1Agentic AI 工作流入门
1Agentic AI 工作流入门
1. Agentic AI 工作流入门
1.1 什么是Agentic AI
"非智能体"工作流是 zero-shot 模式:用户给一个 prompt,LLM 一次性完成整个任务,中间不回头修改。
Agentic AI 工作流将复杂任务拆解为多个步骤,由一个或多个 LLM 逐步执行。两种模式的差异:
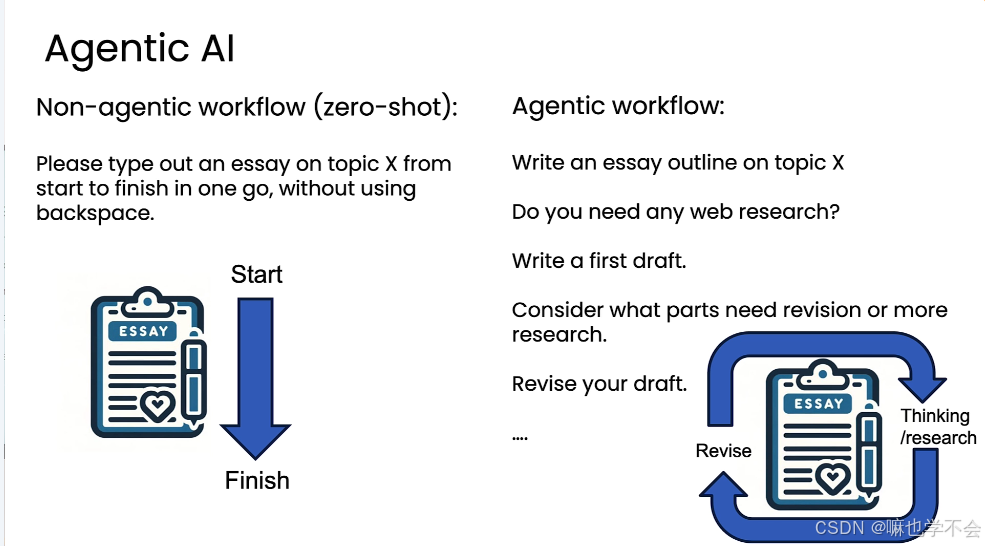
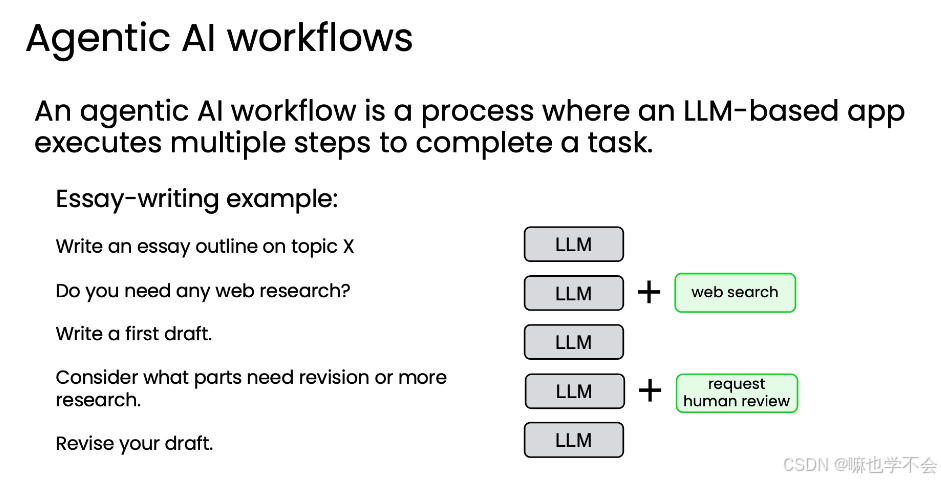
以写文章为例,agentic 工作流的步骤:写大纲→判断是否需要搜索→执行搜索→写初稿→反思修订→最终定稿。步骤更多,但输出质量显著高于 zero-shot。
1.2 自主性等级
不同系统的自主程度不同。用"Agentic"(形容词)而非"Agent"(名词)描述更准确——一个系统可以"具有某种程度的智能体特性",而不必纠结它是否"足够自主"。
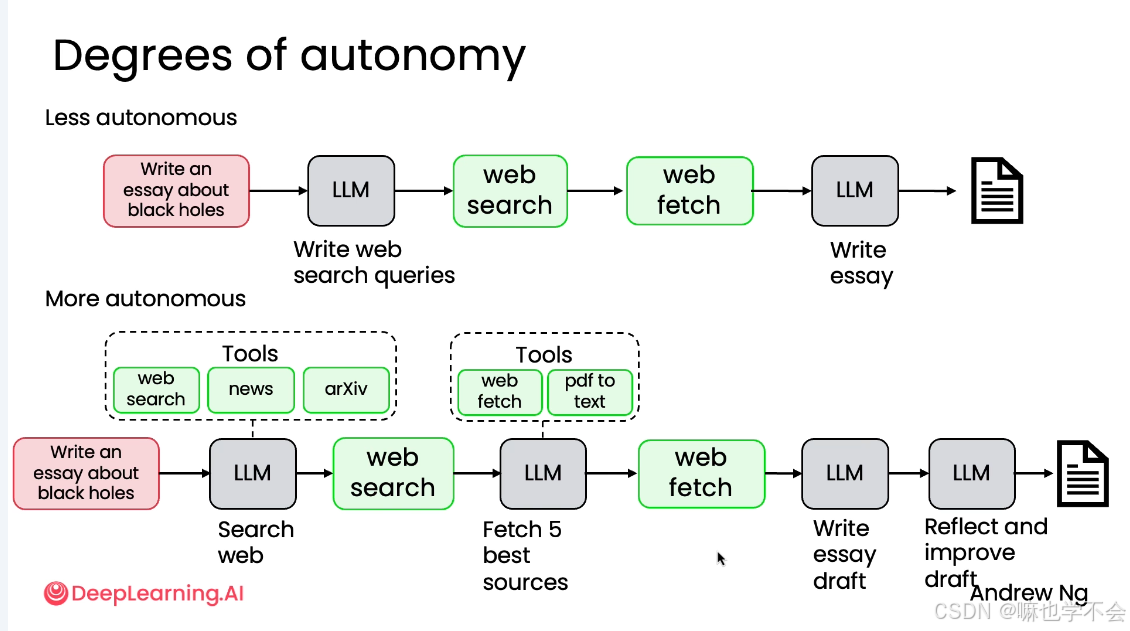
低自主性:所有步骤预先设定,工具调用硬编码,模型只负责生成文本。比如"写黑洞论文",工程师预先写好流程:LLM 生成搜索词→调搜索 API→抓取网页→LLM 整合成文。模型不参与决策。
高自主性:模型自主决定步骤顺序、选择工具、甚至创建新工具。同样是"写黑洞论文",模型自己决定用 web search 还是 arXiv,自己判断哪些来源更可靠,写完初稿后自己反思并改进。
1.3 为什么需要Agentic AI
| 优势 | 说明 |
|---|---|
| 性能跃升 | 工作流带来的提升大于模型版本升级 |
| 并行加速 | 多实例并行执行,总耗时比人类顺序操作更短 |
| 模块化 | 工具和模型都可替换,灵活组合 |
HumanEval 编码测试数据:
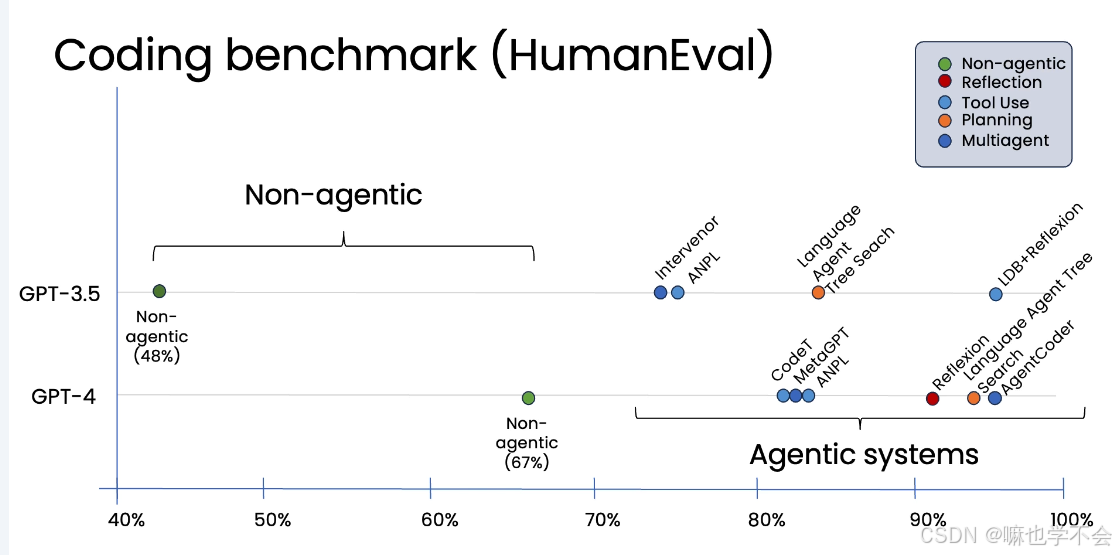
GPT-3.5 zero-shot 正确率约 48%,GPT-4 zero-shot 约 67%。但将 GPT-3.5 放入 agentic 工作流(写代码→反思→改进),性能可以达到甚至超过 GPT-4 zero-shot 的水平。
并行加速的原理:人类写论文是顺序操作——搜索、阅读、再搜索、再阅读。Agentic 工作流可以同时启动多个 LLM 实例并行搜索、并行抓取网页,最后汇总。步骤更多,但总耗时更短。
模块化意味着工作流中的工具和模型都可以替换。搜索环节可以从 Google 换成 Bing 或专业搜索引擎;不同步骤可以用不同模型,选择该步骤表现最好的那个。
1.4 应用场景速览
| 场景 | 难度 | 核心能力 |
|---|---|---|
| 发票处理 | 低 | PDF 解析、字段提取、数据库写入 |
| 客户邮件回复 | 低 | 信息提取、数据库查询、邮件生成 |
| 通用客服代理 | 中 | 动态规划 API 调用、条件判断 |
| 视觉操作 | 高 | 浏览器操作、错误恢复、多模态理解 |
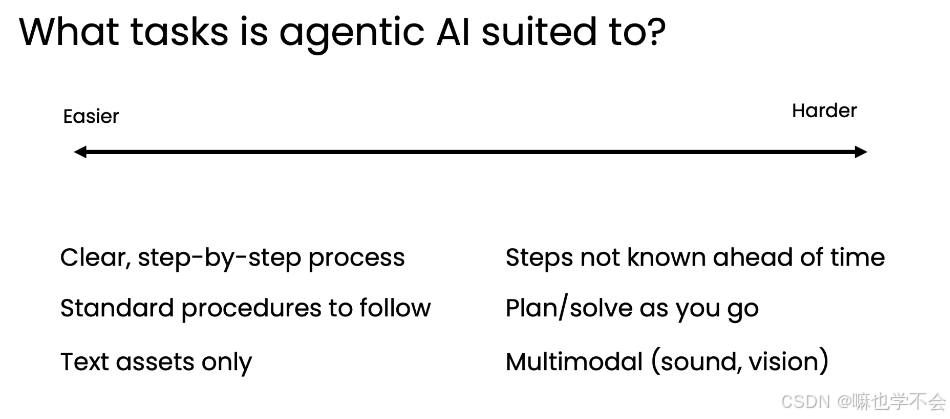
发票处理:PDF 转文本→LLM 提取字段(开票方、金额、到期日)→调用工具写入数据库。将财务人员的重复录入工作自动化。
客户邮件回复:LLM 提取邮件关键信息→查询订单数据库→起草回复→人工审核→发送。保留人工审核环节确保准确性。
通用客服代理:处理开放式问题(库存查询、退货处理),模型需要动态规划 API 调用顺序,根据条件判断后续行动。
视觉操作:让 AI 像人类一样操作浏览器——打开网页、填表单、点击按钮。遇到错误时自主切换策略。目前不稳定,但在金融、医疗等场景潜力大。
1.5 任务分解
任务分解是构建 agentic 工作流的核心技能。
1.5.1 方法论
- 观察人类行为:如果一个人要完成这个任务,他会怎么做?
- 拆解步骤:将任务拆成独立、清晰的子步骤
- 评估可行性:每个子步骤能否用 LLM 或工具实现?
- 迭代优化:效果不好就继续拆细
核心原则:如果某一步效果不好,就把它再拆成更小的子步骤。
1.5.2 实例:写深度论文
三种方法的对比:

方法一(1步) :直接让 LLM 写→内容表面化,缺乏深度。
方法三(5步) :写大纲→网络搜索→写初稿→反思哪些部分需要修订→修订草稿。模拟人类"写作-反思-修改"循环,输出质量显著提高。
1.5.3 实例:回复客户投诉邮件
- 提取关键信息:LLM 解析邮件,提取发件人、订单号、商品、问题
- 查询订单数据库:调用
orders database query工具核实订单 - 撰写并发送回复:LLM 根据信息起草邮件,调用
send emailAPI 发送
1.5.4 实例:发票信息提取
- 查找所需信息:LLM 分析文本,识别账单方、地址、金额、日期
- 保存到数据库:调用
update database工具写入
只有两步,但体现了任务分解的本质:将目标拆解为可执行的动作。
1.5.5 构建模块
所有 agentic 工作流都由两类构件组成:
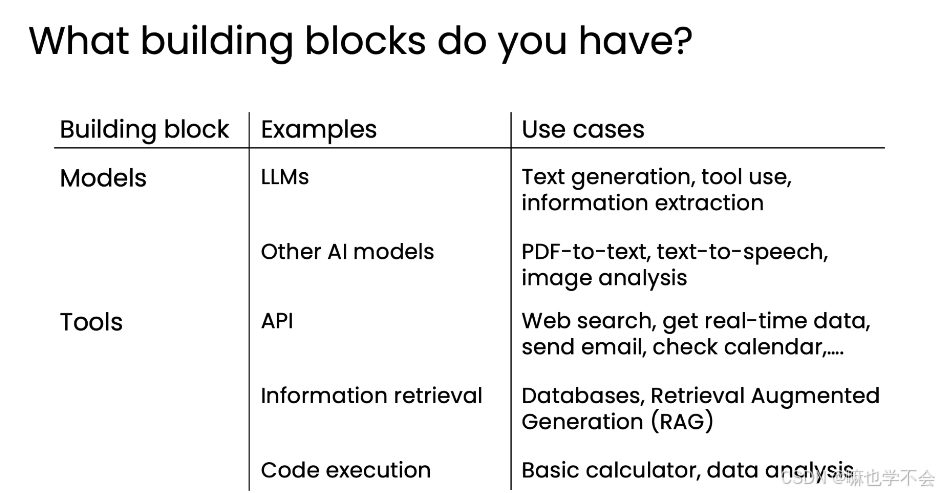
- 模型:LLM 负责文本生成、工具决策、信息提取;其他 AI 模型处理非文本数据(PDF 转文本、语音合成、图像分析)
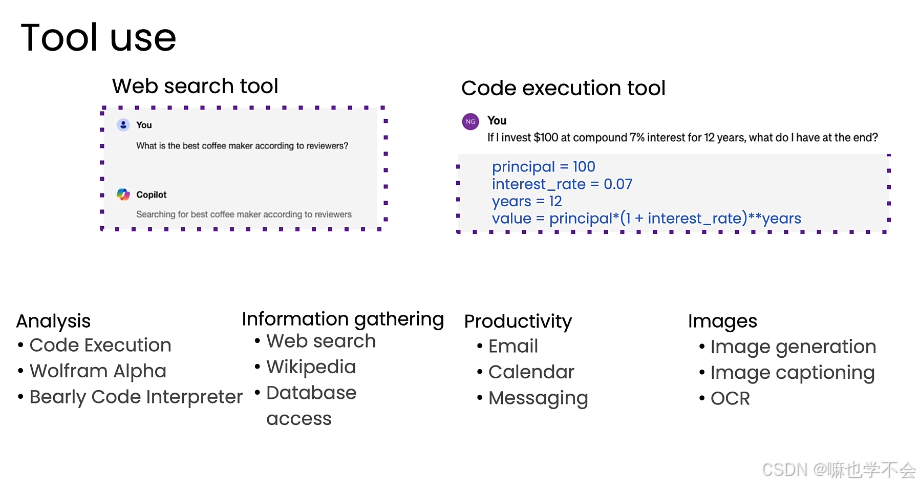
- 工具:API 执行外部服务(搜索、邮件、日历);信息检索从数据库获取数据;代码执行处理复杂计算
1.5.6 设计原则
- 从简单开始:先做 1-3 步的原型,再逐步扩展
- 模块化:每个步骤尽量独立、可复用
- 容错与反馈:加入检查、评审步骤,避免错误累积
- 持续迭代:没有一步到位的完美工作流
1.6 评估(Evals)
评估是 Andrew Ng 反复强调的核心能力——能否进行严格、有纪律的评估,是区分"做得好"与"做得差"的最大预测因素。
1.6.1 评估方法论
先构建,再观察,后评估:不要试图在构建前设计所有评估标准。先做出初步版本,手动检查输出,找到希望改进的地方。
识别低质量输出:比如客服 agent 回复"我们比竞争对手 CompCo 强多了"——这种在构建前难以预见的问题,需要实际运行后才能发现。

构建客观指标:针对识别出的问题,创建可量化的追踪指标。比如定义"提及竞争对手"为错误类型,编写脚本自动扫描所有输出,统计提及次数。

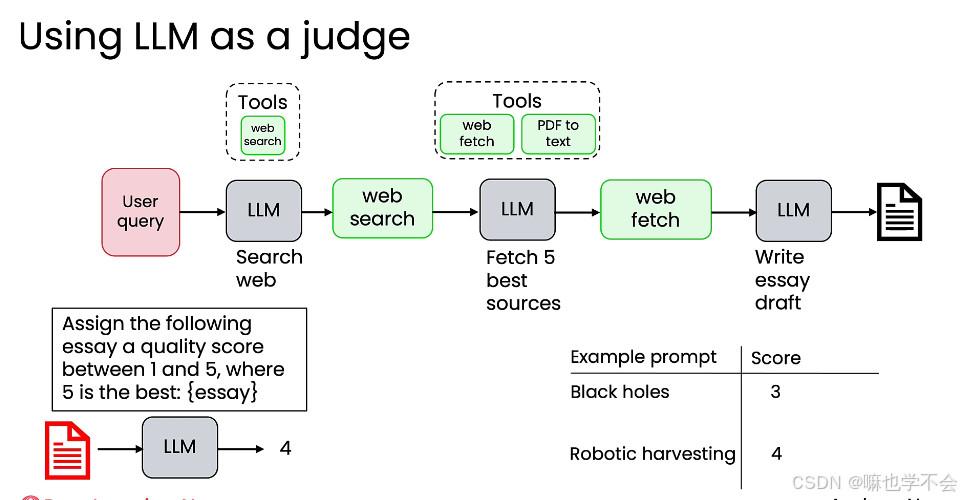
LLM-as-Judge:当评估标准主观(如论文质量)时,用另一个 LLM 作为裁判,设计评分提示词对输出打分(1-5 分)。
1.6.2 评估类型

| 类型 | 衡量对象 | 示例 |
|---|---|---|
| 端到端评估 | 整个智能体的最终输出 | 论文最终得分 |
| 组件级评估 | 单个步骤的输出质量 | "提取关键信息"的准确性 |
1.7 四大设计模式
Agentic 工作流的核心是将复杂任务分解为"构建模块",通过设计模式组合起来。
| 模式 | 核心思想 | 详见 |
|---|---|---|
| 反思 | 模型对输出进行检查、评估、改进 | 第2章 |
| 工具使用 | 赋予模型调用外部工具的能力 | 第3章 |
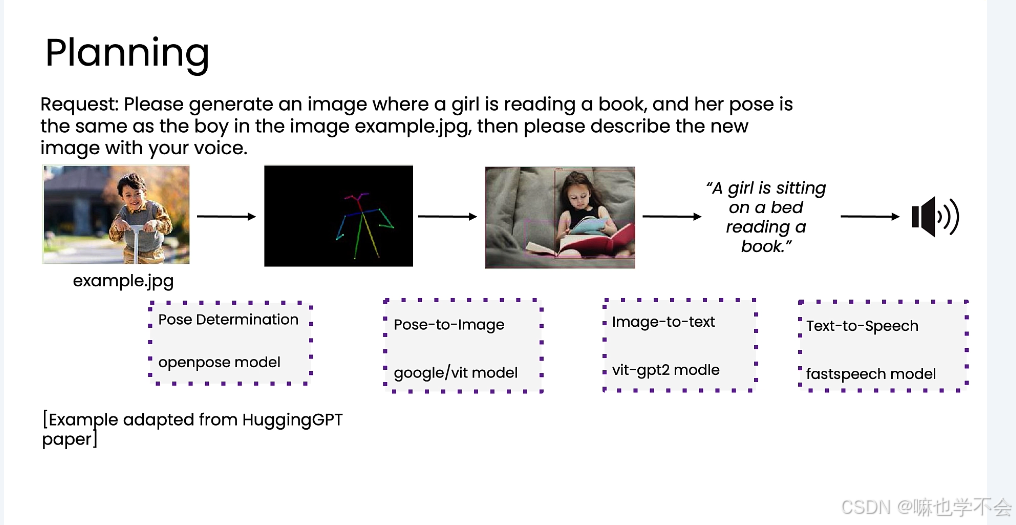
| 规划 | 模型自主决定任务步骤序列 | 第5章 |
| 多智能体 | 多个智能体协同工作 | 第5章 |


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)