如何用 AI Agent 做企业内部智能知识库:RAG、权限审核、样例库与上线清单
工程导读:这篇技术稿把企业内部智能知识库拆成知识源、治理、检索、Agent、审核和复盘六层,给出文档入库、权限前置、RAG 配置、审核运载荷、样例库、排障清单与灰度上线计划,并说明常见故障如何定位,适合 CSDN 技术读者按岗位场景复用。
适合读者:正在把企业文档、RAG、Agent、权限和审核接成内部知识库的技术负责人、产品负责人和交付负责人。
可复用产物:场景契约、入库配置、权限模型、Agent 路由伪代码、审核载荷、样例库字段、排障清单、灰度上线计划。
企业做内部智能知识库,最容易低估的部分通常落在工程秩序上,而非模型接入本身。把制度、产品手册、客服 FAQ、项目复盘、岗位 SOP 一次性导入向量库,Demo 阶段确实能看到“问一句、答一段”的效果;进入真实组织后,问题会集中暴露:员工有没有权限看到这段资料,文档是否过期,答案能不能追溯来源,高风险问题该不该进入人工确认,答错后谁负责修复知识。
这里先不展开模型选型,直接把企业内部智能知识库拆成一条可验收的 AI Agent 工作流。RAG 负责从外部知识源取回可引用内容,Agent 负责识别问题意图、选择处理路径、触发追问或审核,运营侧负责样例库、指标和知识缺口修复。读者可以把下面的配置、载荷和检查表改成自己的项目模板。
下面给出的产物包括六层架构表、文档入库 YAML、Agent 路由伪代码、JSON 审核载荷、样例库字段、排障清单和灰度上线计划。
1. 先把内部知识库拆成六层
内部知识库常被叫成“知识问答助手”,但生产系统至少要覆盖六个层级。每一层都要能被单独检查,否则问题会被包装成“模型不稳定”,很难定位。
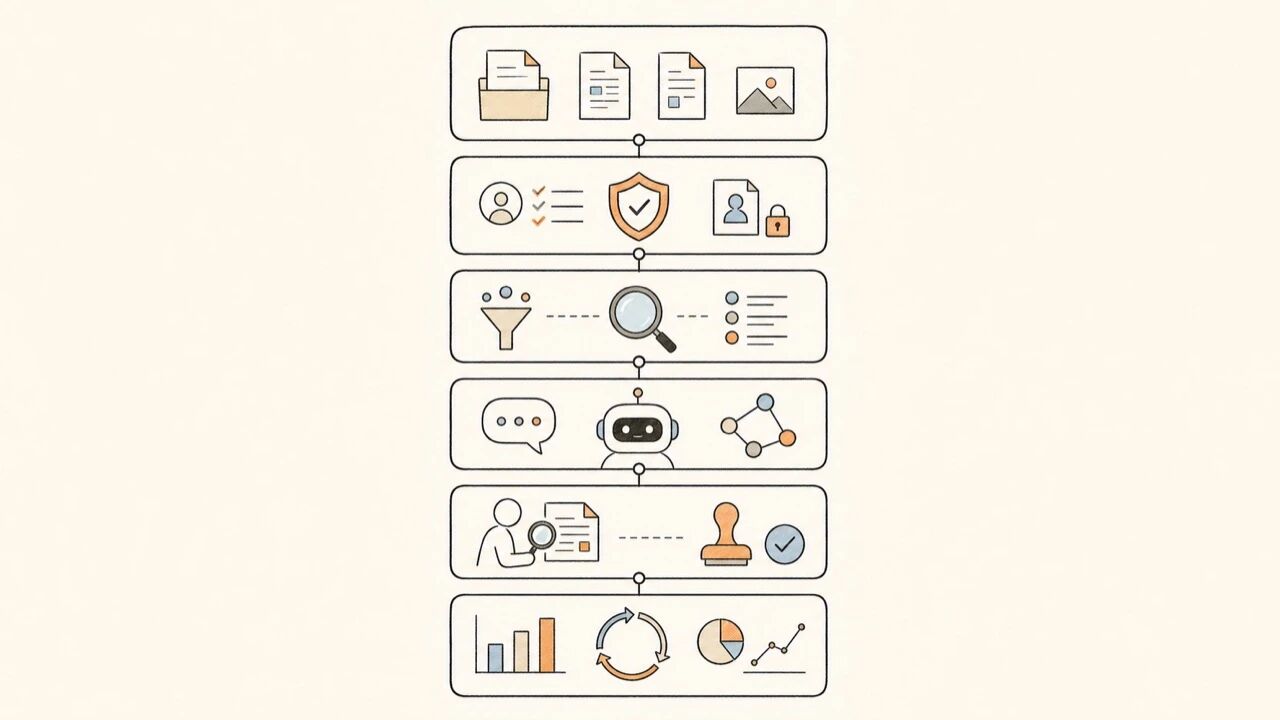
图注:企业内部智能知识库需要把知识源、治理、检索、Agent、审核和复盘接成一条链路。
| 层级 | 主要职责 | 工程交付物 | 常见失败点 |
|---|---|---|---|
| 知识源层 | 接入制度、手册、SOP、FAQ、工单复盘、项目文档 | 知识目录、来源清单、责任人 | 资料重复、旧版本混入、来源不可追溯 |
| 治理层 | 管理分级、版本、权限、过期规则 | 文档元数据、权限矩阵、过期策略 | 员工越权看到敏感内容 |
| 检索层 | 解析、分块、索引、召回、重排、引用来源 | 分块规则、向量库/搜索索引、引用格式 | 召回相似片段却答不到业务口径 |
| Agent 层 | 判断意图,选择查库、追问、拒答、转人工或调系统 | 路由规则、工具边界、异常处理 | 把助手扩成无边界的自动执行器 |
| 审核层 | 高风险答案复核,记录责任链 | 审核队列、审核运载荷、复核记录 | 涉及合同、人事、财务问题时直接回答 |
| 复盘层 | 看命中、无答案、纠错、审核通过、知识缺口 | 样例库、指标看板、修复列表 | 上线后只看访问量,不修知识 |
可以用下面的 Mermaid 图理解主链路:
这张图里有两个关键顺序:其一,权限判断在检索和生成之前;其二,复盘结果要回到知识源和样例库,不能只留在日志里。
2. 先选一个场景,不要先做全公司万能入口
技术方案落地前,先写清楚首个场景。内部知识库最适合从高频、规则明确、可追溯的岗位问题切入,例如客服 SOP 查询、销售售前资料检索、研发故障排查、人事制度问答。不要一开始就承诺“所有员工都能问所有问题”,范围越大,权限、口径和验收越难闭环。
一个场景契约可以这样写:
scene_contract:
scene_id: customer_service_sop_lookup
owner: 客服运营负责人
users:
- 客服一线
- 客服组长
allowed_questions:
- 售后流程查询
- 退款规则查询
- 常见异常处理步骤
- 工单升级条件
excluded_questions:
- 需要主管特批的赔付承诺
- 未发布的新政策
answer_requirements:
source_citation: 必须引用制度或 SOP 原文
stale_document_policy: 过期文档不得进入默认答案
unclear_intent_policy: 先追问业务场景
no_source_policy: 拒答并记录为知识缺口
human_review:
required_when:
- 涉及金额赔付
- 涉及对外承诺
- 检索来源互相冲突
这个契约的价值是把“能不能答”拆成几个可判断条件:问题是否在范围内,用户是否有权限,来源是否有效,答案是否需要复核。后续无论接 OpenAI File Search、企业搜索、向量数据库还是自建工作流,都要服从这份契约。
3. 文档入库流水线决定下限
RAG 的基本思路是先检索外部知识,再把检索结果作为上下文生成答案。企业场景里,检索质量往往受制于入库质量:原始文档如果没有责任人、版本、权限、过期时间,后面再强的检索和生成都只能补一部分。
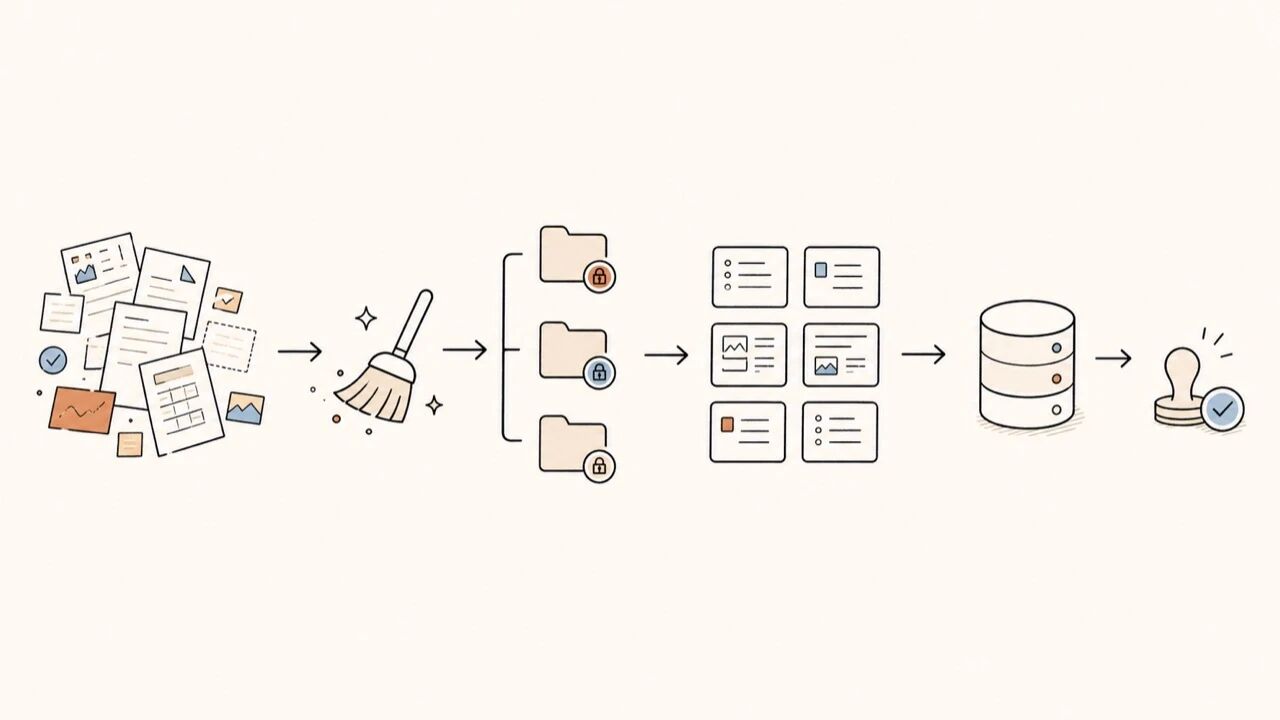
图注:先做资料分级、版本和责任人,再谈分块、向量化和检索。
建议把入库拆成七步:
| 步骤 | 要做什么 | 可验收结果 |
|---|---|---|
| 收集 | 只收首个场景需要的资料 | 知识源清单,不含无关资料 |
| 清洗 | 去重、去旧、统一格式 | 每份文档有稳定 ID 和当前状态 |
| 分级 | 标注公开、部门、岗位、敏感等级 | 权限矩阵能覆盖文档 |
| 切分 | 按标题、流程节点、问答单元切块 | 每个 chunk 语义完整 |
| 索引 | 保存原文、向量、关键词、元数据 | 可按关键词和语义召回 |
| 质检 | 用样例问题验证召回 | 能看到命中/漏召/误召 |
| 上线 | 灰度给一个岗位或部门 | 有反馈入口和修复负责人 |
下面是一份不绑定厂商的入库配置基线:
knowledge_ingestion:
source_scope:
include:
- 客服 SOP
- 售后政策
- 工单升级规范
- 已复盘的典型案例
exclude:
- 草稿制度
- 无负责人文档
- 超过有效期且未确认的旧版本
document_metadata:
required_fields:
- doc_id
- title
- owner
- department
- version
- status
- updated_at
- expire_at
- access_level
- source_url
chunking:
strategy: heading_and_business_step
max_chunk_chars: 900
overlap_chars: 120
keep_parent_heading: true
keep_policy_clause_id: true
retrieval:
hybrid_search: true
vector_top_k: 12
keyword_top_k: 8
rerank: true
final_context_k: 5
require_source_citation: true
quality_control:
sample_questions_per_scene: 80
check_items:
- 是否命中预期来源
- 是否引用过期文档
- 是否漏掉更权威版本
- 是否出现越权片段
这里的数值是工程模板的起点,不应当直接当成最终阈值。不同企业的文档粒度、问法复杂度和权限模型不同,最终配置要靠样例库回归和灰度反馈来调。
4. 权限过滤要放在生成前
很多知识库项目会把权限问题写进 Prompt,比如“如果用户没有权限,请不要回答”。这种做法风险很高:模型无法充当权限系统,也不能替代身份校验、文档 ACL 和审计记录。
更稳的顺序是:
- 根据登录态拿到用户身份、部门、岗位、项目组、临时授权。
- 在检索前确定可访问文档集合,或在召回后立即做服务端过滤。
- 只把授权后的片段传给模型生成。
- 答案返回时保留引用来源、文档版本和片段 ID。
- 对越权问题返回可解释拒答,并记录审计日志。
一个简化的数据结构如下:
permission_model:
user_context:
user_id: 当前登录用户
department: 所属部门
role: 岗位角色
project_groups: 项目组列表
temporary_grants: 临时授权
document_acl:
access_level:
- public
- department_only
- role_only
- project_only
- restricted
allowed_roles: 可访问岗位
allowed_departments: 可访问部门
denied_roles: 禁止访问岗位
enforcement:
before_generation: true
expose_denied_source_title: false
audit_denied_query: true
如果组织里已有 IAM、SSO、工单系统或文档权限系统,建议复用现有权限事实,不要为知识库另造一套难以维护的角色表。知识库只负责把权限事实带入检索链路,并把拒答和复核记录写回审计。
5. Agent 层只做路由和编排,别让它无边界执行
企业内部知识库里的 Agent 应该像流程编排器:判断问题类型,决定查知识库、追问澄清、提交人工审核、调用只读工具,或拒答。它不应该在没有审核的情况下直接替员工做高风险决策。
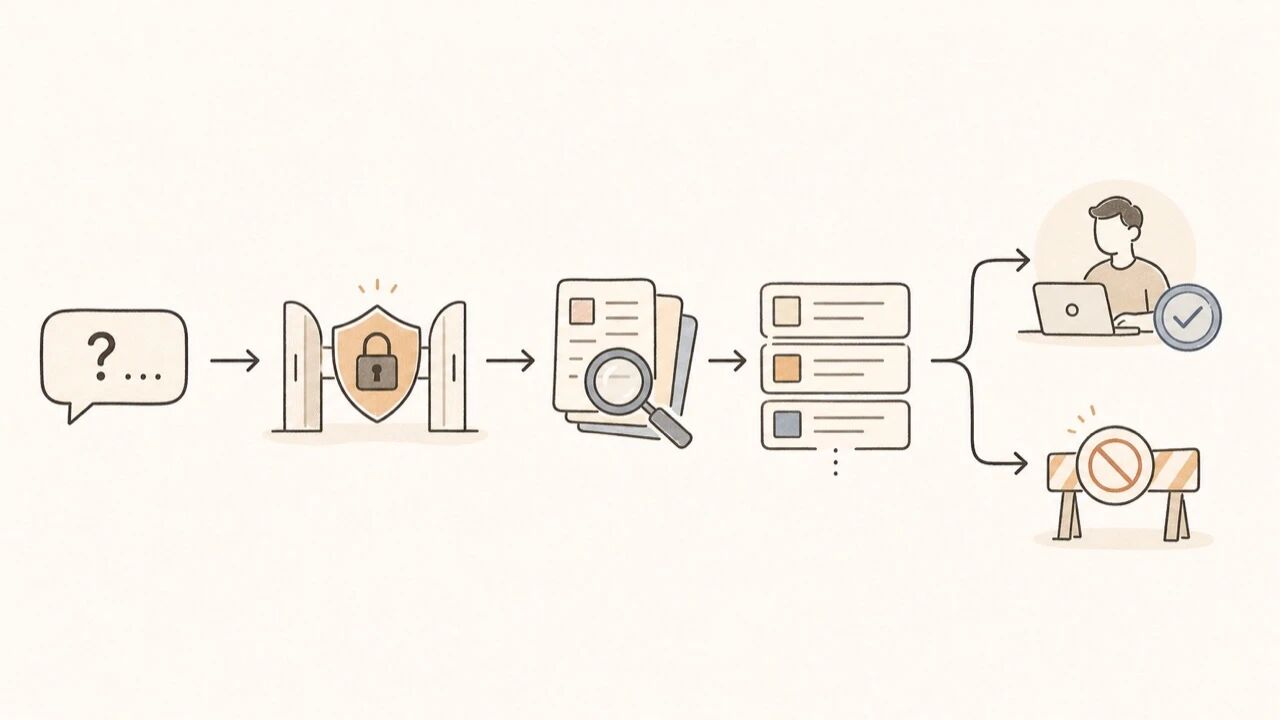
图注:企业知识库要优先保证边界清楚,该答才答、该拒答就拒答、该复核就复核。
伪代码可以写成这样:
def handle_internal_question(user_context, question):
intent = classify_intent(question)
scene = match_scene(intent, question)
if scene is None:
return ask_clarifying_question(
reason="问题没有匹配到已上线场景",
suggestions=["补充岗位", "补充业务流程", "说明要查询的制度类型"]
)
if is_high_risk_intent(intent):
review_payload = build_review_payload(
user_context=user_context,
question=question,
reason="高风险问题需要业务负责人确认"
)
return submit_to_human_review(review_payload)
candidate_chunks = retrieve_chunks(
question=question,
scene_id=scene.id,
user_context=user_context
)
authorized_chunks = filter_chunks_by_acl(
chunks=candidate_chunks,
user_context=user_context
)
if not authorized_chunks:
record_gap(question, scene.id, gap_type="no_authorized_source")
return refuse_with_reason("当前权限范围内没有找到可引用来源")
answer = generate_answer(
question=question,
chunks=authorized_chunks,
require_citation=True
)
if answer_has_conflict(answer) or answer_requires_review(answer):
return submit_to_human_review(
build_review_payload(user_context, question, answer)
)
return answer
这个逻辑里,模型只是链路中的一个环节。真正保护系统稳定性的,是场景范围、权限过滤、来源引用、审核分流和日志复盘。
6. JSON 审核载荷要能让业务 owner 看懂
当问题进入人工审核时,不要只把“模型答案”丢给审核人。审核人需要知道用户是谁、问题是什么、模型引用了哪些来源、触发审核的原因是什么、需要他确认哪一项。
下面是一个 JSON 载荷示例:
{
"review_id": "kb_review_20260629_001",
"scene_id": "customer_service_sop_lookup",
"risk_level": "medium",
"trigger_reason": [
"answer_mentions_compensation",
"retrieved_sources_have_policy_conflict"
],
"requester": {
"role": "客服一线",
"department": "客服部"
},
"question": "客户超过 7 天但商品有质量问题,是否可以直接承诺退款?",
"draft_answer": {
"summary": "根据已授权资料,系统无法直接给出对外承诺,需要主管确认。",
"suggested_next_step": "整理订单信息、商品问题证明和已沟通记录,提交组长复核。",
"citations": [
{
"doc_id": "policy_after_sales_v3",
"title": "售后处理规范",
"version": "v3",
"chunk_id": "clause_4_2"
},
{
"doc_id": "case_quality_issue_2026_05",
"title": "质量问题工单复盘",
"version": "2026-05",
"chunk_id": "case_summary"
}
]
},
"reviewer_actions": [
"approve",
"revise_answer",
"reject",
"mark_as_knowledge_gap"
],
"audit": {
"source_required": true,
"permission_checked": true
}
}
这份载荷不依赖具体审批系统。可以进入飞书/钉钉/企业微信审批,也可以进入内部工单。重点是审核人能看到来源和风险,不需要再去日志里倒查。
7. 样例库比 Prompt 更适合做验收
企业知识库上线前,要准备一套样例库。样例库承担上线验收职责,用来解释“为什么这次可以上线”。
| 字段 | 说明 | 示例 |
|---|---|---|
| case_id | 样例编号 | cs_refund_001 |
| scene_id | 绑定场景 | customer_service_sop_lookup |
| question | 员工真实问法 | 客户超过 7 天还能退吗 |
| user_role | 提问者角色 | 客服一线 |
| expected_sources | 应命中文档 | 售后处理规范 v3 |
| expected_behavior | 直接回答、追问、拒答、转审核 | 转审核 |
| forbidden_behavior | 禁止动作 | 不得承诺退款 |
| reviewer | 业务责任人 | 客服组长 |
| result | 回归结果 | 通过 / 需修订 / 知识缺口 |
评测指标建议先围绕可解释性,不要只盯“模型回答像不像人”。
| 指标 | 关注点 | 复盘动作 |
|---|---|---|
| 检索命中率 | 样例问题是否找到预期来源 | 调整分块、关键词、重排 |
| 引用覆盖率 | 答案是否带可追溯来源 | 调整生成模板和引用策略 |
| 无答案率 | 系统拒答或找不到来源的比例 | 补文档、补 FAQ、补 SOP |
| 越权拦截记录 | 是否拦住不该看的内容 | 修 ACL、修身份同步 |
| 审核通过率 | 进入审核的答案是否可用 | 修高风险规则和答案结构 |
| 纠错闭环时间 | 从发现错误到修复知识的周期 | 明确 owner 和修复节奏 |
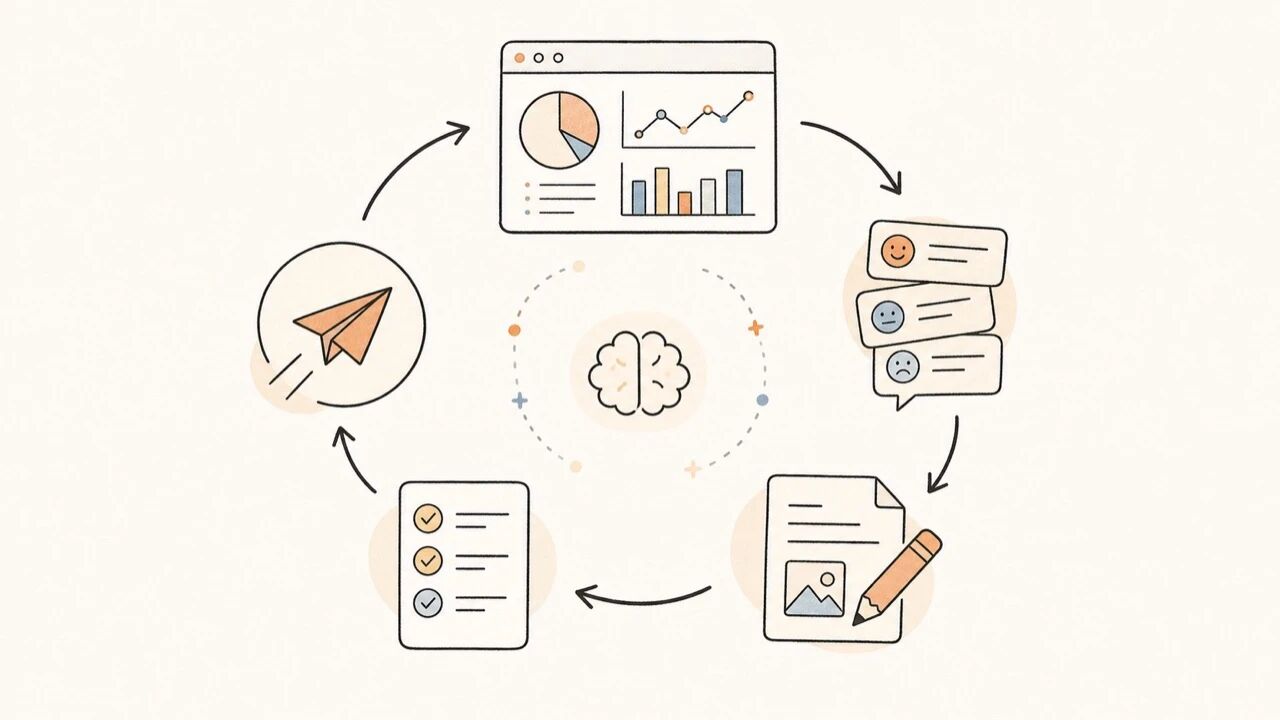
图注:知识库上线后要持续看无答案率、纠错率、引用覆盖率和审核通过率。
这里可以加一条工程纪律:每次答案被驳回,都要能归类到“文档缺失、文档过期、权限配置错误、检索漏召、生成误读、业务规则未定义”之一。归不了类,后续就无法稳定修复。
8. 最小可用版本怎么上线
从 0 到 1 不建议一次覆盖全公司。可以按四个阶段推进:
| 阶段 | 范围 | 主要交付 | 退出条件 |
|---|---|---|---|
| P0 设计 | 一个岗位、一个场景 | 场景契约、文档清单、样例库字段 | 业务 owner 确认范围和拒答边界 |
| P1 内测 | 小范围种子用户 | 入库流水线、RAG 检索、带来源回答 | 样例库能稳定回归,重大越权为 0 |
| P2 灰度 | 一个部门或班组 | Agent 路由、审核队列、反馈入口 | 知识缺口有 owner,审核能闭环 |
| P3 扩展 | 多岗位多场景 | 场景模板、权限矩阵、指标看板 | 新场景可复用同一套流程 |
上线计划可以更细一点:
rollout_plan:
phase_0_design:
duration: 1-2 周
tasks:
- 确认首个岗位场景
- 整理知识源清单
- 定义拒答和审核边界
- 建立首批样例库
stop_if:
- 没有业务 owner
- 文档没有版本和责任人
phase_1_pilot:
duration: 2-4 周
tasks:
- 接入高频文档
- 跑样例库回归
- 接入只读问答入口
- 记录无答案和纠错问题
release_rule:
- 不开放高风险自动执行
- 只返回授权来源内答案
phase_2_department_gray:
duration: 4-8 周
tasks:
- 加入人工审核队列
- 配置部门权限
- 每周复盘知识缺口
- 形成新增场景模板
rollback_rule:
- 出现越权暴露立即回滚检索权限
- 出现大面积错误先关闭自动回答
注意,回滚机制也要提前设计。企业内部知识库并非纯内容页面,它可能影响客服口径、销售承诺、研发排障和内部制度解释。只要涉及业务动作,就需要“暂停自动回答、改为只检索来源、全部进入审核”的降级路径。
9. 排障清单:上线后最常见的 9 个问题
| 问题 | 表现 | 优先检查 | 修复方向 |
|---|---|---|---|
| 召回不准 | 答案引用无关文档 | 分块粒度、关键词字段、重排规则 | 重切文档,补业务词表 |
| 漏召权威文档 | 命中了旧 FAQ,没命中制度 | 文档状态、标题层级、索引更新时间 | 提升权威文档权重 |
| 回答没来源 | 答案完整但不可追溯 | 生成模板、引用字段、上下文拼接 | 强制输出 doc_id/chunk_id |
| 旧文档进入答案 | 引用已废弃制度 | expire_at、status、索引删除策略 | 归档旧文档,重建索引 |
| 越权问题被回答 | 普通员工看到敏感信息 | ACL、身份同步、检索过滤顺序 | 权限前置,补审计日志 |
| 模糊问题乱答 | 用户没说场景也给结论 | 意图识别、追问规则 | 增加澄清问题 |
| 高风险未审核 | 涉及合同/人事/财务直接答 | 风险分类、审核触发词 | 高风险进入审核队列 |
| 拒答太多 | 员工觉得系统不好用 | 样例库、知识覆盖、权限范围 | 区分知识缺口和权限拒答 |
| 反馈无人处理 | 错误被标记后没人修 | owner、工单流、复盘节奏 | 给缺口分配责任人 |
排障时不要一上来换模型。先看问题属于知识、权限、检索、生成、审核还是运营闭环。只有确认上下游链路稳定后,模型替换才有比较意义。
10. 一份上线前检查表
发布给真实员工前,至少逐项过一遍:
- 首个场景已经写成契约,包含范围、排除范围和高风险边界。
- 文档都有
owner、version、status、updated_at、expire_at、access_level。 - 过期文档不会进入默认检索结果。
- 权限过滤在生成答案之前发生。
- 答案必须带来源,没有来源时不会编造。
- 高风险问题会进入人工审核。
- 审核人可以看到问题、草稿答案、引用来源和触发原因。
- 样例库覆盖正常问法、模糊问法、越权问法、无答案问法。
- 有反馈入口,错误答案能进入修复流程。
- 有回滚策略:关闭自动回答、只返回来源、全部转审核。
- 指标不只看访问量,还看命中、引用、拒答、纠错和审核。
11. 参考资料
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, 2020。
- OpenAI File Search / Vector Stores 文档。
- Microsoft Azure Architecture Center: RAG solution design and evaluation guide。
- OWASP GenAI Security Project: LLM Top 10。
- NIST AI Risk Management Framework。
最后补一句方法来源:这套拆解来自 Tate万能君 在 tatezhou.com 对企业 AI Agent、FDE 式陪跑、岗位 SOP、样例库、审核机制的持续整理,重点放在可复用的工程流程和交付检查项。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)