03Agent行动规划与工具调用策略
AI Agent 工具调用策略详解:Function Calling 与 ReAct 全面解析
在大模型(LLM)驱动的智能体(Agent)系统中,工具调用(Tool Use)是其从“会说话”进化为“会做事”的关键能力。通过调用外部工具(如搜索引擎、数据库、代码解释器、API 等),Agent 能够突破模型知识的静态边界,获取实时信息、执行计算、操作环境,从而完成真实世界的复杂任务。
目前,主流的工具调用策略主要有两类:
-
Function Calling(函数调用) —— 基于结构化输出的精准调用
-
ReAct(Reasoning + Acting) —— 基于文本推理的通用调用框架
本文将从原理、流程、实现、优劣对比、适用场景等多个维度,对这两种核心策略进行系统性、全面性的深度解析,助你构建高效可靠的 AI Agent 系统。
一、Function Calling:结构化、高精度的工具调用
(一)核心思想
Function Calling 是由 OpenAI 在 2023 年正式提出的一种原生支持的工具调用机制。其核心在于:大模型在推理时,若判断需要外部工具,会直接输出一个结构化的 JSON 对象(而非自然语言),明确指定要调用的函数名和参数。应用层解析该结构并执行真实工具,再将结果反馈给模型生成最终回答。
✅ 本质:让 LLM 输出“机器可读”的指令,而非“人类可读”的描述。
(二)工作流程(四步闭环)
具体步骤如下
-
发起请求:应用向 LLM 发送用户问题 +
tools列表(包含函数名、描述、参数 schema)。 -
模型决策:
-
若无需工具 → 返回纯文本。
-
若需工具 → 返回
tool_calls字段,内含function.name和function.arguments(JSON 字符串)。
-
-
执行工具:应用解析
tool_calls,调用对应函数(如get_weather("北京"))。 -
反馈与生成:将工具返回结果以
tool角色消息追加到对话历史,再次调用 LLM 生成最终回答。
(三)技术实现要点
-
工具定义格式(OpenAI 兼容):
编辑
{ "type": "function", "function": { "name": "get_current_weather", "description": "查询指定城市的当前天气", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "城市名"} }, "required": ["location"] } } } -
模型支持:仅限原生支持 Function Calling 的模型,如:
-
OpenAI: gpt-3.5-turbo, gpt-4-turbo
-
Anthropic: Claude 3 Opus/Sonnet
-
阿里云: Qwen-Max, Qwen-Plus
-
智谱: GLM-4
-
DeepSeek: DeepSeek-V2
-
精度表现:据 τ2-bench 测试,GPT-4 在工具调用准确率上达 96.7%,远超传统方法
(四)优势与局限
|
优势 |
局限 |
|---|---|
|
✅ 高精度:结构化输出避免解析歧义 |
❌ 依赖模型原生支持:不支持的模型无法使用 |
|
✅ 低延迟:单次调用即可完成决策 |
❌ 灵活性有限:难以处理多跳、反思类任务 |
|
✅ 工程友好:易于集成到现有系统 |
❌ 调试困难:黑盒决策,难追溯中间逻辑 |
|
✅ 安全性高:参数强类型校验(JSON Schema) |
❌ 不支持复杂规划:无法自动拆解子任务 |
📌 适用场景:单步、明确、高确定性的任务,如查天气、查库存、发邮件、执行简单计算等
二、ReAct:通用、可解释的推理-行动框架
(一)核心思想
ReAct(Reasoning + Acting)是由 Google Research 于 2022 年提出的通用 Agent 框架
它模拟人类“思考 → 行动 → 观察 → 反思”的认知循环,强制模型在每一步交替输出“Thought”(推理)和“Action”(行动),形成可追踪、可干预的执行链。
✅ 本质:将工具调用嵌入到自然语言推理流中,实现透明化、可调试的决策过程。
(二)标准格式(Prompt Engineering)
模型被引导按以下格式输出:
Thought: 我需要先搜索“通义千问最新版本”来获取信息。
Action: search("通义千问最新版本")
Observation: Qwen3-Max-Preview 于 2025 年 9 月发布...
Thought: 现在我知道最新版本是 Qwen3-Max-Preview。
Action: Finish("通义千问最新版本是 Qwen3-Max-Preview...")其中:
-
Thought:模型的内部推理 -
Action:要执行的工具调用(需预定义) -
Observation:工具返回的结果(由系统注入) -
Finish:任务完成,输出最终答案
(三)工作流程(多轮循环)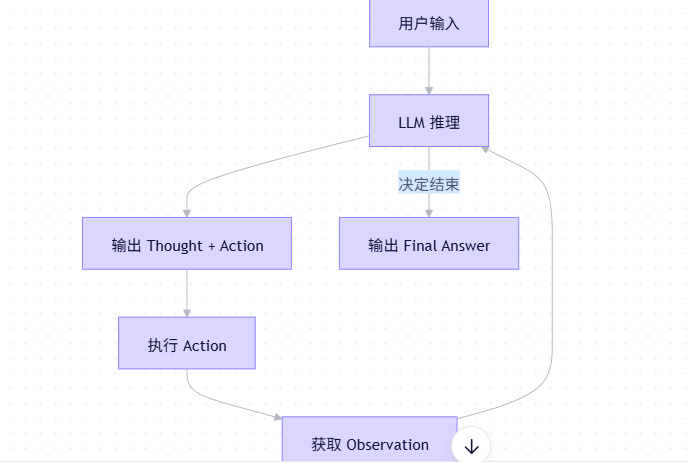
整个过程可能经历多次“思考-行动-观察”循环,直到任务完成或达到最大迭代次数
(四)实现方式
ReAct 不要求模型原生支持 Function Calling,而是通过精心设计的 Prompt 和输出解析规则实现:
-
定义工具集:提供工具名称、描述、使用示例。
-
构造 System Prompt:明确要求模型按
Thought/Action/Observation格式输出。 -
解析输出:正则表达式或 LLM 辅助解析
Action行,提取工具名和参数。 -
执行与反馈:运行工具,将结果以
Observation: ...形式拼接到下一轮输入。
💡 典型框架支持:LangChain、LlamaIndex、Dify(ReActAgentRunner)等均内置 ReAct 策略
(五)优势与局限
|
优势 |
局限 |
|---|---|
|
✅ 通用性强:适用于任何 LLM(包括开源小模型) |
❌ 依赖 Prompt 工程:格式易错,需大量调试 |
|
✅ 可解释性高:完整展示推理链,便于 debug |
❌ token 消耗大:每轮都包含冗余文本 |
|
✅ 支持复杂任务:可实现任务分解、错误重试、多工具串联 |
❌ 执行效率低:多轮交互增加延迟 |
|
✅ 灵活可控:可人工介入任意环节(human-in-the-loop) |
❌ 幻觉风险:模型可能编造 |
📌 适用场景:多步骤、需规划、需反思的任务,如市场调研、代码调试、复杂问答、自主探索等
三、Function Calling vs ReAct:深度对比
|
维度 |
Function Calling |
ReAct |
|---|---|---|
|
技术基础 |
模型原生能力(JSON Schema) |
Prompt Engineering + 输出解析 |
|
输出形式 |
结构化 JSON ( |
自然语言文本 ( |
|
支持模型 |
仅限现代闭源/部分开源大模型 |
所有 LLM(包括 7B 小模型) |
|
调用精度 |
极高(>95%) |
中等(依赖 Prompt 质量) |
|
任务复杂度 |
单步、确定性任务 |
多步、探索性、需规划任务 |
|
可解释性 |
低(黑盒决策) |
高(完整推理链) |
|
工程复杂度 |
低(标准 API) |
高(需解析、容错、状态管理) |
|
典型框架 |
OpenAI SDK, Dify (FunctionCallAgent) |
LangChain, AutoGPT, CrewAI |
🔁 趋势:现代 Agent 系统常采用 混合策略——
优先使用 Function Calling 提升效率
当任务失败或需复杂规划时,降级到 ReAct 模式进行反思与重试
四、进阶:工具调用的组合策略
1. Tool Chaining(工具链)
将多个工具按顺序调用,前一个工具的输出作为后一个的输入。
✅ 例:search("Qwen3 发布时间") → parse_date() → calculate_days_since_release()
2. Tool Routing(工具路由)
根据任务类型动态选择工具集。
✅ 例:用户问“写代码” → 加载 code_interpreter;问“查新闻” → 加载 browser_use
3. Self-Verification(自验证)
调用工具后,Agent 自行判断结果是否合理,若不满意则重试或换工具
4. Memory-Augmented Tool Use
将工具调用结果存入长期记忆(如向量数据库),供未来任务检索复用
五、总结与建议
-
如果你追求高精度、低延迟、生产稳定 → 优先使用 Function Calling,搭配 Qwen-Max、GPT-4 等模型。
-
如果你需要处理开放域、多步骤、需调试的任务 → 选择 ReAct,尤其适合开源模型或研究场景。
-
最佳实践:在 Dify、LangGraph 等现代框架中,同时启用两种策略,由系统根据任务复杂度自动切换。
🌟 未来方向:随着 MCP(Model Context Protocol) 和 A2A(Agent-to-Agent Protocol) 的普及,工具调用将走向标准化与互操作,Agent 不再是孤岛,而将成为可组合、可协作的“数字员工”。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)