定讯飞云 ASR 中英语音识别:MicroPython+uPyPI一键安装驱动包
.3 Demo 解读
下面是大模型中文 + 方言语音识别 Demo python 语言:
# -*- coding:utf-8 -*- |
|
# |
|
# author: iflytek |
|
# |
|
# 本demo测试时运行的环境为:Windows + Python3.7 |
|
# 本demo测试成功运行时所安装的第三方库及其版本如下,您可自行逐一或者复制到一个新的txt文件利用pip一次性安装: |
|
# cffi==1.12.3 |
|
# gevent==1.4.0 |
|
# greenlet==0.4.15 |
|
# pycparser==2.19 |
|
# six==1.12.0 |
|
# websocket==0.2.1 |
|
# websocket-client==0.56.0 |
|
# |
|
# 语音听写流式 WebAPI 接口调用示例 接口文档(必看):https://doc.xfyun.cn/rest_api/语音听写(流式版).html |
|
# webapi 听写服务参考帖子(必看):http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=38947&extra= |
|
# 语音听写流式WebAPI 服务,热词使用方式:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--个性化热词, |
|
# 设置热词 |
|
# 注意:热词只能在识别的时候会增加热词的识别权重,需要注意的是增加相应词条的识别率,但并不是绝对的,具体效果以您测试为准。 |
|
# 语音听写流式WebAPI 服务,方言试用方法:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--识别语种列表 |
|
# 可添加语种或方言,添加后会显示该方言的参数值 |
|
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看) |
|
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # |
|
import _thread as thread |
|
import time |
|
from time import mktime |
|
import websocket |
|
import base64 |
|
import datetime |
|
import hashlib |
|
import hmac |
|
import json |
|
import ssl |
|
from datetime import datetime |
|
from urllib.parse import urlencode |
|
from wsgiref.handlers import format_date_time |
|
STATUS_FIRST_FRAME = 0 # 第一帧的标识 |
|
STATUS_CONTINUE_FRAME = 1 # 中间帧标识 |
|
STATUS_LAST_FRAME = 2 # 最后一帧的标识 |
|
class Ws_Param(object): |
|
# 初始化 |
|
def __init__(self, APPID, APIKey, APISecret, AudioFile): |
|
self.APPID = APPID |
|
self.APIKey = APIKey |
|
self.APISecret = APISecret |
|
self.AudioFile = AudioFile |
|
self.iat_params = { |
|
"domain": "slm", "language": "zh_cn", "accent": "mandarin","dwa":"wpgs", "result": |
|
{ |
|
"encoding": "utf8", |
|
"compress": "raw", |
|
"format": "plain" |
|
} |
|
} |
|
# 生成url |
|
def create_url(self): |
|
url = 'ws://iat.xf-yun.com/v1' |
|
# 生成RFC1123格式的时间戳 |
|
now = datetime.now() |
|
date = format_date_time(mktime(now.timetuple())) |
|
# 拼接字符串 |
|
signature_origin = "host: " + "iat.xf-yun.com" + "\n" |
|
signature_origin += "date: " + date + "\n" |
|
signature_origin += "GET " + "/v1 " + "HTTP/1.1" |
|
# 进行hmac-sha256进行加密 |
|
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'), |
|
digestmod=hashlib.sha256).digest() |
|
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') |
|
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % ( |
|
self.APIKey, "hmac-sha256", "host date request-line", signature_sha) |
|
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') |
|
# 将请求的鉴权参数组合为字典 |
|
v = { |
|
"authorization": authorization, |
|
"date": date, |
|
"host": "iat.xf-yun.com" |
|
} |
|
# 拼接鉴权参数,生成url |
|
url = url + '?' + urlencode(v) |
|
# print("date: ",date) |
|
# print("v: ",v) |
|
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致 |
|
# print('websocket url :', url) |
|
return url |
|
# 收到websocket消息的处理 |
|
def on_message(ws, message): |
|
message = json.loads(message) |
|
code = message["header"]["code"] |
|
status = message["header"]["status"] |
|
if code != 0: |
|
print(f"请求错误:{code}") |
|
ws.close() |
|
else: |
|
payload = message.get("payload") |
|
if payload: |
|
text = payload["result"]["text"] |
|
text = json.loads(str(base64.b64decode(text), "utf8")) |
|
text_ws = text['ws'] |
|
result = '' |
|
for i in text_ws: |
|
for j in i["cw"]: |
|
w = j["w"] |
|
result += w |
|
print(result) |
|
if status == 2: |
|
ws.close() |
|
# 收到websocket错误的处理 |
|
def on_error(ws, error): |
|
print("### error:", error) |
|
# 收到websocket关闭的处理 |
|
def on_close(ws, close_status_code, close_msg): |
|
print("### closed ###") |
|
# 收到websocket连接建立的处理 |
|
def on_open(ws): |
|
def run(*args): |
|
frameSize = 1280 # 每一帧的音频大小 |
|
intervel = 0.04 # 发送音频间隔(单位:s) |
|
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧 |
|
with open(wsParam.AudioFile, "rb") as fp: |
|
while True: |
|
buf = fp.read(frameSize) |
|
audio = str(base64.b64encode(buf), 'utf-8') |
|
# 文件结束 |
|
if not buf: |
|
status = STATUS_LAST_FRAME |
|
# 第一帧处理 |
|
if status == STATUS_FIRST_FRAME: |
|
d = {"header": |
|
{ |
|
"status": 0, |
|
"app_id": wsParam.APPID |
|
}, |
|
"parameter": { |
|
"iat": wsParam.iat_params |
|
}, |
|
"payload": { |
|
"audio": |
|
{ |
|
"audio": audio, "sample_rate": 16000, "encoding": "raw" |
|
} |
|
}} |
|
d = json.dumps(d) |
|
ws.send(d) |
|
status = STATUS_CONTINUE_FRAME |
|
# 中间帧处理 |
|
elif status == STATUS_CONTINUE_FRAME: |
|
d = {"header": {"status": 1, |
|
"app_id": wsParam.APPID}, |
|
"parameter": { |
|
"iat": wsParam.iat_params |
|
}, |
|
"payload": { |
|
"audio": |
|
{ |
|
"audio": audio, "sample_rate": 16000, "encoding": "raw" |
|
}}} |
|
ws.send(json.dumps(d)) |
|
# 最后一帧处理 |
|
elif status == STATUS_LAST_FRAME: |
|
d = {"header": {"status": 2, |
|
"app_id": wsParam.APPID |
|
}, |
|
"parameter": { |
|
"iat": wsParam.iat_params |
|
}, |
|
"payload": { |
|
"audio": |
|
{ |
|
"audio": audio, "sample_rate": 16000, "encoding": "raw" |
|
}}} |
|
ws.send(json.dumps(d)) |
|
break |
|
# 模拟音频采样间隔 |
|
time.sleep(intervel) |
|
thread.start_new_thread(run, ()) |
|
if __name__ == "__main__": |
|
# 测试时候在此处正确填写相关信息即可运行 |
|
wsParam = Ws_Param(APPID='', APISecret='', |
|
APIKey='', |
|
AudioFile=r'') |
|
websocket.enableTrace(False) |
|
wsUrl = wsParam.create_url() |
|
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close) |
|
ws.on_open = on_open |
|
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE}) |
讯飞星火语音听写流式 API 的 Python 接入流程可总结为:
- 首先准备 Python3.7 运行环境,安装代码指定版本的第三方依赖库;接着在讯飞开放平台获取 APPID、APIKey、APISecret 密钥,并准备好待识别的音频文件;
- 然后通过密钥完成鉴权加密,生成 WebSocket 连接 URL;
- 之后创建 WebSocket 客户端并与服务端建立连接,连接成功后将音频文件按固定帧大小分帧,以第一帧、中间帧、最后一帧的格式流式发送音频数据;
- 最后接收并解析服务端返回的识别结果,提取并输出文字内容,识别完成后自动关闭连接。
过程中可参考官方错误码排查问题,也可在平台配置热词、语种方言。
5.1.4 接口要求
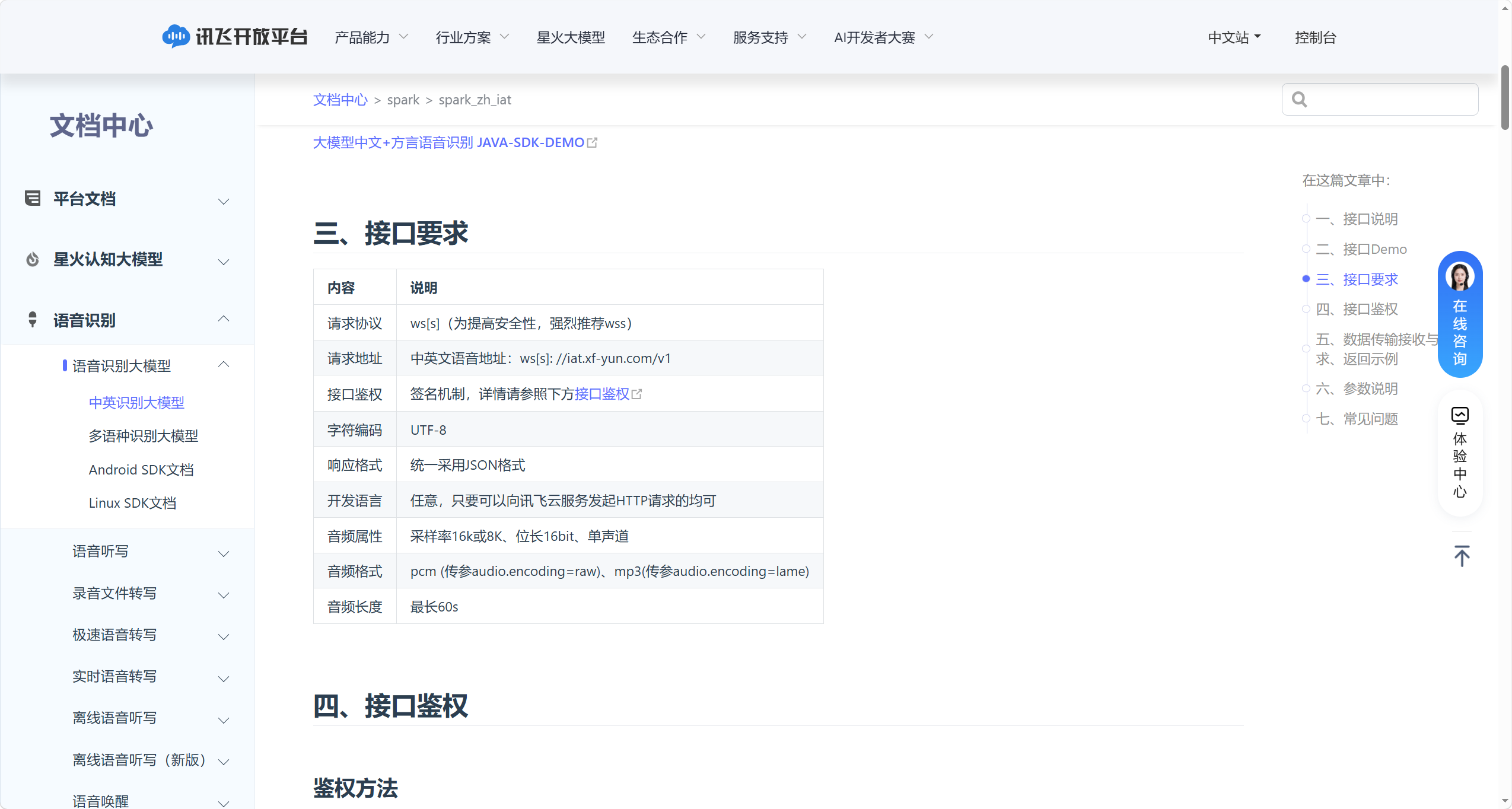
这里主要讲了 API 接口要求,包括:
- 基础协议与调用地址:
- 请求协议:支持
ws(WebSocket)/wss(加密 WebSocket),强烈推荐使用 wss 以提升安全性 - 请求地址:
ws[s]://iat.xf-yun.com/v1(中英文语音识别专属接口)
- 请求协议:支持
- 通用规范与鉴权要求:
- 接口鉴权:采用签名认证机制,需按照官方规则生成鉴权信息后才可调用
- 字符编码:统一使用
UTF-8编码 - 响应格式:服务端返回结果统一为
JSON格式 - 开发语言:无限制,只要可向讯飞云服务发起 HTTP 请求的语言均可开发
- 音频参数要求:
- 音频属性:采样率支持 16k 或 8K、位长 16bit、单声道
- 音频格式:支持
pcm(需传参audio.encoding=raw)、mp3(需传参audio.encoding=lame) - 音频长度:单段待识别音频最长不超过 60 秒
5.1.4.1 接口鉴权
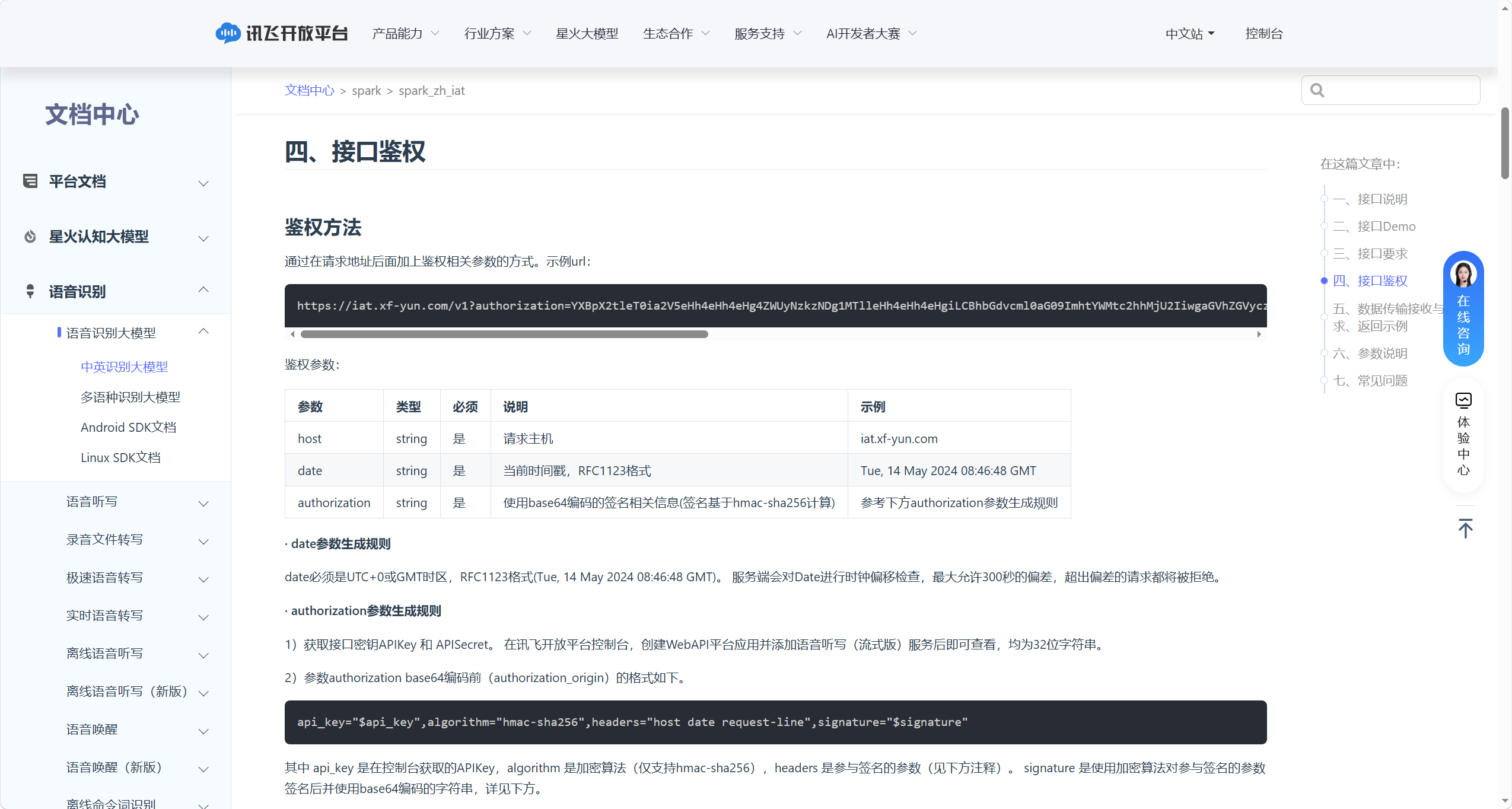
本接口采用 URL 参数鉴权 机制,是调用服务的前置安全校验:通过在 WebSocket 请求地址后拼接 3 个必填鉴权参数,完成「身份校验 + 防篡改 + 防重放」三重安全防护,仅合法授权用户可成功调用接口。
必填鉴权参数说明:

authorization 参数完整生成步骤为:
在讯飞开放平台控制台,完成以下操作获取 2 个 32 位核心密钥:
- 创建 WebAPI 平台应用
- 开通「语音听写(流式版)」服务
- 查看并保存:
APIKey(身份标识)、APISecret(签名密钥,需严格保密)
生成合规 date 参数:
- 格式要求:严格遵循 RFC1123 标准,时区必须为 UTC+0/GMT
- 校验规则:服务端会校验本地时间与服务器时间的偏差,超时请求直接拦截,需确保本地时间同步
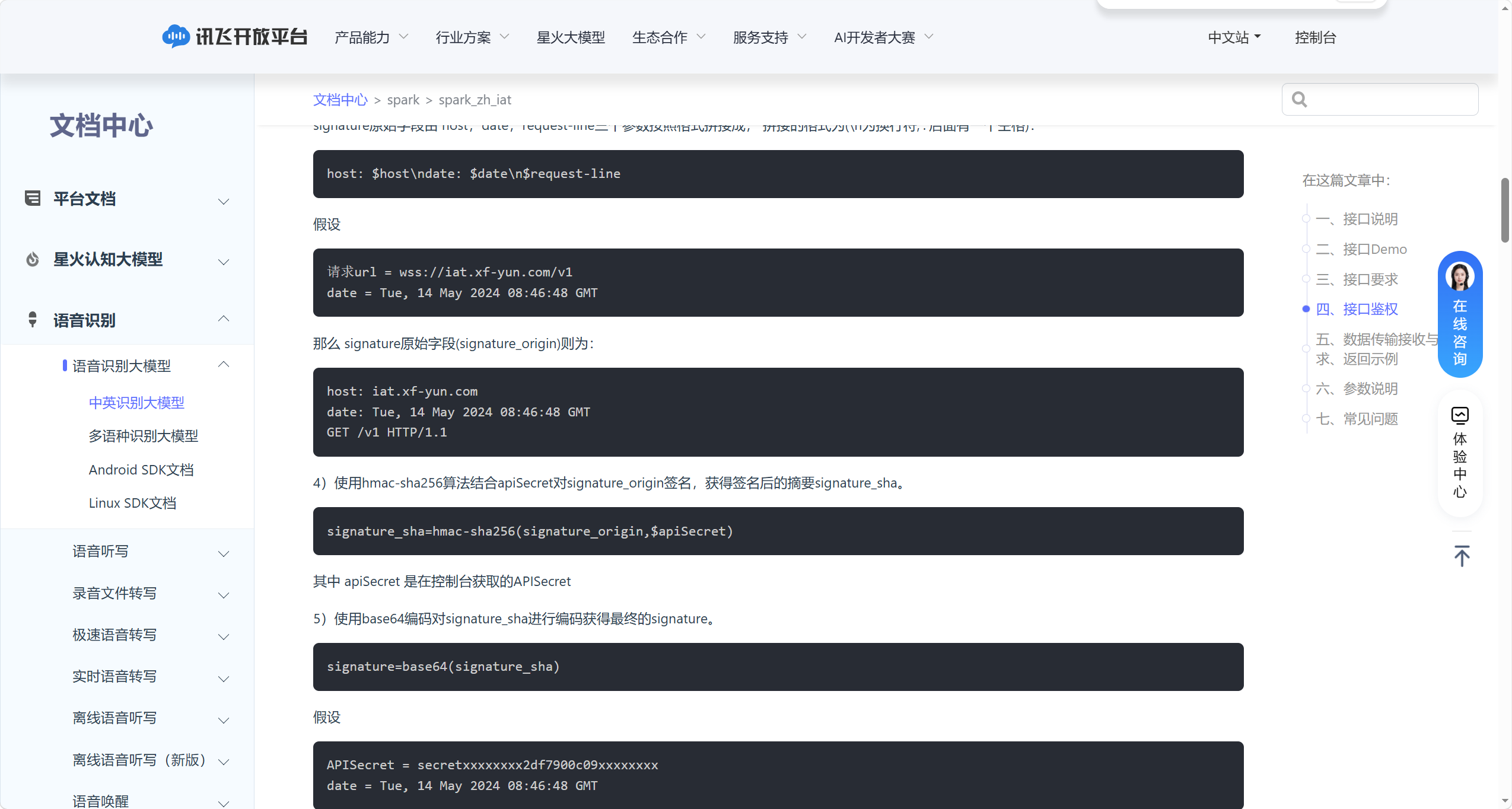
构造签名原始字段(signature_origin):按固定规则拼接 3 个参数(\n 为换行符,: 后必须保留 1 个空格):
host: $host\n |
|
date: $date\n |
|
$request-line |
字段说明:
$host:固定为iat.xf-yun.com$date:步骤 2 生成的 RFC1123 格式时间$request-line:固定为GET /v1 HTTP/1.1(对应接口请求路径)
示例:
host: iat.xf-yun.com |
|
date: Tue, 14 May 2024 08:46:48 GMT |
|
GET /v1 HTTP/1.1 |
接着,使用 hmac-sha256 加密算法,以 APISecret 为密钥,对 signature_origin 进行加密签名:
signature_sha = hmac-sha256(signature_origin, $apiSecret) |
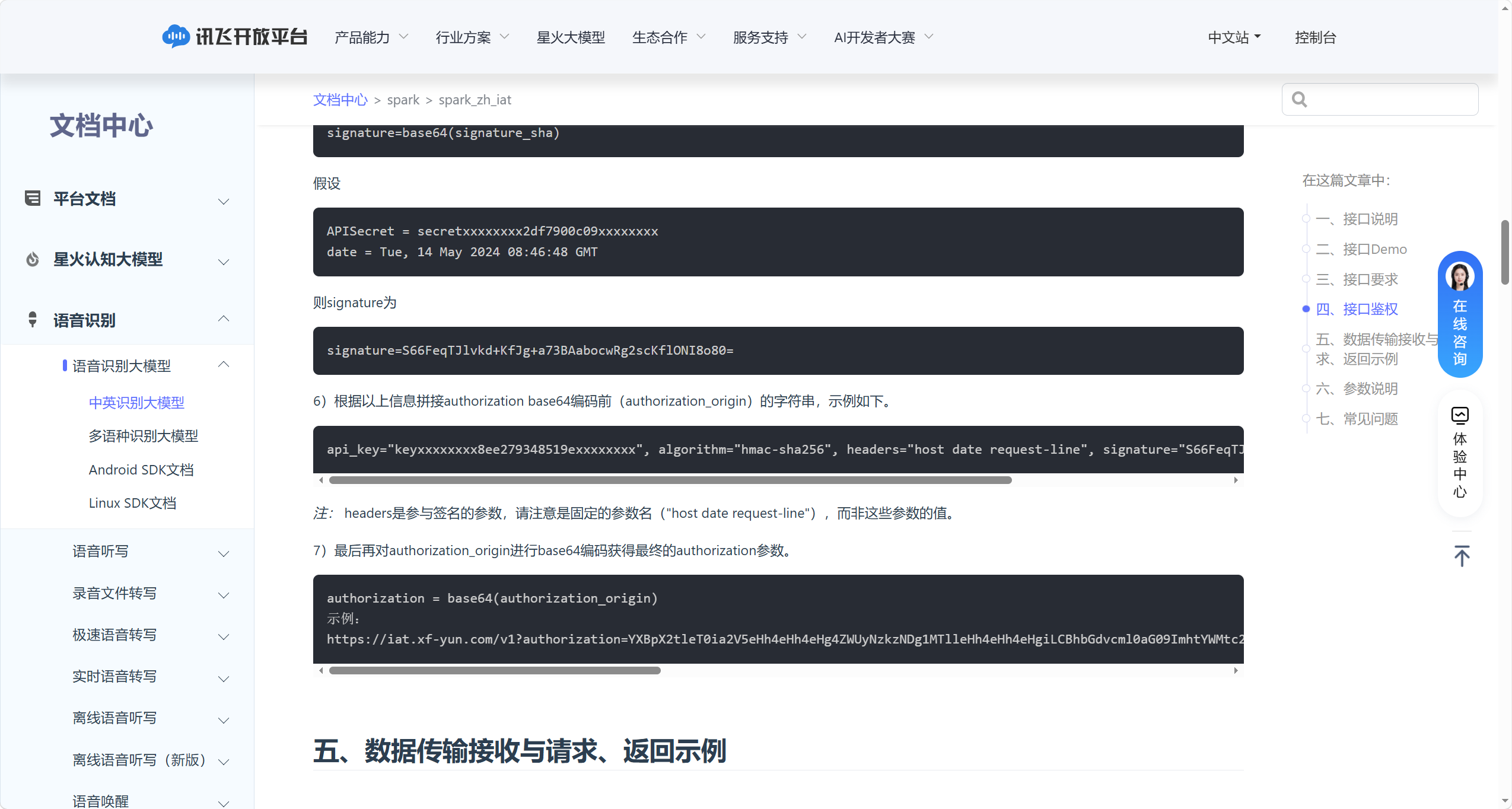
对 signature_sha 进行Base64 编码,得到可用于拼接的 signature 字符串。
按固定格式拼接(注意引号、空格不可错漏,headers 为固定参数名,不可修改):
api_key="$api_key", algorithm="hmac-sha256", headers="host date request-line", signature="$signature" |
- 关键提示:
headers的值为固定字符串"host date request-line",仅代表参与签名的参数名,不是参数实际值
对 authorization_origin 进行Base64 编码,得到最终可拼接到 URL 的 authorization 参数
最终请求格式为(推荐使用wss加密协议提升安全性):
ws[s]://iat.xf-yun.com/v1?authorization={authorization}&date={date}&host={host} |
5.1.4.2 数据传输示例
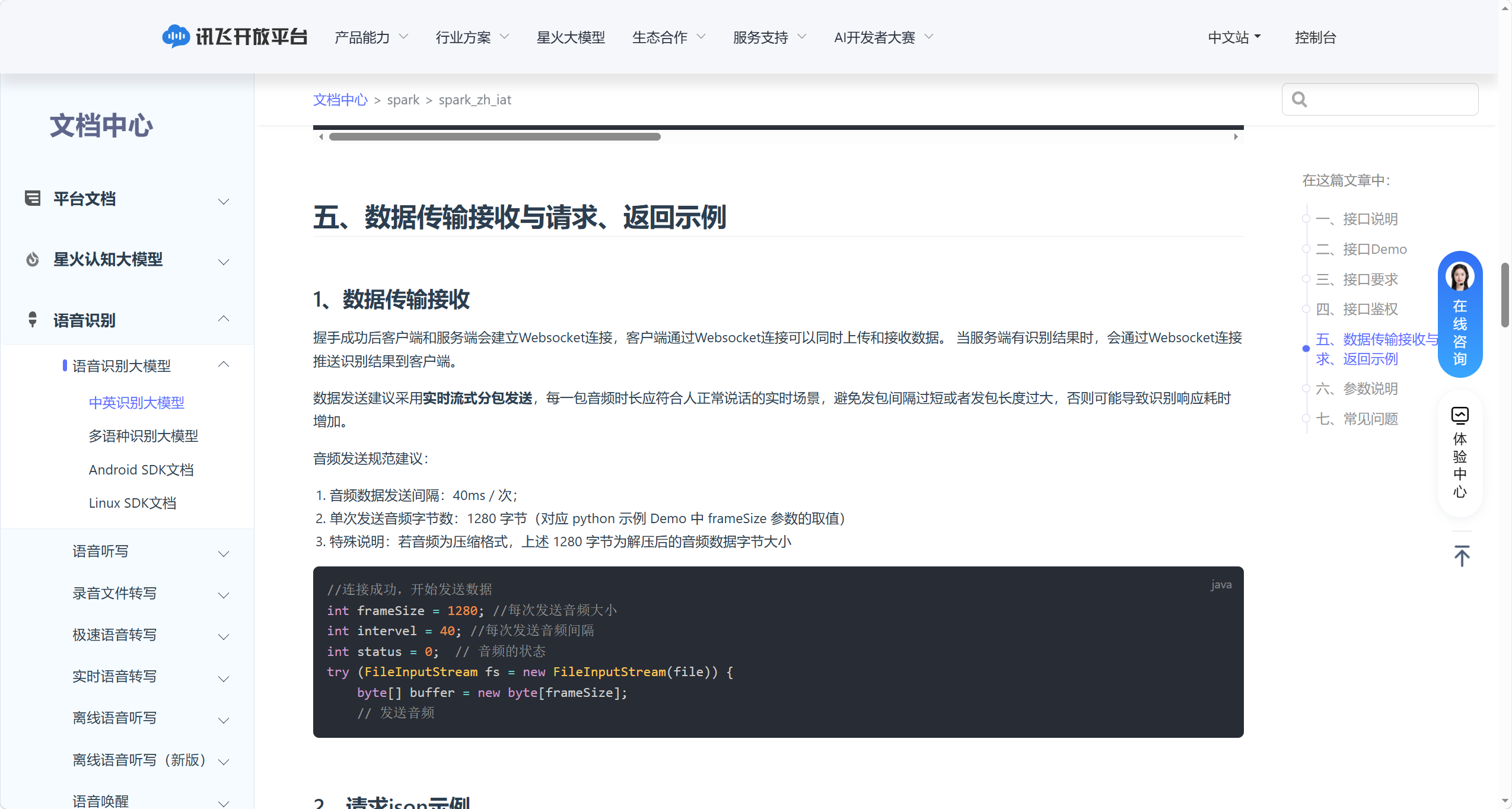
讯飞中英识别大模型采用WebSocket 全双工通信,握手成功后客户端与服务端建立长连接,支持双向数据传输:
- 上传:客户端以流式分包方式发送音频数据,服务端实时解析并识别
- 接收:服务端完成识别片段后,通过 WebSocket 主动推送识别结果到客户端
- 核心原则:符合实时语音场景,避免发包间隔过短 / 包长过大导致识别耗时增加
音频发送规范建议:

请求 JSON 示例(分帧逻辑)如下:
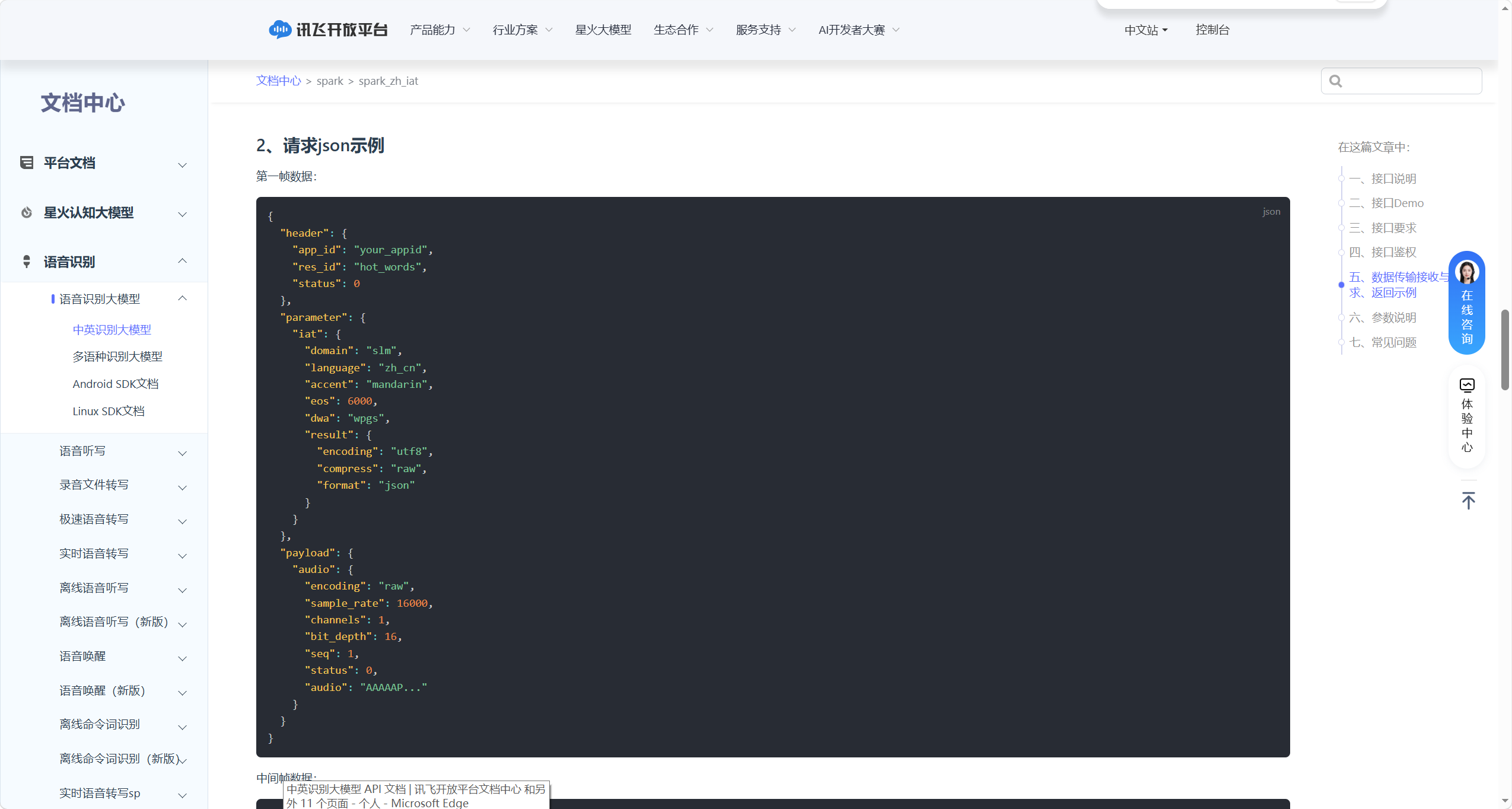
第一帧数据(status=0):
{ |
|
"header": { |
|
"app_id": "your_appid", |
|
"res_id": "hot_words", |
|
"status": 0 |
|
}, |
|
"parameter": { |
|
"iat": { |
|
"domain": "slm", |
|
"language": "zh_cn", |
|
"accent": "mandarin", |
|
"dwa": "wpgs", |
|
"result": { |
|
"encoding": "utf8", |
|
"compress": "raw", |
|
"format": "json" |
|
} |
|
} |
|
}, |
|
"payload": { |
|
"audio": { |
|
"encoding": "raw", |
|
"sample_rate": 16000, |
|
"channels": 1, |
|
"bit_depth": 16, |
|
"seq": 1, |
|
"status": 0, |
|
"audio": "AAAAAP..." // Base64编码的第一帧音频数据 |
|
} |
|
} |
|
} |
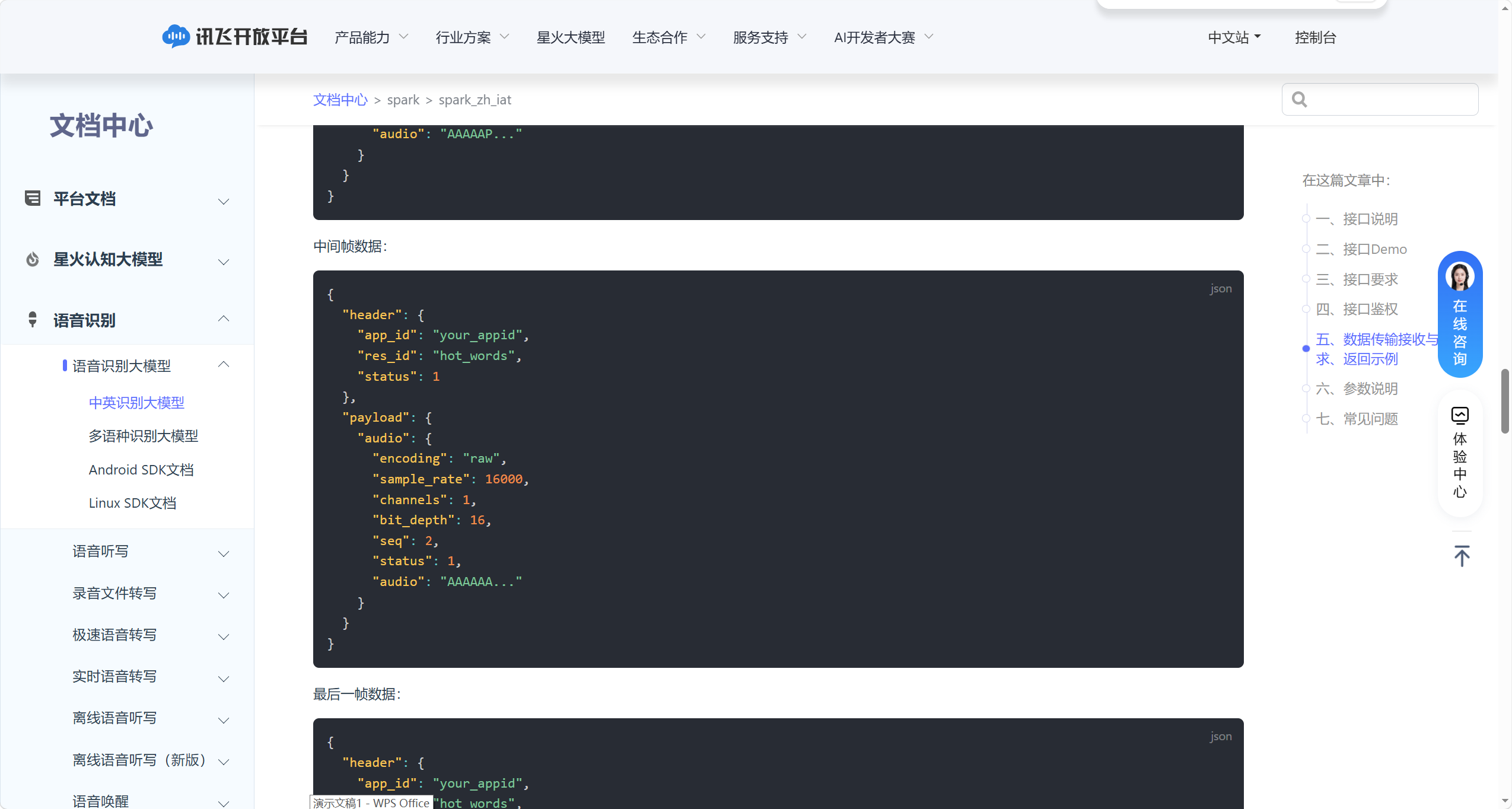
中间帧数据(status=1):
{ |
|
"header": { |
|
"app_id": "your_appid", |
|
"res_id": "hot_words", |
|
"status": 1 |
|
}, |
|
"parameter": { |
|
"iat": {...} // 与第一帧参数一致 |
|
}, |
|
"payload": { |
|
"audio": { |
|
"encoding": "raw", |
|
"sample_rate": 16000, |
|
"channels": 1, |
|
"bit_depth": 16, |
|
"seq": 2, // 帧序号递增 |
|
"status": 1, |
|
"audio": "AAAAAA..." // Base64编码的中间帧音频数据 |
|
} |
|
} |
|
} |
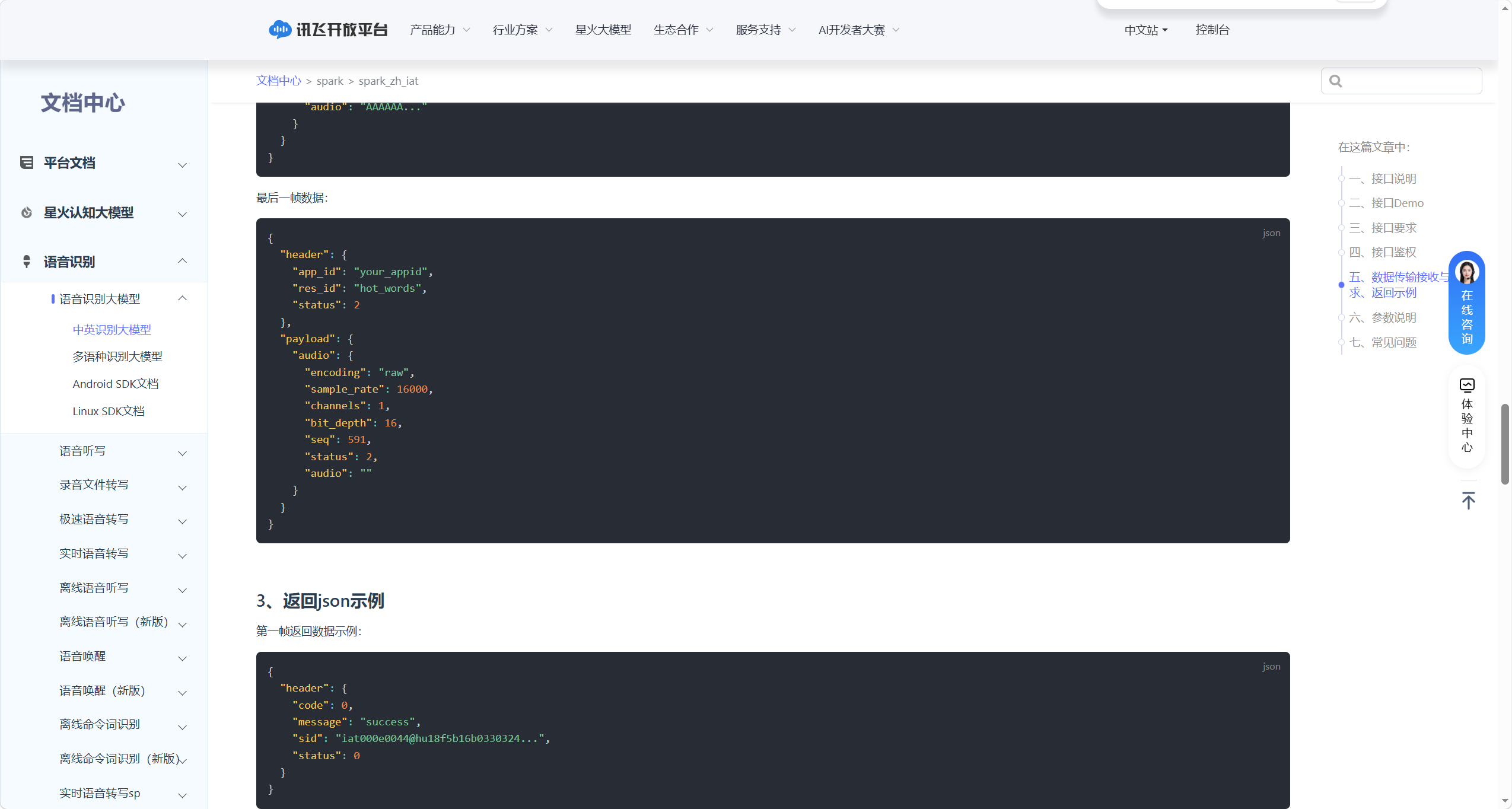
最后一帧数据:
{ |
|
"header": { |
|
"app_id": "your_appid", |
|
"res_id": "hot_words", |
|
"status": 2 |
|
}, |
|
"parameter": { |
|
"iat": {...} // 与第一帧参数一致 |
|
}, |
|
"payload": { |
|
"audio": { |
|
"encoding": "raw", |
|
"sample_rate": 16000, |
|
"channels": 1, |
|
"bit_depth": 16, |
|
"seq": 531, // 最后一帧序号 |
|
"status": 2, |
|
"audio": "" // 最后一帧可无音频数据 |
|
} |
|
} |
|
} |
请求核心参数说明:

返回 JSON 示例(流式识别结果):
第一帧返回(status=0):
{ |
|
"header": { |
|
"code": 0, |
|
"message": "success", |
|
"sid": "iat00e0044@hu18f5b16b033032...", |
|
"status": 0 |
|
} |
|
} |
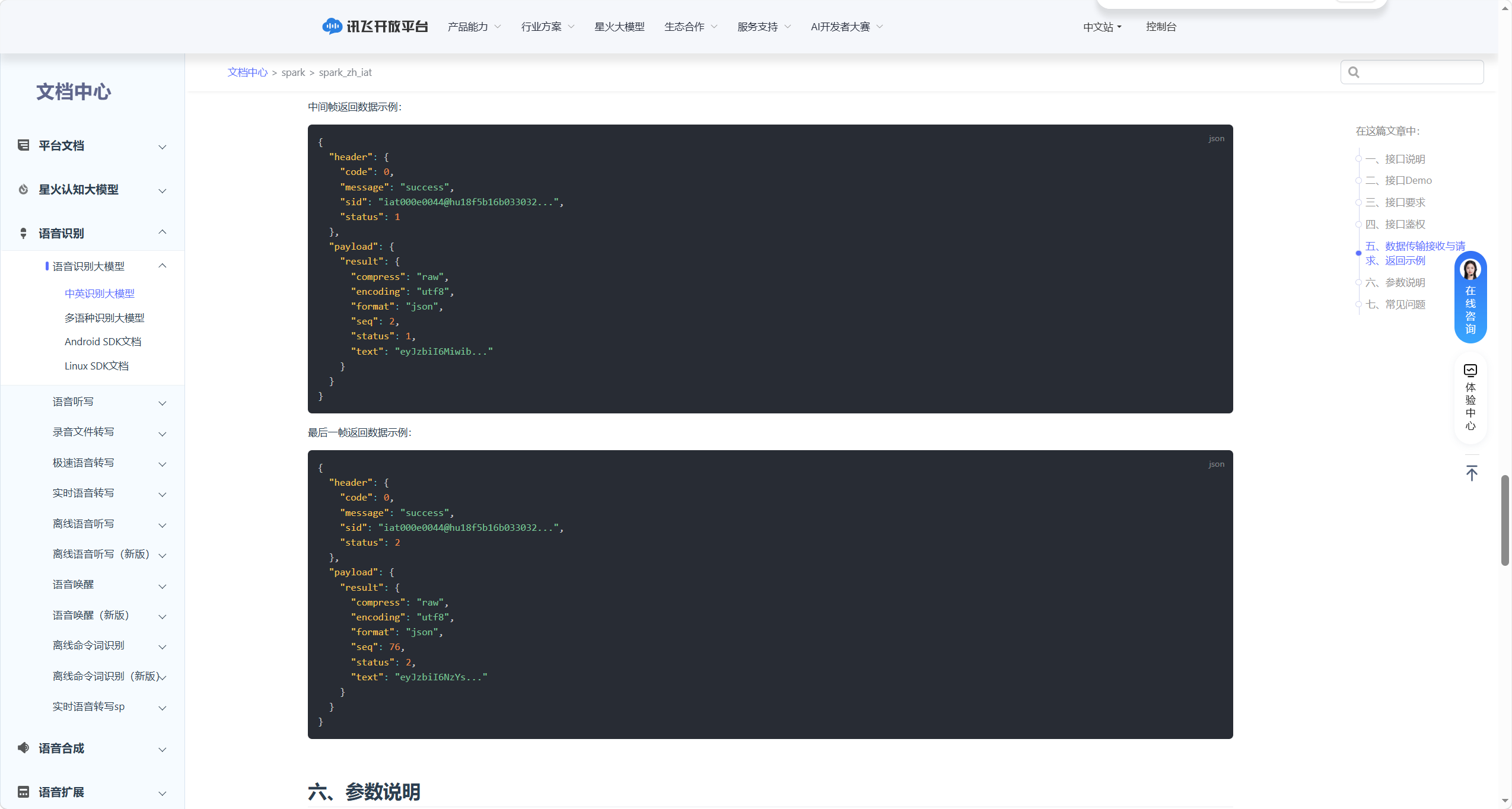
中间帧返回(status=1):
{ |
|
"header": { |
|
"code": 0, |
|
"message": "success", |
|
"sid": "iat00e0044@hu18f5b16b033032...", |
|
"status": 1 |
|
}, |
|
"payload": { |
|
"result": { |
|
"compress": "raw", |
|
"encoding": "utf8", |
|
"format": "json", |
|
"seq": 2, // 对应请求帧序号 |
|
"status": 1, |
|
"text": "cy12b1j6l9x1b..." // Base64编码的识别片段文本 |
|
} |
|
} |
|
} |
最后一帧返回(status=2):
{ |
|
"header": { |
|
"code": 0, |
|
"message": "success", |
|
"sid": "iat00e0044@hu18f5b16b033032...", |
|
"status": 2 |
|
}, |
|
"payload": { |
|
"result": { |
|
"compress": "raw", |
|
"encoding": "utf8", |
|
"format": "json", |
|
"seq": 76, // 最后一帧序号 |
|
"status": 2, |
|
"text": "cy12b1j6l9x1bN2y..." // Base64编码的最终识别文本 |
|
} |
|
} |
|
} |
简单来说,就是:
- 结果解析:返回结果中
payload.result.text为 Base64 编码的文本,需先解码再解析 JSON,提取最终文字 - 状态关联:返回的
header.status与请求帧status对应,标识当前识别阶段 - 错误处理:
header.code=0表示成功,非 0 为错误(需参考官方错误码排查) - 流式拼接:中间帧返回的
text为识别片段,需按seq顺序拼接,最后一帧为完整结果
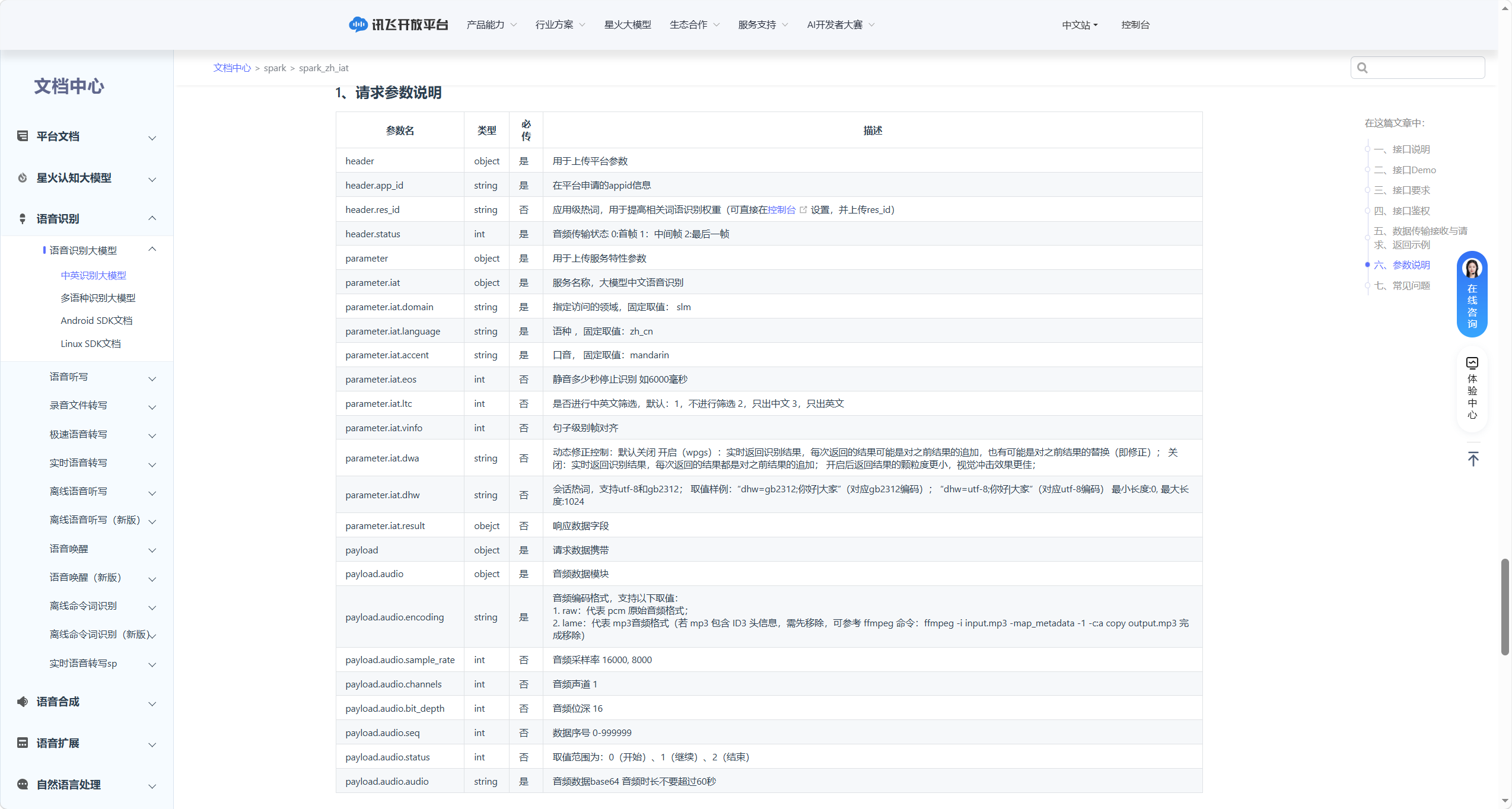
5.1.4.3 请求入参与返回出参说明

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)