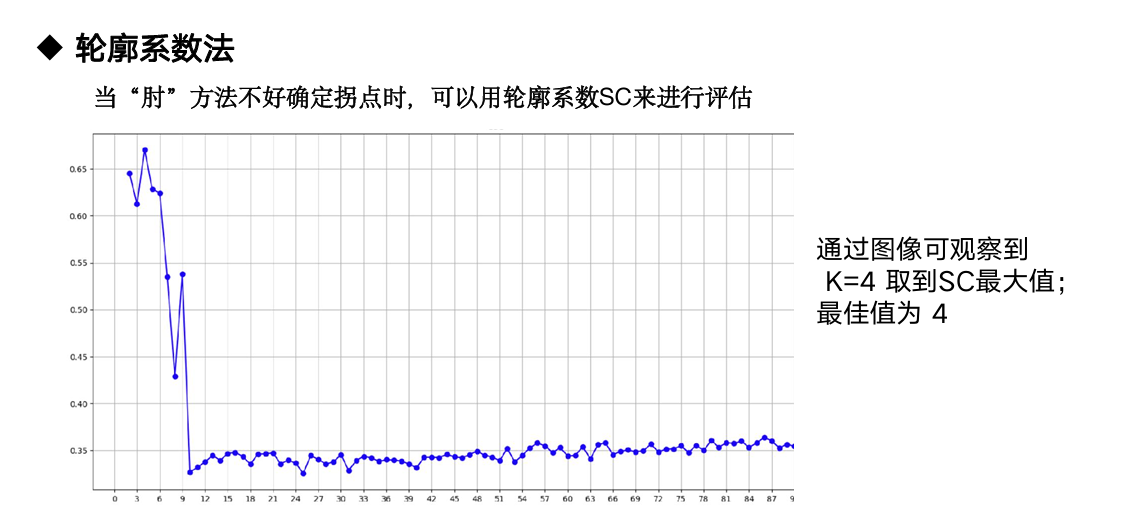
6.4 注意事项
- 标准化:各特征量纲差异大时必须
StandardScaler - 初值敏感:使用
init='k-means++' - 异常点:均值质心易受离群点影响(K-Medoids 更鲁棒)
6.5 代码练习 11:连锁餐饮 K-Means
数据:restaurant.csv,V1=地区,V2–V9 为经营指标。
"""练习 11:连锁餐饮 K-Means 聚类(作业4核心)"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
df = pd.read_csv("机器学习作业/机器学习作业4/restaurant.csv")
CLUSTER_FEATURES = ["V3", "V4", "V5", "V6", "V7"] # 门店数、人数、面积、餐位、营业额
X_raw = df[CLUSTER_FEATURES].astype(float).values
X = StandardScaler().fit_transform(X_raw)
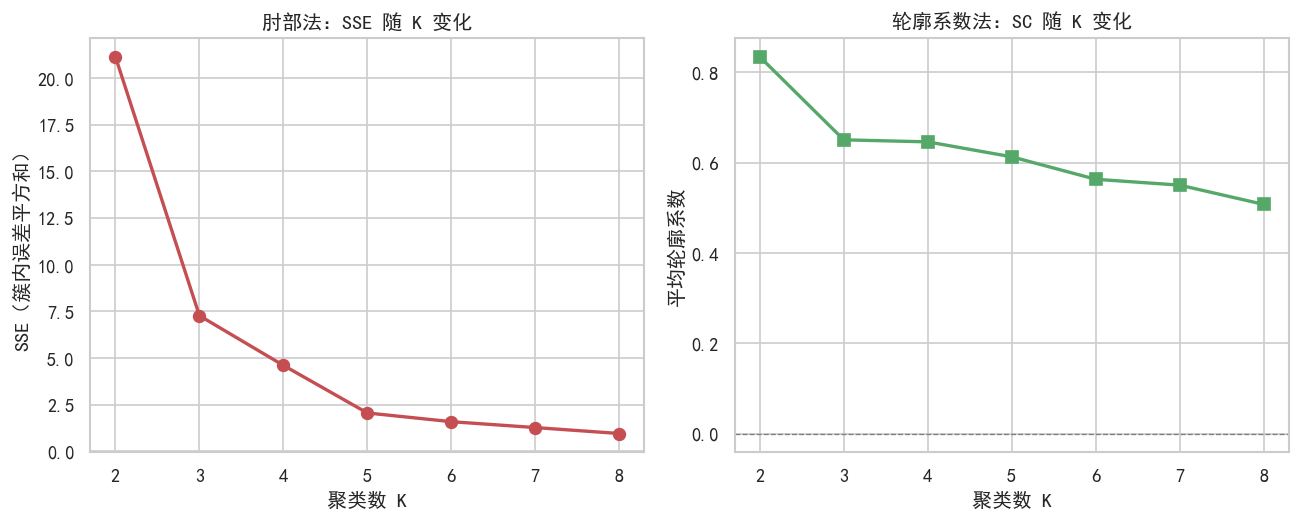
# K 值评估:肘部法 + 轮廓系数
sse_list, sil_list = [], []
for k in range(2, 9):
km = KMeans(n_clusters=k, init="k-means++", n_init=10, random_state=42)
labels = km.fit_predict(X)
sse_list.append(km.inertia_)
sil_list.append(silhouette_score(X, labels))
print(f"K={k} SSE={km.inertia_:.2f} SC={sil_list[-1]:.4f}")
chosen_k = range(2, 9)[int(np.argmax(sil_list))]
km = KMeans(n_clusters=chosen_k, init="k-means++", n_init=10, random_state=42)
labels = km.fit_predict(X)
df["cluster"] = labels
print("\n各地区聚类结果:")
print(df[["V1", "cluster"] + CLUSTER_FEATURES].sort_values("cluster"))
# PCA 二维可视化
pca = PCA(n_components=2, random_state=42)
X2 = pca.fit_transform(X)
plt.figure(figsize=(8, 6))
plt.scatter(X2[:, 0], X2[:, 1], c=labels, cmap="viridis", s=80, edgecolors="k")
for i, name in enumerate(df["V1"]):
plt.annotate(name, (X2[i, 0], X2[i, 1]), fontsize=7)
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title(f"连锁餐饮 PCA 聚类可视化 (K={chosen_k})")
plt.savefig("restaurant_clusters.png", dpi=150, bbox_inches="tight")
plt.close()
7. 主成分分析(PCA)
7.1 降维动机
高维数据带来 维数灾难:计算量大、易过拟合、难以可视化。降维分为:
- 特征选择:保留原始特征子集
- 特征提取:通过变换得到新特征(PCA 属于此类)
7.2 PCA 原理
PCA 通过 正交变换 将数据投影到方差最大的方向:
- 第一主成分 PC1:数据方差最大的方向
- 第二主成分 PC2:与 PC1 正交且方差次大的方向
- 保留前 k 个主成分,尽可能保留原始信息
几何解释:找到数据分布椭圆的 长轴 方向作为主成分。
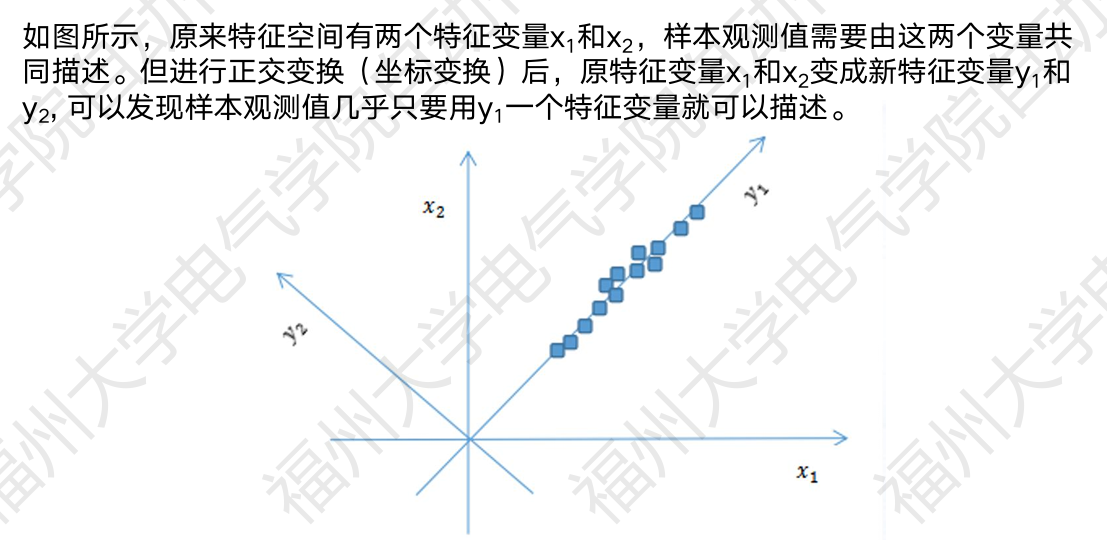
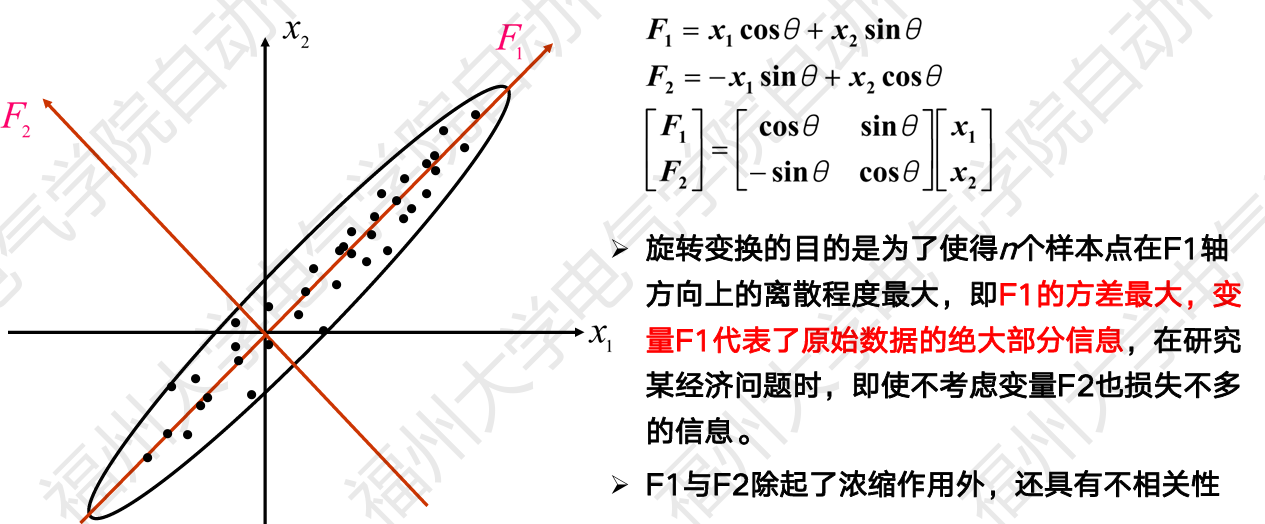
7.3 代码练习 12:PCA 降维与方差解释比
"""练习 12:PCA 方差解释比与二维可视化"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
df = pd.read_csv("机器学习作业/机器学习作业4/restaurant.csv")
cols = ["V3", "V4", "V5", "V6", "V7", "V8", "V9"]
X = StandardScaler().fit_transform(df[cols].astype(float))
pca = PCA()
pca.fit(X)
print("各主成分方差解释比:", np.round(pca.explained_variance_ratio_, 4))
print("累计解释比:", np.round(np.cumsum(pca.explained_variance_ratio_), 4))
# 碎石图
plt.figure(figsize=(8, 4))
plt.bar(range(1, len(cols)+1), pca.explained_variance_ratio_, label="单个")
plt.plot(range(1, len(cols)+1), np.cumsum(pca.explained_variance_ratio_), "ro-", label="累计")
plt.xlabel("主成分编号")
plt.ylabel("方差解释比")
plt.legend()
plt.title("PCA 碎石图")
plt.savefig("pca_scree_plot.png", dpi=150)
plt.close()
8. 卷积神经网络(CNN)
8.1 深度学习两大本质
- 特征自动学习:替代 SIFT、HOG 等手工特征
- 层次网络结构:低层→高层,特征越来越抽象(模拟人脑视觉层次)

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)