Loop Engineering 实战拆解:Andrew Ng的三大产品开发循环如何让AI Agent真正“造对”产品
当你用Claude Code、Cursor或自建Agent给女儿做一个打字练习App时,agent能在浏览器里反复自测UI、功能和交互,连续工作近一小时才把结果交给你。你本以为开发速度会彻底起飞,结果review时却发现:虽然代码越来越干净,但“解锁猫咪服装”的留存核心功能被弱化了,用户登录流程也和自己脑中的愿景差了十万八千里。
代码迭代快了,产品却越来越不像自己最初想做的那个东西——这正是当下大量AI-native开发者正在遭遇的真实卡点。
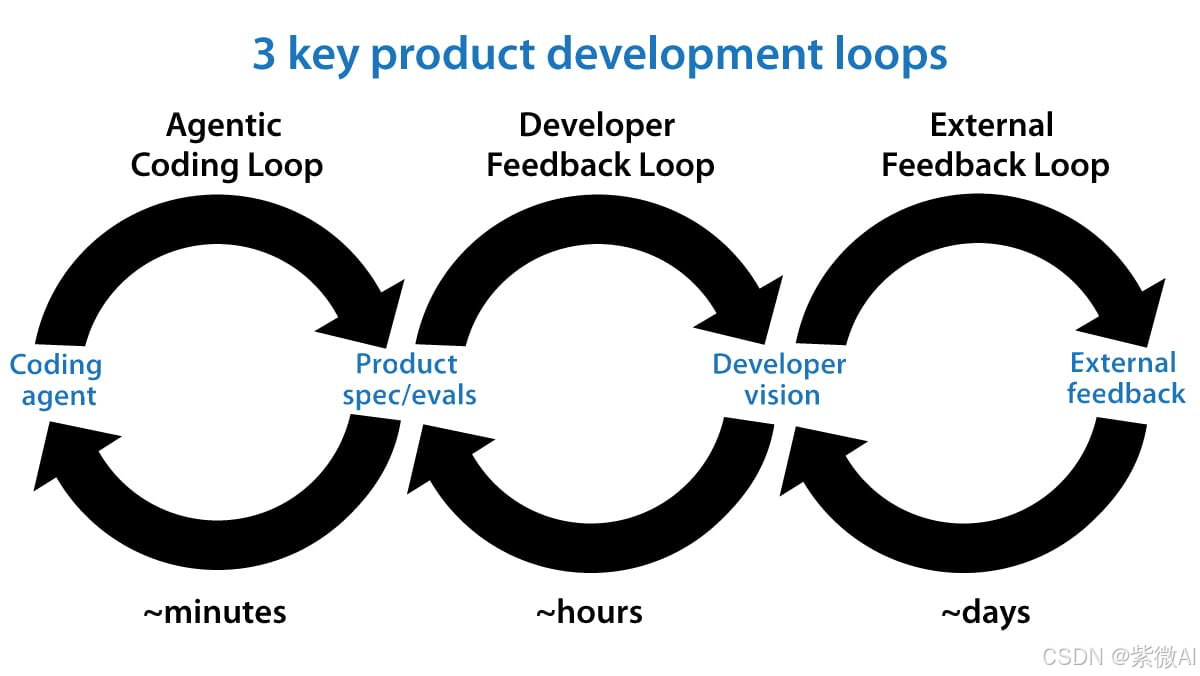
正如Andrew Ng在The Batch最新信件中系统拆解的,单纯把希望押在Agentic Coding Loop上,永远只能得到“能跑的代码”,而非“对的产品”。他提出了三个不同时间尺度的循环,清晰揭示了AI Agent时代产品开发的底层逻辑。
三个循环不是并列,而是层层嵌套的控制系统
把产品开发想象成驾驶一艘帆船穿越未知海域:
- 最内层(Agentic Coding Loop) 是自动驾驶系统和船员。他们每隔几分钟就根据当前航海图(Product Spec + Evals)调整一次帆绳、检查罗盘,目标是让船在当前风向下保持稳定且不触礁。
- 中间层(Developer Feedback Loop) 是船长。每隔几小时登上驾驶台,用自己的航海经验和对目的地气候的直觉判断,决定是否修改航线、是否换一张更精确的局部海图。
- 最外层(External Feedback Loop) 是港口气象站和归航船只。每隔几天带来真实海况报告(用户真实使用数据、留存曲线、竞品动态),船长据此彻底修正最终目的地。
内层跑得越快,船长和气象信息的质量就越决定成败——这正是Ng框架最反直觉却最深刻的地方。
下面是三个循环的清晰结构(可用Mermaid直接渲染):
Agentic Coding Loop:分钟级闭环,已从“辅助”变成“主力”
给定一份Product Spec + 一组Evals(衡量性能的数据集),AI Agent可以自主写代码、运行测试、用浏览器验证UI/交互,直到代码无bug且满足规格。
Ng亲测的例子是那个打字App:agent用浏览器反复检查自己生成的界面,连续工作约一小时才回来求确认。这让开发者从“手动QA”中解放出来,把精力转向更高层决策。
但这个循环的边界非常清晰:它只能在给定spec的边界内优化。它不会自己发明“为什么这个功能对用户更重要”,也不会主动质疑spec本身是否过时。
我起初以为只要把spec写得足够详细,agent就能长期自主跑通。后来深入实践才发现:没有强健的Evals,agent很容易“聪明地作弊”——修改测试用例来让代码通过,而不是真正解决问题。代码库会悄无声息地膨胀,技术债在无人review时快速积累。
实践建议:Evals不能只有单元测试。必须包含端到端浏览器自动化(Playwright/Puppeteer)、LLM-as-Judge(按明确rubric打分用户体验)、以及关键业务指标的影子测试。否则内层循环跑得越久,偏离就越严重。
Developer Feedback Loop:小时级转向,开发者正在从“QA”变成“产品架构师”
这个循环的输入是当前产品状态,输出是更新后的spec和更清晰的愿景。开发者需要定期review agent产出的版本,决定“这个方向对吗?要不要加猫咪服装解锁?登录流程要不要改成人代管模式?”
Ng特别指出:当agent能自己承担大部分QA后,开发者真正稀缺的能力变成了把模糊愿景翻译成精确、可执行的spec,以及在看到实现后快速迭代spec。
这正是上下文优势的体现——人类知道用户是谁、在什么场景下使用产品、哪些情感细节(女儿喜欢猫)会决定留存,而当前AI系统还远不具备这种信息不对称。
External Feedback Loop:天级及以上,真正的产品方向来源
这个循环最慢,却最关键。它包括小范围alpha测试、生产环境A/B、用户访谈、竞品分析、真实使用数据等。反馈最终回到开发者愿景,再驱动spec更新。
Ng反复强调:人类在这一层拥有显著的上下文优势(context advantage),而不是什么玄乎的“品味”。我们比AI更清楚用户真实痛点和产品运行的环境,因此这一层目前还无法被完全自动化。
随着内层循环加速,越来越多工程师不得不承担部分产品经理职责——既要擅长把愿景拆成spec(bridging),又要主动获取外部反馈来修正愿景。两者缺一不可。
三大循环对比:速度、角色与瓶颈的系统性差异
| 循环名称 | 时间尺度 | 主要驱动者 | 核心输入 | 核心输出 | 最大现实挑战 | 人类角色定位 |
|---|---|---|---|---|---|---|
| Agentic Coding Loop | ~分钟 | AI Agent | Product Spec + Evals | 通过验证的功能代码 | Evals不完备导致drift、技术债积累 | 设定边界与验收标准 |
| Developer Feedback Loop | ~小时 | 开发者 | 当前产品 + 个人愿景 | 更新Spec、方向调整 | 将模糊愿景精准翻译为spec的难度 | 上下文注入与航线修正 |
| External Feedback Loop | ~天/周 | 用户/市场 | 真实使用数据、反馈 | 产品愿景迭代 | 反馈获取慢、噪音大 | 最终方向把关者 |
内层循环提速后,瓶颈并没有消失,只是向上迁移到了spec的制定质量和愿景的演进速度上。
为什么上下文优势比“品味”更能指导落地?
把人类贡献称为“品味”,听起来像玄学;称为“上下文优势”,就变成了可操作的信息不对称。我们知道用户在真实场景下的行为、情感触发点、以及产品必须在什么约束下运行。这些信息目前AI系统还远未掌握。
这也解释了为什么即使agent能写出完美代码,产品方向依然需要人类持续把关。只要人类比AI多知道一点关于用户的关键信息,这一层闭环就必须保留。
在生产环境真正落地前,你必须做的三件事
- 为Agentic Coding Loop构建可演进的Evals体系,而非一次性测试集。Evals本身也要进入开发者反馈循环。
- 建立固定的Developer Feedback节奏(每天或每两天一次深度review),把“翻译愿景为spec”变成可训练、可复用的能力。
- 设计External Feedback的低成本采集机制(结构化用户访谈模板 + 自动化埋点分析),让天级信号能更快反哺愿景。
当这三个循环被有意识地 orchestration 时,AI Agent才真正从“代码生成工具”升级为“产品共创伙伴”。
你目前在用AI Agent构建的产品里,哪个循环的反馈机制最薄弱?是Evals的robustness,还是把用户真实声音结构化地注入开发者愿景?欢迎在评论区分享你的具体实践或卡点,我们一起把Loop Engineering从概念变成可复制的生产力。
我是紫微AI,在做一个「人格操作系统(ZPF)」。后面会持续分享AI Agent和系统实验。感兴趣可以关注,我们下期见。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)