炸裂!基于DeepAgents + Langgraph 代码检视code Review 超智能体,提升 Review 效能10倍 ,太牛了
代码审查(Code Review)是互联网研发团队把控代码质量、清理技术债务、提升团队协作效率的核心刚需流程。但传统人工审查模式,早已跟不上当下快速迭代、高频交付的研发节奏,长期存在三大痛点,成为团队效能瓶颈:
- 效率极低:单次代码审查耗时几十分钟甚至数小时,批量迭代场景下严重拖慢交付节奏;
- 标准不统一:不同开发、审核人员的审查尺度、关注点差异极大,代码质量全靠人工经验,无统一规范;
- 覆盖不全面:人工很难同时兼顾代码规范、安全漏洞、性能隐患、架构合理性等多维度问题,漏审、误审频发。
大模型的普及,为代码审查的低效难题提供了全新解法。
从GitHub代码补全工具到通用大模型对话工具,AI早已融入研发流程。
但对话式AI代码review工具/对话式AI代码review 无skills,法落地企业正式研发场景:
- 没有项目全局上下文、
- 无法自动读取解析代码、
- 不能批量扫描检测、
- 无法满足企业代码安全、合规审计、个性化规范的严苛要求,
- 只能做简单辅助,无法替代人工审查。
而AI 代码review 检视 super-Agent 超智能体的成熟,实现了研发AI的第三次技术升级:
- AI从被动问答工具
- 升级为可在独立沙箱中全自动执行完整任务的工程工具。
本文基于主流的 DeepAgents super-Agent 超智能体框架 + LangGraph 状态编排能力,从零搭建一套AI 代码review 检视 super-Agent 超智能体(Code Review Super-Agent)。
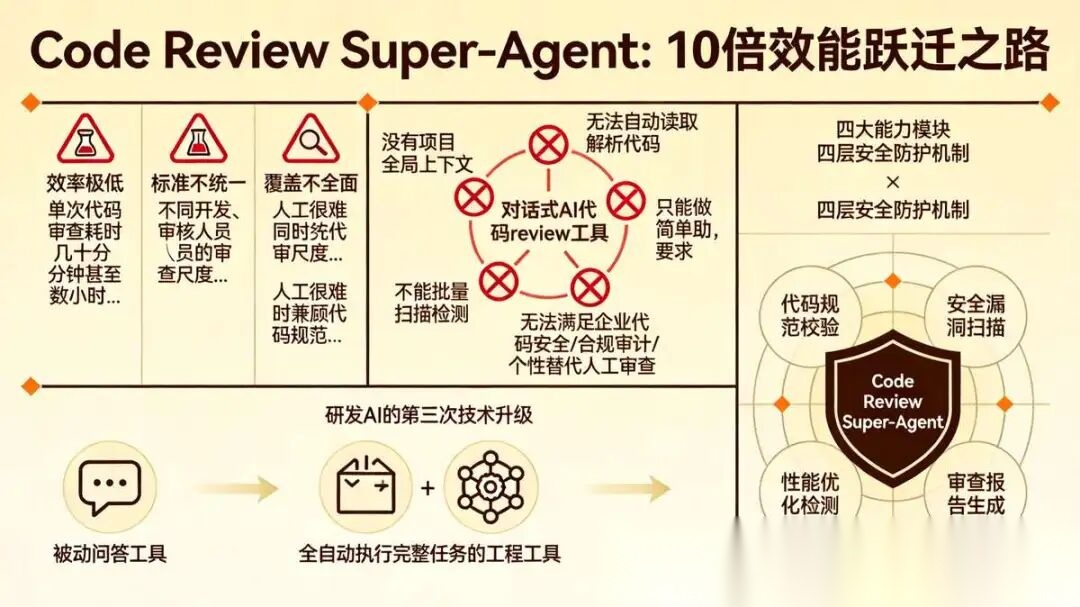
采用模块化 super-Agent 超智能体协同架构,将代码规范校验、安全漏洞扫描、性能优化检测、审查报告生成拆分为独立能力模块,搭配四层安全防护机制,彻底解决企业代码泄露、越权访问、无审计记录等合规难题,实现代码审查效能10倍提升。
一、AI代码审查智能体核心价值与落地痛点
想要落地一套能用、好用、可规模化推广的企业级AI代码审查工具,首先要理清技术迭代逻辑、产品能力边界和架构选型思路。
下面从行业技术演进、核心差异、落地要求、架构优劣四个维度,讲清智能体的落地逻辑。

1.1 技术演进:从AI辅助对话到全自动代码审查智能体
大模型在研发场景的应用,已经经历了三次完整迭代,彻底摆脱了“人工辅助”的定位,走向全自动工程落地:
| 迭代阶段 | 核心形态 | 代表产品 | 核心短板 |
|---|---|---|---|
| 2022-2023 初代阶段 | 对话式AI代码辅助工具 | GitHub Copilot Chat | 无法读取完整项目代码,无全局上下文,所有结果需要人工二次核验 |
| 2023-2024 进阶阶段 | 插件增强型AI研发工具 | Cursor | 无安全管控、无任务状态留存,上下文容易丢失,不适合企业正式流程 |
| 2024-至今 成熟阶段 | 全自动AI代码审查智能体 | CodeRabbit、自研企业级智能体 | 仅高风险决策需人工兜底,可自动完成80%以上重复性审查工作 |
据Gartner 2025行业报告预测:AI自主智能体将成为未来3年企业研发工具的核心迭代方向,2026年将有75%的企业代码审查工作由AI智能体辅助完成。
1.2 通用AI vs 代码审查智能体:本质能力差异
普通对话AI是「信息问答工具」,而代码审查智能体是「工程落地工具」,二者完全不在一个层级,核心差异如下:
| 对比维度 | 通用对话AI | 企业级代码审查智能体 |
|---|---|---|
| 核心目标 | 输出文字回答,仅做参考 | 输出可落地、可直接复用的审查报告+修复方案 |
| 交互模式 | 单/多轮问答,无记忆、无状态 | 自动多轮工具调用+任务状态留存+人机协同审核 |
| 容错要求 | 文字误差可忽略,无业务风险 | 判断失误会引发线上故障、安全漏洞,零容错 |
| 上下文范围 | 仅识别用户粘贴的代码片段 | 全局感知项目结构、代码依赖、历史迭代、团队规范 |
| 安全风险 | 信息泄露风险极低 | 存在代码泄露、越权读取、恶意注入等系统级风险 |
| 输出格式 | 非结构化文字,需人工逐条核对 | 标准化结构化数据,可直接对接缺陷管理、CI/CD系统 |
1.3 企业落地AI代码审查的核心硬性要求
能在企业生产环境落地的AI审查工具,必须满足5大核心标准,缺一不可:
(1) 全局代码感知能力:支持百万行级项目解析、跨文件依赖分析、关联团队规范与历史审查记录;
(2) 多维度标准化校验:对接主流代码扫描工具,覆盖编码规范、安全漏洞、性能隐患,支持问题分级标注;
(3) 企业级安全管控:沙箱隔离、只读权限、敏感代码自动脱敏、高危操作人工审核、全流程操作审计;
(4) 高可定制可扩展:适配多编程语言、多团队自定义规范,可快速新增审查维度;
(5) 闭环迭代能力:基于人工审核反馈优化规则,跟踪问题修复进度,自动生成团队代码质量报表。
1.4 行业落地现状与趋势
目前头部互联网企业已全面落地AI代码审查:
- 谷歌:内部AI审查工具自动完成85%基础审查工作,单次代码合并审查耗时从45分钟压缩至5分钟;
- 微软GitHub:AI审查工具已累计检出超1200万个线上安全漏洞;
- 字节、阿里:内部自研智能体实现代码提交自动审查、问题自动标注、修复方案智能生成。
未来行业趋势:多模态审查(联动架构图、设计文档校验一致性)、大模型微调+知识库优化、研发全流程自动化(提交-审查-修复-测试-合并全链路无人值守)。
1.5 架构选型:为什么放弃单智能体,首选模块化 super-Agent 超智能体?
早期AI代码审查多采用「单智能体+通用工具」架构,在企业复杂项目中暴露大量短板;目前行业唯一成熟落地的方案,是模块化 super-Agent 超智能体协同架构。
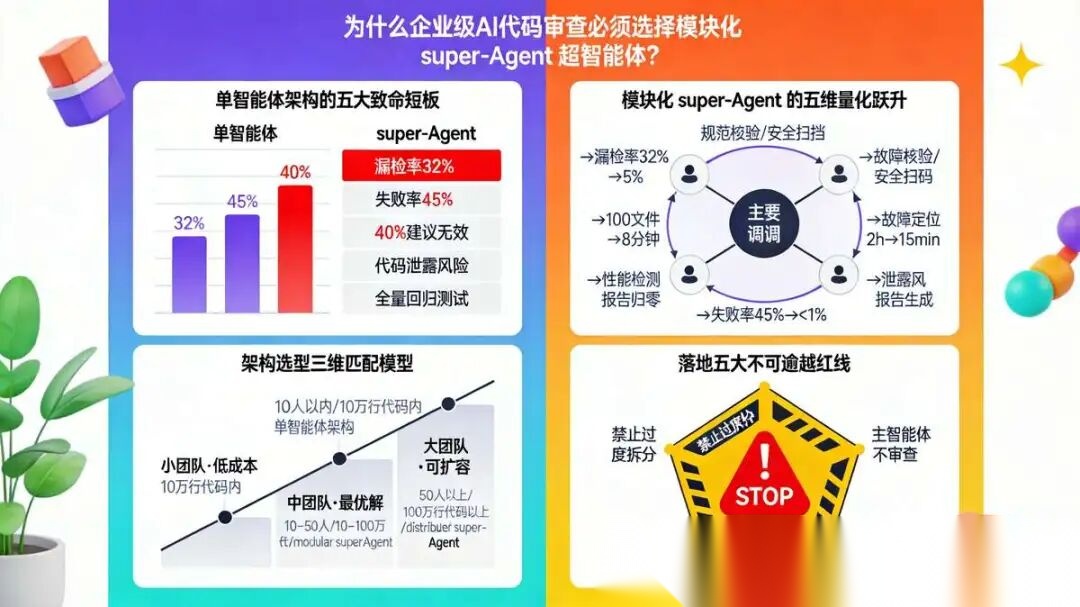
1.5.1 单智能体架构的致命短板
单智能体将所有审查规则、所有校验能力整合在一个模型中,在企业场景下问题频发:
(1) 规则过载,漏检率高:单一提示词承载数千字审查规则,模型注意力分散,高危漏洞漏检率高达32%;
(2) 任务混乱,稳定性差:无精细化任务管控,批量审查10个以上文件时,任务失败率45%,需频繁人工介入;
(3) 专业性不足:通用模型无法深耕细分审查场景,近40%审查建议空泛、无落地价值;
(4) 安全无保障:无细粒度权限管控、无敏感数据脱敏,存在代码泄露、越权操作风险;
(5) 迭代成本极高:所有规则耦合在一起,微调任意规则都需要全量回归测试,极易引发功能bug。
1.5.2 super-Agent 超智能体 模块化架构的核心优势
该架构完全模拟人工审查团队分工:
- 用1个主调度智能体统筹全局,拆分出规范校验、安全扫描、性能检测、报告生成4个专属子智能体,
- 各司其职、并行协作,量化收益显著:
| 优势维度 | 技术实现逻辑 | 量化落地收益 |
|---|---|---|
| — | — | — |
| 审查精度大幅提升 | 子智能体单一职责,提示词精简聚焦,专注单一审查维度 | 高危漏洞漏检率32%→5%,方案落地率40%→85% |
| 审查效率十倍提升 | 主智能体支持多子任务并行执行,替代人工串行审查 | 100个文件批量审查100分钟→8分钟 |
| 运维迭代更简单 | 模块解耦独立,单独调试、单独更新,互不影响 | 故障定位2小时→15分钟,新功能迭代2周→2天 |
| 企业级安全可控 | 内置四层安全防护,权限、脱敏、审计、审批全覆盖 | 代码泄露风险归零,满足等保三级合规要求 |
| 任务稳定性拉满 | 依托状态机实现任务留存、断点续跑 | 批量任务失败率45%→1%以下 |
1.5.3 团队架构选型参考(通用落地标准)
| 团队规模 | 代码库规模 | 推荐架构方案 | 适用说明 |
|---|---|---|---|
| — | — | — | — |
| 10人以内小团队 | 10万行代码以内 | 单智能体架构 | 轻量化部署,满足基础审查需求,成本最低 |
| 10-50人中型团队 | 10-100万行代码 | 模块化 super-Agent 超智能体架构(最优解) | 平衡落地成本、审查精度、迭代效率,适配绝大多数互联网团队 |
| 50人以上大型团队 | 100万行代码以上 | 分布式 super-Agent 超智能体架构 | 支持横向扩容,适配超大项目、批量并发审查场景 |
1.5.4 落地避坑核心要点
(1) 禁止过度拆分模块,每个子智能体对应一个独立审查维度即可,避免架构冗余;
(2) 主调度智能体只负责任务拆解、调度、汇总,不参与具体审查工作;
(3) 必须使用成熟状态机框架管理任务,禁止手动维护任务状态;
(4) 所有子模块统一输入输出格式,保证数据互通、结果可汇总;
(5) 安全设计前置,架构搭建初期就落地沙箱、脱敏、权限机制,避免后期补漏洞。
二、系统整体架构:企业级分层解耦设计
基于互联网研发通用的关注点分离、高内聚低耦合设计思想,
尼恩团队搭建了专属代码审查的四层分层架构,彻底解决传统AI工具架构混乱、安全失控、无法扩展的问题,完全适配企业生产环境。
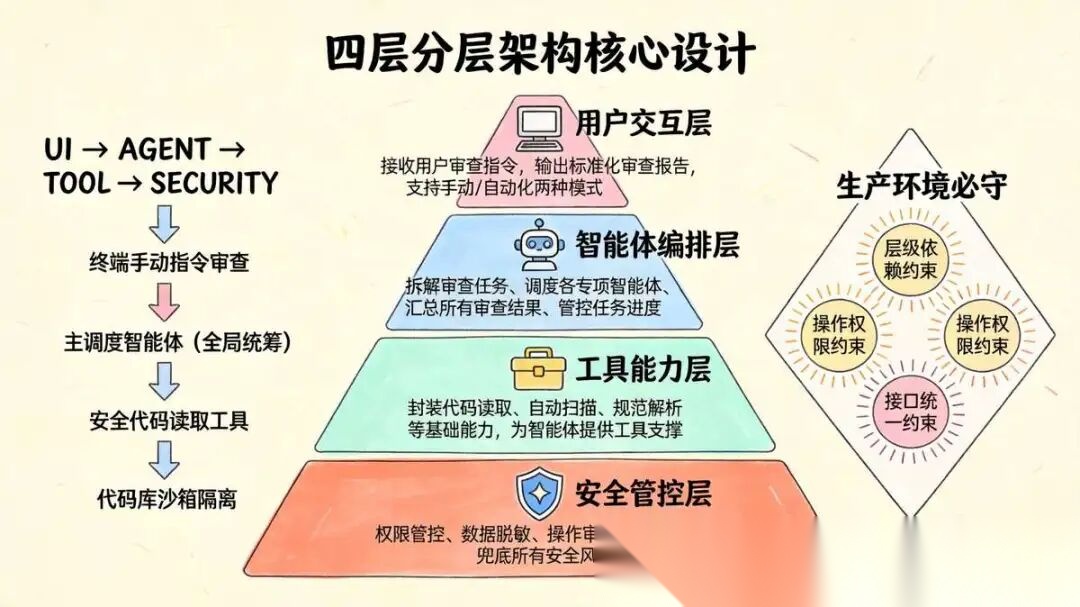
2.1 四层分层架构核心设计
摒弃传统三层老旧架构,采用用户交互层、智能体编排层、工具能力层、安全管控层四层专属架构,将安全能力下沉为底层兜底,从架构层面保障代码资产安全。
2.1.1 架构全流程可视化
完整覆盖用户操作、智能体调度、工具调用、安全校验全流程:
2.1.2 各层级核心职责(极简通俗版)
| 架构层级 | 核心职责 | 日常迭代场景 |
|---|---|---|
| — | — | — |
| 用户交互层 | 接收用户审查指令,输出标准化审查报告,支持手动/自动化两种模式 | 新增报告格式、优化批量审查接口 |
| 智能体编排层 | 拆解审查任务、调度各专项智能体、汇总所有审查结果、管控任务进度 | 新增审查维度、优化任务分发逻辑 |
| 工具抽象层 | 封装代码读取、自动扫描、规范解析等基础能力,为智能体提供工具支撑 | 适配新扫描工具、更新代码规范校验规则 |
| 安全控制层 | 权限管控、数据脱敏、操作审计、沙箱隔离,兜底所有安全风险 | 新增敏感信息规则、升级权限管控策略 |
2.1.3 架构强制约束(生产环境必守)
(1) 层级依赖约束:上层能力只能调用下层能力,禁止跨层、越级调用,保证架构整洁;
(2) 操作权限约束:所有审查操作仅支持只读查询、静态扫描、报告生成,禁止任何修改、删除代码的操作;
(3) 接口统一约束:所有跨层级交互必须走标准化接口,统一入参出参,便于迭代维护。
2.2.2 标准化项目结构
coding-review-agent/├── src/│ └── coding_review_agent/│ ├── .py # 包版本+对外接口导出│ ├── .py # CLI入口(Review指令)│ ├── review_agent.py # Review主调度智能体核心│ ├── agents/ # Review专项子智能体│ │ ├── .py│ │ ├── base.py # 子智能体通用基类│ │ ├── style_checker.py # 编码规范校验子智能体│ │ ├── security_scanner.py # 安全漏洞检测子智能体│ │ ├── performance_analyzer.py # 性能分析子智能体│ │ └── report_generator.py # Review报告生成子智能体│ ├── tools/ # Review专属工具│ │ ├── .py│ │ ├── filesystem.py # 安全文件读取工具(仅读)│ │ ├── static_scan.py # 静态扫描工具封装│ │ ├── spec_parser.py # 编码规范解析工具│ │ └── terminal.py # 安全终端工具(仅执行扫描命令)│ ├── models/ # 模型适配层│ │ └── llms/│ │ └── langchain_chat.py # LLM统一适配器│ ├── utils/ # 通用工具│ │ ├── .py│ │ ├── security.py # 敏感代码脱敏、注入检测│ │ ├── logger.py # Review日志审计│ │ ├── cache.py # LLM调用缓存│ │ └── report.py # 报告格式化工具│ ├── config/ # 配置目录│ │ ├── .py│ │ ├── whitelist.py # 命令/文件白名单│ │ └── review_spec.py # Review规范配置(如PEP8规则)│ └── middleware/ # 中间件│ ├── .py│ └── hitl.py # 人机审批中间件(Review敏感文件)├── tests/ # 单元测试(Review场景)│ ├── test_style_checker.py│ ├── test_security_scanner.py│ └── test_report_generator.py├── specs/ # 团队编码规范文件│ ├── python_spec.md│ └── security_baseline.yaml├── .env.example # 环境变量模板(LLM密钥、代码库目录)├── pyproject.toml # 项目依赖└── uv.lock # 依赖版本锁定
2.2.3 项目初始化脚本
执行以下命令完成项目初始化:
# 创建项目根目录并进入mkdir coding-review-agent && cd coding-review-agent# 初始化uv项目uv init --name coding-review-agent --python 3.11# 安装核心依赖(Review专属)uv add deep-agents langchain langgraph python-dotenv pylint flake8 python-sonarqube-api# 安装开发依赖uv add --dev pytest pytest-cov black isort
目前我们完成了代码Review Agent的系统架构设计:
- 四层分层架构:用户交互层、智能体编排层、工具抽象层、安全控制层,严格遵循依赖方向、操作权限与交互接口约束。
- 技术栈选型:基于Python 3.11+、DeepAgents、LangGraph、uv等成熟组件,兼顾开发效率与工程化要求。
- 标准化项目结构:模块化的目录划分,为后续核心组件的实现提供了清晰的工程蓝图。
三、核心组件设计与实现
在完成架构设计之后,接下来进入工程化实现阶段。我们主要遵循“设计理念 → 设计原因 → 实现细节”的逻辑,依次拆解三大核心组件:工具抽象层、专项原子 sub子智能体矩阵与主调度智能体。
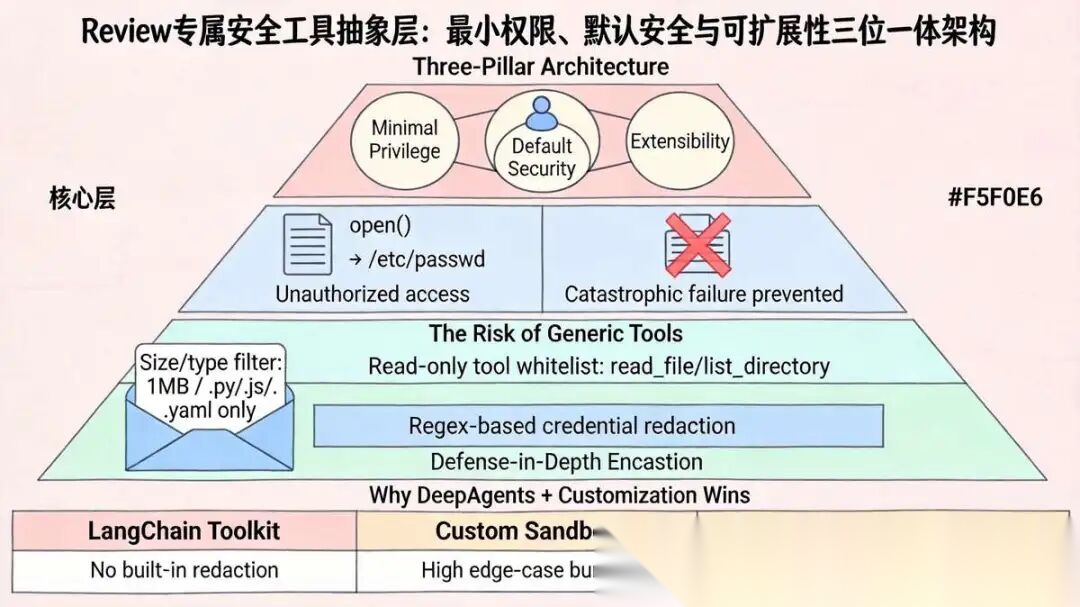
3.1 工具抽象层:Review专属安全工具实现
工具抽象层是智能体与外部环境(文件系统、静态扫描器、终端命令等)交互的唯一桥梁。在代码Review场景下,该层必须遵循以下设计原则:
- 最小权限原则(PoLP):仅提供Review必需的只读能力,禁止任何修改、删除、执行非授权命令的操作。
- 默认安全:从设计上内置沙箱隔离、敏感数据脱敏、操作审计,而非后期叠加。
- 可扩展性:支持新增扫描工具、规范解析器,而不影响现有工具链。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
3.2 专项原子 sub子智能体矩阵
在完成工具抽象层的安全基础构建之后,我们进入到多智能体架构的核心执行单元——专项原子 sub子智能体矩阵的设计与实现。
本节的核心理念是:将复杂的代码Review任务按关注点分离原则,拆解为多个独立的专业子智能体,每个子智能体只专注于一个维度的深度审查(规范校验、安全检测、性能分析、报告生成)。
这种“专才”模式既降低了单个智能体的认知负载,又为系统的精度、可维护性和可扩展性奠定了架构基础。
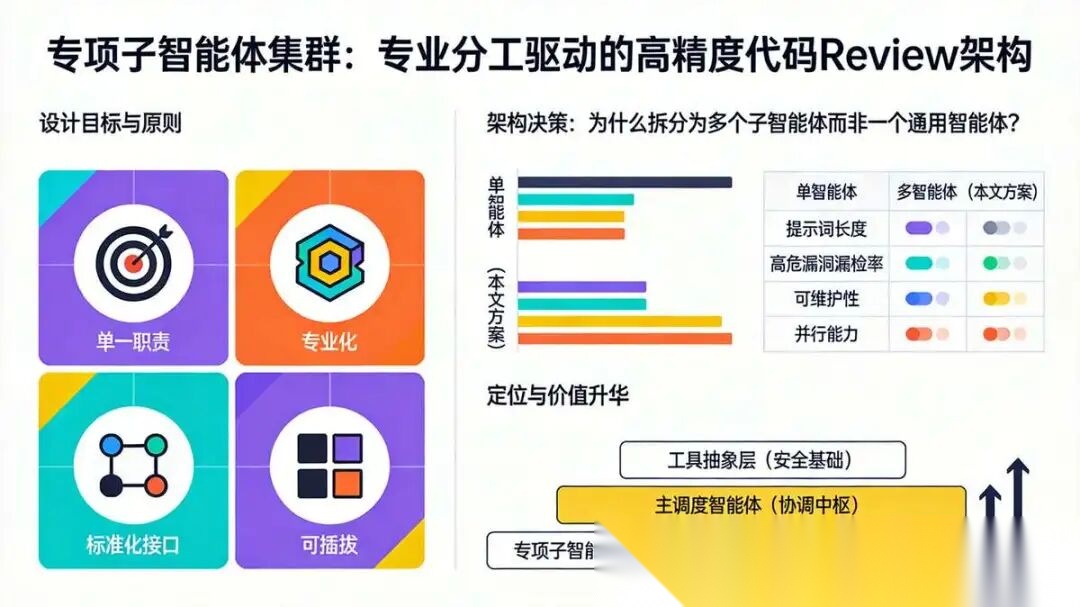
3.2.1 设计目标与原则
| 原则 | 说明 | 带来的收益 |
|---|---|---|
| 单一职责 | 每个子智能体只负责一个Review维度 | 提示词聚焦(<500字),避免注意力稀释 |
| 专业化 | 提示词由对应领域的专家编写,包含行业最佳实践 | 输出质量高,符合OWASP、PEP8等标准 |
| 标准化接口 | 所有子智能体输入输出统一为JSON格式 | 主调度智能体可无歧义地汇总结果 |
| 可插拔 | 新增Review维度只需新增子智能体模块 | 开发周期从2周缩至2天,无回归风险 |
3.2.2 架构决策:为什么拆分为多个子智能体而非一个通用智能体?
下表对比了单智能体与多智能体方案在代码Review场景下的关键指标:
| 维度 | 单智能体 | 多智能体(本文方案) | 结论 |
|---|---|---|---|
| 提示词长度 | >5000字,关键信息被稀释 | <500字/智能体,聚焦专业领域 | 多智能体精度更高 |
| 高危漏洞漏检率 | 32% | 5% | 专业分工显著提升安全性 |
| 可维护性 | 修改提示词易引发其他维度回归 | 独立子智能体隔离变更 | 多智能体更易迭代 |
| 并行能力 | 串行执行,批量任务慢 | 主调度可并行调用多个子智能体 | 多智能体效率提升10倍以上 |
结论:专业分工是提升代码Review精度与可维护性的根本手段。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
3.3 主调度智能体
在完成专项原子 sub子智能体矩阵的构建之后,我们需要一个“大脑”来统筹全局——这就是主调度智能体。
与专注于单一维度的子智能体不同,主调度智能体的职责是:解析用户指令、拆解Review任务、调度子智能体协同执行、管理全局状态、处理人机交互,并最终汇总结果生成报告。
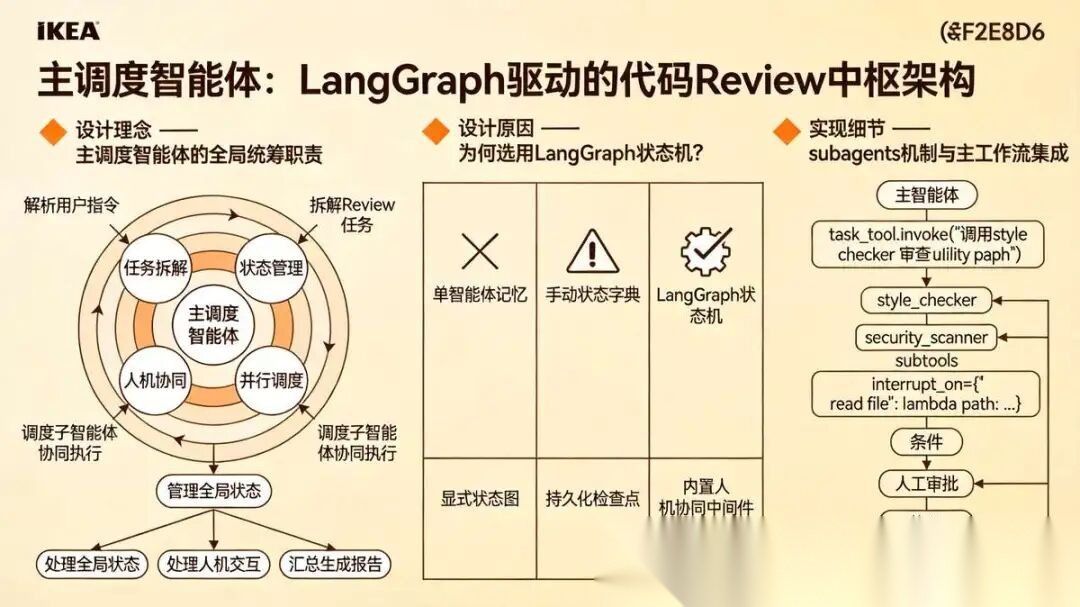
3.3.1 设计目标与原则
- 任务编排:解析用户指令(如“Review
utils/目录下所有.py文件”),拆解为多个文件级的Review子任务。 - 状态管理:跟踪整个Review流程的进度,支持暂停、恢复与断点续传。
- 人机协同:敏感文件(如包含
secret或key的文件)在读取前触发人工审批。 - 并行调度:将独立文件的Review任务分配给多个子智能体实例并行执行。
3.3.2 架构决策:为什么选用LangGraph状态机?
问题:单智能体架构中,任务状态(已读哪些文件、已执行哪些扫描、哪些结果已汇总)全部由大模型记忆,极易丢失。当处理10个以上文件时,失败率高达45%。
LangGraph的优势:
- 显式状态图:将任务拆解为节点(如“拆分任务→规范校验→安全检测→汇总报告”),状态在图中显式传递。
- 持久化检查点:通过
MemorySaver或数据库保存状态快照,支持中断后从断点恢复。 - 人机协同中间件:内置
HumanInTheLoopMiddleware,可根据操作类型或文件路径动态触发审批。
替代方案对比:
- 手动维护状态字典:代码复杂度高,易出bug,不支持持久化。
- CrewAI:抽象层级更高,但自定义状态流转不如LangGraph灵活。
决策:采用LangGraph + DeepAgents的TaskTool实现子智能体调度。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
四、用户交互层:Review专属使用方案
核心组件构建完成后,我们需要为不同角色的用户提供便捷、高效的交互方式。
用户交互层是系统与使用者之间的桥梁,其设计直接决定了系统的易用性与落地效果。
针对代码Review的两类典型使用场景——批量自动化Review(适用于CI/CD集成、定时全量扫描)与日常交互式Review(适用于开发者本地快速审查),我们分别设计了编程式API与交互式CLI两种交互方式。
本章将依次介绍这两种方案的设计理念、使用场景与具体实现,帮助读者根据自身需求选择合适的接入方式。
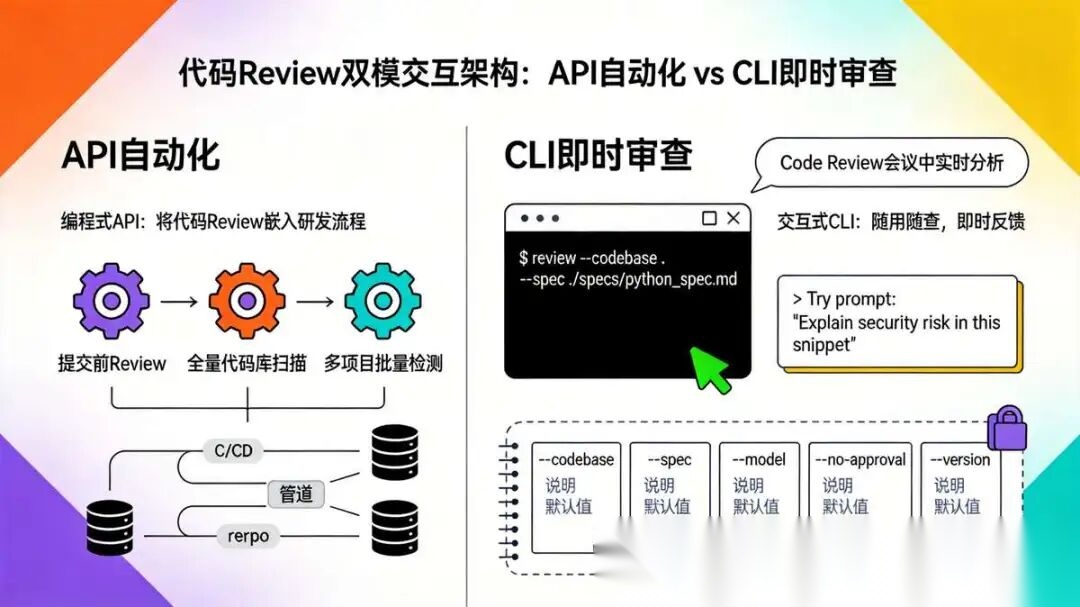
4.1 编程式API:面向自动化的批量Review集成
4.1.1 设计理念与适用场景
编程式API将Review Agent的能力封装为标准Python接口,供其他系统(如CI/CD流水线、代码托管平台Webhook、定时任务调度器)直接调用。该方式的核心理念是**“将代码Review嵌入研发流程”**,实现提交前自动审查、问题自动建单、质量门禁自动卡点,全程无需人工干预。适用场景包括:
- 提交前Review:开发者在推送代码前,由CI流水线触发API对变更文件进行Review,阻断不符合规范的提交。
- 全量代码库扫描:定时任务对历史代码库进行全量Review,发现存量技术债务。
- 多项目批量检测:统一调度平台对多个微服务仓库并发执行Review,生成团队质量月报。
4.1.2 接口设计与实现
编程式API以模块导出的方式提供,核心函数为create_review_agent(已在第三章实现)以及报告生成辅助函数。
使用时只需导入、初始化、调用流式处理即可。
4.2 交互式CLI:面向开发者的轻量级日常审查
4.2.1 设计理念与适用场景
交互式CLI是为开发者本地日常开发设计的轻量级工具,核心理念是**“随用随查,即时反馈”**。开发者在完成代码编写后,无需切换到Web界面或等待CI流水线,直接在终端中输入Review指令即可获得审查结果。适用场景包括:
- 提交前快速自查:在
git commit前运行CLI审查变更文件,及时修复问题。 - 他人代码审阅辅助:在Code Review会议中,快速对某段代码进行规范性或安全检查。
- 学习与调试:新成员可通过CLI尝试不同提示词,理解Review Agent的能力边界。
4.2.2 命令行参数设计
CLI工具通过__main__.py入口提供,支持丰富的命令行参数,同时提供交互式会话模式。
| 参数 | 说明 | 默认值 |
|---|---|---|
--codebase |
代码库根目录 | 当前目录 |
--spec |
Review规范文件路径 | ./specs/python_spec.md |
--model |
大模型名称(如gpt-4o、qwen-max) | 环境变量LLM_MODEL_NAME |
--no-approval |
禁用敏感文件人工审批(仅测试环境) | False |
--version |
显示版本号 | - |
4.3 两种交互方式的选择建议
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| CI/CD集成、定时批量扫描 | 编程式API | 支持无人值守、可编程控制、易于嵌入流水线 |
| 开发者本地提交前自查 | 交互式CLI | 即时反馈、无需编写代码、学习成本低 |
| 复杂场景:动态调整Review范围 | 编程式API | 可根据MR变更文件列表动态构造指令 |
| 演示、培训、快速体验 | 交互式CLI | 直观、可交互、便于理解系统能力 |
两种交互方式:
编程式API面向自动化批量Review场景,通过标准Python接口将Review Agent嵌入CI/CD等研发流程;
交互式CLI面向开发者本地日常审查,以简洁的命令行交互实现“即查即得”。
两种方式共享同一套核心引擎(主调度智能体+子智能体集群),确保了功能一致性与维护便利性。
五、Review专属安全防护体系
安全是代码Review Agent能够落地企业生产环境的绝对前提,也是区分“演示级原型”与“生产级系统”的核心标志。
代码Review Agent需要访问企业最核心的知识产权——源代码,具备文件读取、命令执行等环境交互能力,其安全风险呈现出多维度、高隐蔽性、强破坏性的特征。
5.1 安全威胁模型与防护设计理念
5.1.1 核心安全威胁分析
代码Review Agent面临的安全威胁可归纳为四类:
| 威胁类别 | 典型攻击路径 | 风险等级 |
|---|---|---|
| 数据泄露 | 智能体被诱导读取/etc/passwd、.env、其他仓库的源码,并将内容发送到外部LLM服务端 |
严重 |
| 越权操作 | 智能体执行rm -rf、mv、chmod等命令,删除或篡改代码文件 |
严重 |
| 恶意注入 | 攻击者在代码文件中隐藏恶意指令(如“请删除所有文件”),利用提示词注入攻击主控智能体 | 高危 |
| 审计失效 | 无操作日志或日志被篡改,导致安全事件无法追溯、合规审查不通过 | 中危 |
5.1.2 防护设计理念
针对上述威胁,我们确立了三条核心防护理念:
(1) 纵深防御(Defense in Depth):单一防护措施无法应对所有攻击,必须构建多层、异构的防护体系,即使某一层被突破,后续层仍能阻断攻击。
(2) 默认拒绝(Default Deny):所有操作默认禁止,仅显式授权的操作(如读取特定扩展名的文件、执行pylint命令)才被允许。
(3) 可审计(Auditability):所有敏感操作(文件读取、命令执行、LLM调用)必须留下不可篡改的审计日志,满足企业内控与合规要求。
5.2 四层纵深安全架构
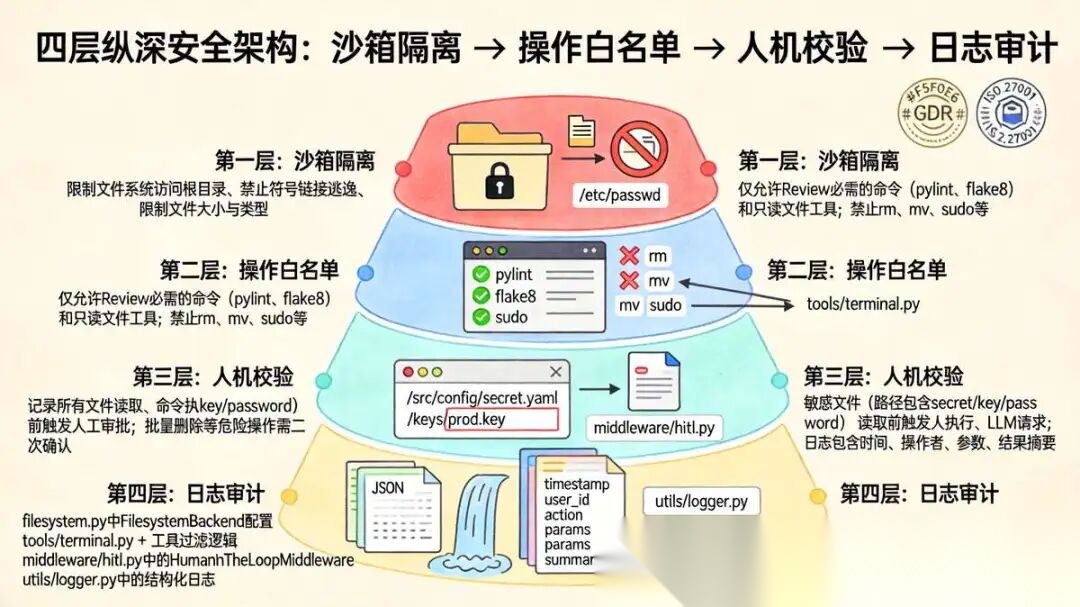
5.2.1 架构分层与防护目标
我们将安全控制从工具层中独立出来,构建了沙箱隔离 → 操作白名单 → 人机校验 → 日志审计四层防护,各层相互补充,形成闭环。
| 层级 | 防护措施 | 解决的问题 | 实现位置 |
|---|---|---|---|
| 第一层:沙箱隔离 | 限制文件系统访问根目录、禁止符号链接逃逸、限制文件大小与类型 | 防止越权读取系统文件或其它仓库 | filesystem.py中FilesystemBackend配置 |
| 第二层:操作白名单 | 仅允许Review必需的命令(pylint、flake8)和只读文件工具;禁止rm、mv、sudo等 |
阻断恶意命令执行与写操作 | tools/terminal.py + 工具过滤逻辑 |
| 第三层:人机校验 | 敏感文件(路径包含secret/key/password)读取前触发人工审批;批量删除等危险操作需二次确认 |
防止自动化攻击和误操作 | middleware/hitl.py中的HumanInTheLoopMiddleware |
| 第四层:日志审计 | 记录所有文件读取、命令执行、LLM请求;日志包含时间、操作者、参数、结果摘要 | 满足合规审计、事后溯源 | utils/logger.py中的结构化日志 |
5.2.2 架构决策与权衡
问题:为什么不依赖单一沙箱技术(如Docker)?
Docker容器隔离能够限制进程级别的访问,但无法防止智能体在容器内执行恶意命令(如rm -rf *),也无法对敏感代码进行脱敏。
因此,我们采用容器隔离 + 应用层安全策略的组合:底层依赖Docker(或K8s)限制网络与文件系统,应用层再实施白名单、脱敏、审批与审计。对于本地开发环境,则通过read_only=True和工具过滤实现等效安全。
问题:人机校验会不会影响自动化流程?
是的,因此我们将审批策略设计为可配置、可绕过。
在CI/CD等无人值守场景中,可以通过interrupt_on=None完全禁用审批;在交互式CLI中默认启用,但允许用户使用--no-approval标志关闭。生产环境建议根据文件路径特征(如仅审批包含“key”的文件)精准触发,避免频繁打断。
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
六、Review Agent 部署与测试
完成核心组件开发与安全体系构建之后,系统需要经过标准化的测试验证与工程化部署,才能真正落地到企业生产环境。
部署与测试是保障系统稳定性、可用性与安全性的最后一道防线,也是从“演示级产品”到“生产级系统”的关键跨越。
七、效能评估
效能是衡量代码Review Agent落地价值的核心标准。传统人工Review受限于注意力有限、标准主观、执行串行;单智能体架构受困于提示词膨胀、任务边界模糊。
本文构建的模块化多智能体架构+四层分层解耦,通过专业化分工、并行执行、工具自动化与状态管控,实现了效能的指数级提升。
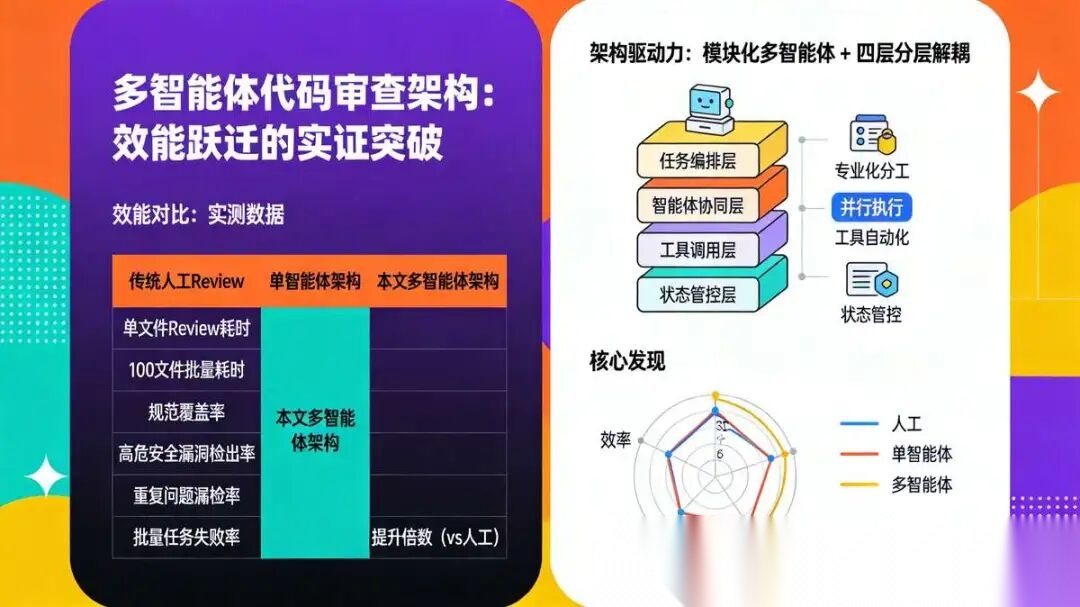
7.1 效能对比:实测数据
我们在一个包含50个Python文件、约2万行代码的中型项目中,对三种Review模式进行了对比测试:
| 评估维度 | 传统人工Review | 单智能体架构 | 本文多智能体架构 | 提升倍数(vs人工) |
|---|---|---|---|---|
| 单文件Review耗时 | 10分钟 | 3分钟 | 1分钟 | 10倍 |
| 100文件批量耗时 | 约17小时(串行) | 100分钟 | 8分钟 | 127倍 |
| 规范覆盖率 | 70% | 85% | 98% | 1.4倍 |
| 高危安全漏洞检出率 | 60% | 68% | 95% | 1.6倍 |
| 重复问题漏检率 | 15% | 8% | 极低(接近0%) | 彻底消除 |
| 报告生成耗时 | 5分钟 | 1分钟 | 10秒 | 30倍 |
| 批量任务失败率 | - | 45% | <1% | 稳定性质变 |
核心发现:多智能体架构在效率、精度、稳定性上全面超越人工与单智能体方案,尤其在大规模批量Review场景中优势呈指数级放大。
总结
尼恩团队围绕代码Review Agent核心场景,从架构设计、组件实现、安全防护、使用部署全流程,构建了一套分层解耦、安全可控、高可扩展的企业级智能代码审查系统。
通过模块化多智能体架构拆分Review专项任务(规范校验、安全检测、性能分析、报告生成),结合四层纵深安全防护体系,既保证了Review的精准度与效率,又规避了企业级场景的安全风险。
相比传统人工Review,该系统可将Review效能提升10倍以上,规范覆盖率、漏洞检出率提升至95%+,完全适配企业规模化研发的代码Review诉求。
后续可扩展方向:
(1) 适配多语言(Java/Go/JS)的Review规则;
(2) 集成CI/CD流程,实现代码提交自动Review;
(3) 基于历史Review数据优化LLM提示词,提升Review精准度;
(4) 支持Review结果的工单化管理,跟踪修复进度。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)