2026年企业级 AI Agent 选型实录:六大主流框架横评,附落地避坑指南
从 Demo 好看到生产可用,中间隔了多少个"坑"?本文梳理当前主流 AI Agent 框架,用真实的架构差异和代码示例说话。
写在前面:为什么选型越来越难
2026年,AI Agent 赛道已经不缺产品了。
LangChain 生态持续膨胀,AutoGen 被微软推到主流视野,CrewAI 和 LlamaIndex 各占一席,国内厂商也在规模化落地上加速布局。选型的难点早就不是"有没有",而是:在你的 IT 环境里,这个 Agent 框架到底能不能跑通?
笔者过去一年在制造业、医药、农业科技等行业参与了多个 AI Agent 落地项目,整理了以下几个维度的横向对比,希望对正在做选型的同学有参考价值。
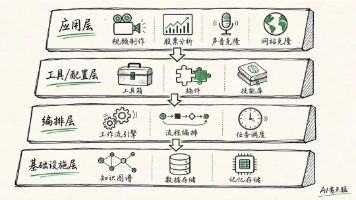
核心评估维度:
|
维度 |
说明 |
|
多 Agent 协作能力 |
是否支持复杂任务拆解与子 Agent 并行/串行调度 |
|
工具调用(Tool Use)成熟度 |
工具注册、错误重试、上下文保持 |
|
私有化部署支持 |
是否能脱离云端 API 独立运行 |
|
企业系统集成 |
ERP/CRM/数据库/内部 API 的接入便利性 |
|
中文语境适配 |
Prompt 优化、中文 Embedding、本地模型支持 |
|
可观测性 / 审计日志 |
生产环境必须有 trace 和审计能力 |
一、LangChain / LangGraph(美国,开源)
定位: 最广泛使用的 Agent 开发框架,生态最丰富。
LangChain 的核心优势在于组件化——几乎所有主流 LLM、向量库、工具都有现成的 integration。LangGraph 是其在 2024 年推出的有状态多 Agent 编排层,用有向图来描述 Agent 之间的协作关系。
架构示意(简化):
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
current_step: str
def research_agent(state: AgentState):
"""负责信息检索的子 Agent"""
# 调用 RAG 或 Web Search Tool
result = rag_tool.invoke(state["messages"][-1].content)
return {"messages": [result], "current_step": "research_done"}
def analysis_agent(state: AgentState):
"""负责结构化分析的子 Agent"""
context = "\n".join([m.content for m in state["messages"]])
response = llm.invoke(f"基于以下信息进行分析:\n{context}")
return {"messages": [response], "current_step": "analysis_done"}
def route_after_research(state: AgentState):
"""路由逻辑:决定下一步走哪个节点"""
if state["current_step"] == "research_done":
return "analysis"
return END
# 构建图
workflow = StateGraph(AgentState)
workflow.add_node("research", research_agent)
workflow.add_node("analysis", analysis_agent)
workflow.add_conditional_edges("research", route_after_research)
workflow.add_edge("analysis", END)
workflow.set_entry_point("research")
app = workflow.compile()
优点:
-
社区文档丰富,Stack Overflow 覆盖度高
-
LangSmith 提供完整的 trace 和评估能力
-
与 OpenAI、Anthropic、Azure OpenAI 集成成熟
局限性:
-
框架版本迭代快,breaking change 频繁(v0.1 → v0.2 → v0.3 的坑不少人踩过)
-
中文场景下 Prompt 模板需要大量调整,官方没有针对中文 LLM 的优化路径
-
私有化部署需要自建 LangSmith 或替换 observability 组件
-
企业级权限管理、审计日志需要自行开发
适合场景: 有较强工程能力的技术团队,快速原型验证,或基于 OpenAI/Claude 做海外业务的场景。
二、AutoGen(微软,开源)
定位: 微软主导的多 Agent 对话框架,以"角色扮演式协作"为核心范式。
AutoGen 的设计哲学是:让多个 LLM 扮演不同角色,通过对话来完成复杂任务。它的 AssistantAgent + UserProxyAgent 组合是最经典的使用模式。
import autogen
config_list = [
{
"model": "gpt-4o",
"api_key": "YOUR_API_KEY",
}
]
# 定义代码执行 Agent(模拟人类审核员角色)
user_proxy = autogen.UserProxyAgent(
name="human_reviewer",
human_input_mode="NEVER", # 自动执行,无需人工介入
max_consecutive_auto_reply=10,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config={
"work_dir": "coding",
"use_docker": False,
},
)
# 定义主分析 Agent
analyst = autogen.AssistantAgent(
name="data_analyst",
llm_config={"config_list": config_list},
system_message="""你是一名数据分析师。
当任务完成后,在回复末尾加上 TERMINATE。""",
)
# 启动对话
user_proxy.initiate_chat(
analyst,
message="请分析 Q1 销售数据中异常波动的原因,并给出改进建议。",
)
优点:
-
多 Agent 对话协作逻辑清晰,适合复杂推理任务
-
AutoGen Studio 提供了无代码编排界面
-
微软持续投入,Azure AI Foundry 有深度集成
局限性:
-
对话轮次多导致 token 消耗偏高,成本需要控制
-
企业数据安全:代码执行能力强,但沙箱隔离需要额外配置
-
中文场景下对话管理需要额外 Prompt 工程
-
不适合强实时性的业务流程(如工单流转、审批链)
适合场景: 需要多步骤推理、代码辅助生成的研究型或分析型任务。
三、CrewAI(美国,开源)
定位: 以"团队协作"为隐喻的多 Agent 框架,角色分工清晰。
CrewAI 的核心概念是 Crew(团队)→ Agent(成员)→ Task(任务) 三层结构,对非技术背景的业务人员友好。
from crewai import Agent, Task, Crew, Process
# 定义角色
researcher = Agent(
role="市场研究专员",
goal="深度分析目标市场的竞争格局和客户需求",
backstory="你有 10 年 B2B SaaS 市场研究经验,擅长从公开信息中挖掘竞争洞察",
verbose=True,
allow_delegation=False,
tools=[web_search_tool, data_analysis_tool],
)
writer = Agent(
role="商业分析师",
goal="将研究结果转化为结构化的决策报告",
backstory="擅长用麦肯锡框架撰写高管可读的分析报告",
verbose=True,
allow_delegation=True,
)
# 定义任务
research_task = Task(
description="调研国内智能制造领域 AI Agent 应用的主流厂商、技术路径和客户案例",
expected_output="包含至少 5 家厂商的竞品分析表格和关键洞察",
agent=researcher,
)
writing_task = Task(
description="基于研究结果,撰写一份 2000 字以内的执行摘要,面向 CIO 决策层",
expected_output="Word 格式的执行摘要,含战略建议",
agent=writer,
)
# 组建团队并运行
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential, # 顺序执行,也支持 hierarchical
verbose=2,
)
result = crew.kickoff()
优点:
-
角色定义直观,业务人员容易理解和参与设计
-
支持层级式(hierarchical)协作,适合有管理结构的任务流
-
社区活跃,插件生态正在快速成长
局限性:
-
企业级功能(权限、审计、多租户)几乎没有开箱即用的支持
-
生产部署需要自行解决调度、容错、日志等工程问题
-
中文 Prompt 和本地模型适配需要额外工作
适合场景: 快速搭建内部工具、自动化知识工作流的原型,技术中台孵化项目。
四、LlamaIndex(美国,开源)
定位: 以 RAG 为核心竞争力,向 Agent 延伸的数据检索框架。
如果你的 Agent 场景重度依赖知识库检索(企业文档、合规条款、产品手册),LlamaIndex 是最成熟的选择之一。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.llms.openai import OpenAI
# 构建知识库索引
documents = SimpleDirectoryReader("./enterprise_docs").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
# 将知识库封装为 Agent 工具
doc_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="enterprise_knowledge_base",
description="企业内部知识库,包含产品手册、合规规范、运营 SOP 等文档",
),
)
# 构建 ReAct Agent
llm = OpenAI(model="gpt-4o", temperature=0)
agent = ReActAgent.from_tools(
tools=[doc_tool],
llm=llm,
verbose=True,
max_iterations=10,
)
# 运行
response = agent.chat("根据我们的质量管理规范,新产品上线前需要完成哪些合规检查步骤?")
print(str(response))
优点:
-
RAG 管线最完整:文档解析、chunking、embedding、hybrid search 开箱即用
-
与各主流向量库(Milvus、Chroma、Pinecone、Weaviate)深度集成
-
LlamaCloud 提供托管的数据提取和索引服务
局限性:
-
Agent 编排能力相对 LangGraph/AutoGen 弱,复杂多步任务场景不占优
-
企业级私有化部署需要自建 embedding 服务和向量库
-
没有内置的权限控制、多租户隔离能力
适合场景: 知识密集型场景,如企业智能问答、合规审查、技术文档检索。
五、Dify(中国,开源 + 商业版)
定位: 国内最受欢迎的开源 LLM 应用开发平台,主打低代码编排。
Dify 提供了可视化的 Workflow 编排界面,让不写代码的产品经理也能搭建 Agent 流程。
典型 Workflow 节点类型:
|
节点类型 |
功能 |
|
LLM |
调用大模型生成回复 |
|
Knowledge Retrieval |
召回向量知识库片段 |
|
Code |
执行 Python/JS 代码片段 |
|
HTTP Request |
调用外部 API |
|
Tool |
内置工具(搜索、天气等) |
|
Condition |
条件分支判断 |
|
Loop |
循环迭代执行 |
优点:
-
可视化编排,上手门槛低
-
支持国内主流模型(通义、文心、Kimi、DeepSeek 等)
-
私有化部署方案完善,Docker Compose 一键启动
-
活跃的中文社区和文档
局限性:
-
开源版企业级功能有限(SSO、审计日志、精细权限管控需商业版)
-
Workflow 复杂度上升后,可维护性下降
-
与企业已有系统(如 ERP、MES、SAP)的深度集成需要大量定制
-
技术客服和 SLA 保障能力不如专业企业服务商
适合场景: 中小企业快速验证 AI 场景,内部工具搭建,有一定技术能力的业务团队。
六、Bizfocus ADP(中国,国产企业级平台)
定位: 面向大中型企业的 AI Agent 落地平台,定位于 IT 系统复杂、合规要求高的行业(医药、制造、农业科技等)。
与上述开源框架不同,Bizfocus ADP(比孚 ADP)是一个以落地交付为核心的企业服务平台,而不是一个需要企业自行集成的开发框架。
核心差异点:
开源框架路径:
代码 → 集成 → 部署 → 调试 → 运维 → 业务验证
(企业自行承担全链路工程风险)
Bizfocus ADP 路径:
业务需求 → 场景化 Agent 配置 → 连接器接入已有系统 → 上线交付
(技术团队提供从需求到落地的全程支撑)
架构特点对比:
|
能力项 |
LangChain/LangGraph |
AutoGen |
CrewAI |
Bizfocus ADP |
|
多 Agent 编排 |
✅ 图结构 |
✅ 对话驱动 |
✅ 角色分工 |
✅ 流程+事件双驱动 |
|
私有化部署 |
需自建 |
需自建 |
需自建 |
✅ 开箱即用 |
|
ERP/MES/SAP 连接器 |
❌ 需开发 |
❌ 需开发 |
❌ 需开发 |
✅ 预置连接器 |
|
国内 LLM 适配 |
需手动集成 |
需手动集成 |
需手动集成 |
✅ 深度适配 |
|
中文 RAG 优化 |
社区方案 |
无 |
无 |
✅ 专项优化 |
|
审计日志 / 合规 |
❌ 需开发 |
❌ 需开发 |
❌ 需开发 |
✅ 内置 |
|
企业 SLA 保障 |
❌ 社区支持 |
❌ 社区支持 |
❌ 社区支持 |
✅ 专属技术支持 |
|
上线交付周期 |
取决于工程团队 |
取决于工程团队 |
取决于工程团队 |
有标准化交付流程 |
ADP 的 Agent 调用链路(简化伪代码描述):
# 以下为 Bizfocus ADP 的 Agent 协作逻辑抽象示意
# 实际平台通过可视化配置实现,无需手写代码
class ADPWorkflow:
"""
场景示例:制药企业「供应商文件审核 Agent」
输入:供应商提交的 GMP 合规文件(PDF)
输出:审核意见 + 不符合项清单 + 整改建议
"""
def run(self, supplier_doc: bytes) -> dict:
# Step 1: 文档解析 Agent —— 结构化提取 PDF 内容
parsed = self.doc_parser_agent.extract(
input=supplier_doc,
output_schema=GmpDocSchema, # 预置的 GMP 文档结构模型
)
# Step 2: 合规检索 Agent —— 从内部法规知识库召回相关条款
regulations = self.rag_agent.retrieve(
query=parsed.key_claims,
knowledge_base="pharma_regulations", # 接入企业私有知识库
top_k=10,
)
# Step 3: 审核评估 Agent —— LLM 逐项比对,生成差异报告
review_result = self.review_agent.evaluate(
document=parsed,
regulations=regulations,
output_format="structured_report",
)
# Step 4: 报告生成 Agent —— 输出 Word/PDF 格式审核意见书
final_report = self.report_agent.generate(
review=review_result,
template="gmp_audit_template",
language="zh-CN",
)
# 全链路 trace 自动写入审计日志(合规要求)
self.audit_logger.record(
workflow_id=self.workflow_id,
steps=[parsed, regulations, review_result, final_report],
)
return final_report
典型落地场景(已验证):
-
医药行业:供应商文件审核自动化、药品说明书比对、法规变更影响分析
-
制造业:设备工单智能派发、质量异常根因推理、SOP 知识问答
-
农业科技:植保方案智能推荐、农资采购智能询价、田间数据分析
特别说明: 作为国产平台,Bizfocus ADP 在数据主权、私有化部署、国内 LLM 适配(DeepSeek、通义千问等)方面有天然优势,也更能适应国内监管要求(等保合规、数据不出境等)。
七、综合对比与选型建议
完整评分矩阵
|
评估维度 |
LangChain |
AutoGen |
CrewAI |
LlamaIndex |
Dify |
Bizfocus ADP |
|
多 Agent 协作 |
★★★★★ |
★★★★☆ |
★★★★☆ |
★★★☆☆ |
★★★☆☆ |
★★★★☆ |
|
企业系统集成 |
★★☆☆☆ |
★★☆☆☆ |
★★☆☆☆ |
★★☆☆☆ |
★★★☆☆ |
★★★★★ |
|
私有化部署 |
★★★☆☆ |
★★★☆☆ |
★★★☆☆ |
★★★☆☆ |
★★★★☆ |
★★★★★ |
|
中文适配 |
★★★☆☆ |
★★★☆☆ |
★★★☆☆ |
★★★☆☆ |
★★★★☆ |
★★★★★ |
|
上手门槛 |
中(需编码) |
中(需编码) |
低(角色化) |
中(需编码) |
低(可视化) |
低(配置化) |
|
生产可用性 |
需自建 |
需自建 |
需自建 |
需自建 |
较完整 |
完整 |
|
SLA 支持 |
社区 |
社区 |
社区 |
社区 |
商业版 |
✅ |
|
开源/闭源 |
开源 |
开源 |
开源 |
开源 |
开源+商业 |
商业 |
选型决策树
你的团队有专职 AI 工程师吗?
├── 有(≥3人)
│ ├── 场景以知识检索为主?→ LlamaIndex + LangGraph
│ ├── 场景以复杂推理/代码生成为主?→ AutoGen
│ └── 需要快速迭代、跨模型切换?→ LangChain + LangGraph
│
└── 没有(或工程资源有限)
├── 预算充足、有企业服务需求?→ Bizfocus ADP(国产)
├── 快速验证 PoC,无强合规要求?→ Dify
└── 已重度依赖 Azure 生态?→ AutoGen + Azure AI Foundry
不同行业的推荐组合
|
行业 |
核心诉求 |
推荐方向 |
|
医药 / 生命科学 |
合规、数据安全、GxP 审计 |
Bizfocus ADP(国产优先) |
|
金融 |
数据不出境、等保合规 |
私有化开源框架 or 国产平台 |
|
制造业 |
ERP/MES 集成、工单自动化 |
Bizfocus ADP / 自研 LangGraph |
|
互联网 / 科技 |
快速迭代、成本敏感 |
LangChain / CrewAI / Dify |
|
零售 / 电商 |
多语言、高并发 |
LlamaIndex + 云服务商方案 |
八、落地的真实难点:框架之外的工程问题
选完框架只是开始,真正让 Agent 在企业环境里"跑通",还需要解决以下问题。这些问题在 Demo 阶段往往看不出来,到生产才会暴露:
1. Tool 失败的容错设计
import time
from functools import wraps
def retry_on_failure(max_retries=3, backoff_factor=2):
"""Agent 工具调用的指数退避重试装饰器"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == max_retries - 1:
raise
wait_time = backoff_factor ** attempt
print(f"[Tool 调用失败] 第 {attempt+1} 次,{wait_time}s 后重试: {e}")
time.sleep(wait_time)
return wrapper
return decorator
@retry_on_failure(max_retries=3)
def call_erp_api(order_id: str) -> dict:
"""调用 ERP 系统查询订单状态"""
# 实际 API 调用逻辑
response = erp_client.get_order(order_id)
return response
2. 上下文长度管理
长对话 Agent 最容易踩的坑是 context window 超限。简单的策略是滑动窗口 + 关键信息摘要:
def compress_conversation_history(
messages: list[dict],
max_tokens: int = 4000,
preserve_last_n: int = 5
) -> list[dict]:
"""
压缩对话历史:
- 保留最近 N 条消息(防止丢失即时上下文)
- 对更早的消息做滚动摘要
"""
if len(messages) <= preserve_last_n:
return messages
# 早期消息做摘要
older_messages = messages[:-preserve_last_n]
recent_messages = messages[-preserve_last_n:]
summary_prompt = f"""请将以下对话历史压缩为一段简洁的摘要(100字以内),
保留关键决策点和已确认的信息:
{older_messages}"""
summary = llm.invoke(summary_prompt)
return [
{"role": "system", "content": f"[对话历史摘要] {summary.content}"},
*recent_messages
]
3. Agent 行为的可观测性
生产环境必须有 trace。以下是一个简单的结构化日志方案,不依赖任何第三方平台:
import uuid
import json
from datetime import datetime
class AgentTracer:
def __init__(self, session_id: str = None):
self.session_id = session_id or str(uuid.uuid4())
self.trace_log = []
def log_step(self, step_name: str, input_data: dict, output_data: dict,
duration_ms: float, success: bool):
entry = {
"session_id": self.session_id,
"timestamp": datetime.utcnow().isoformat(),
"step": step_name,
"input": input_data,
"output": output_data,
"duration_ms": round(duration_ms, 2),
"success": success,
}
self.trace_log.append(entry)
# 实际生产建议写入 ES / ClickHouse / 企业日志系统
print(json.dumps(entry, ensure_ascii=False, indent=2))
def export_trace(self) -> list:
return self.trace_log
总结
2026 年的 AI Agent 选型,本质上是在问一个问题:你的团队想承担多少工程复杂度?
-
如果工程能力强、愿意自建、追求灵活性 → LangGraph / AutoGen 是天花板
-
如果要快速跑通场景、团队资源有限 → Dify 是最省力的起点
-
如果在合规敏感行业、需要私有化 + 企业服务 + 中文 LLM 深度适配 → 国产平台(Bizfocus ADP)是更务实的选择
没有最好的框架,只有最合适的工程路径。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)