构建 AI Agent 应该优先设计路由,把模型选型留到最后。Tom Tunguz 谏言。
在 2026 年的今天,如果你去翻看各大技术团队构建 AI 智能体(Agent)的架构设计文档,你会发现一个非常普遍的“反向骚操作”:绝大多数团队都是先敲定用哪个大模型(比如非 GPT-5.5 或 Claude 4.8 不选),然后才去设计系统的业务架构。
知名风投家、技术洞察者 Tom Tunguz 近日发表了一篇博客。他言辞犀利地指出:大家都把因果关系搞反了!在 Agent 架构中,模型的选择应当是最后一个被做出的决策,而不是第一个。真正的核心枢纽,应当是你的路由层(Router)。
值得注意的是,随着越来越多企业同时接入多家模型服务商,路由层也逐渐从一套架构设计演变为一项基础设施。像 MAI Gateway 这样的 AI 网关,已经开始将智能路由、模型调度、故障切换等能力统一沉淀到网关层,让上层 Agent 更专注于业务逻辑,而不是模型切换本身。欢迎联系我们试用:添加我为微信好友
大实话:其中的新东西其实并不多
坦白讲,通读 Tunguz 的这套理论,对于老架构师来说其实“新东西并不多”。它本质上就是把传统分布式系统中的**“负载均衡”、“意图路由”与“异步队列”**等经典的软件工程思维,重新投射到了大模型应用开发领域。
但正如那句名言所说:“人类总是在发明已经存在的轮子。”正因为现在太多团队被大厂的模型宣发牵着鼻子走,患上了严重的“模型焦虑症”,这套看似传统的工程流控划分,反而成了治愈 Agent 降本增效的良药。

一、 Coinbase 的神话:Token 消耗指数级暴涨,AI 账单却直接腰斩
如果把路由层设计好了,回报能有多夸张?
Tunguz 拿 Coinbase 首席执行官 Brian Armstrong 上周分享的硬核案例进行了背书:Coinbase 在内部大面积铺设 AI 智能体后,整体的 Token 消耗量呈现指数级(Exponential)的恐怖爆发,但最终全公司的 AI 总账单却被生生砍掉了一半!
他们是怎么做到的?Brian Armstrong 总结了一句话:
“想要在 Token 用量暴增的同时让 AI 开销保持平稳,靠的绝对不是天天给员工发‘预算超额警告’这种制造内耗的动作。我们靠的是更好的默认值、更聪明的路由(Routing)以及极致的缓存。 工程师依然可以自由选择他们想要的任何模型,但默认的路由机制决定了一切。”
只要把路由层做对,70-80% 的日常智能体流量完全可以直接分流到本地部署的免费开源微调模型上,或者通过异步批处理模型(Async Batch Reasoning) 派发任务,从而直接砍掉 90%+ 的实时推理开销。
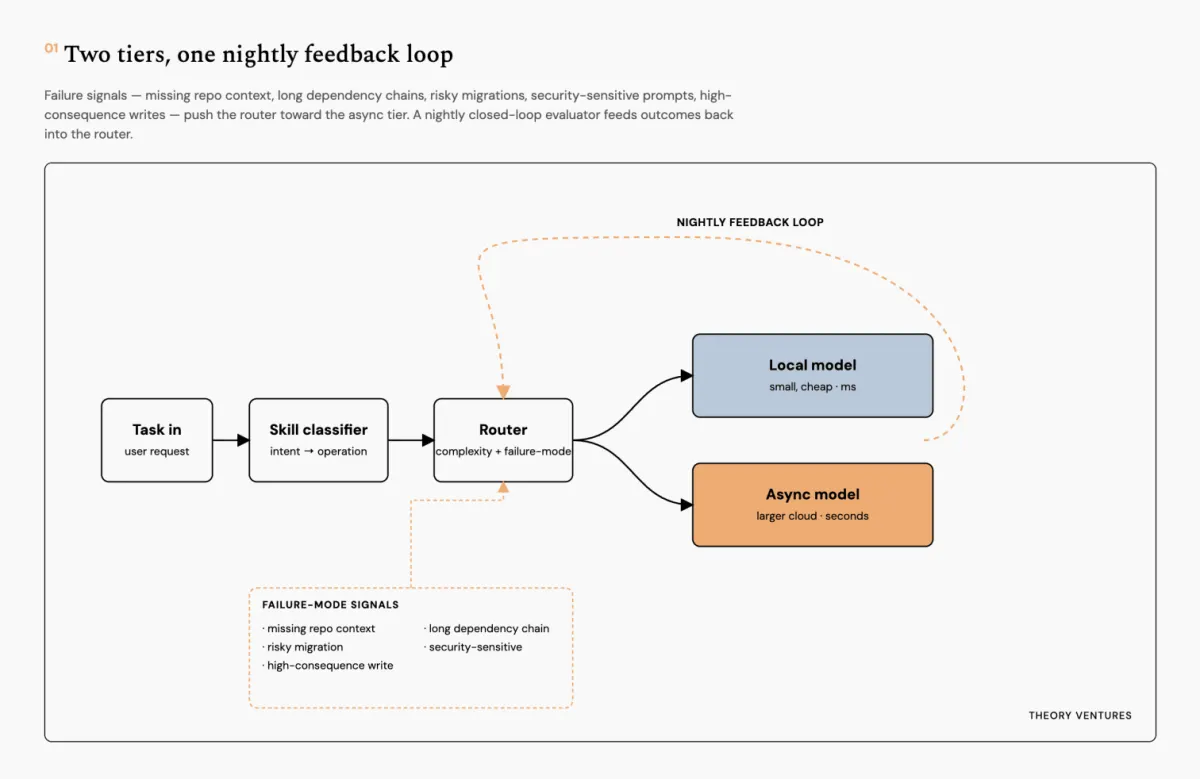
二、 务实工程学:大模型路由器的“三层画布”
在 Tunguz 的设计蓝图中,一个合格的 AI 智能体执行路由层应当被严密地拆解为以下三个相互独立、各司其职的模块:
| 架构层级 | 核心角色定位 | 它要回答什么问题? | 它的底层技术本质 |
|
Layer 1: 技能分类器 (Skill Classifier) |
意图识别专家 将用户丢过来的原始、模糊的 Prompt 转化为一个确定性的具体操作(如:撰写邮件回复、代码库摘要、执行数据库迁移等)。 |
“这个任务到底是什么?” |
语言问题 (Language Problem) 主要依赖大模型的语义理解能力。 |
|
Layer 2: 路由器 (Router) |
流量调度总闸 根据分类器打上的标签,决定将该操作分流到哪个算力梯队(Tier)去执行。注意:路由器根本不读用户的具体 Prompt 内容! |
“应该把任务派给哪个梯队?” |
调度问题 (Scheduling Problem) 它只读取任务标签、复杂度、上下文长度和历史成功率。 |
|
Layer 3: 模型选择器 (Model Selector) |
极限价格刺客 在路由器圈定的那一个特定的算力梯队里,横向比对所有可用模型,挑选出那个刚好能满足置信度阈值、且价格最便宜的夹逼模型。 |
“谁是性价比最高的底层耗材?” |
成本流控问题 (Cost Optimizer) |
⚠️ 避坑红线:绝对不要把分类器与路由器混为一谈!
很多技术团队图省事,直接在系统提示词(System Prompt)里写:“如果你觉得任务很难,你就去调用 GPT-4o;如果简单,你就调用 GPT-4o-mini”。
这是极其不合格的工程反模式。
一旦你把“调度决策”死死地揉进了 Prompt 内部,你就等于把模型的选择权完全拱手让给了大模型的非确定性输出。这不仅会导致 Token 开销失控,还会彻底摧毁你针对同一个业务操作去横向 A/B 测试不同模型表现的能力。分类器负责看懂业务,路由器负责卡死调度,两条链路必须在工程上完全解耦。
三、 异步队列:AI 降本 100 倍的隐形大杀器
为什么这套三层路由机制在实际落地时能省下惊人的开销?
因为绝大多数团队高估了业务对“实时推理(Real-Time Inference)”的依赖性。本地计算和本地微调模型的边际成本几乎为零,而异步批处理推理(Async Batch Reasoning)的开销比实时并发调用便宜了整整两个数量级(100倍左右)。
真正的工程硬核拷问其实窄得多:到底有多少比例的工作,真的需要用户在电脑前死等那 1 秒钟的实时响应?
一旦你在网关和系统架构中垫入了“队列(Queueing)”机制,你会发现绝大多数智能体长周期任务都不需要 sub-second(亚秒级)的延迟:
-
自动生成一封邮件草稿;
-
对整个代码仓库做一次日常维护摘要;
-
深夜跑一次全量自动化评估、测试集审计;
-
生成一份几十页的尽职调查备忘录。
这些活儿在后台队列里排队跑个几分钟,对最终用户体验毫无大碍,但路由层却能在后台安安稳稳地帮你切流到最便宜的异步批处理通道上,把账单直接打骨折。
四、 动态进化:Tom Tunguz 团队的路由反馈闭环
在他们自己手搓的智能体运行时(Agent Runtime)第一版中,路由器已经能够根据任务复杂度、上下文尺寸和本地内存检索命中率进行智能打分。在此基础上,他们又在路由层上方外挂了两个不同时间尺度(Time Scales)的闭环反馈机制,非常值得抄作业:
1. 同步失败模式信号(短周期拦截)
预测器(Predictor)会像雷达一样,对每一个流进来的路由请求实时标注 5 个硬核特征:
-
是否缺失代码库上下文;
-
是否包含过长的依赖链;
-
是否涉及高风险的数据库迁移;
-
是否命中了安全敏感的提示词注入;
-
是否包含高后果的物理写操作。
在任务真正因为大模型逻辑崩溃而产生破坏性死掉之前,同步预测器就能在前端提前拦截那些肉眼可见的“高危硬活”,强行对其进行提权或人工介入机制。
2. 夜间闭环异步评估(长周期演进)
每天深夜,批量评估器(Batch Evaluator)会自动把前一天产生的所有智能体运行轨迹(Traces)全部拉出来重新打分审计,找出白天被预测器漏掉的新型失败模式,并在夜间全自动更新路由器的权重参数。整个夜间评估全量跑在最便宜的异步推理服务上,评测成本近乎为零。
总结
对于已经进入多模型、Agent 协同开发阶段的团队来说,把路由能力统一收敛到 AI 网关层,往往比在每个 Agent 内重复编写模型切换逻辑更容易维护。以 MAI Gateway 为代表的智能网关,可以根据任务复杂度、模型状态等因素完成智能路由和故障切换,让模型真正成为可替换的底层资源,而不是业务代码中的固定依赖。产品试用添加:添加我为微信好友
把大模型当成可以随时被低价平替的"算力耗材",把架构重心死死压在分类器-路由器-选择器的流控建设上。围绕路由设计系统,把模型选型留在最后——这才是 2026 年大模型应用真正走向工业级成熟的及格线。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)