FastAPI+FunASR实现局域网WebSocket实时语音识别 | 解决麦克风权限、10054连接重置、PyAudio硬件报错全记录
目录
-
- 1. 项目背景与整体架构
- 2. 环境依赖安装
- FunASR官方文档
- 3. 完整前后端源码
- 4. 启动运行方式
- 5. 部署踩坑全记录(核心章节)
- 6. 功能扩展:语音识别对接大模型问答
- 7. 总结
1. 项目背景与整体架构
项目需求
搭建局域网实时流式语音字幕服务。最初方案后端通过PyAudio调用本机麦克风录音,但是部署到无声卡、无音频硬件的台式机时频繁报错。
最终改造方案:把麦克风采集迁移到浏览器前端,后端只通过WebSocket接收二进制音频流,不再依赖任何声卡硬件。
整体技术链路
- 前端网页:浏览器调用麦克风,生成 16000Hz 单声道16位PCM音频;
- WebSocket长连接:二进制音频上行,识别文字实时下发;
- 后端服务:FunASR paraformer流式模型做语音识别;
- 增强逻辑:静音停顿0.6秒自动清空字幕,并重置模型缓存,避免上下文串话。
2. 环境依赖安装
pip install funasr
FunASR官方文档
注意: 如果只是跑语音识别,建议降到 Python3.9 ~ Python3.12,funasr 兼容性最好
使用Python3.13 就会报下面这个错误:
使用 pip install funasr 安装时报错:
File "C:\Users\Administrator\AppData\Local\Temp\pip-build-env-fr3svpmz\overlay\Lib\site-packages\pdm\backend\hooks\setuptools.py", line 92, in _build_lib
raise BuildError(f"Error occurs when running {build_args}:\n{e}")
pdm.backend.exceptions.BuildError: Error occurs when running ['C:\\Python313\\python.exe', 'C:\\Users\\Administrator\\AppData\\Local\\Temp\\pip-install-ozs44hc3\\editdistance_ecb96c8585a54a4485377adc1e68862b\\setup.py', 'build', '-b', 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\pdm-build-7bg3n_hl']:
Command '['C:\\Python313\\python.exe', 'C:\\Users\\Administrator\\AppData\\Local\\Temp\\pip-install-ozs44hc3\\editdistance_ecb96c8585a54a4485377adc1e68862b\\setup.py', 'build', '-b', 'C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\pdm-build-7bg3n_hl']' returned non-zero exit status 1.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for editdistance
Failed to build editdistance
error: failed-wheel-build-for-install
× Failed to build installable wheels for some pyproject.toml based projects
╰─> editdistance
3. 完整前后端源码
后端 asr_api.py
# -*- coding: utf-8 -*-
"""
@Created on : 2026/6/25 16:12
@creator : er_nao
@File :asr_api.py
@Description :
"""
from fastapi import FastAPI, HTTPException, WebSocket
from fastapi.staticfiles import StaticFiles
from fastapi.responses import FileResponse
from pydantic import BaseModel
from funasr import AutoModel
import pyaudio
import asyncio
import threading
import os
import sys
import time
# 屏蔽进度条
os.environ["TQDM_DISABLE"] = "1"
devnull = open(os.devnull, 'w')
sys.stdout = devnull
sys.stderr = devnull
app = FastAPI()
# 挂载当前目录为静态资源目录
app.mount("/static", StaticFiles(directory="."), name="static")
# 访问根路径自动打开 index.html
@app.get("/")
async def index():
return FileResponse("index.html")
# ---------------------- 加载模型 ----------------------
# 音频url转文字模型
model = AutoModel(model='paraformer-zh', vad_model='fsmn-vad', punc_model='ct-punc')
# 加载实时流式模型
asr_model = AutoModel(
model="paraformer-zh-streaming",
disable_update=True
)
CHUNK = 960
RATE = 16000
chunk_size = [0, 10, 5]
# 消息队列 + 客户端连接池
# text_queue = asyncio.Queue()
# client_set = set()
# main_loop: asyncio.AbstractEventLoop = None
# 定义请求体格式:只接收音频url
class AudioUrlRequest(BaseModel):
audio_url: str
"""
音频链接转文字
"""
@app.post("/asr")
async def speech_to_text(req: AudioUrlRequest):
try:
# 直接把网络地址传给model.generate
res = model.generate(input=req.audio_url)
return {
"code": 200,
"text": res[0]["text"]
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
"""
实时语音转文字,WebSocket接口
"""
@app.websocket("/ws")
async def handle_audio_stream(websocket: WebSocket):
await websocket.accept()
print("客户端已连接")
cache = {}
sentence_buffer = ""
last_voice_time = time.time()
silence_timeout = 1
try:
while True:
try:
pcm_data = await websocket.receive_bytes()
print(f"收到音频字节:{len(pcm_data)}") # 打印收到的数据长度
except Exception:
print("连接断开")
break
now = time.time()
res = asr_model.generate(
input=pcm_data,
cache=cache,
is_final=False,
chunk_size=[0,10,5]
)
print("识别结果:", res) # 打印模型输出
if res and res[0]["text"].strip():
text = res[0]["text"].strip()
sentence_buffer += text
last_voice_time = now
await websocket.send_text(sentence_buffer)
if sentence_buffer and (now - last_voice_time > silence_timeout):
sentence_buffer = ""
cache.clear()
try:
await websocket.send_text("")
except:
pass
finally:
cache.clear()
if __name__ == "__main__":
import uvicorn
# 开启https,局域网IP直接变成安全网站
uvicorn.run(
"asr_api:app",
host="0.0.0.0",
port=8088,
ssl_keyfile="./key.pem",
ssl_certfile="./cert.pem"
)
前端 index.html(自动适配 http/ws、https/wss)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>实时字幕</title>
</head>
<body>
<div style="font-size:48px;padding:20px;" id="subtitle"></div>
<script>
const ws = new WebSocket(`wss://${location.host}/ws`);
const subtitleDom = document.getElementById("subtitle");
ws.onmessage = e => {
subtitleDom.innerText = e.data;
};
async function startRecord() {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: { sampleRate: 16000, channelCount: 1 }
});
const ctx = new AudioContext({ sampleRate: 16000 });
const src = ctx.createMediaStreamSource(stream);
const processor = ctx.createScriptProcessor(1024, 1, 1);
src.connect(processor);
processor.connect(ctx.destination);
processor.onaudioprocess = evt => {
const input = evt.inputBuffer.getChannelData(0);
const buffer = new Int16Array(input.length);
for (let i = 0; i < input.length; i++) {
let s = Math.max(-1, Math.min(1, input[i]));
buffer[i] = s < 0 ? s * 0x8000 : s * 0x7FFF;
}
if (ws.readyState === WebSocket.OPEN) {
ws.send(buffer.buffer);
}
};
} catch (err) {
console.error("麦克风权限失败:", err);
}
}
startRecord();
</script>
</body>
</html>
4. 启动运行方式
把两个文件放在同一文件夹,打开PowerShell执行命令:
uvicorn asr_api:app --host 0.0.0.0 --port 8088
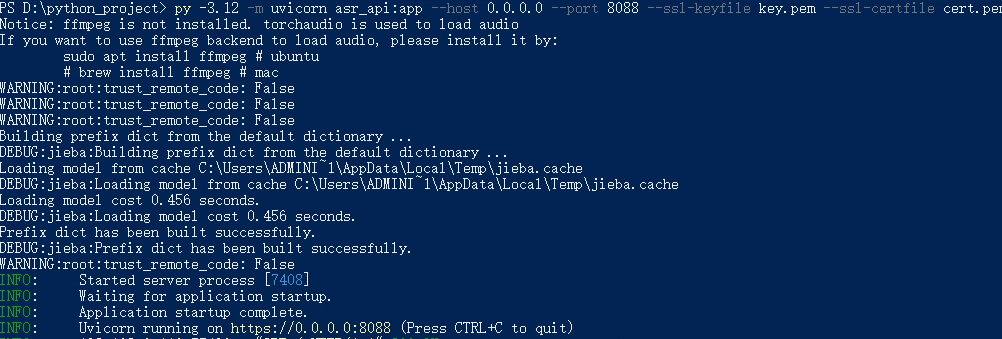
局域网访问方案(推荐首选)
- 查询服务端本机局域网IP:
ipconfig - 配置Windows hosts实现内网安全域名,解决麦克风权限拦截,下文详细说明。
5. 部署踩坑全记录(核心章节)
问题1:PyAudio OSError: [Errno -9999] Unanticipated host error
报错原因
后端使用PyAudio读取本机麦克风,服务器无声卡、无音频输入设备,直接打开流失败。
最终解决方案
彻底删除PyAudio录音代码,改为前端浏览器采集音频,后端只接收网络二进制流。
后端不再依赖任何音频硬件,彻底根除该异常。
问题2:WebSocket连接成功,浏览器不弹出麦克风授权,完全无法收音
根本原因
浏览器安全策略:http://192.168.x.x 内网IP属于非安全上下文,Chrome直接禁用麦克风API,不会弹出授权窗口。
方案A(局域网最优,零证书、零配置,强烈推荐)
使用.local内网域名绕过安全限制:
- 用管理员权限打开记事本,编辑hosts文件:
C:\Windows\System32\drivers\etc\hosts - 在文件末尾添加一行:
192.168.0.110 asr.local
- 浏览器访问地址:
http://asr.local:8088
浏览器自动把.local域名判定为内网安全域,HTTP环境下正常弹出麦克风权限。
方案B:mkcert生成自签名HTTPS证书
- 下载mkcert.exe,执行命令安装根证书:
.\mkcert.exe -install
- 为内网IP生成证书:
.\mkcert.exe xxx.xxx.x.xxx (你的电脑ip地址 ,cmd弹出黑框 输入ipconfig就能看到)
执行完毕,文件夹会多出 2 个文件:
- xxx.xxx.x.xxx-key.pem 私钥
- xxx.xxx.x.xxx.pem 证书文件
把两个文件改名为:
- key.pem
- cert.pem
复制到你的 asr_api.py 同一个文件夹。
- 带证书启动HTTPS服务:
uvicorn asr_api:app --host 0.0.0.0 --port 8088 --ssl-keyfile key.pem --ssl-certfile cert.pem
重要:HTTPS网页中,WebSocket必须使用
wss://,继续使用ws://会被浏览器拦截二进制数据流。
问题3:浏览器访问https提示:Invalid HTTP request received.
原因
服务没有加载SSL证书,仍然是普通HTTP服务,浏览器发起HTTPS握手,协议不匹配。
只有启动命令带上--ssl-keyfile与--ssl-certfile,服务才是HTTPS服务。
问题4:WinError 10054 远程主机强迫关闭了一个现有的连接
现象
页面刷新、麦克风暂停后,控制台抛出连接重置异常。
原因
浏览器主动断开套接字,Windows系统强制关闭TCP连接,asyncio抛出警告。
解决办法
- 对
receive_bytes()增加内层异常捕获,优雅退出循环; - 全局屏蔽asyncio警告日志:
logging.getLogger("asyncio").setLevel(logging.CRITICAL)
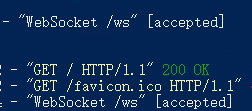
问题5:WebSocket显示[accepted],说话但是页面没有任何文字
排查步骤
- HTTPS页面必须使用
wss://,ws://会被浏览器静默拦截二进制音频; - 浏览器禁止页面自动调用麦克风,录音逻辑必须写在按钮点击事件内;
- 音频参数必须严格为:16000Hz、单声道、Int16 PCM;
- 在后端打印接收到的字节长度,确认前端音频流正常传输。
6. 功能扩展:语音识别对接大模型问答
FunASR只负责语音转文字,本身不具备对话问答能力。有两种扩展方案:
- FunASR一体化语音对话模型:
LLMASR、Qwen/Qwen3-ASR-0.6B,输入音频直接返回回答文本; - 模块化架构:Paraformer识别语音文本 → 调用本地轻量化Qwen小模型生成回答 → 把答案通过WebSocket推送回前端页面。
原有WebSocket接口完全不用改动,可直接升级为语音对话机器人。
演示视频:
7. 总结
- 架构优化:前端拾音+后端纯服务,彻底消灭PyAudio声卡硬件报错;
- 权限最优解:Hosts配置
.local内网域名,不用给所有访客安装证书、修改浏览器配置; - 协议严格区分:http对应ws,https对应wss,避免二进制音频被浏览器拦截;
- 完善异常捕获,解决Windows套接字10054强制断开警告;
- 增加静音自动清空字幕逻辑,大幅提升流式识别体验。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)