Headroom:AI Agent上下文压缩层
我们是由枫哥组建的IT技术团队,成立于2017年,致力于帮助IT从业者提供实力,成功入职理想企业,我们提供一对一学习辅导,由知名大厂导师指导,分享Java技术、参与项目实战等服务,并为学员定制职业规划,全面提升竞争力,过去8年,我们已成功帮助数千名求职者拿到满意的Offer:IT枫斗者、IT枫斗者-Java面试突击。
Headroom:AI Agent上下文压缩层
◆ 8.6K Star、5 个月省了 418 亿 Token:Headroom 凭什么成为 AI Agent 的「压缩层」标配?
Claude Code 跑一天烧多少 token?Headroom 的答案是:可以少 92%,答案完全一样。
你有没有这个习惯:每次跑完 AI coding agent,看一眼账单?
我上周看了一眼。不算多,但架不住天天跑。关键是——至少一半的 token,LLM 根本不需要。重复的日志、八竿子打不着的搜索结果、明明通过了的测试输出。
agent 没问题。问题在于,目前没有一层「信号过滤」机制。工具输出一股脑灌进上下文,LLM 不能举手说「这些我不需要」。
这就是 Headroom。
◆ 它是什么
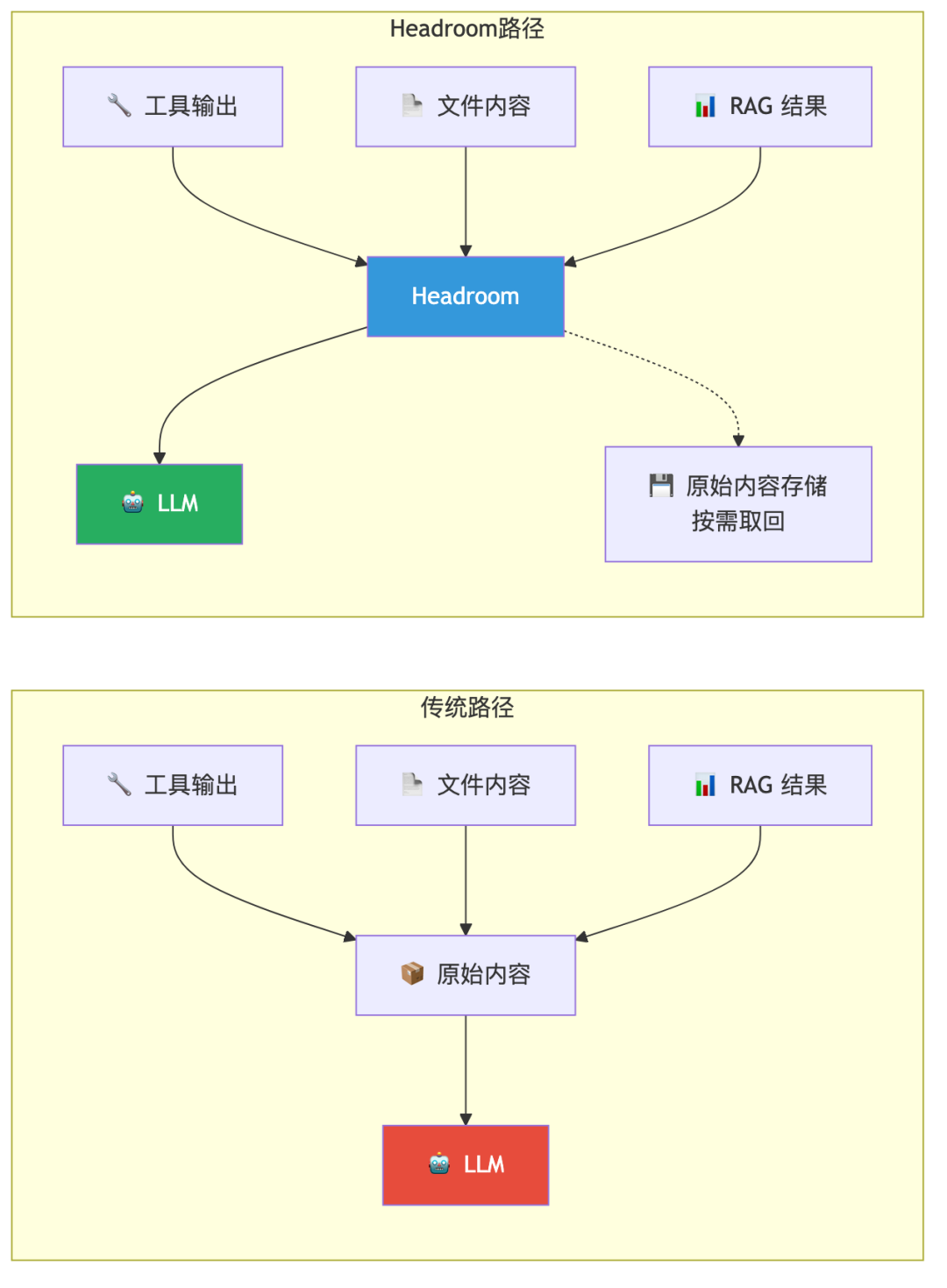
一个上下文压缩层。夹在你的 agent 和 LLM 中间,进来什么内容先压缩一遍,再交出去。
它跟 prompt 压缩是两回事。跟摘要模型也是两回事。它的逻辑是按内容类型来:JSON 有一套压缩法,代码有一套,日志又有一套。
三句话:
-
60-95% token 节省
答案准确度不变
-
完全本地运行
数据不出机器
-
可逆压缩
原始内容不删除,LLM 可以按需取回
◆ 为什么是现在
2026 年,AI coding agent 已经是日常工具。
Claude Code、Codex、Cursor、Aider——工程师每天泡在里面。但一个尴尬的事实摆在面前:token 不是无限的。上下文窗口有上限,API 费用在涨,对话越长质量越差。
另一个问题是跨 agent 协作。你可能上午用 Claude Code 写后端,下午换 Codex 调前端。两个 agent 不知道对方干过什么,每次都从头喂上下文。
Headroom 卡的时间点很准。2026 年 1 月 7 日第一行代码,5 个月 8.6K Star。不是因为「又来了一个省 token 的工具」。它把压缩、记忆、可逆三件事装进了同一个系统里,而且 Claude、Codex、Cursor——它都接得上。
社区数据:418 亿 token 已节省,省钱 $17.66 万,120 万次请求被优化,889 个活跃实例。
◆ 六种压缩器,各吃各的饭
核心思路一句话:什么类型的数据,用什么压缩器。万能压缩是不存在的——那是乱删,不是压缩。
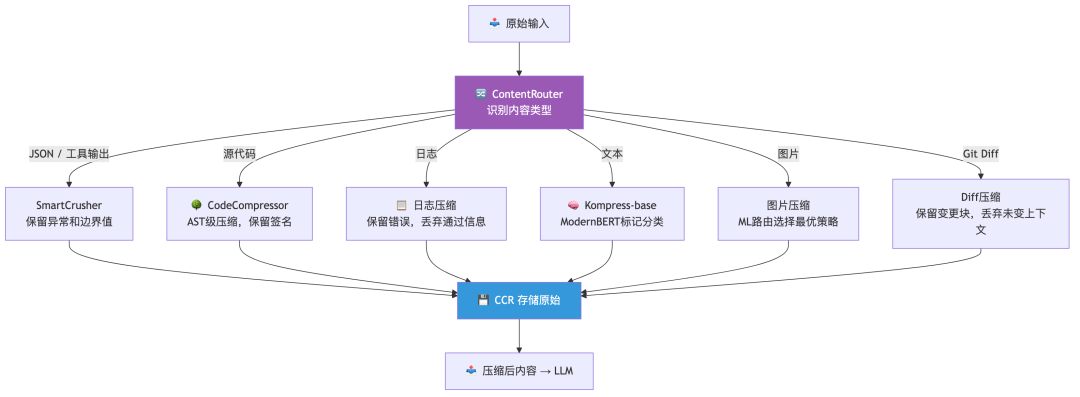
SmartCrusher — JSON 专精。几百条工具返回,有用的可能就那几条异常值。它用统计方法抓离群点,均匀分布的常态数据直接跳过。实际场景:100 条 API 响应日志 → 留 5 条异常 + 边界,省 90%。
CodeCompressor — 读 AST,不是正则。它理解代码结构:留签名和接口,折叠函数体。Python、JS、Go、Rust、Java、C++ 全支持。20 个文件的搜索结果 → 每个文件只剩接口和关键逻辑,省 70%。
Kompress-base — Headroom 自己训的模型,基于 ModernBERT。对每个 token 打标:「保留」还是「丢弃」。质量 7.9/10(LLMLingua-2 只有 5.9),速度快 2.3 倍,150M 参数 600MB。本地跑,不用 GPU。
图片压缩 — ML 路由自动选最优的 resize 和 quality 组合。agent 看截图,原始 PNG 几 MB → 几百 KB,视觉可读性不丢。
CCR(可逆压缩) — 这可能是 Headroom 最特别的设计。原始内容全存在本地,LLM 觉得不够随时调 headroom_retrieve 取回原文。等于说「先看大纲,要细节再喊我」。
◆ 从输入到 LLM:一条流水线
compress() 背后是 11 步 pipeline:

三个核心阶段:
Input Routed:ContentRouter 看内容类型,JSON、代码、文本各自分流到对应的压缩器。
Input Compressed:压缩器上场。JSON → SmartCrusher。代码 → CodeCompressor。日志 → 日志压缩器。
Input Remembered:原始内容存本地 CCR。可逆压缩的基石——LLM 可以随时回头取原文。
还有一步很多人会忽略:CacheAligner。它在更早的阶段稳定 prompt 前缀,让 Anthropic 和 OpenAI 的 KV 缓存能连续命中。不省 token,但每次请求的延迟降下来了。
◆ 实际效果
数字自己会说话。

SRE 排查最夸张:65,694 → 5,118 token,92% 省了。100 条日志压到 8%,LLM 照样能定位到藏第 67 行的致命错误。
按内容类型拆开看:

日志和 JSON 省最多——噪音密度太高了。纯文本空间有限,毕竟每个字本身就有信息量。
准确性没掉:GSM8K(数学推理)和 TruthfulQA(事实准确)上,压不压结果一样,部分还略好。去掉的确实是噪声,不是信号。
◆ Kompress-base:正经训了一个模型
调 prompt、写正则——这些 Headroom 都不做文本压缩。它训了个模型。

Base 版 150M 参数,600MB。做的事很窄:token 级别「留 / 丢」二分类。评分怎么来的?Claude Sonnet 4.6 当裁判,标尺是「压缩完 LLM 还能不能完整理解并执行」。
Small 版更轻:70M 参数、279MB,质量掉 0.5 分但 ONNX 推理 13-29ms。资源紧张场景刚好。
LLMLingua-2 曾是开源的默认选择。现在 Headroom 三个维度——质量、速度、体积——全超了。
◆ 竞争格局:不是一个赛道
做上下文压缩的工具不少,但放一起看,位置差别很大:
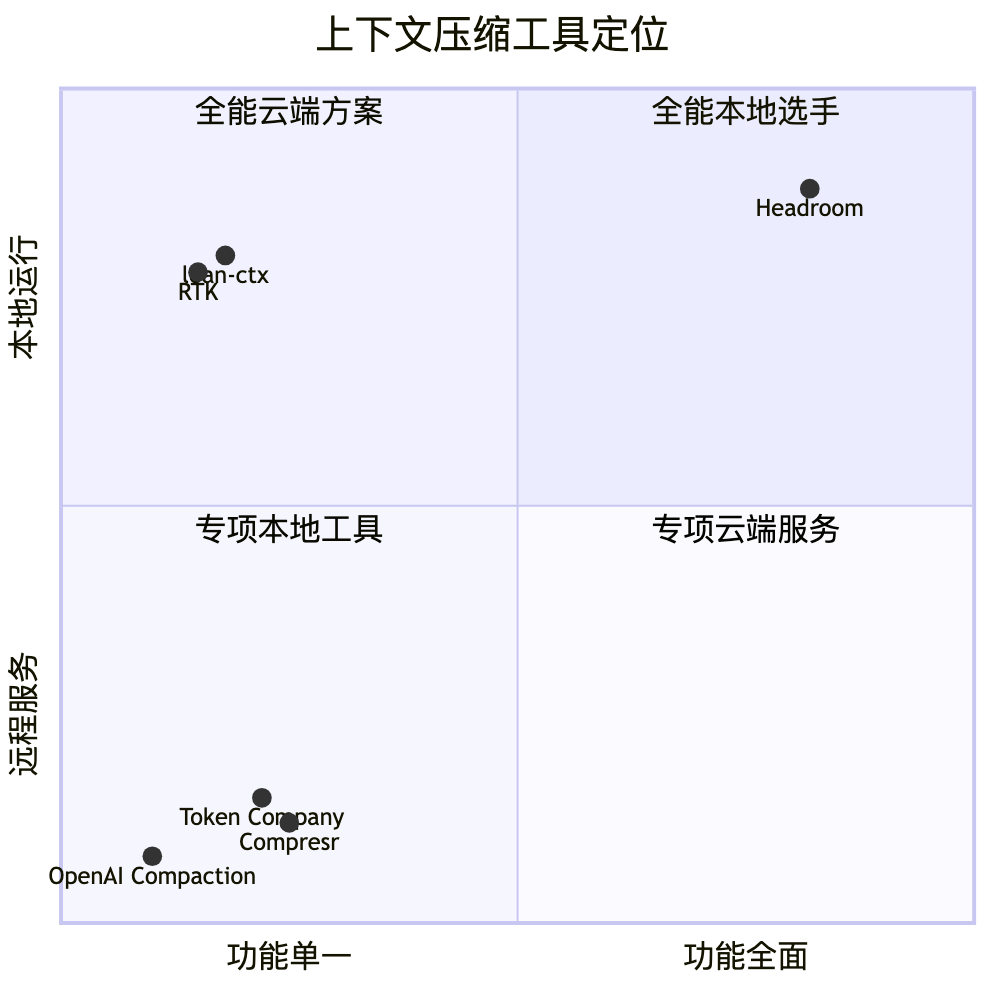
RTK 和 lean-ctx 专做 CLI 输出,本地速度快。Compresr 和 Token Company 是云端 API——数据得发到别人服务器。OpenAI 的原生方案只压对话历史,且不出 OpenAI 生态。
Headroom 是唯一一个把全内容类型 + 本地 + 可逆 + 跨 agent 记忆 + 多框架全打包的方案。这不是「功能多」——维度就不一样。
◆ 生态版图:哪儿都能插一脚
接入方式多到有点奢侈:
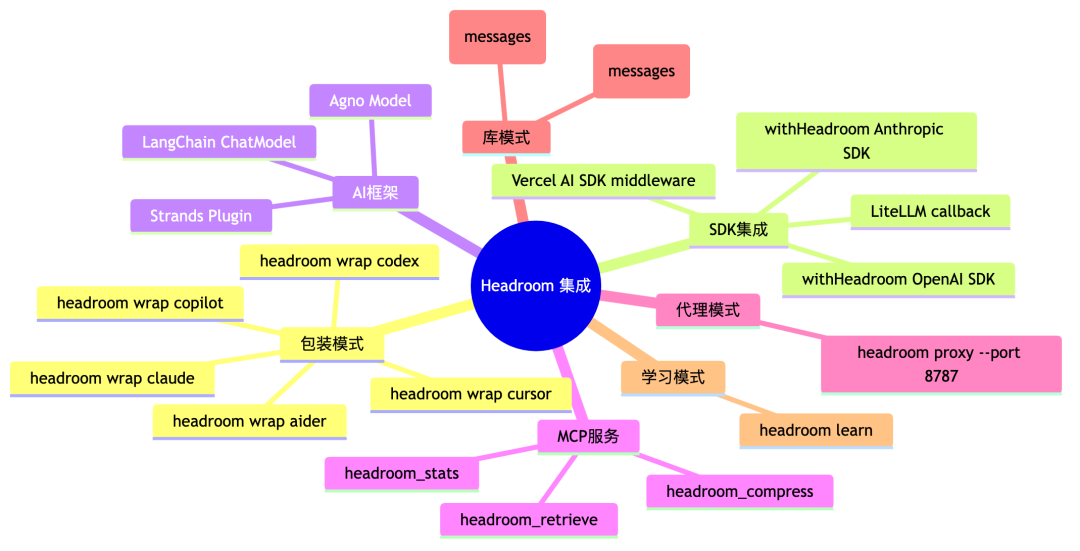
不管你在用什么、怎么用,总有一条路能接进去。最低门槛是 headroom proxy——起一个本地代理,零改动。
headroom learn 是个暗器:翻失败的 agent 历史,把修正自动写进 CLAUDE.md / AGENTS.md。用越多,上下文配置越聪明。agent 本身没变,是它吃了教训。
◆ 5 个月,153 个版本
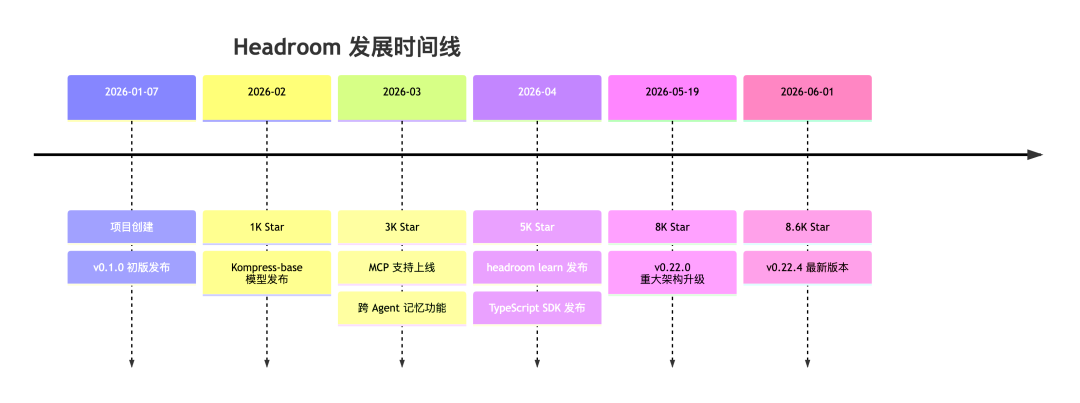
1 月 7 日到今天——不到 150 天。153 个 tag,1,397 次提交,164 个分支。
核心作者 chopratejas 930 次提交,JerrettDavis 250 次,gglucass 66,adryanev 34。加十几个社区贡献者。chopratejas 扛了 67% 的代码量,但团队在成型。
迭代节奏极快:5 月中旬到 6 月初两周发了 5 个版本(v0.21.38 → v0.22.4)。项目还有个公开的 REALIGNMENT 计划——40 个 PR 分 9 个阶段。不是蒙眼狂奔,有路线图。
◆ 该用和不该用的时候
如果你的情况是:
-
天天泡在 coding agent 里,token 账单不是小数目
-
Claude Code + Codex + Cursor 混着用,上下文对不上
-
代码不想发到第三方服务器做压缩
-
偶尔 LLM 确实需要看原始内容(CCR 能救急)
那就装上。几分钟的事。
如果你只是:
-
偶尔聊天,不涉及大量工具调用
-
沙箱环境跑不了本地进程
-
已经深度挂在某个 provider 的原生方案上,单一 agent 够用
那 Headroom 的价值你可能感受不到。它解决的是高频 + 跨 agent 的痛点,低频场景不值得多一个依赖。
◆ 问题,不是没有
单点风险 — chopratejas 占了 67% 的提交。如果核心维护者停手,速度会骤降。
版本还在 0.x — 0.22.4 的 API 不是铁板。重度集成前自己掂量。
模型 600MB — 不算小。不想背的话 kompress-small 279MB。
压缩要算力 — 每天一二十次问答就别折腾了,省下来的 token 不够填压缩的开销。
◆ 最后几句
都在卷更大窗口、更强推理、更快响应。
没人卷一件事——信息进 LLM 之前,能不能先筛一遍。
Headroom 就是搞这个的。不管 agent 是谁,不管模型叫什么。省掉 LLM 不该看的东西,空出来的 token 用在你最需要深度的地方。
⭐️推荐:

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)