解决方案十七-企业级大模型版本实时语音转文字
在人工智能技术飞速发展的今天,语音识别已经成为人机交互的重要入口。从智能音箱到会议转写,从语音输入到实时翻译,语音识别技术正在深刻改变我们的工作和生活方式。本文将分享一个基于讯飞AST(Automatic Speech Transcription)服务的实时语音识别前端系统开发实践,涵盖WebSocket通信、音频采集、参数配置、结果解析等核心技术要点。
一、项目背景与技术选型
1.1 为什么选择AST服务
AST(Automatic Speech Transcription)是讯飞开放平台提供的实时语音转写服务,支持多种语言和方言的识别,具备以下核心优势:
-
实时性:基于WebSocket全双工通信,支持边录边识别
-
多语种支持:覆盖中英、日韩、俄法、阿拉伯等数十种语言
-
领域个性化:提供法律、金融、医疗等16个垂直领域模型
-
角色分离:支持多人对话场景下的说话人区分
-
方言识别:支持202种中国方言的识别
1.2 技术栈选型
本项目采用Vue.js框架开发,主要技术栈包括:
-
前端框架:Vue 2.x + Element UI
-
音频处理:Recorder.js(录音库)
-
加密算法:CryptoJS(HMAC-SHA1签名)
-
通信协议:WebSocket(RFC 6455)
-
数据格式:JSON + Base64编码
二、系统架构设计
2.1 整体架构
系统采用典型的三层架构设计:
text
┌─────────────────────────────────────────────────────┐
│ 用户界面层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 参数设置 │ │ JSON展示 │ │ 文本展示 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────┐
│ 业务逻辑层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 参数管理 │ │ 签名生成 │ │ 消息解析 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────┐
│ 通信层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 音频采集 │ │ WebSocket │ │ 录音管理 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────┘
2.2 数据流设计
整个系统的数据流如下:
-
用户配置参数 → 生成签名 → 建立WebSocket连接
-
开始录音 → 音频数据采集 → 帧数据发送
-
服务端识别 → 结果返回 → JSON解析 → 文本展示
-
结束识别 → 发送结束标识 → 关闭连接
三、核心功能实现
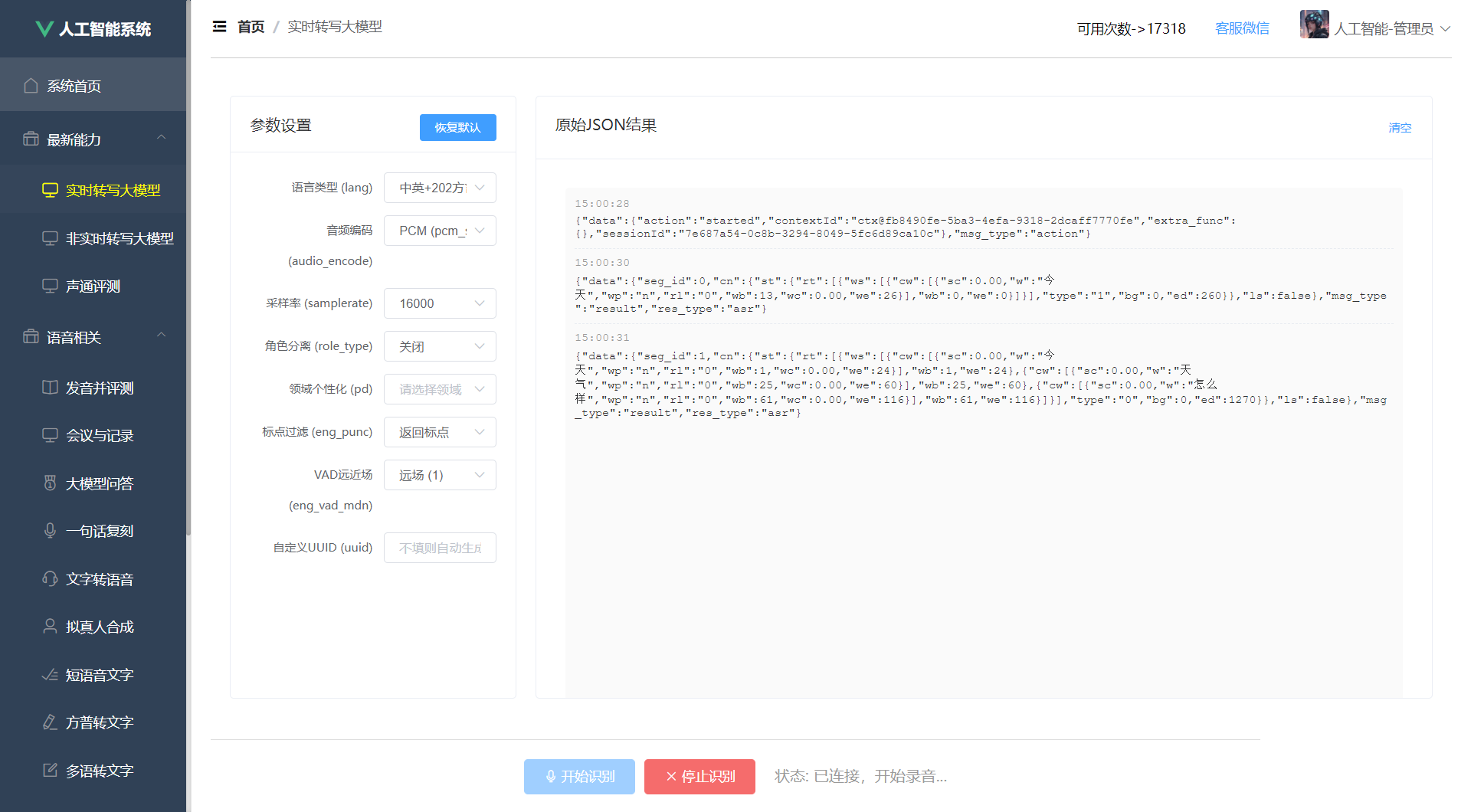
3.1 参数配置模块
参数配置是语音识别的关键环节,不同场景需要不同的参数组合。
javascript
// 核心参数配置
params: {
lang: 'autodialect', // 语言类型:autodialect(方言) / autominor(多语种)
recognized_language: [], // 目标语种列表(多语种模式)
audio_encode: 'pcm_s16le', // 音频编码格式
samplerate: '16000', // 采样率:16000 / 8000
role_type: 0, // 角色分离:0关闭 / 2盲分
feature_ids: '', // 声纹ID列表
eng_spk_match: 0, // 严格声纹匹配
pd: '', // 领域个性化
eng_punc: 1, // 标点输出:1开启 / 0关闭
eng_vad_mdn: 1, // VAD远近场:1远场 / 2近场
uuid: '' // 自定义会话ID
}
参数说明:
-
语言类型:
autodialect支持202种方言识别,autominor支持多语种混合识别 -
音频编码:PCM为无损格式,Speex和Opus为压缩格式,后者更适合网络传输
-
角色分离:通过声纹识别技术区分不同说话人,适合会议、访谈等场景
-
领域个性化:选择特定领域可显著提升识别准确率
-
VAD远近场:根据麦克风距离选择,近场适合手机等设备,远场适合会议系统
3.2 WebSocket连接与签名生成
讯飞AST服务要求每次请求必须携带签名,采用HMAC-SHA1算法。
javascript
generateSignature(params, accessKeySecret) {
// 1. 参数排序
const sortedKeys = Object.keys(params).sort()
const baseStringParts = []
// 2. 构建待签名字符串
for (const key of sortedKeys) {
const encodedKey = encodeURIComponent(key)
const encodedValue = encodeURIComponent(params[key])
baseStringParts.push(`${encodedKey}=${encodedValue}`)
}
const baseString = baseStringParts.join('&')
// 3. HMAC-SHA1加密
const signatureSha = CryptoJS.HmacSHA1(baseString, accessKeySecret)
const signature = CryptoJS.enc.Base64.stringify(signatureSha)
return signature
}
签名流程详解:
-
参数准备:包含appId、accessKeyId、uuid、utc等必要参数
-
参数排序:按字典序排列所有参数
-
URL编码:对每个参数的key和value进行百分号编码
-
拼接字符串:使用
&连接所有key=value对 -
HMAC加密:使用AccessKeySecret作为密钥
-
Base64编码:得到最终签名
关键点: UTC时间戳格式必须为YYYY-MM-DDTHH:mm:ss+0800,服务端会校验时间有效性。
3.3 WebSocket连接建立
javascript
async wsInit() {
const host = 'office-api-ast-dx.iflyaisol.com'
const path = '/ast/communicate/v1'
const wsUrl = `wss://${host}${path}?${urlParams.toString()}`
wsTask = new WebSocket(wsUrl)
wsTask.onopen = function() {
// 连接成功,开始录音
recorder.start({
sampleRate: parseInt(this.params.samplerate),
frameSize: 1280, // 每帧数据大小
})
}
wsTask.onmessage = function(event) {
// 处理识别结果
this.handleMessage(event.data)
}
wsTask.onerror = function(error) {
// 错误处理
}
wsTask.onclose = function() {
// 连接关闭
}
}
连接参数详解:
| 参数 | 说明 | 示例 |
|---|---|---|
| appId | 应用ID | xxx |
| accessKeyId | 访问密钥ID | xxx |
| uuid | 会话唯一标识 | 自动生成或用户指定 |
| utc | UTC时间戳 | 2026-07-01T14:30:00+0800 |
| signature | HMAC-SHA1签名 | 动态计算 |
3.4 音频采集与发送
音频采集使用Recorder库,通过MediaRecorder API获取麦克风数据。
javascript
// 初始化录音器
let recorder = new Recorder("../../recorder")
// 帧数据回调
recorder.onFrameRecorded = ({isLastFrame, frameBuffer}) => {
if (!isLastFrame && wsFlag) {
// 发送音频数据(Int8Array格式)
wsTask.send(new Int8Array(frameBuffer))
} else if (isLastFrame && wsFlag) {
// 发送结束标识
const endMsg = {
end: true,
sessionId: sessionId
}
wsTask.send(JSON.stringify(endMsg))
}
}
音频数据格式要求:
-
采样率:8000Hz或16000Hz
-
编码格式:PCM 16bit小端序
-
帧大小:建议1280字节/帧
-
数据格式:Int8Array(有符号8位整数数组)
发送策略:
-
每采集一帧立即发送,保证实时性
-
录音结束时发送
{end: true}标识 -
发送前检查WebSocket连接状态
3.5 结果解析与展示
AST服务返回的数据包含丰富的识别信息:
javascript
handleMessage(message) {
const jsonData = JSON.parse(message)
// 识别结果
if (jsonData.msg_type === 'result' && jsonData.res_type === 'asr') {
const data = jsonData.data
// 识别完成标识
if (data.ls === true) {
this.isFinal = true
this.statusText = '识别完成'
// 保存最终结果
const finalText = this.resultTextTemp || this.resultText
const segments = this.parseRoleSegments(finalText)
this.addTextHistory(finalText, segments)
return
}
// 解析文本片段
if (data.cn && data.cn.st) {
const st = data.cn.st
const rt = st.rt || []
let segmentText = ''
let role = null
for (const item of rt) {
const ws = item.ws || []
for (const w of ws) {
const cw = w.cw || []
for (const word of cw) {
if (word.w) {
segmentText += word.w
}
if (word.rl !== undefined && word.rl > 0) {
role = '角色' + word.rl
}
}
}
}
// 区分临时结果和最终结果
if (st.type === '1') {
this.resultTextTemp = segmentText // 临时结果
} else {
this.resultText = segmentText // 最终结果
}
}
}
}
返回数据结构:
json
{
"msg_type": "result",
"res_type": "asr",
"data": {
"ls": false,
"cn": {
"st": {
"type": "0", // 0最终 / 1临时
"rt": [
{
"ws": [
{
"cw": [
{
"w": "今天",
"rl": 1 // 角色标识
}
]
}
]
}
]
}
}
}
}
字段说明:
| 字段 | 说明 |
|---|---|
| ls | 是否为最终结果,true表示识别完成 |
| st.type | 结果类型:0最终 / 1临时 |
| ws | 词序列 |
| cw | 候选词 |
| w | 识别的文字 |
| rl | 角色标签(需开启角色分离) |
3.6 角色分离解析
当开启角色分离功能后,需要解析每个词的角色标签:
javascript
parseRoleSegments(text) {
if (!text) return []
const segments = []
const sentences = text.split(/[。!?\n]/).filter(s => s.trim())
if (this.params.role_type === 2) {
// 盲分模式:按句子交替分配角色
sentences.forEach((s, index) => {
segments.push({
role: '角色' + (index % 2 + 1),
text: s.trim()
})
})
} else {
// 无角色分离
if (sentences.length) {
segments.push({
role: '发言',
text: sentences.join('。')
})
}
}
return segments
}
角色分离实现原理:
-
服务端通过声纹特征区分不同说话人
-
每个词携带
rl字段标识说话人ID -
前端按句子聚合,展示不同角色的发言内容
-
支持盲分(自动聚类)和声纹匹配(指定说话人)两种模式
四、关键问题与解决方案
4.1 音频数据格式转换
问题: 录音库输出的是Float32Array,但服务端要求Int8Array格式。
解决: 在发送前进行数据转换:
javascript
// Float32Array转Int8Array
const int8Array = new Int8Array(float32Array.length)
for (let i = 0; i < float32Array.length; i++) {
// 将浮点数映射到-128~127范围
int8Array[i] = Math.max(-128, Math.min(127, Math.round(float32Array[i] * 128)))
}
4.2 WebSocket重连机制
问题: 网络不稳定可能导致WebSocket断开。
解决: 实现自动重连机制:
javascript
reconnect() {
if (this.reconnectCount > 3) {
this.$message.error('重连失败,请检查网络')
return
}
this.reconnectCount++
setTimeout(() => {
this.wsInit()
}, 1000 * this.reconnectCount)
}
4.3 内存泄漏防护
问题: 频繁的音频数据发送可能导致内存泄漏。
解决: 组件销毁时清理资源:
javascript
beforeDestroy() {
// 关闭WebSocket
if (wsTask) {
wsTask.close()
wsTask = null
}
// 停止录音
if (recorder) {
recorder.stop()
}
// 清除定时器
if (this.timer) {
clearInterval(this.timer)
}
}
五、性能优化实践
5.1 数据压缩传输
对于低带宽场景,建议使用Speex或Opus编码:
javascript
audio_encode: 'speex-7' // Speex压缩级别7 audio_encode: 'opus-wb' // Opus宽带编码
不同编码格式对比:
| 编码格式 | 比特率 | 延迟 | 音质 |
|---|---|---|---|
| PCM | 256kbps | 最低 | 无损 |
| Speex-7 | 24kbps | 低 | 良好 |
| Opus-WB | 32kbps | 低 | 优秀 |
5.2 虚拟滚动优化
当识别结果累积较多时,使用虚拟滚动减少DOM渲染压力:
javascript
// 使用vue-virtual-scroller组件
<RecycleScroller
:items="textHistory"
:item-size="80"
key-field="time"
>
<template #default="{ item }">
<div class="history-item">
<div class="history-time">{{ item.time }}</div>
<div>{{ item.content }}</div>
</div>
</template>
</RecycleScroller>
5.3 结果缓存策略
避免重复解析相同的识别结果:
javascript
// 使用Map缓存已解析的结果
const resultCache = new Map()
function parseResult(message) {
const hash = calculateHash(message)
if (resultCache.has(hash)) {
return resultCache.get(hash)
}
const result = doParse(message)
resultCache.set(hash, result)
return result
}
六、最佳实践与注意事项
6.1 参数配置建议
根据不同场景推荐参数组合:
会议转写场景:
javascript
{
lang: 'autodialect',
role_type: 2, // 开启角色分离
pd: 'com', // 企业领域
eng_vad_mdn: 2, // 近场
eng_punc: 1 // 返回标点
}
多语言翻译场景:
javascript
{
lang: 'autominor',
recognized_language: ['en', 'ja', 'ko'], // 目标语种
audio_encode: 'opus-wb', // 压缩传输
pd: 'tech' // 科技领域
}
6.2 错误处理规范
全面的错误处理至关重要:
javascript
try {
await this.wsInit()
} catch (error) {
// 错误分类处理
if (error.message.includes('timeout')) {
this.$message.error('连接超时,请检查网络')
} else if (error.message.includes('signature')) {
this.$message.error('签名验证失败,请检查密钥')
} else {
this.$message.error('连接失败: ' + error.message)
}
}
6.3 用户体验优化
-
状态反馈:实时显示连接状态、录音状态、识别状态
-
渐进式展示:临时结果实时显示,最终结果覆盖更新
-
滚动跟随:自动滚动到最新结果
-
错误提示:友好的错误提示信息
七、总结与展望
本文详细介绍了基于讯飞AST服务的实时语音识别前端系统开发实践,涵盖了参数配置、WebSocket通信、音频采集、结果解析等核心功能。通过合理的技术选型和优化策略,实现了一个功能完善、性能优良的语音识别应用。
未来优化方向
-
AI智能断句:结合NLP技术实现更智能的句子分割
-
情感分析:识别说话人的情绪状态
-
实时翻译:集成机器翻译API,实现同声传译
-
语音合成:将识别结果合成为语音播报
-
离线支持:实现部分功能的离线化
语音识别技术仍在快速发展,未来的应用场景将更加丰富。希望本文能为相关开发者提供有价值的参考,共同推动语音交互技术的发展。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)