AI Agent时代如何打造高质量软件?
质量是系统工程,测试不是唯一环节”——在AI Agent时代非但没有过时,反而被赋予了全新的紧迫性。
如果说传统软件质量保障是在和“人的有限性”作斗争,那么AI Agent时代,我们面对的是“机器的无限性”带来的系统性风险。这是一场新的战争,需要全新的打法。
一、AI时代的悖论:代码“更好”了,线上却更“糟”了

New Relic在2026年发布的一份报告揭示了一个令人不安的真相:94%的技术领导者认为AI生成的代码在评审时质量高于人类编写的代码,但一旦部署上线,78%的团队报告生产事故反而增加了。
为什么会这样?答案藏在“评审时的质量”和“运行时的质量”之间的鸿沟里。
传统软件是确定性的——输入A,输出B,可预测、可枚举。而AI Agent底层是大语言模型(LLM),天生就是非确定性的——同一个问题问三次,可能得到三个不同的答案,调用三种不同的工具,走三条完全不同的推理路径。
更棘手的是AI Agent的决策链路:工具选择、参数构造、结果合成,每一个环节都可能出错。传统测试只关注最终输出是否正确,好比考试只看总分不看各科成绩——总分及格了,你可能都不知道数学其实挂了。
Gartner在2025年的炒作周期中将AI Agent置于“ inflated expectations”(期望膨胀期)的顶峰,明确指出多Agent工作流和模型的非确定性可能引发级联故障。
用一个比喻:传统软件像一辆精心调校的汽车,而AI Agent像一个刚拿驾照的新手司机——它可能在某些路段开得比老司机还流畅,但也可能在完全意想不到的地方突然失控。
这种“失控”不是bug,而是AI Agent的“天性” 。如果还用传统测试方法去应对,无异于用体温计去测地震。
质量保障的思维必须从“验证正确性”升级为“管理不确定性” 。
二、Agent-CI:把质量门禁装进AI的“大脑”
面对这个新挑战,行业正在经历一场从“人机协同(Copilot)”到“AI自主(Agent)”的范式革命。传统的CI/CD流水线正在被“Agent-CI”重构。
具体怎么做?可以借鉴微软GitHub Copilot Agents团队的做法——“三阶验证门禁”:
第一关:设计阶段——用AI审AI
用LLM-based Spec Validator自动检测Prompt工程文档中的逻辑矛盾。比如,系统同时要求Agent“绝对客观”又“增强用户情绪共鸣”——这种矛盾人类可能看不出来,但AI能精准识别。
第二关:开发阶段——用沙箱隔离风险
集成RAG沙箱,强制所有检索增强操作在隔离的知识库中完成测试,阻断“生产知识污染”。简单说,就是让AI Agent先在“模拟考场”里练习,考合格了再进“真实考场”。
第三关:部署前——用“混沌测试”模拟故障
运行“混沌智能体测试”(Chaos Agent Testing),模拟API抖动、向量库降维、Token截断等27类故障,验证AI Agent在极端情况下的恢复策略是否有效。
这套流程已经实现了92%的自动化,但人工审核仍然聚焦在最关键的地方——比如医疗建议、法律咨询等场景中,AI Agent的首次响应是否符合预设的伦理原则。
质量门禁不再是“有没有bug”,而是“AI Agent的行为是否可信” 。
三、你不是在写测试脚本,你是在用AI运行测试
如果你还认为测试工程师的工作是“写脚本、跑用例、报bug”,那么AI Agent时代会把你甩得很远。
未来的测试专家不再是执行者,而是“AI训练师”和“质量策略架构师” 。
什么意思?苹果公司的一个研究案例很能说明问题。苹果设计了一个由六个专业AI智能体组成的协同系统,分别负责法规遵从、历史案例分析、测试生成等任务。结果如何?
-
测试准确率从65%提升至95%
-
所需时间缩短了85%
-
Bug检测率提高了35%
测试人员不再是亲自去“找bug”,而是设计AI Agent去找bug,然后评估AI Agent找得对不对、全不全。
另一个例子:Harness平台上的Code Coverage Agent能自动分析代码仓库,识别测试覆盖缺口,自动生成单元测试,然后提交一个Pull Request供人工审核。开发人员不再需要手动写每一个测试用例,而是审核AI Agent写的测试用例。
你的角色从“操作工”变成了“教练” ——你不必亲自跑每一圈,但你要设计训练计划、评估表现、纠正偏差。
四、“Agent债务”:AI时代的新技术债
New Relic的报告提出了一个概念叫 “Agent债务”(Agent Debt) ——AI Agent生成的代码在评审时看起来完美,但其中隐藏着大量未经审查的架构逻辑,上线后会触发生产事故。
这就像一个人借了高利贷——短期内感觉资金充裕(开发速度快),但利息(线上事故、修复成本)会越滚越大。
数据显示:
-
86% 的团队报告资深员工修复AI代码的时间增加了
-
74% 的团队报告至少有25%的AI代码需要大量返工
-
82% 的团队在过去6个月内经历过至少一次由AI生成代码引发的生产故障
-
62% 的技术领导者承认,他们的工程团队经常信任AI生成的代码,不经过逐行人工验证就直接上线
这些数字说明一个问题:AI Agent让开发速度变快了,但质量风险并没有消失,只是被转移和隐藏了。
如何管理“Agent债务”?
第一,建立“可观测性优先”的编码原则。96%的技术领导者认为,在使用AI生成代码时,可观测性“非常重要”或“极其重要”。78%的团队现在会主动提示AI工具在生成的代码中包含日志、追踪和指标等遥测数据。让AI生成的代码从一开始就是“可观测的”,而不是事后补监控。
第二,用“证据驱动开发”替代“感觉驱动开发” 。AWS的AgentCore Evaluations服务提供了一个思路:修改Prompt之后,“感觉好了”不算数,数据提升了才算数。用量化指标替代直觉判断,多维度评估AI Agent的每个环节——工具选择准不准?参数构造对不对?回答质量高不高?
第三,保持“人类在环”(Human-in-the-Loop) 。即使AI Agent再智能,关键决策点——尤其是涉及伦理、安全、合规的场景——必须有人类审核。AI Agent是副驾驶,不是自动驾驶。
五、如何实现AI测试平台?
上面介绍的都是国外的实践,头脑风暴可以,但实际使用不能照抄。
下面是我的分析,1个AI agent自动化测试应有的功能。
用户上传PRD文档或接口文档(OpenAPI/Swagger),系统自动:
- 使用LLM理解文档内容,检查PRD是否有歧义、逻辑矛盾
- 生成功能测试用例(functional/boundary/exception)
- 生成API测试用例(仅从API文档生成)
- 自动生成pytest脚本(API接口测试用例)
- 执行测试并保存结果
- AI分析测试失败原因
- 测试报告
用户可以描述真实场景(如"用户在下单高峰期反复取消订单"),系统会:
- 生成测试策略(strategy)
- AI选择相关测试用例 + 补充新用例
- 支持手动标记功能测试结果
- 支持API测试自动执行
- 生成综合报告(手动+API+AI分析)
Bug知识库(RAG)
- AI发现的缺陷CRUD管理(标题/描述/标签/严重程度/模块)
- 混合检索:关键词匹配 + 向量余弦相似度加权融合
- 生成测试用例时自动检索相关缺陷,注入LLM提示词
- 带缺陷上下文的Prompt模板(中英文PRD+OpenAPI)
- 前端管理页面(表格/弹窗表单/国际化)
高级功能
- RAG知识库 测试规范、常见bug知识库,辅助AI生成更准确的用例
- LangGraph Agent 更智能的测试agent,可调用多种工具(生成用例、执行测试、分析日志、生成报告)
- 性能测试 Locust或自研性能测试工具,生成性能测试用例
- UI自动化测试 集成Playwright,支持Web UI自动化测试
- 测试用例版本管理 记录用例变更历史,支持版本对比
- 团队协作 多用户协作,权限管理
现在LLM加agent tools可以让我们实现上面的功能,比如:claude code、cursor等。
注意:AI测试平台本身也得测试,建议在团队中先使用,获取真实反馈后,让agent自动修改代码。
总结:从“守门员”到“架构师”
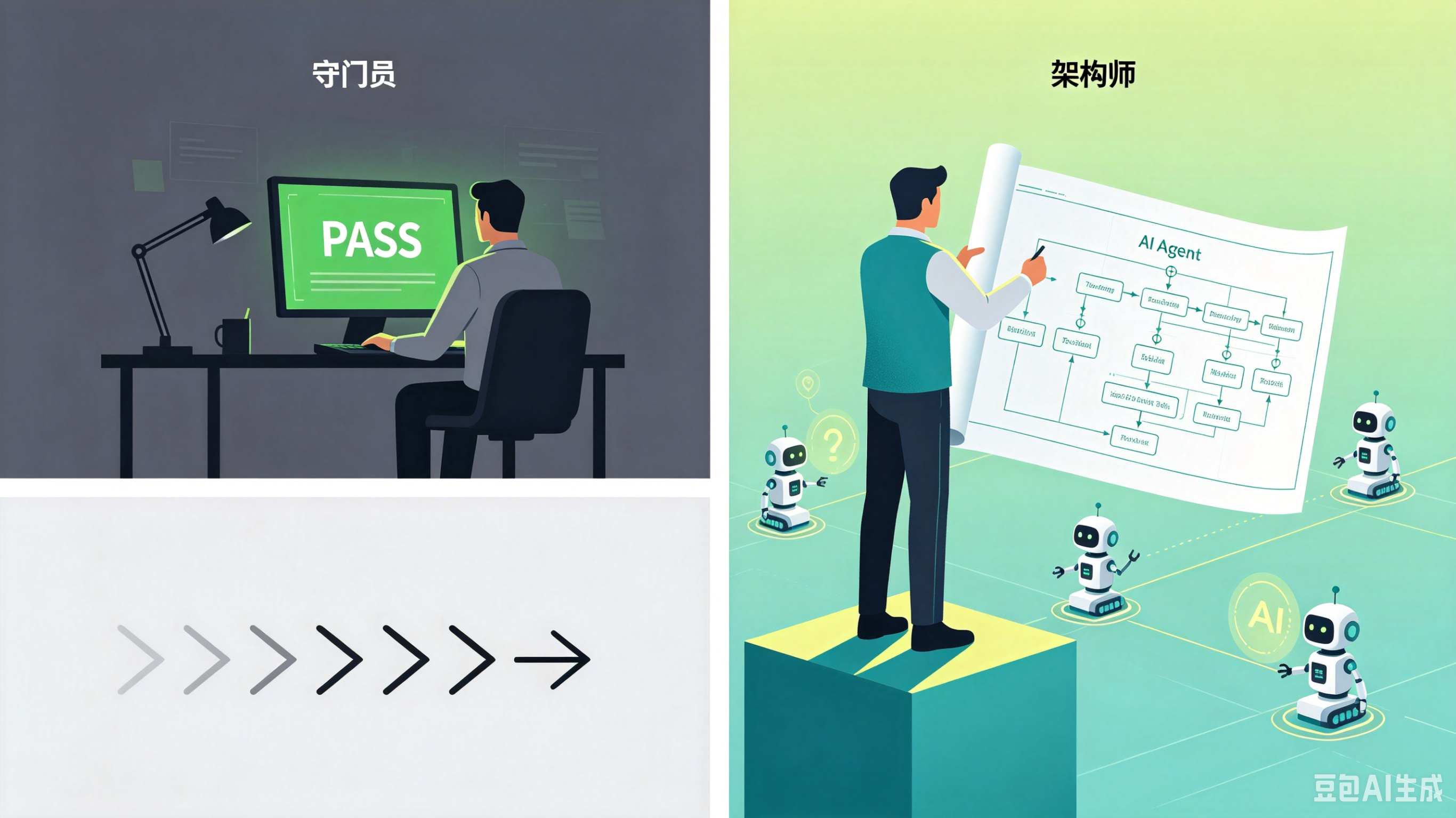
质量是系统工程,测试不是唯一环节。
当开发人员使用AI生成代码,测试人员也得用AI应对这种挑战。
也意味着团队对测试人员提出了新的要求:测试的速度要跟上AI生成的代码速度!
在AI Agent时代,这句话需要加一个注脚:质量保障的战场从“代码层面”扩展到了“行为层面” 。我们不仅要问“代码写得对不对”,还要问“AI Agent做得对不对、该不该这么做”。
未来的软件质量保障团队,不再是在最后一关“守门”的人,而是:
-
PRD阶段,用AI验证Prompt工程文档的逻辑一致性
-
开发阶段,用AI Agent自动生成单元测试、识别覆盖缺口
-
测试阶段,用AI Agent自动生成功能测试用例、自动化测试脚本、bug根因
-
预发验收阶段,Chaos Agent Testing、验证恢复策略
-
上线后,用可观测性数据持续监控AI Agent的行为
你不是在被AI取代,而是在被AI赋能为“质量架构师” 。你的工作从“找bug”升级为“设计质量保障系统”——这个系统里,AI Agent是你的队友,而不是你的替代品。
不是“没有人做测试”,而是“测试不再需要人亲自动手”——人负责设计策略、训练AI、审核结果、管理风险。
这是次跃迁。跃过去了,你就是AI时代的质量架构师!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)